
記住我

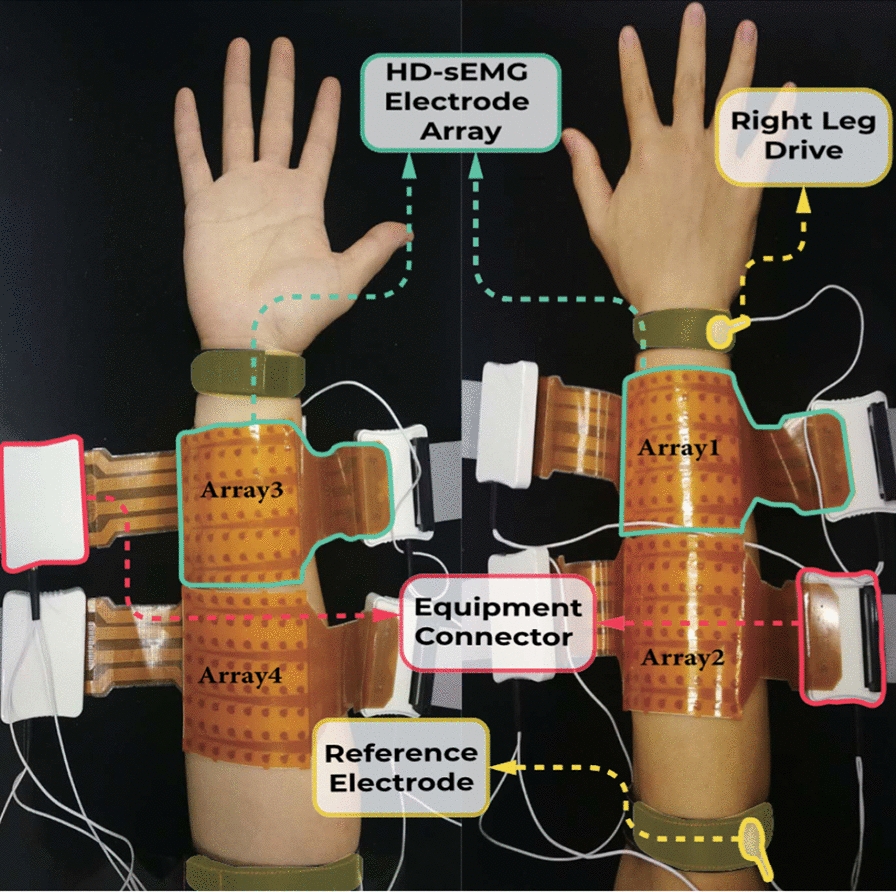
We decimated the sampling rate of raw EMG signal into 1024 Hz. Then, the raw signals were filtered with a 10–500 Hz band-pass filter. Sequentially, a series of notch filters at 50 Hz and its harmonics up to 400 Hz were applied to attenuate the power-line interference. After filtering, we segmented the sEMG signals according to the trigger recorded during the acquisition. Each segment contains 1024 data points (1024 Hz \(\times\) 1 s). Considering that most of the subjects have a certain reaction time before performing the gesture, we selected the last 0.5 s of each data segment as one sample.
EMG measuresThe information carried in sEMG signals can be reflected from many views, such as waveform, time-domain features and frequency-domain features. To compare the similarities and differences between the pattern-specific components disentangled from distinct types of feature information, we selected different sEMG measures as the input of the network [18], including raw signal, sEMG envelope, short-time Fourier transformation (STFT), root mean square (RMS), wave length (WL), zero crossing (ZC), and slope sign change (SSC). For these measures, raw signal and sEMG envelope reflect the waveform characteristics of sEMG signals, STFT contains frequency-domain information in sEMG, and the last four measures represent the time-domain features of sEMG. In the following subsections, these measures are introduced in detail.
For clearer explanation, each sample is denoted as \(\^\}\in }^\). Specifically, x denotes to the sEMG features with dimension of d, which can be varied across different sEMG measures. Since the sEMG signals used in this study have 256 channels, each sample can be referred as a \(d\times 256\) matrix. \(i\in \_\}\) and \(j\in \_\}\) denote the indexes of subject identity and gesture respectively, where \(N_=20\) and \(N_=10\) since we have 20 subjects and 10 gestures.
Raw signalTo control the size of data for model training due to the memory size of GPU, we decimated the segmented data three times. Accordingly, the size of raw signal measure for each sample is 171 \(\times\) 256 (d = 171).
sEMG envelopeFor the sEMG envelope, we smoothed the signal to reduce the significant vibration in the raw signal. In detail, we calculated the root mean square (RMS) of each sample with a window length of 31.25 ms and a step length of 1.95 ms. Accordingly, the size of sEMG envelope measure for each sample is 240 \(\times\) 256 (d = 240).
Frequency-domain featuresWe selected short-time Fourier transformation (STFT) [19] as the frequency-domain feature of sEMG signal because it can preserve time-series information as well. Specifically, the window length of STFT was set as 125 ms and the overlap was zero, generating 4 windows for each 0.5-s sample. To reduce memory occupation, we downsampled the spectrum by four times. Accordingly, the size of frequency-domain measure for each sample is 256 (4 windows × 64 elements per window) × 256 (d=256).
Time-domain featuresFor time-domain feature extraction, we selected four representative time-domain features of sEMG [20], namely root mean square (RMS), wave length (WL), zero crossing (ZC), and slope sign change (SSC). The entire sample in each channel was used to calculate the value of each feature. The vectors of four time-domain features were concatenated into one matrix. Accordingly, the size of time-domain measure for each sample is 4 × 256 (d = 4).
Fig. 3
The framework of proposed model
Combination of different EMG measuresThe frequency-domain and time-domain features of sEMG carry two types of information in two representative but distinct perspectives, both of them performing well in gesture recognition tasks. Therefore, we assumed that the combination of the two measures may provide a more complete description for the characteristics of sEMG signals to achieve a better disentanglement effect.
Therefore, we also investigated the performance of the combination of different EMG measures. However, considering the disentanglement model used in this study (see Fig. 3, and more details can be found in the next section), there are multiple options for combining different features at different positions in the network:
Combining before encoderIn this case, the STFT and all time-domain features were combined into a \(d\times 16\times 16\) array (\(d=260\)), and then served as the model input. In other words, they shared the same encoders and decoder during training.
Combining before decoderIn this case, the STFT and all time-domain features were separately input into the encoder and then combined before the decoder. It means that they had independent encoders for disentanglement and shared a decoder for reconstruction.
Combining before classifierIn this case, the STFT and all time-domain features have independent encoders and decoder from each other. Their pattern-specific components were combined after the model training and then used for gesture recognition.
Disentanglement network modelTo enable the disentanglement model to learn the spatial information of array electrodes, we remapped the data into \(16\times 16\) according to the electrode topological position during acquisition. Accordingly, the sEMG measures were fed into the disentanglement model in the shape of \(d\times 16\times 16\).
In our original study which firstly proposed the sEMG disentanglement model, a multiple encoders and one decoder model structure was proposed to separate the subject-specific and pattern-specific components [16]. In this study, the disentanglement model is innovatively proposed inspired by a classical generative adversarial network (GAN) [21], combined with the original structure. The modification can further enhance the robustness of the model against the individual difference of sEMG signals. The generator is constructed based on a multi-encoder and single-decoder architecture [22, 23], and the discriminator is composed of a series of fully connected layers. The whole architecture of the network is illustrated in Fig. 3. The two encoders, \(E_\) and \(E_\), share the same architecture based on convolutional neural networks (CNN), but are trained independently. They respectively serve to disentangle the pattern-specific and subject-specific components from the the sEMG measures. Accordingly, the decoder takes the responsibility to reconstruct the original inputs with the two components disentangled by the encoders. For better reconstruction of the generator, the task of the discriminator Dis is to distinguish between real samples and reconstructed samples.
The detailed network parameters of the model are listed in Table 1. In the table, Conv, IN, LRLU, UpS, RP and DO denote Convolution, Instance Normalization, Leaky ReLU, Upsample, Reflection Pad and Dropout layers, respectively. k, s and p respectively denote the kernel, stride and padding size of the Convolution Layer. In/Out denotes the input/output channel number of the Convolution Layer. The slope of Leaky ReLU and the probability of Dropout are both 0.2.
Table 1 The detailed parameters of the proposed networkModel trainingThe training loss is composed of the generator loss and the discriminator loss, respectively denoted by \(}_\) and \(}_\). In the generator loss \(}_\), four main parts are involved, namely triplet loss on subject \(}_\), triplet loss on gesture pattern \(}_\), self reconstruction loss \(}_\) and cross reconstruction loss \(}_\). During training, the generator and the discriminator are updated by \(}_\) and \(}_\) in turn independently.
The triplet losses of subject identity can minimize the distance between samples from the same subject in the latent space, and maximize that between samples from the different subjects. It can be described as following formulas:
$$\begin \begin }_&=}[\Vert E_(x_)-E_(x_)\Vert -\Vert E_(x_) \\&-E_(x_)\Vert +\alpha ]_ \end \end$$
(1)
Accordingly, the triplet losses of gesture pattern can cluster the samples of the same gesture in the latent space as close as possible, and scatter those of different gestures as far away as possible. It can be described as following formulas:
$$\begin \begin }_&=}[\Vert E_(x_)-E_(x_)\Vert -\Vert E_(x_) \\&-E_(x_)\Vert +\alpha ]_ \end \end$$
(2)
To ensure that the disentangled components can reconstruct the original signal, we add two reconstruction loss terms to the entire training loss, namely \(}_\) and \(}_\). The former encourages the subject-specific and pattern-specific components extracted from the real sample to be reconstructed as close to itself as possible. The latter utilizes the subject-specific and pattern-specific components from two different samples to reconstruct a real sample, enhancing the independence between the two components. They are respectively formulated as:
$$\begin }_=}[\Vert D(E_(x_),E_(x_))-x_\Vert ] \end$$
(3)
$$\begin }_&=}[\Vert D(E_(x_),E_(x_))-x_\Vert ] \end$$
(4)
Eventually, we obtain the total loss of the generator by summing the above four terms:
$$\begin }_=}_+}_+\lambda _}_+\lambda _}_ \end$$
(5)
To balance the contribution of different parts in training, we multiply \(_\) and \(_\) by two balance weights, respectively termed as \(\lambda _\) and \(\lambda _\). Considering that the subject-specific and pattern-specific components are of equal importance in this study, \(\lambda _\) and \(\lambda _\) are both set to 0.5.
To distinguish real samples and reconstructed samples, we use \(_\) and \(_\in \) to denote the sample and its label, where the sample is real if \(_=1\) and is reconstructed if else. \(n\in \_\}\) denotes the index of the sample, where N denotes the number of all samples. Therefore, the loss of the discriminator can be described as:
$$\begin }_= -[y_\cdot log(Dis(x_))+(1-y_)\cdot log(1-Dis(x_))] \end$$
(6)
Validation protocolsFor the validation, we used different sEMG measures as the model input. Considering that the proposed model is a generic model oriented to cross-subject scenarios, we trained the model on data from 15 of the 20 subjects, and tested it on data from the rest. Accordingly, a five-fold cross-validation was conducted on the 20 subjects.
Since the final purpose of this study is to identify the user’s gesture, we employed the recognition accuracy to evaluate the effectiveness of the extracted pattern-specific components. Additionally, to get a more concrete understanding of the pattern-specific components extracted from different types of inputs, we visualized them in the form of 2-D heatmap based on the topological position of electrode arrays. In this way, we further compared the similarities and differences of pattern-specific components from different sEMG measures and different hand gestures.
Gesture recognition accuracyFor gesture recognition accuracy, we directly input the components extracted by the pattern-specific encoder into three typical classifiers, namely Support Vector Machine with linear kernel (SVM), K-Nearest Neighbor (KNN) and Random Forest (RF). The classification accuracy of 10 gestures were recorded. These three classifiers are chosen for that they do not perform additional nonlinear transformations on the extracted components, thus making the recognition accuracy more dependent on the quality of pattern-specific components, instead of the classifiers.
Gesture pattern visualizationFor gesture pattern visualization, we reconstructed the pattern-specific components into \(d\times 16\times 16\), then plotted its 16 × 16 heatmap according to the average value of all feature dimensions. For reconstruction, the pattern-specific components matrix was concatenated with an all-zero matrix shaped like the subject-specific components, and then processed by the decoder. The output can be considered as the sEMG features with only pattern-related information, arranged in a way consistent with the topological position of electrode arrays. Therefore, we can find the muscle groups capturing the model attention with the highlighted areas of the heatmap. In this way, we can further explore the relationship between the model attention area and the muscle activation pattern, providing neurophysiological interpretation for the pattern-specific components extracted by the model.
Correlation coefficientTo further quantify the correlation of different gesture patterns after decoding, we calculated the correlation coefficients between the reconstructed heatmaps of one gesture and that of the others in pair. According to the gesture recognition accuracy (shown in Tables 2 and 3), we selected three best-performing EMG measures for result presentation (Fig. 4).
Table 2 Gesture recognition accuracy of different sEMG measuresTable 3 Gesture recognition accuracy of combining frequency-domain and time-domain measures at different layersFig. 4
Correlation coefficient between gestures for different EMG measures. Each row/column in the figure corresponds to the number of each gesture, with the last row/column representing the mean correlation coefficient of that row/column
Ablation experimentTo evaluate the impact of GAN on the performance of the disentanglement model, we conducted an ablation experiment, training and testing the model without GAN. In the ablation experiment, the loss function of the model only have one item \(}_\).
Statistical analysisWe conducted the Shapiro-Wilk test on the accuracies of all measures. The results showed that the accuracy values did not follow Gaussian distribution. Therefore, we employed non-parametric tests for statistical analysis. Specifically, the Wilcoxon signed-rank test was selected as the statistical method for comparisons in this study. A significant difference of \(p<0.05\) was used in this study.
留言 (0)