


記住我
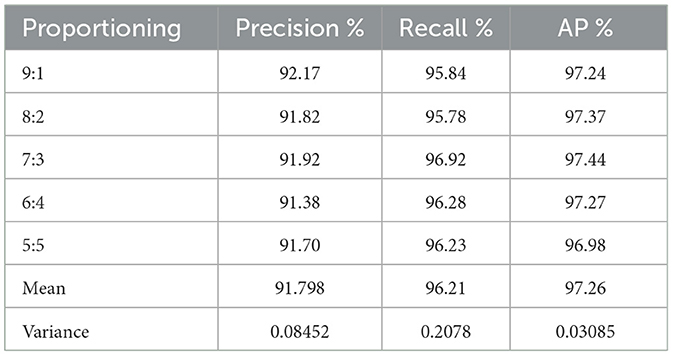
Table 5. Sample cutting in different proportions.
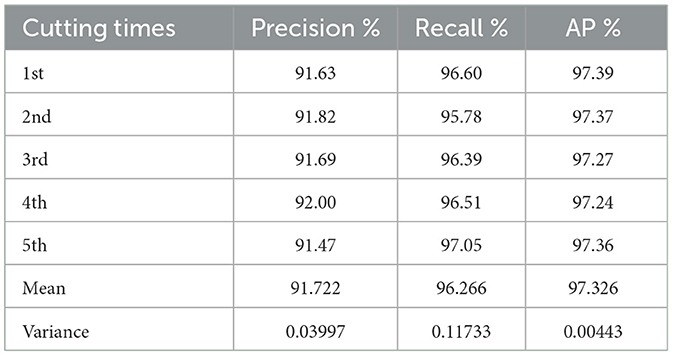
Table 6. Multiple sample cuts in the same proportion.
Table 5 shows that although the number of samples of ship targets in the test samples that are randomly divided by different ratios of the dataset varies significantly, the average accuracy of ST-YOLOA does not change much. However, even though the average accuracy of the samples divided in the ratio of 5:5 among them differed more than the others, it exhibits a good detection ability, which is analyzed because the detection effect degrades as a result of an insufficient number of training samples. The variance of AP for each sample in this experiment is 0.03085, and the variances of the precision and recall are 0.08452 and 0.2078, respectively. This indicates that the ST-YOLOA model proposed in this paper has a stable detection effect for test sets with different numbers of data samples and shows a strong generalization ability.
Due to the same number of samples and smaller variations in the number of ship targets, as shown in Table 6, the variance of the experiment's indicators is lower for samples divided multiple times at the same scale. The mean and variance of the SA-YOLOA model for the same proportion of samples divided multiple times were 91.722% and 0.03997 for precision, 96.266% and 0.11733 for recall, and 97.326% and 0.00443 for mean precision, respectively.
The information in Tables 5, 6 leads to the conclusion that ST-YOLOA performs well and has excellent generalization capacity, both in test samples with various ratios of randomly divided datasets and in test samples with the same proportion of multiple divided datasets.
4.5. Detection effect of the ST-YOLOA model in different scenariosTo visualize the detection effect of the ST-YOLOA model and further measure the model performance, this section first shows the schematic of the confusion matrix of the ST-YOLOA algorithm. As shown in Figure 10, the confusion matrix demonstrates that ST-YOLOA has good performance.
Figure 10. Confusion matrix.
In this study, we demonstrate the effect of ship target detection under different scenarios and scales, including near-shore and far sea. Figure 11 presents the detection effect in each scenario. The first and second rows are near-shore ship targets near islands and near-shore buildings, respectively. Such targets have complex backgrounds and are susceptible to the influence of other non-ship targets around them. Multiple near-shore ship targets can easily be framed by a single detection box due to the dense docking of ships, which suppresses candidate boxes with high overlap and low prediction scores. The third row is a small, dense target in the distance that is easy to miss because it has a small ship scale. The ship target in the fourth row is prone to erroneous target localization since it has indistinct target borders and complicated background information. In all four aforementioned scenarios, the ST-YOLOA model significantly improved the detection rate and accuracy, as can be seen from the figure, and produced positive detection results.
Figure 11. Detection effects in different scenarios.
4.6. Limitations and discussionThe results of previous experimental studies show that our model achieves sound visual effects in SAR ship detection in complex scenes. It is demonstrated that the ST-YOLOA model can learn global features and can be used to extract more powerful semantic features for ship target detection in harsh environments and complex scenes. However, our approach still suffers from some limitations.
The relatively high computational complexity and large number of parameters of the Swin Transformer module lead to more extended training and inference time. As seen from the experimental ablation results in Table 1, although we have used the Swin-Transformer network with a smaller model as much as possible, its use still introduces many parameters compared to the base model. The Swin Transformer network has a solid global modeling capability, capturing rich global feature information and integrating global data. This process requires a vast amount of support operations, resulting in more parameters and computations than other models. At the same time, the computational complexity of the Swin Transformer increases with the length of the input sequence. When dealing with very long input sequences, Swin Transformer may face problems such as high computational complexity and large memory consumption, which need to be alleviated by using lightweight models or other techniques.
5. ConclusionsTo ensure the accuracy of SAR ship target recognition under complicated situations, in this study, we have suggested a more extended ST-YOLOA ship target identification model. To begin with, the feature extraction section adds the Patch Embedding module after the input layer to chunk and flatten the input image and then produces feature maps of varying sizes using Swin Transformer Blocks and the Patch Merging layer. A coordinated attention mechanism is designed at the end to simultaneously capture position information and channel relationships, which significantly improves the performance of downstream tasks. Second, to effectively use semantic and localization information, the PANet is employed to thoroughly fuse high-level and low-level feature information. Finally, a decoupled detection head in the target detection section is used to significantly speed up model convergence and improve the position loss function, both of which improve model performance. This model is more suited for ship target detection in challenging surroundings and complex circumstances because it can extract more potent semantic characteristics and can better learn global features than other detection models.
Considering that our model focuses on improving SAR ship detection accuracy in complex environments, the vital index of the number of parameters of the model is ignored to a certain extent. In the future, we will further conduct model optimization and carry out research on model lightweight by adjusting hyperparameters and model compression methods, such as quantization, distillation, and pruning, and further analysis on lightweight Swin Transformer to achieve lower model parameter computation, faster training speed, and maintain previous accuracy.
Data availability statementThe original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributionsConceptualization: XY, KZ, and RL. Methodology and writing–original draft preparation: KZ and RL. Software: RL. Investigation: JF and SW. Resources and visualization: KZ. Writing–review and editing: XY, KZ, and SW. Supervision: KZ and SW. Project administration and funding acquisition: XY. All authors have read and agreed to the published version of the manuscript.
FundingThis work was supported in part by the National Natural Science Foundation of China under Grant 62276274 (Corresponding author: RL).
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
ReferencesAn, Q., Pan, Z., Liu, L., and You, H. (2019). DRBox-v2: an improved detector with rotatable boxes for target detection in SAR images. IEEE Trans. Geosci. Remote Sensing 57, 8333–8349. doi: 10.1109/TGRS.2019.2920534
CrossRef Full Text | Google Scholar
Bochkovskiy, A., Wang, C. Y., and Liao, H-, Y. M. (2020). Yolov4: Optimal speed and accuracy of object detection. arXiv 2004, 10934. doi: 10.48550/arXiv.2004.10934
CrossRef Full Text | Google Scholar
Cumming, I. G., and Wong, F. H. (2005). Digital processing of synthetic aperture radar data. Artech House 1, 108–110.
Duan, K., Bai, S., Xie, L., Qi, H., Huang, Q., Tian, Q., et al. (2019). “Centernet: Keypoint triplets for object detection”, in Proceedings IEEE/CVF, 6569–6578. doi: 10.1109/ICCV.2019.00667
CrossRef Full Text | Google Scholar
Everingham, M., Van Gool, L., Williams, C. K., Winn, J., and Zisserman, A. (2009). The pascal visual object classes (voc) challenge. Int. J. Computer Vision 88, 303–308. doi: 10.1007/s11263-009-0275-4
CrossRef Full Text | Google Scholar
Gao, G., Gao, S., He, J., and Li, G. (2018). Adaptive ship detection in hybrid-polarimetric SAR images based on the power–entropy decomposition. IEEE Trans. Geosci. Remote Sensing 56, 5394–5407. doi: 10.1109/TGRS.2018.2815592
PubMed Abstract | CrossRef Full Text | Google Scholar
Gao, W., Liu, Y., Zeng, Y., Li, Q., and Liu, Q. (2022). Enhanced attention one shot SAR ship detection algorithm based on cluster analysis and transformer in Second International Conference on Digital Signal and Computer Communications (DSCC 2022): SPIE, 290–295. doi: 10.1117/12.2641456
CrossRef Full Text | Google Scholar
Ge, Z., Liu, S., Wang, F., Li, Z., and Sun, J. (2021). Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv: 2107, 08430.
PubMed Abstract | Google Scholar
Girshick, R. (2015). “Fast r-cnn”, in Proceedings of the IEEE International Conference on Computer Vision, 1440–1448. doi: 10.1109/ICCV.2015.169
Girshick, R., Donahue, J., Darrell, T., and Malik, J. (2014). “Rich feature hierarchies for accurate object detection and semantic segmentation”, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 580–587. doi: 10.1109/CVPR.2014.81
CrossRef Full Text | Google Scholar
Guo, M., Xu, T., Liu, J., Liu, Z., Jiang, P., Mu, T., et al. (2022). Attention mechanisms in computer vision: a survey. Comput. Visual Media 8, 331–368. doi: 10.1007/s41095-022-0271-y
CrossRef Full Text | Google Scholar
Guo, W., Shen, L., Qu, H., Wang, Y., and Lin, C. (2022). Ship detection in SAR images based on adaptive weight pyramid and branch strong correlation. J. Image Graphics 27, 3127–3138. doi: 10.11834/jig.210373
Hou, Q., Zhou, D., and Feng, J. (2021). “Coordinate attention for efficient mobile network design”, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13713–13722.
PubMed Abstract | Google Scholar
Hu, J., Shen, L., and Sun, G. (2018). “Squeeze-and-excitation networks”, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7132–7141.
Jiang, X., Cai, W., Yang, Z., Xu, P., and Jiang, B. (2022). Infrared dim and small target detection based on YOLO-IDSTD algorithm. Infrared Laser Eng. 51, 502–511. doi: 10.3788/IRLA20210106
CrossRef Full Text | Google Scholar
Li, K., Zhang, M., Xu, M., Tang, R., Wang, L., Wang, H., et al. (2022). Ship detection in SAR images based on feature enhancement Swin transformer and adjacent feature fusion. Remote Sensing 14, 3186. doi: 10.3390/rs14133186
CrossRef Full Text | Google Scholar
Lin, T. Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S., et al. (2017a). “Feature pyramid networks for object detection”, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2117–2125. doi: 10.1109/CVPR.2017.106
CrossRef Full Text | Google Scholar
Lin, T. Y., Goyal, P., Girshick, R., He, K., and Dollár, P. (2017b). Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Int. 8, 2999–3007. doi: 10.1109/ICCV.2017.324
PubMed Abstract | CrossRef Full Text
Liu, C., Xie, N., Yang, X., Chen, R., Chang, X., Zhong, R. Y., et al. (2022). A domestic trash detection model based on improved YOLOX. Sensors 22, 6974. doi: 10.3390/s22186974
PubMed Abstract | CrossRef Full Text | Google Scholar
Liu, S., Qi, L., Qin, H., Shi, J., and Jia, J. (2018). “Path aggregation network for instance segmentation”, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 8759–8768.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., et al. (2016). “Ssd: Single shot multibox detector”, in Computer Vision–ECCV 2016, 14th. European Conference (Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14: Springer), 21–37.
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., et al. (2021). “Swin transformer: Hierarchical vision transformer using shifted windows”, in Proceedings of the IEEE/CVF International Conference Computer Vision, 10012–10022. doi: 10.1109/ICCV48922.2021.00986
CrossRef Full Text | Google Scholar
Lu, R., Yang, X., Jing, X., Chen, L., Fan, J., Li, W., et al. (2020a). Infrared small target detection based on local hypergraph dissimilarity measure. IEEE Geoscience Remote Sens Lett 19, 1–5. doi: 10.1109/LGRS.2020.3038784
CrossRef Full Text | Google Scholar
Lu, R., Yang, X., Li, W., Fan, J., Li, D., Jing, X., et al. (2020b). Robust infrared small target detection via multidirectional derivative-based weighted contrast measure. IEEE Geosci. Remote Sensing Letters 19, 1–5. doi: 10.1109/LGRS.2020.3026546
CrossRef Full Text | Google Scholar
Moreira, A., Prats-Iraola, P., Younis, M., Krieger, G., Hajnsek, I., Papathanassiou, K. P., et al. (2013). A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 1, 6–43. doi: 10.1109/MGRS.2013.2248301
PubMed Abstract | CrossRef Full Text | Google Scholar
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A. (2016). “You only look once: Unified, real-time object detection”, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 779–788. doi: 10.1109/CVPR.2016.91
CrossRef Full Text | Google Scholar
Ren, S., He, K., Girshick, R., and Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Proc. Syst. 28, 1–47. doi: 10.1109/TPAMI.2016.2577031
PubMed Abstract | CrossRef Full Text | Google Scholar
Robey, F. C., Fuhrmann, D. R., Kelly, E. J., and Nitzberg, R. (1992). A CFAR adaptive matched filter detector. IEEE Trans. Aerospace Electr. Syst. 28, 208–216. doi: 10.1109/7.135446
PubMed Abstract | CrossRef Full Text | Google Scholar
Schwegmann, C. P., Kleynhans, W., and Salmon, B. P. (2015). Manifold adaptation for constant false alarm rate ship detection in South African oceans. IEEE J. Selected Topics Appl. Remote Sensing 8, 3329–3337. doi: 10.1109/JSTARS.2015.2417756
CrossRef Full Text | Google Scholar
Tan, M., Pang, R., and Le, Q. V. (2020). “EfficientDet: Scalable and Efficient Object Detection”, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Tian, Z., Shen, C., Chen, H., and He, T. (2019). “Fcos: Fully convolutional one-stage object detection”, in Proceedings of the IEEE/CVF International Conference on Computer Vision, 9627–9636.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). Attention is all you need. Adv. Neural Inf. Proc. Syst. 30, 2.
Wang, C., Bi, F., Zhang, W., and Chen, L. (2017). An intensity-space domain CFAR method for ship detection in HR SAR images. IEEE Geosci. Remote Sensing Letters 14, 529–533. doi: 10.1109/LGRS.2017.2654450
CrossRef Full Text | Google Scholar
Wang, C.Y., Liao, H. Y. M., Wu, Y. H., Chen, P. Y., Hsieh, J. W., Yeh, I. H., et al. (2020). “CSPNet: A new backbone that can enhance learning capability of CNN”, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 390–391.
Wang, C. Y., Bochkovskiy, A., and Liao, H-, Y. M. (2022). YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2207, 02696. doi: 10.48550/arXiv.2207.02696
Wang, J., Zhang, Z., Luo, L., Zhu, W., Chen, J., Wang, W., et al. (2021). SwinGD: A robust grape bunch detection model based on swin transformer in complex vineyard environment. Horticulturae 7, 492. doi: 10.3390/horticulturae7110492
CrossRef Full Text | Google Scholar
Wang, Y., Wang, C., and Zhang, H. (2018). Combining a single shot multibox detector with transfer learning for ship detection using sentinel-1 SAR images. Remote Sensing Lett. 9, 780–788. doi: 10.1080/2150704X.2018.1475770
CrossRef Full Text | Google Scholar
Wu, Z., Liu, C., Wen, J., Xu, Y., Yang, J., Li, X., et al. (2022). Selecting High-Quality Proposals for Weakly Supervised Object Detection With Bottom-Up Aggregated Attention and Phase-Aware Loss. IEEE Transactions on Image Processing. doi: 10.1109/TIP.2022.3231744
PubMed Abstract | CrossRef Full Text | Google Scholar
Xia, R., Chen, J., Huang, Z., Wan, H., Wu, B., Sun, L., et al. (2022). CRTransSar: a visual transformer based on contextual joint representation learning for SAR ship detection. Remote Sensing 14, 1488. doi: 10.3390/rs14061488
CrossRef Full Text | Google Scholar
Yuan, Y., and Zhang, Y. (2021). OLCN: An optimized low coupling network for small objects detection. IEEE Geosci. Remote Sensing Letters 19, 1–5. doi: 10.1109/LGRS.2021.3122190
CrossRef Full Text | Google Scholar
Zhang, H., Cisse, M., Dauphin, Y. N., and Lopez-Paz, D. (2017). mixup: Beyond empirical risk minimization. Remote Sensing 1710, 09412. doi: 10.48550/arXiv.1710.09412
CrossRef Full Text | Google Scholar
Zhang, S., Chi, C., Yao, Y., Lei, Z., and Li, S. Z. (2020). “Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection”, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9759–9768.
Zhang, Y., Ren, W., Zhang, Z., Jia, Z., Wang, L., Tan, T., et al. (2022). Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 506, 146–157. doi: 10.1016/j.neucom.2022.07.042
留言 (0)