
記住我
The research on English speech recognition technology holds significant practical importance and broad application prospects (Kheddar et al., 2024). It not only enhances the naturalness and efficiency of human-computer interaction but also plays a crucial role in fields such as education, healthcare, and smart homes. Furthermore, the advancement of speech recognition technology can provide convenient communication means for individuals with hearing impairments, thereby improving their quality of life (Al-Fraihat et al., 2024). In the context of accelerating globalization, cross-language communication has become increasingly frequent. As English is a global lingua franca, the refinement and application of its speech recognition technology can not only facilitate international communication but also promote the integration and advancement of science and culture among nations. Therefore, the research and development of English speech recognition technology are not only a critical aspect of technological innovation but also have profound implications for social progress and human well-being (Dhanjal and Singh, 2024).
Traditional methods for English speech recognition primarily involve symbolic AI and knowledge representation. These methods include expert systems, rule-based approaches, and frame-based approaches. Expert systems use the knowledge of domain experts to perform reasoning and decision-making. They achieve speech recognition functionality through the construction of knowledge bases and inference engines. For example, the DENDRAL project used expert systems for chemical structure analysis and successfully applied similar techniques in speech recognition (Yang and Zhu, 2024). Another example is the MYCIN system, which supports clinical decision-making through expert systems and has shown similar potential in speech recognition (Tarasiev et al., 2024). Rule-based approaches map speech signals to corresponding text using a set of explicit rules. For instance, speech signals are converted into sentence structures through a series of grammatical rules (Chen, 2024). The ELIZA program, which uses a predefined set of rules for simple natural language processing, is another example where rule-based methods have been applied in speech recognition (Yan et al., 2024). Frame-based approaches use structured frameworks to represent knowledge and perform reasoning and recognition through the relationships between these frameworks. For example, frame nets were used to construct the knowledge representation structure of speech recognition systems, interpreting speech signals through the relationships between frames (Yeo et al., 2024). The STRIPS system, which uses frame nets for problem-solving, also demonstrated potential applications in speech recognition (Wang et al., 2024b). These methods offer advantages such as clear knowledge representation and transparent reasoning processes. However, they have limitations, including the inability to handle complex and variable speech environments effectively and the time-consuming and labor-intensive nature of constructing knowledge bases.
To address the limitations of traditional algorithms in handling complex and variable speech environments, data-driven and machine learning algorithms have been employed in English speech recognition. These methods solve the problem by utilizing large datasets to train and optimize models, offering advantages such as strong adaptability and high accuracy. For instance, decision tree-based methods use binary tree structures for classification and regression to achieve efficient speech recognition. A typical application is differentiating between various speech signals through decision tree construction (Wang, 2024). Another example is the use of Classification and Regression Trees (CART) algorithm to handle complex data in speech recognition (Raju and Kumari, 2024). Random forest methods improve classification accuracy and robustness by constructing multiple decision trees and aggregating their votes. This approach demonstrates superior speech recognition performance. For example, random forest algorithms combine multiple classification results to enhance overall recognition rates (Rokach, 2016). Another example is the use of random forests to show high robustness in processing speech signals in noisy environments (Reddy and Pachori, 2024). Support Vector Machines (SVM) classify data by constructing hyperplanes in high-dimensional spaces, effectively handling nonlinear speech data. For example, SVM is used to distinguish different phonemes in speech signals (Cedeno-Moreno et al., 2024). Another example is improving recognition accuracy and efficiency by processing large volumes of speech data with SVM (Kanisha et al., 2024). However, these methods have the drawbacks of long model training times and high computational resource requirements.
To address the issues of long model training times and high computational resource demands in statistical and machine learning-based speech recognition, deep learning algorithms have been employed in English speech recognition. These methods primarily involve constructing multi-layer neural networks and integrating multimodal data, offering advantages such as automatic feature extraction and strong capability to handle complex data. For instance, Convolutional Neural Networks (CNNs) excel in feature extraction and classification of speech signals through hierarchical structures. They have shown outstanding performance in speech recognition tasks, such as classifying spectrograms of speech signals using CNNs (Ilgaz et al., 2024). Another example is the use of deep CNNs to process large amounts of speech data, which improves accuracy and efficiency in speech recognition (Abdel-Hamid et al., 2014). Reinforcement learning methods optimize model strategies through reward mechanisms, demonstrating good adaptability in dynamic and complex environments. For example, reinforcement learning can be used to optimize parameter configurations in speech recognition systems (Yang et al., 2024). Another example is applying deep reinforcement learning to continuous speech recognition tasks (Li et al., 2016). Transformer models handle sequence data through self-attention mechanisms and have shown excellent performance in speech recognition. For instance, Transformer models achieve efficient sequence-to-sequence speech conversion (Ryumin et al., 2024). Another example is using the Transformer architecture to improve the robustness and accuracy of speech recognition (Bahdanau et al., 2016). However, these methods come with the drawbacks of high computational resource consumption and increased model complexity.
To address the issues of high computational resource consumption and model complexity, we propose our approach: EnglishAL-Net: a Multimodal English Speaking Robot Driven by Neural Machine Translation. Traditional speech recognition methods face several limitations, such as limited ability to handle complex and variable speech environments, time-consuming and labor-intensive knowledge base construction, and high computational resource demands. The ALBEF (Align Before Fuse) model significantly reduces model complexity and computational requirements by aligning multimodal information before fusion, addressing the excessive computational overhead caused by modality fusion in traditional methods. The NMT (Neural Machine Translation) model has significant advantages in language conversion and generation, effectively tackling the non-linearity and complexity challenges in speech signals. Combining these two approaches enables more effective English oral communication for robots. Additionally, the cross-attention mechanism further enhances the accuracy and robustness of speech recognition and generation by establishing associations between different modalities, solving the problem of low recognition accuracy due to insufficient information sharing between modalities in traditional methods. The motivation behind this research is that current speech recognition systems perform poorly in complex environments and have high computational demands. By combining multimodal data and advanced attention mechanisms, we can significantly improve system performance and application scope, thus providing stronger support for natural communication between robots and humans.
• The EnglishAL-Net is introduced combined with the cross-attention mechanism to align multi-modal information before fusion, significantly reducing model complexity and computing requirements.
• This method performs well in multiple scenarios, is efficient and versatile, and can achieve high-precision speech recognition in both noisy and quiet environments.
• Experimental results show that the system using this method is significantly better than the traditional method in terms of speech recognition accuracy and robustness, and still maintains efficient performance in complex environments.
2 Related work 2.1 Speech recognitionThe origins of speech recognition technology date back to the 1950s, but significant progress has been made in recent decades, largely due to advancements in deep learning and big data. Early systems relied on finite state machines and Hidden Markov Models (HMMs) (Rabiner, 1989), which were effective for small-scale (Voß et al., 2024), domain-specific tasks but struggled with complex and large-scale speech data. With the advent of the 21st century, machine learning technologies like Support Vector Machines (SVMs) and Artificial Neural Networks (ANNs) began to transform the field. The introduction of Deep Neural Networks (DNNs), including Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), greatly enhanced speech recognition performance. RNNs, along with Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), improved accuracy by capturing time-series data dependencies (Zhu et al., 2024). Recently, Transformer models, known for their attention mechanisms, have brought new advancements to speech recognition. Models like DeepSpeech and wav2vec 2.0, based on Transformers, excel even in noisy or resource-constrained environments. The rise of end-to-end speech recognition methods has further simplified the process by removing the need for complex feature engineering. These methods use a unified neural network architecture to convert raw audio into text, streamlining system design and optimization (Jin et al., 2024b).
2.2 MultimodalityThe development of multimodal technology aims to replicate how humans naturally understand and process information by integrating data from different sensory modalities (such as vision, hearing, touch, etc.), enhancing machine perception and decision-making capabilities. Early multimodal research primarily focused on optimizing individual modality performance, often overlooking the synergistic effects of integrating multiple modalities (Jin et al., 2024a). With advancements in computational power and the widespread use of deep learning, multimodal technology has begun to show significant potential. Convolutional neural networks (CNN) and recurrent neural networks (RNN) have made notable progress in handling visual and language information, enabling cross-modal information fusion. For example, tasks like image captioning and visual question answering combine visual and language data to automatically generate image descriptions and answer questions based on image content (Wang et al., 2021a). Recently, the introduction of transformer models has further advanced multimodal technology. Transformer models, based on attention mechanisms, can simultaneously process and integrate information from different modalities, such as visual-language pre-training models (VLP) and BERT4Video for video understanding. These models, through pre-training and fine-tuning, excel in multiple multimodal tasks, demonstrating strong cross-modal understanding and generation capabilities (Jingning, 2024). Moreover, multimodal technology has made significant strides in practical applications. In autonomous driving, the fusion of multimodal sensor data (such as lidar, cameras, and radar) enhances environmental perception accuracy and robustness. In medical diagnostics, multimodal analysis combining imaging, pathology, and genetic data provides more comprehensive and precise diagnostic results (Wang et al., 2021b). Looking ahead, the development of multimodal technology will focus on more efficient cross-modal fusion methods, larger-scale pre-training models, and more versatile and flexible multimodal systems. These advancements will further drive the application of multimodal technology in natural language processing, computer vision, robotics, and other fields, enabling machines to understand and interact with complex multimodal information more naturally and intelligently (Chen et al., 2024).
2.3 Cross-attention mechanismsCross-attention mechanisms are crucial in deep learning for enhancing model performance and generalization by creating dynamic associations between different modalities or levels. Their applications span various fields, including natural language processing, computer vision, and multimodal fusion. In natural language processing, cross-attention is vital for tasks like machine translation and text generation. In transformer models, cross-attention layers enable flexible focus on different parts of the encoder's output during decoding, leading to smoother and more accurate translations. Pre-trained language models such as BERT and GPT also use cross-attention to capture and utilize contextual information (Prasangini and Nagahamulla, 2018), significantly boosting performance across various NLP tasks (Koyama et al., 2020). In computer vision, cross-attention mechanisms are used in object detection, image segmentation, and image generation. For example, they help models identify and locate objects in complex scenes more accurately, and Vision Transformers (ViT) use attention between image patches to improve feature extraction compared to traditional convolutional neural networks. Multimodal fusion benefits from cross-attention by integrating and complementing information across different modalities, such as images, text, and audio (Jin et al., 2023). In visual question answering (VQA) and image captioning, cross-attention mechanisms allow models to focus on relevant parts of both questions and images or regions of images while generating text. Additionally, cross-attention shows promise in recommendation systems and medical diagnostics. It can link user and item features for more personalized recommendations and integrate imaging, genetic, and clinical data to enhance diagnostic accuracy and reliability.
3 Method 3.1 Overview of our networkIn this paper, the proposed EnglishAL-Net model enhances the robot's ability to process visual and auditory inputs by leveraging Neural Machine Translation (NMT) (as shown in Figure 1). EnglishAL-Net combines the strengths of the ALBEF-NMT model and a cross-attention mechanism to improve semantic understanding. ALBEF (Align before Fuse) is a multimodal learning method that aligns and fuses data, particularly suited for visual and textual inputs. This approach processes each modality's data separately before using alignment mechanisms to ensure high semantic consistency between different modalities. Finally, the fused data is further processed, enabling EnglishAL-Net to understand and respond more accurately to complex spoken instructions in various environments.
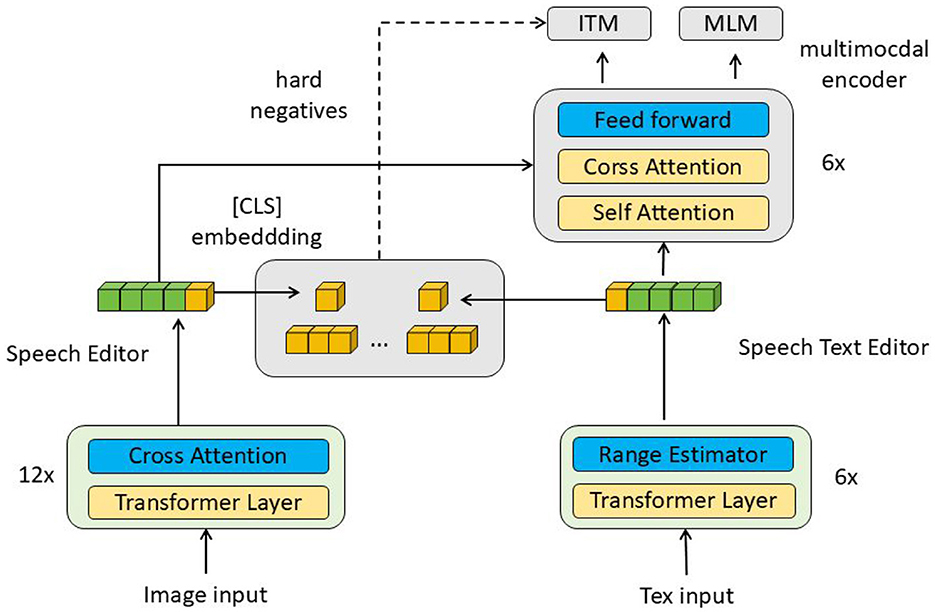
Figure 1. Overall framework diagram. The data flow in the figure starts from the image and text input, and is processed by multiple layers of cross-attention and transformer respectively, and then fused through the multimodal encoder, and the final output is used for ITM and MLM tasks.
EnglishAL-Net improves the speed of autoregressive correction models by using a non-autoregressive (NAR) generation technique coupled with alignment-based editing. Initially, it calculates the Levenshtein distance between the source sentence (recognized text) and the target sentence (reference text). By analyzing the insertions, deletions, and substitutions indicated by the Levenshtein distance, it determines the number of target tokens corresponding to each source token post-editing. Specifically, a deletion is marked by 0, no change or substitution by 1, and an insertion by values of 2 or more. EnglishAL-Net employs a non-autoregressive (NAR) encoder-decoder structure and incorporates a range estimator to manage length discrepancies between the source sequence (encoder) and the target sequence (decoder). This range estimator is trained to adjust each source token as necessary, ensuring the correct number of target tokens. These adjusted source tokens are then processed by the decoder in parallel. Subsequent sections will discuss the alignment-based editing, model architecture, and pre-training methods used in EnglishAL-Net.
The ALBEF (Align Before Fuse) model was optimized by focusing on the alignment of multimodal data before fusion, reducing computational overhead and improving real-time performance. Specifically, we fine-tuned the cross-attention layers to ensure that the alignment between text and visual inputs is efficient. We implemented dynamic weight adjustments to prioritize high-confidence modality inputs, which helps the model process ambiguous or noisy data more effectively. This optimization significantly reduces computational costs, especially in scenarios with large, complex datasets.
The newly designed text and image editor integrates seamlessly with the ALBEF model by leveraging alignment-based mechanisms. This editor is built to support dynamic editing of both textual and visual content in real-time, ensuring that contextual and semantic relationships between modalities are preserved. It works by first segmenting both text and images into meaningful units (words, phrases, image regions) and then applying cross-modal attention to match corresponding elements. We also incorporated an error detection and correction mechanism based on Levenshtein distance, allowing the editor to automatically refine outputs based on alignment quality between the recognized input and reference data.
In EnglishAL-Net, multimodal data–such as text and image inputs–are integrated through an optimized version of the ALBEF (Align Before Fuse) model. The key steps in this integration process are as follows: Initially, the input modalities (text and image) are processed separately through dedicated encoders. For text, we use a transformer-based encoder that captures the semantic information from the input. For images, a convolutional neural network (CNN) is used to extract visual features, generating a feature map that represents different parts of the image. After encoding, the ALBEF model ensures that the features from both modalities are aligned before they are fused. This alignment is crucial for preserving the semantic relationship between the text and image data. Specifically, we use a cross-attention mechanism that aligns the relevant parts of the image to the corresponding text elements, ensuring that the information from both modalities is contextually related before fusion. The cross-attention layers allow the model to focus on the relevant parts of each modality that are most informative for the task at hand. For example, when processing a spoken command alongside an image, the cross-attention mechanism identifies which part of the image is relevant to the spoken words and aligns them. This dynamic attention helps reduce irrelevant information and emphasizes the meaningful connections between modalities. Once the alignment is completed, the fused multimodal representation is formed by combining the aligned text and image features. The fused representation is then processed through the remaining network layers, allowing EnglishAL-Net to generate a response or perform the required task with a deeper understanding of the multimodal input. After the fusion, the multimodal representation is fed into a neural machine translation (NMT) module to generate the final output. This step is particularly useful for tasks like speech recognition and response generation, where the output is based on the combined understanding of both text and visual inputs. Additionally, a real-time text and image editor refines the results, ensuring higher precision and coherence. This structured approach to multimodal integration significantly improves the model's ability to handle complex tasks that involve both language and visual data, ensuring that EnglishAL-Net can robustly process and respond to a wide range of inputs. The combination of alignment before fusion and cross-attention enables the model to make more accurate associations between modalities, resulting in enhanced performance across different domains.
3.2 Edit alignment 3.2.1 Calculating edit pathEdit distance is a metric used to measure the difference between two sentences by calculating the minimum number of edit operations required to transform the source sentence into the target sentence. These operations include inserting, deleting, and substituting tokens. Assume that the source sentence is X = (x1, x2, …, xP), and the target sentence is Y = (y1, y2, …, yQ), where P and Q denote the length of the source and target sentences, respectively. We can recursively calculate the edit distance of the prefix sentences to obtain the edit distance between X and Y. The specific formula is as follows:
F(p,q)=min{F(p-1,q)+1F(p,q-1)+1F(p-1,q-1)+λ(xp,yq) (1)The function F(p, q) represents the minimum edit distance between the source prefix sentence (x1, x2, …, xp) and the target prefix sentence (y1, y2, …, yq). Here, p and q are indices representing the length of the current prefixes of the source and target sentences, respectively.
Explanation of p and q:
1. Role of p and q: - p is the length (or index) of the prefix of the source sentence X, so it ranges from 0 to P, where P is the total length of the source sentence. - q is the length (or index) of the prefix of the target sentence Y, and it ranges from 0 to Q, where Q is the total length of the target sentence.
2. Limits of p and q: - The values of p and q must lie within the bounds of the lengths of the source and target sentences. That is:
0≤p≤P and 0≤q≤Q (2)- If p = 0, the prefix of the source sentence is empty, and similarly, if q = 0, the prefix of the target sentence is empty. These cases are handled by the boundary conditions:
F(p,0)=p and F(0,q)=q (3)- This represents the edit distances when one sentence is entirely empty.
3. What happens at F(0, 0): - F(0, 0) corresponds to the case where both the source and target prefixes are empty. The edit distance between two empty strings is naturally 0, so:
- This is consistent with the boundary conditions, as no operations are required to transform an empty string into another empty string.
To determine edit alignments between tokens in source and target sentences, we follow a structured approach. Initially, we evaluate the alignment score for each edit path, calculated by the number of unchanged tokens retained, and select the path with the highest score. This score reflects the path's quality by preserving more source tokens. Subsequently, we derive the set of edit alignments A, which encompasses all possible alignments between the source and target sentences. The extraction process adheres to the following principles: 1) For deletions, source tokens align with empty target tokens ∅. 2) For substitutions or identities, source tokens align with the corresponding target tokens, irrespective of whether they are unchanged or altered. 3) For insertions, target tokens, which lack corresponding source tokens, align with the adjacent left or right source tokens, creating various edit alignments.
In the final step, we choose the optimal edit alignment a from A by evaluating the n-gram frequency of the aligned target tokens. We first compile an n-gram frequency table F that logs the occurrence counts of each n-gram within the training corpus. The frequency score Scorefreq(a) for each alignment a∈A is computed using the formula:
Scorefreq(a)=∑j=1NFreq(a[tj]); Freq(y)={F[y],if len(y)>10,if len(y)≤1 (5)where a[tj] signifies the source token aligned to target token tj under alignment a, N denotes the total number of tokens in the target sentence, len(y) is the word count in y, and F[y] provides the frequency of y from the n-gram table F. Focusing on unique token combinations, all 1-grams are assigned a frequency of 0. The alignment a∈A with the highest frequency score is selected as the final edit alignment, promoting alignments of source tokens with more frequent n-gram target tokens.
3.3 Model structureIn EnglishAL-Net, we adopt ALBEF as the base multimodal model for handling English speech recognition tasks. The ALBEF model operates by aligning and fusing visual and textual modalities to enhance the understanding and generation capabilities of machines in multimodal tasks. The alignment step matches visual inputs (such as images or videos) with textual inputs (such as natural language), ensuring the model can correlate them effectively. The fusion step then integrates these aligned representations, allowing the model to utilize both visual and textual information for more accurate and comprehensive task processing. The fundamental principle of ALBEF can be represented by the following formula:
ALBEF(I,T)=Fuse(Align(I,T)) (6)In this formula: - ALBEF(I, T) represents the multimodal output generated by the model for a given visual input I and text input T. - I denotes the visual input. - T denotes the text input. - Align(I, T) represents the alignment operation. - Fuse(·) represents the fusion operation.
3.3.1 Speech text editorIn the EnglishAL-Net text editing task, we propose a new architecture called the Speech Text Editor to replace the original text editor in ALBEF. The architecture of the Speech Text Editor is described as follows: We employ the Transformer architecture as the foundational model for our speech-to-text editor. The encoder processes the input source sentences, generating a hidden sequence. This sequence serves two primary functions: 1) It is used by the input range estimator, which forecasts the count of target tokens for each source token (based on the edit alignment discussed earlier). 2) It is fed to the decoder via the encoder-decoder attention mechanism. The detailed structure of the range estimator can be found in the subgraph on the left of Figure 2, and it is trained using Mean Squared Error (MSE) loss.
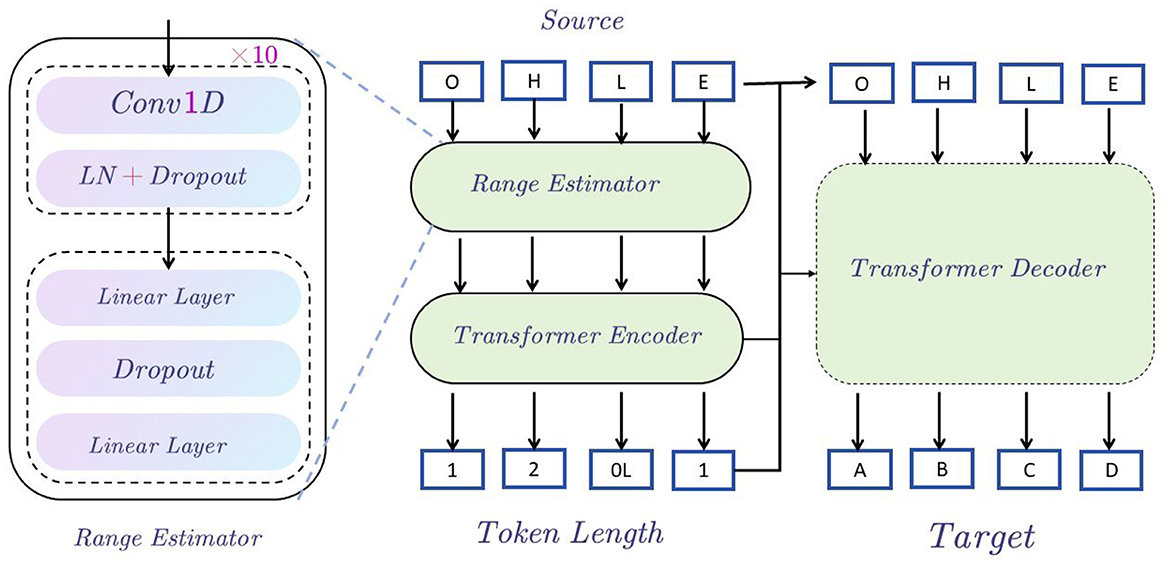
Figure 2. Speech text editor structure diagram. The figure shows that starting from the Source input, the data is encoded through the Range Estimator and Transformer Encoder, then enters the Transformer Decoder, and finally generates the Target output, indicating the sequence generation process from input to output.
The overall model architecture can be mathematically formulated as follows:
1. Hidden sequence generation:
Where: - X denotes the input source sentence. - H represents the hidden sequence produced by the encoder.
2. Length prediction:
L=LengthPredictor(H) (8)Where: - L signifies the predicted length sequence of target tokens associated with each source token.
The range estimator is trained using the mean squared error (MSE) loss:
LMSE=1N∑i=1N(Li-L^i)2 (9)Where: - Li represents the predicted length of the i-th source token. - L^i represents the actual length of the i-th source token. - N represents the total number of tokens in the source sentence.
3. Decoder attention mechanism:
Y=Decoder(H,L,Attention(H,S)) (10)Where: - Y represents the output target sentence. - S is the source sentence used in the attention mechanism. - Attention(H, S) denotes the attention mechanism applied between the hidden sequence H and the source sentence S.
4. Error identification and rectification:
Errors involving deletions and insertions can be discerned by predicting the source token's corresponding length as 0 or greater than 1. Errors of substitution can be identified when the predicted length of the source token is 1. The decoder utilizes target tokens to distinguish between substitution errors and unchanged tokens.
L~i={0if deletion>1if insertion1if substitution or unchanged (11)This methodology simplifies the error correction process by enabling the range estimator to pinpoint error patterns precisely and allowing the decoder to concentrate on modifications.
In the formula, Li represents the predicted length of the target token(s) corresponding to the i-th source token. Specifically, when Li>1, this corresponds to an insertion operation, indicating that more than one target token is aligned with the i-th source token.
Clarification on Li>1:
When Li>1, it means that multiple target tokens are inserted relative to a single source token. The exact value of Li reflects how many target tokens are inserted:
- For example, Li = 2 implies that 2 target tokens are inserted in place of the i-th source token. - Similarly, Li = 3 would mean 3 target tokens are inserted.
The value of Li greater than 1 does not have a fixed upper limit but depends on how many target tokens are required for the insertion process in the specific case. This clarifies that Li>1 represents an insertion, with the exact value of Li indicating how many target tokens are inserted in place of the source token.
Speech editor
To further enhance EnglishAL-Net, we introduce the Speech Editor, which replaces ALBEF's original image editor. The Speech Editor adopts a Neural Machine Translation (NMT) structure optimized with a cross-attention mechanism, providing robust text editing capabilities tailored for speech recognition tasks. Neural Machine Translation (NMT) (Stahlberg, 2020) models are machine translation models based on neural networks, which primarily use these networks to facilitate automatic translation (Mohamed et al., 2021). NMT models function by converting sentences from a source language into a target language, thus achieving automatic translation between languages. The NMT model in our Speech Editor adopts the following structure and principles: Encoder-Decoder Structure (as shown in Figure 3): the NMT models employ an encoder-decoder structure. The encoder transforms input sentences from the source language into a fixed-length vector representation, while the decoder generates the translation results in the target language based on this vector.
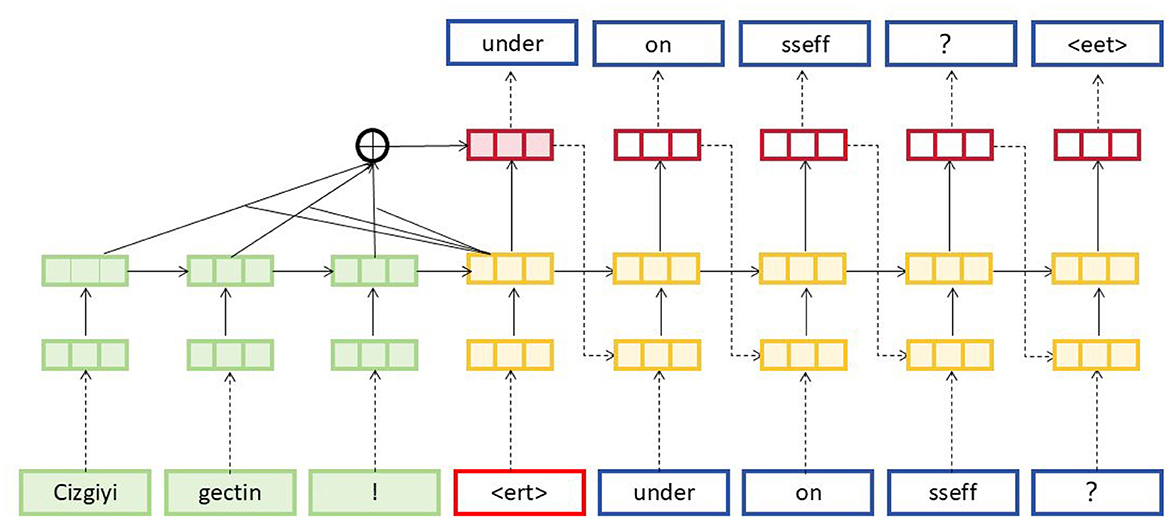
Figure 3. NMT model structure diagram. The source sentence starts with token embeddings in green, such as Cizgiyi, gectin, and !. These pass through the network layers, combining into attention layers. The generated target sequence predictions in blue, such as under, on, and sseff, are produced step-by-step with cross-attention on previous tokens, represented by the different colored layers.
Cross-Attention Mechanism (as shown in Figure 4): To optimize the translation process, the Speech Editor incorporates a cross-attention mechanism (Zhang and Feng, 2021). This mechanism facilitates interaction and alignment between the source and target languages by dynamically combining the information through the calculation of attention weights. This enhances cross-linguistic information transfer and alignment.
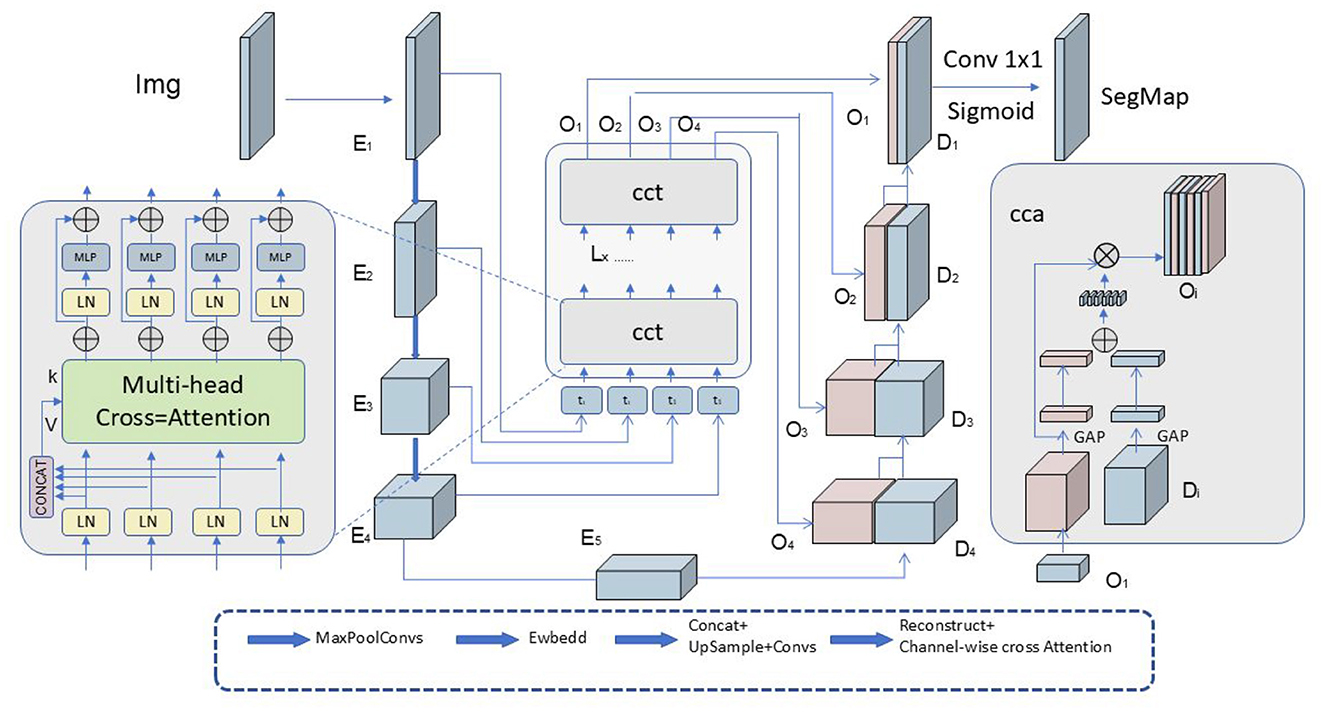
Figure 4. Diagram illustrating the cross-attention mechanism. The image Img passes through multiple layers: E1, E2, E3, E4, E5, then enters the Multi-head Cross-Attention module. The outputs O1, O2, O3, O4 flow through CCT layers. Results pass to concatenation layers and form segmentation map SegMap.
In this formula: ŷ is the predicted translation output of the target language sentence. y represents the candidate translation of the target language sentence. X is the input source language sentence. P(y|X) denotes the probability of the target language sentence y given the source language sentence X. The NMT model trains a neural network to transform the source language sentence X into a probability distribution over the target language sentence y. Based on the source language sentence X, the target sentence ŷ with the highest probability is selected as the predicted translation.
CrossAttention(Q,K,V)=softmax(QKTdk)V (12)In this formula: - Q: query vector, used for calculating attention weights. - K: key vector, also used for calculating attention weights. - V: value vector, used to produce the weighted combination result. - dk: dimension of the key vector, used for scaling attention weights.
The cross-attention mechanism initially computes attention scores by taking the inner product of the query vector Q and the key vector K. These scores are then normalized using the softmax function to produce attention weights. Finally, the output is derived by calculating the weighted sum of the value vector V with these attention weights. By incorporating the Speech Editor, which utilizes an NMT framework optimized with cross-attention mechanisms, EnglishAL-Net is capable of managing intricate multimodal English speech recognition tasks. This combination enhances the model's proficiency in performing end-to-end translation, capturing semantic and contextual information to deliver accurate and fluent translations. Ultimately, this facilitates automatic language generation and improves the efficiency and effectiveness of the multimodal speech recognition system.
Although speech recognition technology is often regarded as a subfield of natural language processing (NLP), in fact, it has independent and broad applications within machine learning, particularly in handling time-series data and sequence learning. Early speech recognition systems relied on rule-based and expert system methods (Kim and Woodland, 2000), such as Hidden Markov Models (HMM) and Gaussian Mixture Models (GMM). While these approaches were effective in certain scenarios, their limitations became evident as the complexity of speech data increased. With the rapid advancement of deep learning, Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Long Short-Term Memory networks (LSTM), and, more recently, Transformer models have been introduced into the field of speech recognition, significantly improving model accuracy and robustness. Speech recognition is particularly strong in sequence learning. Speech signals are essentially time-series data, and machine learning, especially deep learning, excels at extracting complex temporal dependencies when processing sequence data. Therefore, research in speech recognition not only drives advancements in sequence modeling techniques but also inspires progress in other tasks requiring time-series data processing, such as financial data analysis, bioinformatics, sensor data processing, and more. Additionally, speech recognition is widely used in multimodal interactive systems. As machine learning progresses toward multimodal applications, speech recognition is often combined with other modalities such as vision and text. For example, in autonomous driving, intelligent customer service, and smart home scenarios, speech, vision, and text together form essential input modes for systems to understand the external environment. Through cross-modal learning (e.g., vision-language joint learning), machine learning systems can simultaneously process and comprehend information from different modalities, thereby enhancing the naturalness and efficiency of human-computer interaction. In this process, speech recognition plays a crucial role, enabling systems not only to "understand" the user's commands but also to integrate them with information from other modalities, resulting in more comprehensive and accurate perception and decision-making. With the upgrading of hardware devices and the continuous growth of data, future development trends in speech recognition include more efficient model architectures (such as self-supervised learning and few-shot learning), more lightweight inference models (such as TinyML), and deeper integration with other modalities. These trends suggest that speech recognition is not only an important component of natural language processing but also an indispensable key technology within the entire machine learning ecosystem for handling complex, multimodal data.
Pepper (Pande et al., 2024) is a social humanoid robot developed by SoftBank Robotics, which is designed to interact with humans using multimodal data fusion. It integrates speech recognition, facial recognition, and gesture analysis to facilitate natural communication. By incorporating multimodal inputs, Pepper is able to respond to human emotions and social cues, making it a valuable reference for understanding how robots utilize data from different modalities to enhance interaction, much like how EnglishAL-Net combines speech, text, and visual inputs.
Sophia (Parviainen and Coeckelbergh, 2021), developed by Hanson Robotics, is another advanced humanoid robot known for its ability to pro
留言 (0)