
記住我

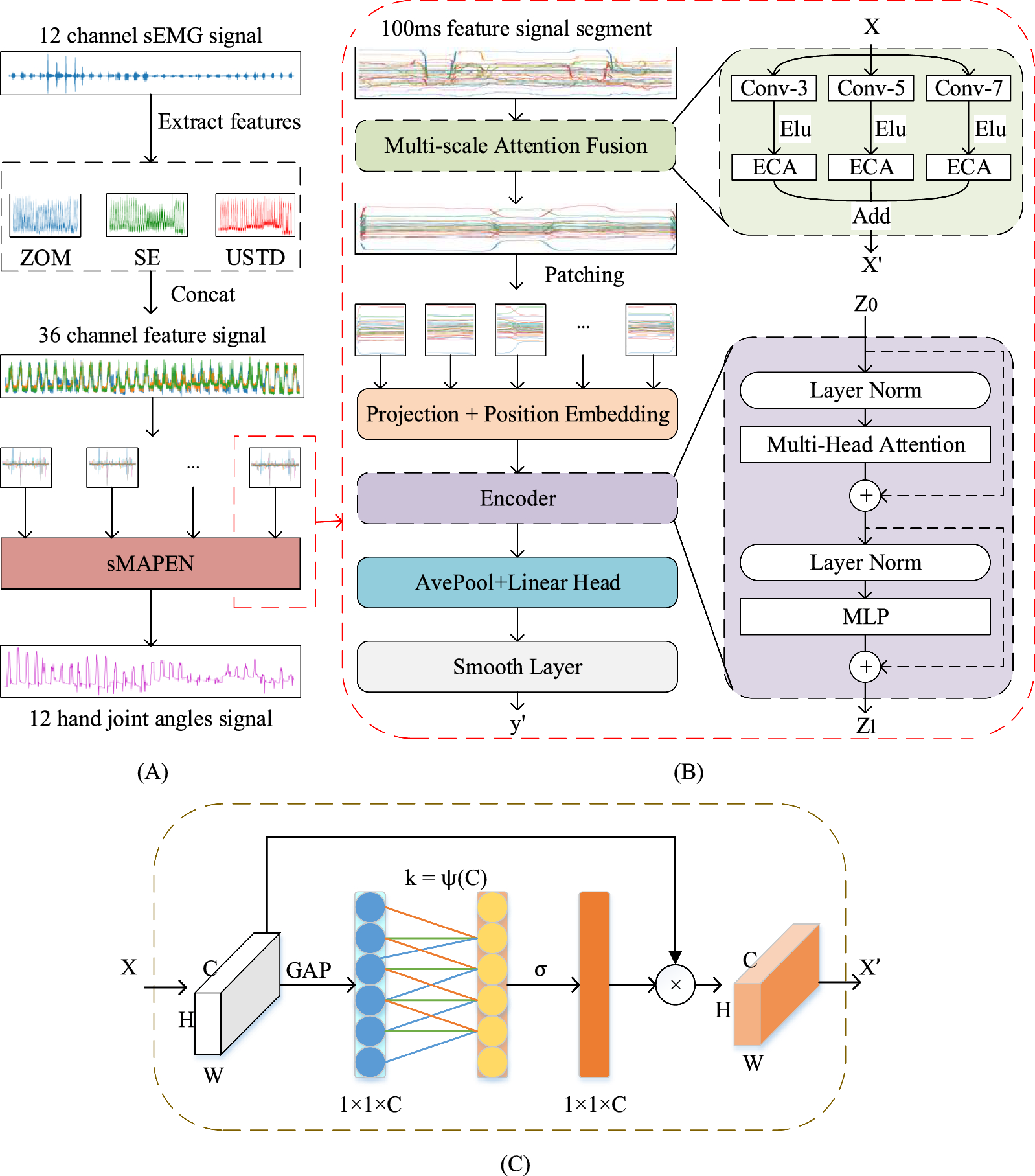
The Multi-Scale Attention Fusion (MAF) part uses three convolution operations with kernel sizes of 3, 5, and 7 to connect the ECA channel attention module. Then it adds up the results of the three operations to enhance the channel features of the input feature map while preserving the size.
The Patch Encoder (PE) section first divides the input data into multiple patches and adds positional information. Then, the Transformer Encoder extracts advanced features from the information to obtain the predicted joint angles.
The smoothing layer utilizes a small amount of historical data to process larger predicted values, to fit the actual human motion data.
A. FeaturesTo reduce latency and ensure an accurate representation of effective information, we employed a sliding window of 100-ms duration, with 0.5-ms stride length to extract features from each sEMG channel. We extracted the following features from these intervals. From the lightweight feature set, we selected three sEMG features [23]: Zero Order Moment, Shake Expectation, and Unbiased Standard Deviation. The formulas used for the calculation of these features are presented below:
1) Zero Order Moment (ZOM)Extracting the zero-order moment from time domain signals allows for the representation of muscle contraction strength through the square root of the zero-order moment. Adjusting the magnitude of its value using the logarithmic function brings it closer to the inverse characteristic. The expression for the square root characteristic of the electromyographic zero-order moment is denoted as \(_\).
$$\beginc} = Log\left( }^} } } } \right)} \\ \end$$
(1)
where \(N\) represents the length of the sliding window, and \(x\left[i\right]\), \(i=1, 2,..., N\) represents the sEMG signal with a time length of \(N\).
2) Shake Expectation (SE)In the field of sEMG processing, the expectation (Shaking Expectation, SE) of the EMG amplitude change speed can be expressed by the mean value of the absolute value of the second derivative. Calculated as follows:
$$\beginc} \sum\limits_}^} x\left[ i \right]} \right|} } \\ \end$$
(2)
where \(^\) represents the second derivative.
3) Unbiased Standard Deviation (USTD)Here, the unbiased standard deviation based on Bessel correction is used to reflect the degree of dispersion of the sEMG data. It is calculated as follows:
$$\beginc} \sum\nolimits_^ } \right|^ } } } \\ \end$$
(3)
where \(\widehat\) represents the expected value of the sEMG sample.
B. Multi-scale Attention Fusion (MAF)Essentially, the MAF module is the combination of multi-scale convolution and Efficient Channel Attention (ECA) modules [26] (Fig. 1). The kernel size of convolution is 3, 5, and 7 in this study. Multi-scale convolution is used to obtain the local temporal features. ECA employs a global average pooling technique to extract global features. A one-dimensional convolution operation is attached to ECA to learn inter-channel interactions. The kernel size of the one-dimensional convolution is crucial as it determines the interaction between channels. The kernel size k can be calculated by the following formula:
$$\beginc} log_ \left( C \right) + \frac} \right|_ } \\ \end$$
(4)
where \(_\) represents the odd number closest to \(t\). C denotes the channel dimension (i.e., number of filters).
Fig. 1
The model structure of the continuous hand movement estimation method based on sMAPEN for sEMG signal. A shows the overall flowchart, first extracting features from the raw sEMG, and then dividing the features into 100 ms (200 sampling points) slices for prediction by the model. Where ZOM, SE, and USTD denote three sEMG features: Zero Order Moment, Shake Expectation, and Unbiased Standard Deviation, respectively. “Concat” refers to the operation of splicing two matrices according to corresponding dimensions [24]. B is the specific structure of the sMAPEN model. Where Conv-3 represents convolutional computation using a convolutional kernel size of 3, Elu refers to the activation function, ECA represents the Efficient Channel Attention Module, and Add stands for computing sums [26]. C shows the structural details of the ECA module, where GAP represents global average pooling, k represents dynamic convolution kernel size, σ represents the activation function, and represents channel multiplication [25]
In this study, we employ the ECA method to extract sEMG features between channels. This allows us to extract temporal scale information and inter-channel spatial information simultaneously. Finally, we combine the information from each feature branch to obtain a multi-scale feature representation \(X^\, \in \,}^\), which represents the extracted features:
$$\beginc} = F\left( } \right) + F\left( } \right) + F\left( } \right)} \\ \end$$
(5)
$$\beginc} X} \right)} \right) } \\ \end$$
(6)
where \(^\) denotes C convolutional operations with \(n\times 1\) kernels, \(\sigma\) denotes the ELU activation function, and E denotes the ECA channel attention module. \(_\), \(_\), and \(_\) denote different convolutional kernel sizes, which are set to 3, 5, 7 in this paper.
C. Patching Encoder (PE)Patching Encoder (PE) consists of two processes: Patching Layer and Transformer Encoder. The patching layer divides the input data into multiple patches first, and after linear transformation, adds positional information as input information for the encoder. The Transformer Encoder consists of multi-head attention modules and multilayer perceptron modules, which can effectively extract advanced features of information and capture their complex relationships. And then ultimately obtaining predicted joint angles.
1) Patching LayerBefore feeding the multi-scale feature fused signal \(X^\) into the encoder, we divide it into several non-overlapping patches, denoted as \(X_ = \left\^ ,x_^ \ldots x_^ } \right\}\). The length of each patch is \(C\), so the number of patches is \(m=W/C\). Unlike traditional Transformer-based models, we do not treat each time point as a token, we treat each patch as a token. We linearly project each token to dimension d of the model through an embedding matrix \(E\) and then fed it into a normal Transformer encoder directly. \(E\) is randomly initialized while initializing the model. During the training process, each element is randomly selected and continuously optimized through a backpropagation algorithm and gradient descent to transform patches into more meaningful feature representations.
Since sEMG signal is a special type of time series, its sampling points at each time step do not have clear semantic meanings like words in a sentence. Therefore, extracting local semantic information is crucial for analyzing the relationships between them. Compared to many previous methods that only use token-level input point by point, we adopted the approach of aggregating the time steps into sEMG subsequence-level patches. This not only enhances locality but also captures comprehensive semantic information that is not available at the point level.
Additionally, dividing sEMG signals into fragment sequences brings another benefit: it can reduce the computational complexity so thus improving the efficiency of the model. The original attention mechanism has a time and space complexity of O(N2). However, by using patching, the number of input tokens can be reduced from input sequence length L to approximately \(L/S\). This reduces the memory usage and computational complexity of the attention map by a factor of \(S\), resulting in improved computational efficiency. Furthermore, to prevent overfitting, parameters in our prediction head will also be reduced by a factor of \(S\).
What should be noted is that sEMG signals have a specific order, if the order is changed, the meaning of the input signal will also change accordingly. However, the transformer’s architecture does not model positional information, so the order of the input sequence needs to be encoded explicitly. In this study, we employ a learnable 1D position embedding matrix \(E^ \in }^\) to capture position information. The learnable 1D position embedding matrix has the same dimension as patch embedding, and each row corresponds to the position information of a patch in the image. At the beginning of training, \(^\) will be randomly initialized, and then continuously optimized through gradient descent during the training process. Patch sequence have been generated with location information can be expressed as:
$$\beginc} = \left[ ^ E;x_^ E; \ldots x_^ E} \right] + E^ } \\ \end$$
(7)
where \(x_^ ,\,x_^ \ldots x_^\) represents the patch partitioned from the input data, \(E\) and \(^\) respectively represent the linear transformation matrix and positional embedding matrix. First, divide the input data into multiple patches, and each patch is first transformed with a linear transformation \(E\) to obtain an embedding vector, which is the token. After obtaining all the tokens, add position information, i.e. \(^\), to these tokens, and these token sequences are the input information of the encoder.
2) Transformer EncoderNext, we input the patch with positional information into the encoder. We adopt \(N\) identical encoders to extract relevant information from the sEMG signal, each consisting of a multi-head self-attention block (MSA) and a multi-layer perceptron (MLP) [28]. For ease of description, we denote the input of each layer of the encoder as \(_\) (\(l=\text\dots N\)).
Multi-Head Self-AttentionThe multi-head attention module is composed of multiple self-attention layers. The function of the self-attention layer is to capture the correlation between different vectors in the sequence of sEMG features, and aggregate global contextual information to update each component of the sequence.
Therefore, for a series of input segments \(_\), we first transform the input vectors into three different vectors: query vector \(q\), key vector \(k\), and value vector \(v\), with dimensions of \(_\)=\(_\)=\(_\)=\(D\). Vectors from different inputs are packed into three different matrices, namely \(Q, K\), and \(V\). The formula for computing the attention function between different input vectors is as follows:
$$\beginc} \right) = softmax\left( }} } }}} \right) \cdot V} \\ \end$$
(8)
Multi-head attention allows the model to use multiple attention heads to focus on different parts of the input sEMG patch in different ways. Assuming there are h heads, each head has a dimension of \(_= D/h\). First, we calculate the output result \(_\) for each attention head, then concatenate the output of multiple attention heads according to their respective dimensions and project the result into a matrix, which can be achieved through the following process:
$$\beginc} = Attention\left( ,K_ ,V_ } \right)} \\ \end$$
(9)
$$Multihead = Concat\left( \ldots head_ } \right)W$$
(10)
where \(_\), \(_\), and \(_\) respectively represent \(Q, K, V\) in the calculation process of the i-th attention head, and \(W \in }^\) is a linear projection matrix.
To slow down the degradation of the network and accelerate the training speed, this module adds skip connections and layer normalization operations, the formula is as follows:
$$\beginc} = Multihead\left( } \right)} \right) + Z_ } \\ \end$$
(11)
Multi-layer Perceptron (MLP)The MLP consists of two linear transformation layers, a dropout layer, and a non-linear activation function called a Gaussian Error Linear Unit (GELU). The linear transformation layer of MLP maps the input data \(Z\) to a higher dimensional space, helping the network integrate information. The dropout layer is used to avoid overfitting. Then filter through the nonlinear activation function, and change the data back to the original dimension after filtering. Inspired by [27], we finally chose GELU instead of the commonly used ReLU due to its higher accuracy on numerous datasets. Therefore, MLP can be described as:
$$\beginc} } \right) = W_ \delta \left( Z_ } \right)} \\ \end$$
(12)
where \(_\) and \(_\) represent the parameter matrices of the two linear layers, respectively, and \(\delta\) represents the activation function GELU.
As with the multi-head attention module, a residual block and a normalization layer are also added here:
$$\beginc} _ = MLP\left( } \right)} \right) + Z_ } \\ \end$$
(13)
Prediction LayerTo avoid feature redundancy, average pooling was first used to further compress the features, and then a linear layer was used to make predictions, resulting in the predicted joint angles \(y\).
$$\beginc} _ } \right)} \right)} \\ \end$$
(14)
D. Smooth LayerBased on the preliminary results of experiments, the network predictions have certain fluctuations, which may cause the joint angle sequence to not match the smoothness of biological movements. Therefore, a smoothing module is introduced to smooth the predicted joint angle signals. The module can use a small amount of historical joint angles to handle some predicted values with larger errors, making them more consistent with actual human movements and improving the robustness of the model. The specific implementation method is described as follows:
$$y_^ \, = \,\sum\limits_}^ }}}$$
(15)
$$\beginc} = y^_ + y^_ + y^_ } \\ \end$$
(16)
$$\beginc} = \alpha y^_ + \left( \right)s_ } \\ \end$$
(17)
where \(y\) is the output of MAPEN, \(L\) represents the window length, and \(\alpha\) represents the smoothing coefficient. According to Fig. 1. We set \(L\) and \(\alpha\) to 4 and 0.3, respectively.
留言 (0)