
記住我
In recent years, the application of multimodal educational robots in the field of education has received widespread attention. Multimodal educational robots not only enhance students' learning experiences through various senses such as vision and hearing but also improve students' learning motivation and engagement through human-machine interaction (Liang and Hwang, 2023). Additionally, multimodal educational robots can integrate artificial intelligence technologies to achieve personalized teaching and intelligent tutoring, thereby better meeting the learning needs of different students (Lin et al., 2022). Therefore, researching the application and development of multimodal educational robots not only helps improve the quality and efficiency of education but also promotes innovation and advancement in educational technology (Tozadore and Romero, 2020).
Traditional approaches primarily rely on symbolic AI and knowledge representation to implement the functions of multimodal educational robots. Firstly, expert systems simulate the decision-making process of human experts by encoding their knowledge. They are highly interpretable and can provide explicit reasoning for each recognition result. For example, Cheng et al. (2022) proposed a knowledge-based expert system for human action analysis in educational robots. Additionally, a comprehensive review by Zhao (2023) showcases various applications and developments of expert systems in the field of education. Secondly, rule-based methods utilize a set of predefined rules for action recognition and interaction of educational robots. These methods exhibit high determinism and reliability, performing well in complex or dynamic educational scenarios. Lin and Zou (2022) introduced a rule-based system for automated educational analysis, while Xu and Yan (2020) presented a rule-based framework for analyzing student learning performance. Furthermore, logistic regression, as a statistical method, learns features from training data to make classification decisions. It has important applications in action recognition for educational robots and significantly improves classification accuracy. Sun and Ma (2021) demonstrated the application of logistic regression in educational robots, while Pang (2022) further investigated action analysis in educational science, using logistic regression models to enhance recognition accuracy. These methods offer advantages such as strong interpretability and transparency in the decision-making process. However, these methods have limitations in handling complex and dynamic actions, as well as limited capabilities in processing large-scale data.
To address the limitations of interpretability and performance in handling complex and dynamic actions, data-driven and machine learning algorithms have been applied to multimodal educational robots, primarily focusing on learning features from large amounts of data and performing pattern recognition. These approaches offer advantages such as automation, efficiency, and high accuracy. Firstly, Support Vector Machines (SVM) are widely used for classification tasks and can effectively handle high-dimensional data. Ng et al. (2020) demonstrated the application of SVM in educational robots, achieving precise recognition of student behaviors through accurate classification. Additionally, Sarker (2023) proposed an SVM-based system for student emotion detection, significantly improving the accuracy of emotion recognition. Secondly, Random Forest, as an ensemble learning method, improves classification stability and accuracy by constructing multiple decision trees. Ossai (2019) showed the effectiveness of Random Forest in predicting student performance. Another study by Yağcı (2022) showcased the strong performance of Random Forest in educational data analysis. Lastly, Multilayer Perceptron (MLP), as a neural network structure, can learn complex nonlinear relationships. Mamatnabiyev et al. (2024) demonstrated the superiority of MLP in predicting student grades. Furthermore, Deyzel and Theart (2023) validated the effectiveness of MLP in educational robots, significantly enhancing the robot's understanding and responsiveness to student behaviors. However, these methods have limitations in their high dependency on large-scale data and long model training times.
To address the limitations of statistical and machine learning algorithms in handling complex and dynamic actions, deep learning-based algorithms have been applied to multimodal educational robots. These algorithms primarily rely on extracting high-level features and performing pattern recognition from large datasets. This approach offers advantages such as automation, efficiency, and high accuracy. Firstly, Convolutional Neural Networks (CNNs) have been widely used for image and video processing, enabling high-precision action recognition through hierarchical feature extraction. Yoshizawa et al. (2020) utilized CNN models to analyze students' facial expressions for estimating confusion levels. Additionally, Robinson and Nejat (2023) research showcased the application of CNNs in multimodal inputs within a home environment, supporting the daily activities of older adults. Secondly, reinforcement learning has significantly improved the autonomy and adaptability of educational robots by learning optimal strategies through interaction with the environment. Elgajiji (2015)'s research demonstrated the application of reinforcement learning in multimodal robot communication systems. Yang et al. (2021) compared multiple deep learning methods for multimodal anomaly detection and found that reinforcement learning models based on Long Short-Term Memory (LSTM) performed best in terms of efficiency and accuracy. Lastly, Transformers, as models based on attention mechanisms, achieve efficient information processing by capturing global dependencies. Ye et al. (2023) proposed a real-time object detection method based on Transformers. Ortega and Faisal (2021)'s research showcased the application of attention mechanisms in multimodal signal fusion, improving the decoding of EEG and fNIRS signals for handgrip force estimation. However, these approaches suffer from the limitations of high dependency on large-scale data and high computational complexity.
This paper proposes a method that combines ALBEF (Align before Fuse), VGG19 (Visual Geometry Group), and a dynamic attention mechanism to evaluate and optimize the educational capabilities of multimodal robots. Firstly, we use the ALBEF method to preprocess visual and textual data to enhance the understanding and alignment of visual and textual information. ALBEF improves the matching and consistency of multimodal information by aligning visual and textual data before fusion. Then, we introduce the VGG19 model as a feature extractor to extract feature representations of image data. VGG19 is a classic convolutional neural network architecture known for its excellent performance in image classification and feature extraction. Next, we employ a dynamic attention mechanism to further enhance the perception and understanding capabilities of multimodal information. The dynamic attention mechanism can automatically learn the key parts of the input data and focus on important information, thereby improving the model's performance and effectiveness. By integrating ALBEF, VGG19, and the dynamic attention mechanism, we construct a multimodal robot education model and perform training and optimization.
To address the challenges of high computational complexity and long model training time, this paper proposes Res-ALBEF: a dynamic attention-driven multimodal educational robot that aims to address the alignment and processing of multimodal data in educational robots. Firstly, the ALBEF method preprocesses visual and textual data to enhance their understanding and alignment, thus improving the consistency of multimodal information. Secondly, the VGG19 model serves as a feature extractor for image data. Lastly, the dynamic attention mechanism automatically identifies and focuses on the important parts of the input data, thereby improving the overall effectiveness of the model. By integrating ALBEF, VGG19, and the dynamic attention mechanism, Res-ALBEF significantly enhances the educational capabilities of multimodal robots.
The three contributions of this paper are as follows:
• The proposed method introduces a novel multimodal network architecture called Res-ALBEF, which presents a new approach for the alignment and processing of multimodal data in educational robots.
• This method is efficient and versatile, suitable for various educational scenarios, ensuring robust performance across different tasks, and environments.
• Experimental results demonstrate a significant enhancement in the educational capabilities of multimodal robots, showcasing improved alignment, feature extraction, and attention mechanisms.
2 Related work 2.1 Multimodal perception and understandingMultimodal perception and understanding is a key direction in the field of multimodal robot education. By integrating various sensory modalities such as vision, hearing, and touch, multimodal robots can more comprehensively perceive the learning environment and the state of the students, thus providing a richer and more personalized educational experience (Braud et al., 2020). Researchers face many challenges in this direction, including the alignment of multimodal data, feature extraction and representation learning, and how to use multimodal information to understand and generate educational content (Hong et al., 2024). Firstly, the alignment of multimodal data is a significant issue. Data from different sensory modalities have different formats and characteristics, such as images, speech, and text. Researchers need to explore effective methods to align these data so that information from different modalities can match and integrate. For example, alignment networks or adversarial generative networks can be used to achieve alignment and conversion between modalities (Yan et al., 2021). Secondly, feature extraction and representation learning are critical tasks for multimodal perception and understanding. Researchers need to design deep learning models or neural network architectures to extract meaningful feature representations from multimodal inputs. These features should capture the correlations and semantic information between different modalities, providing useful inputs for subsequent educational tasks. For instance, convolutional neural networks (CNNs) and recurrent neural networks (RNNs) can be used for feature extraction and sequence modeling. Furthermore, an important area of research is the utilization of multimodal information for comprehending and creating educational content. Researchers can investigate methods for combining visual, auditory, and textual information to enhance the understanding and context of educational materials. For example, attention mechanisms can be used to automatically learn the key parts of input data and focus on important information. Additionally, research can be conducted on how to generate multimodal educational responses, such as image descriptions and speech answers, to provide effective interaction capabilities with students (Lin et al., 2024).
2.2 Personalized and adaptive learningPersonalized and adaptive learning is another critical direction in the field of multimodal robot education. Traditional educational models often adopt a one-size-fits-all approach, which fails to meet the individual differences and learning needs of students. In contrast, multimodal robot education systems, equipped with perception and interaction capabilities, can provide personalized and adaptive educational services based on individual student characteristics, learning progress, and emotional states (Yan et al., 2022). Firstly, personalized education requires the use of multimodal robots to perceive and analyze students' individual characteristics. For instance, through visual perception, robots can recognize students' facial expressions and body language to understand their emotional states and levels of attention. Through auditory perception, robots can analyze students' voice features and speech rates, assessing pronunciation accuracy and fluency. Subsequently, multimodal robots need to design and optimize educational strategies and interaction methods based on students' individual characteristics and learning progress. For students with slower learning progress, robots can adopt more detailed and gentle explanations, providing additional support materials and practice opportunities. For students with faster learning progress, robots can offer more advanced and challenging learning content to stimulate their interest and motivation (Wang et al., 2021). Additionally, adaptive learning is a crucial component of personalized education. Multimodal robots can adjust teaching strategies and content in real time based on students' learning behaviors and feedback to provide the most suitable learning paths and educational resources. For example, robots can offer targeted feedback and tutoring based on students' incorrect answers and error patterns, helping them overcome difficulties and improve learning outcomes (Hong et al., 2024).
2.3 Human-robot collaboration and interactive learningHuman-robot collaboration and interactive learning is another important research direction in the field of multimodal robot education. Multimodal robots, acting as educational assistants and partners, need to engage in effective human-robot interactions and collaborations with students to facilitate learning and knowledge transfer. Research in this direction aims to design the expressions and interaction methods of robots so that they can communicate with students in a natural, intelligent, and effective manner (Wang et al., 2019). Firstly, researchers can explore how to design the language and non-verbal expression capabilities of robots. Robots need to have good language understanding and generation abilities to converse and interact with students. For example, robots can understand students' questions and needs, and respond appropriately, providing targeted explanations and guidance. Additionally, robots can interact with students through facial expressions, gestures, and postures, enhancing the richness of communication and emotional connection (Bera et al., 2020). Secondly, researchers need to focus on the cooperation and collaborative learning between robots and students. Multimodal robots can act as learning partners, working with students to solve problems, discuss learning content, and complete tasks and projects together (Ai et al., 2023). Through collaboration with robots, students can gain practical experience and develop hands-on skills, teamwork, and problem-solving abilities. Researchers can study how to design the cooperation strategies and interaction modes of robots to achieve efficient human-robot collaboration and interactive learning. Moreover, human-robot collaboration involves the robot's ability to adapt to the student's learning pace and style, providing personalized assistance and feedback. Robots can monitor students' progress and adjust their support accordingly, ensuring that students remain engaged and motivated. For instance, when a student struggles with a concept, the robot can offer additional explanations or alternative approaches, fostering a supportive learning environment (Lazaro et al., 2021).
3 Methodology 3.1 Overview of our networkThis study aims to evaluate and optimize the educational capabilities of multimodal robots using Res-ALBEF: A Multimodal Educational Robot driven by Dynamic Attention. Res-ALBEF combines ALBEF (Align Before Fuse) and VGG19 with a dynamic attention mechanism. ALBEF aligns text and visual representations to capture semantic relationships, while VGG19 extracts visual features from images or videos. The dynamic attention mechanism enables the model to focus on relevant parts of the input data based on task relevance. Figure 1 shows the overall framework diagram of the proposed method.
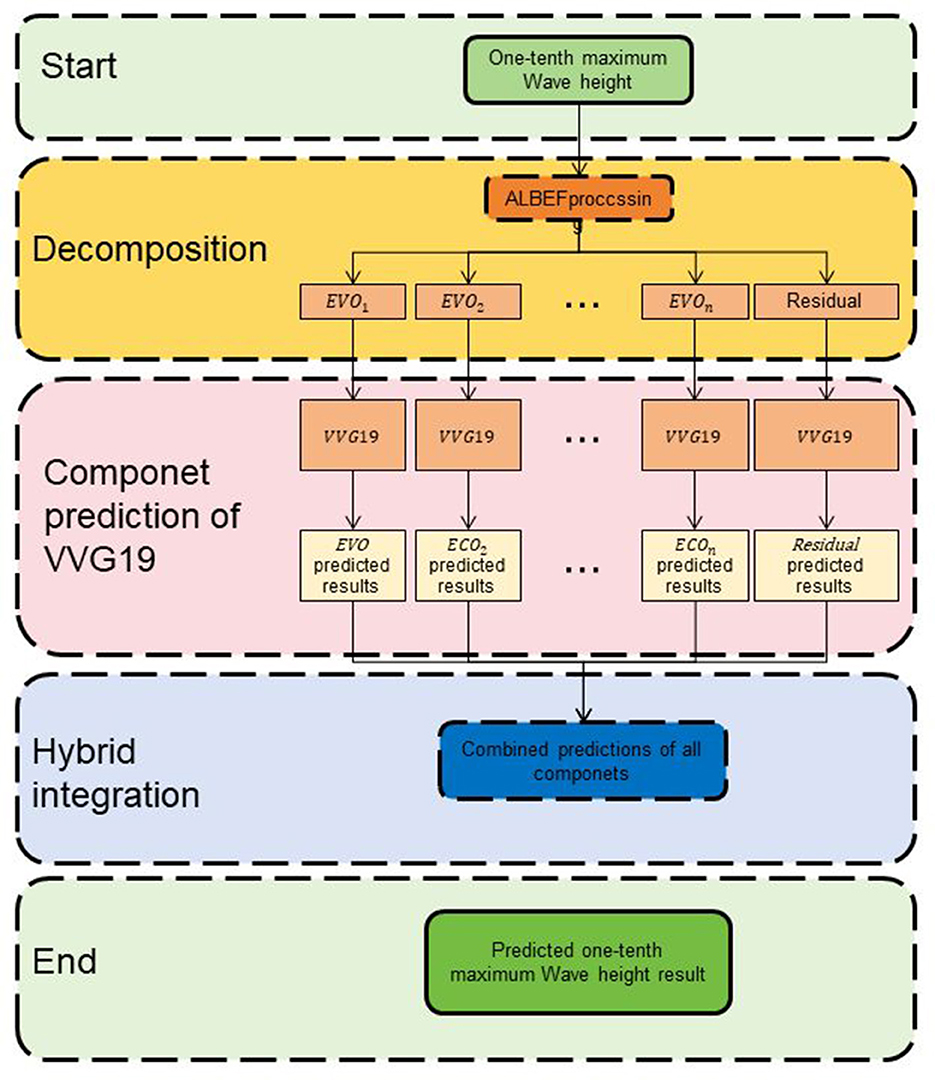
Figure 1. The overall framework diagram of the proposed method is presented.
3.2 Model architectureDesign a multimodal architecture that integrates ALBEF, VGG19, and a dynamic attention mechanism. This model should be capable of aligning text and visual representations, using VGG19 to extract visual features, and dynamically focusing on relevant information during educational tasks. In order to evaluate the performance of the multimodal educational robot model, we defined appropriate evaluation indicators. These indicators include: Accuracy, which evaluates the accuracy of the overall prediction of the model; Precision, which evaluates the proportion of correctly predicted positive samples among all predicted positive samples; Recall, which evaluates the proportion of correctly predicted positive samples among all actually positive samples; F1 Score, the harmonic mean of precision and recall, which comprehensively measures model performance. In addition, we also use the educational content understanding score to evaluate the accuracy and depth of the robot's understanding of educational content, and the response generation score to evaluate the relevance and effectiveness of the robot's generated responses in educational scenarios.
The main reason for combining ALBEF, VGG19, and dynamic attention mechanisms is that these three components bring complementary strengths to the processing of multimodal data. By working together, they overcome the current limitations in multimodal systems, particularly in data alignment, feature extraction, and information focus. This synergy enhances the overall performance of the system. ALBEF (Align Before Fuse) plays a crucial role by ensuring that different modalities, visual and textual information are aligned before being fused. In multimodal tasks, visual, and textual data often have distinct representations, and fusing them prematurely can lead to mismatched or lost information. ALBEF provides a mechanism to align these modalities in a high-dimensional feature space, enabling better understanding and interaction between them. This alignment is particularly critical for educational robots, where student behaviors and expressions (visual data) must be accurately linked with course content (textual data) to enable the robot to respond appropriately.
VGG19, a powerful image feature extractor with a deep convolutional structure, extracts fine-grained visual features, especially in complex visual inputs. It captures multi-level image information such as edges, shapes, and objects, providing a strong foundation for handling visual data. In scenarios where educational robots need to analyze visual scenes or student facial expressions, VGG19 ensures the extraction of highly accurate visual features, which, when combined with ALBEF's alignment process, leads to more efficient and precise multimodal fusion. Finally, the dynamic attention mechanism dynamically adjusts the model's attention based on the characteristics of the input data, focusing computational resources on the most relevant information. This is essential for multimodal data processing, as only portions of the visual or textual input may be highly relevant to the current task. The dynamic attention mechanism filters out irrelevant noise, allowing the model to focus on key aspects of the data, thereby improving processing efficiency and accuracy. Together, these three components form a cohesive system: ALBEF ensures proper alignment of the modalities, VGG19 provides rich visual features, and the dynamic attention mechanism focuses on the most critical information, creating a robust, flexible, and efficient framework for multimodal data processing, particularly in educational robotics.
3.3 ALBEFThe ALBEF (Align before Fuse) (Li et al., 2021) model's fundamental principle is to align textual and visual representations before fusing them in multimodal tasks (Zeng et al., 2021). This method aims to capture the semantic relationships between text and visual data to enhance the understanding of multimodal information. Figure 2 is a schematic diagram of the principle of ALBEF Model.
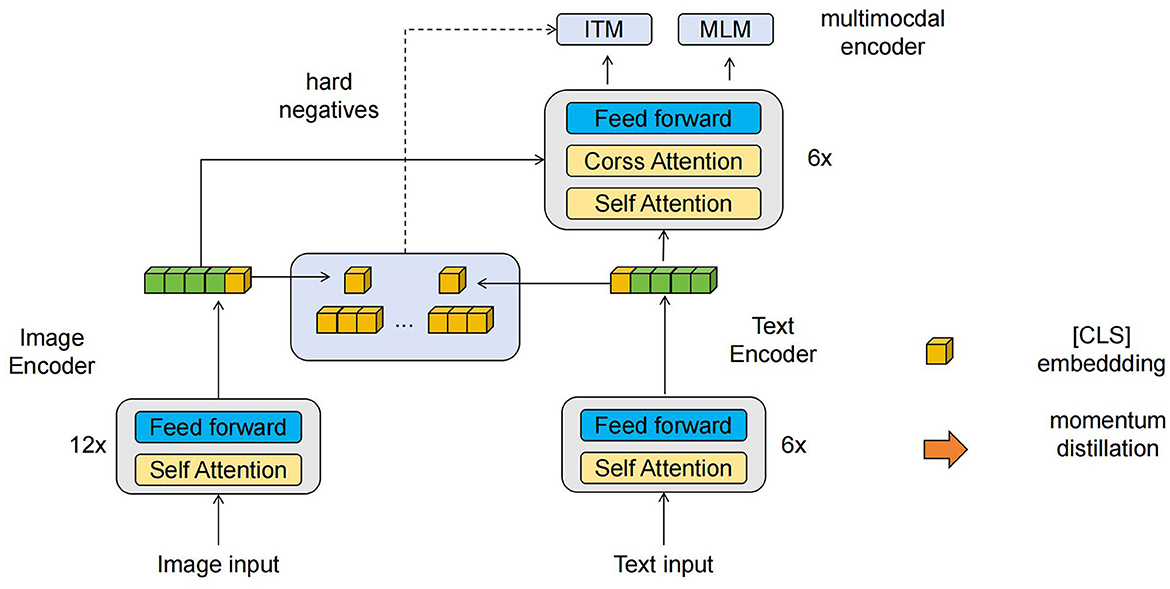
Figure 2. A schematic diagram of the principle of ALBEF Model.
In multimodal tasks, there often exists an information mismatch between text and visual data. For example, when describing an image, the text can provide a semantic description of the image's content, while visual information offers more intuitive visual features. ALBEF's goal is to find a way to align these two types of representations to better fuse them and improve the understanding of multimodal data. The key function of ALBEF is to achieve the alignment of textual and visual representations. The specific steps can include the following aspects: Textual and Visual Feature Extraction: First, extract feature representations from text and visual data. For text data, natural language processing techniques such as word embeddings or text encoders can be used to convert the text into vector representations. For visual data, methods such as convolutional neural networks (CNNs) can be used to extract visual features from images or videos. Cross-modal Alignment: In ALBEF, a cross-modal alignment method is used to align textual and visual representations. This can be achieved through cross-modal retrieval or cross-modal attention mechanisms.
In terms of cross-modal retrieval, the most relevant text-visual pairs are identified by calculating the similarity or distance between text and visual representations. We use the following metrics to measure the similarity between text and visual data: Cosine Similarity, which measures the cosine angle between two vectors, where higher similarity means the two vectors are closer; Euclidean Distance, which measures the straight-line distance between two vectors, where smaller distance means the two vectors are closer. Cross-modal Attention: By computing attention weights between textual and visual representations, it dynamically focuses on the relevant textual and visual information. This can be achieved by introducing attention mechanisms such as bilinear attention or adaptive attention. Aligned Feature Fusion: After aligning textual and visual representations, the aligned features are fused. Fusion can be done through simple concatenation, weighted summation, or using neural network models to learn fusion weights. The key idea of ALBEF is to address the information mismatch problem in multimodal tasks by aligning textual and visual representations before fusion. Through alignment, ALBEF can better capture the semantic relationships between text and visual data, thereby enhancing the understanding of multimodal information. In the context of multimodal robot education tasks, ALBEF enhances the robot's ability to understand and respond to educational content, improving its performance in the education domain.
The formula of ALBEF (Align before Fuse) is as follows (Equation 1):
Align(T,V)=softmax(T·VTd)·V (1)Where the variables have the following meanings:
T: text representation, dimension is n×d, where n is the number of text samples and d is the text feature dimension. V: visual representation, dimension is m×d, where m is the number of visual samples and d is the visual feature dimension. Align(T, V): aligned visual representation, dimension is n×d, the same as the text representation. softmax(·): softmax function, used to calculate the attention weight so that it satisfies the properties of probability distribution. T·VTd: The similarity matrix between text and vision, obtained by calculating the dot product of the text representation and the visual representation, and normalized by d. ·: Matrix multiplication operation. This formula represents the alignment operation in the ALBEF model. The attention weights are obtained by calculating the similarity matrix between text and vision and normalizing it through the softmax function. Then, the attention weights are multiplied with the visual representation to obtain the aligned visual representation. In this way, the text and visual representations are semantically aligned.
3.4 VVG19VGG19 (Effati and Nejat, 2023) proposed by the Visual Geometry Group, is a deep convolutional neural network model designed to extract visual features from images through operations such as convolution and pooling (Rajangam et al., 2021). It is one of the models in the VGG series, consisting of 19 layers of convolutional and fully connected layers, featuring a deep network structure. Figure 3 is a schematic diagram of the principle of VVG Model.
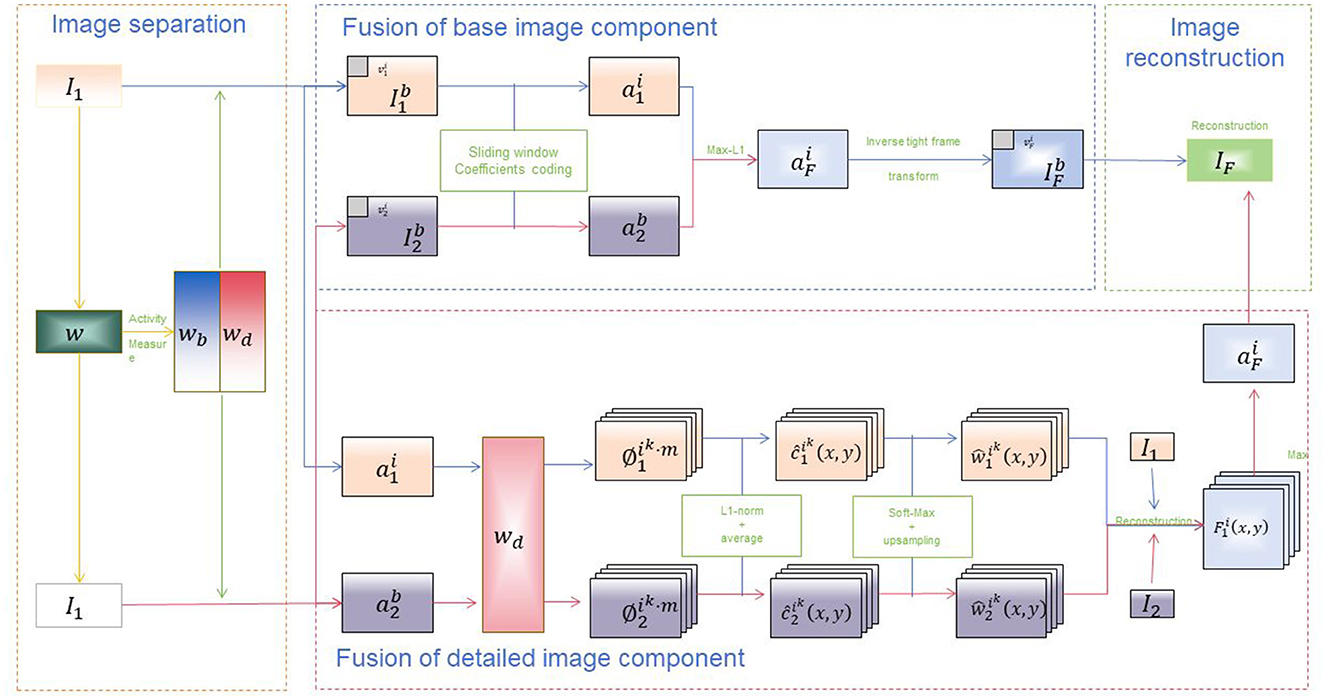
Figure 3. A schematic diagram of the principle of VVG19 Model.
Basic Principles of VGG19: Preprocessing of Input Images: VGG19 first preprocesses the input images, which includes normalizing pixel values, subtracting the mean, or using other preprocessing methods. Convolutional and Pooling Layers: VGG19 consists of multiple convolutional layers and pooling layers. These stacked layers extract features at different levels of abstraction from the images. VGG19 uses small-sized (3 × 3) convolutional kernels and (2 × 2) pooling kernels to increase the network's depth and non-linear capability. Learning Feature Representations: By adding activation functions (such as ReLU) after convolutional layers, non-linearity is introduced, enabling the network to learn feature representations from images. Through the stacking of multiple convolutional and pooling layers, VGG19 gradually learns higher-level feature representations, such as edges, textures, and parts of objects. Fully Connected Layers: After the convolutional and pooling layers, VGG19 includes several fully connected layers to map the learned features to the predicted categories. The fully connected layers typically include multiple hidden layers and an output layer, where the number of nodes in the output layer corresponds to the number of categories in the task. VGG19 is commonly used as a visual feature extractor in multimodal approaches. In this study, we leverage a pre-trained VGG19 model to extract rich semantic visual features from images or videos. These features are solely used for visual feature extraction and integrated with textual or other modal features to enhance the model's understanding of multimodal data.
The VGG19 (Visual Geometry Group 19) model does not have a single formula to describe it because it is a deep neural network consisting of multiple convolutional layers, pooling layers, and fully connected layers. However, the overall structure of the VGG19 model can be represented as follows:
Conv→Conv→Pool→Conv→Conv→Pool→Conv→Conv→Conv→Pool→Conv→Conv→Conv→Pool→Conv→Conv→Conv→Pool→Conv→Conv→Conv→Pool→FC→FC→FC (2)The meanings of the variables are as follows:
Conv: Convolutional layer, which uses convolution operations to extract image features. Pool: Pooling layer, which uses pooling operations to reduce the size of feature maps. FC: Fully connected layer, which maps features to predicted categories.
The VGG19 model consists of multiple convolutional layers and pooling layers stacked alternately, and finally uses several fully connected layers as output layers. Each convolutional layer uses convolution operations to extract image features and introduces nonlinearity through activation functions. The pooling layer is used to reduce the size of the feature map to reduce computational complexity and increase the translation invariance of the input. The final fully connected layer maps the learned features to the predicted category. This image provides a visual representation of the VGG19 architecture applied to a multimodal fusion process. The process is divided into several key stages: 1. Image separation: - The input image I1 is divided into different components. - An activity measure w is applied to the image to produce wb and wd. 2. Fusion of base image component: - The base components of the images (I1b and I2b) are processed using sliding window coefficients coding. - The coded components a1i and a2i are then combined using a Max-L1 strategy to produce aFi. - An inverse tight frame transform is applied to aFi to reconstruct the base fused image component IFb, resulting in the intermediate fused image IF. 3. Fusion of detailed image component: - The detailed components a1i and a2i are processed. - These components undergo L1-norm averaging and soft-max upsampling to produce weighted components c1ki(x,y) and c2ki(x,y). - The resulting components are then reconstructed into F1i(x,y), which contributes to the final fused image IF. 4. Image reconstruction: - The fused components are combined and reconstructed to form the final output image IF. The diagram illustrates the complex process of image fusion using the VGG19 architecture, highlighting the detailed steps involved in separating, processing, and combining image components to achieve a final fused output. This architecture is essential in applications requiring high-quality image fusion, such as in multimodal educational robots driven by dynamic attention mechanisms.
3.5 Dynamic attention mechanismThe Dynamic Attention Mechanism (Van Amsterdam et al., 2022) is a commonly used attention mechanism in multimodal models, designed to weigh and focus on different parts of the input at various time steps or spatial locations (Ding et al., 2021). Its basic principle is to dynamically compute attention weights based on the contextual information of the input, enabling the model to adaptively focus on important parts of the input. Figure 4 is a schematic diagram of the principle of Dynamic Attention Mechanism.
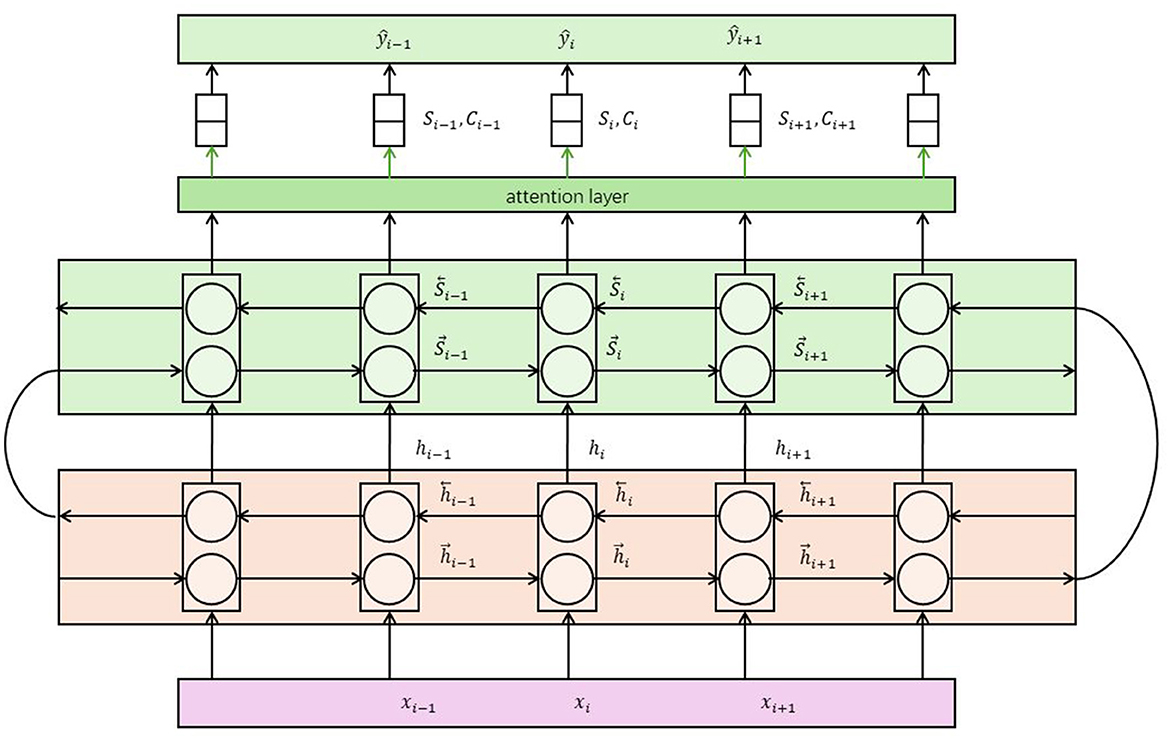
Figure 4. A schematic diagram of the principle of Dynamic Attention Mechanism.
Steps to Calculate Attention Weights in Dynamic Attention Mechanism: Input Feature Representation: First, extract feature representations for each modality of the input data . This can be achieved using pretrained neural network models such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), or Transformers. Context Representation: Next, compute the context representation based on the current state or contextual information of the model. This could be the hidden state from a previous time step or feature representations from other modalities. Attention Weight Calculation: Calculate attention weights using the context representation and input feature representation. This is typically done by computing the similarity or correlation between them. Common methods include dot-product attention, additive attention, and multi-head attention. Weighted Aggregation: Multiply the input feature representation by the attention weights and perform a weighted sum to obtain the aggregated feature representation. This allows the model to focus on parts of the input that are relevant to the current task. Role in Multimodal Tasks The dynamic attention mechanism provides a flexible way for the model to adaptively focus on different parts of the input based on the contextual information. It can be used in various tasks such as image captioning, visual question answering, and multimodal machine translation. By using the dynamic attention mechanism, the model can selectively extract useful information from the input while ignoring noise or irrelevant parts. This helps improve the model's performance and robustness, enabling it to better understand and model the relationships in multimodal data. Additionally, the dynamic attention mechanism enhances the interpretability of the model by allowing visualization of the attention weights, which can explain the model's decisions or generated results. Translation to Multimodal Robot Education In the context of multimodal robot education, the dynamic attention mechanism allows the robot to focus on relevant parts of multimodal educational content based on the current educational task. This improves the robot's ability to understand and respond to educational content, making the interactions more effective and personalized. By visualizing attention weights, educators can also gain insights into how the robot processes information and makes decisions, further enhancing the educational experience.
Context=ComputeContext(PreviousState) AttentionWeights=ComputeAttention(InputFeatures,Context) WeightedFeatures=AttentionWeights⊙InputFeaturesAggregatedFeatures=Aggregate(WeightedFeatures) (3)Wherein, the meanings of the variables are as follows:
Context: context representation, representation calculated based on the current state of the model or context information. PreviousState: representation of the hidden state or other modal data of the model at the previous time step. InputFeatures: input feature representation, feature representation from different modal data. AttentionWeights: Attention weights, used to weight the importance of input feature representations. ⊙: Represents element-wise multiplication. WeightedFeatures: Weighted feature representation, the weighted result obtained by multiplying the input feature representation and the attention weights. AggregatedFeatures: Aggregated feature representation, the final feature representation obtained by summing or other aggregation operations on the weighted feature representations.
4 Experiment 4.1 DatasetsThis paper uses four datasets: ms coco dataset, Ref coco dataset, CC12M datasets, and VG-Cap dataset. MS COCO Dataset (Tong and Wu, 2023) (Microsoft Common Objects in Context): MS COCO is a widely used dataset for image recognition and captioning tasks. It contains over 200,000 labeled images, covering a wide range of object categories. The dataset also includes human-annotated captions for each image, making it suitable for tasks related to image understanding and natural language processing. Ref COCO Dataset (Jing et al., 2021) (ReferIt Game Dataset): The Ref COCO dataset is an extension of the MS COCO dataset, specifically designed for referring expression comprehension. It contains additional annotations where human subjects provide expressions referring to specific objects in the images. This dataset is useful for tasks that involve understanding natural language references in the context of visual scenes. CC12M Datasets (Fan et al., 2024) (Conceptual Captions 12M Dataset): CC12M is a large-scale dataset consisting of 12 million image-caption pairs. The dataset emphasizes diverse and novel concepts, covering a wide range of visual and linguistic variations. It is useful for training and evaluating models in various tasks such as image captioning, image-text matching, and multimodal learning. VG-Cap Dataset (Ye and Kovashka, 2021) (Visual Genome Caption Dataset): The VG-Cap dataset contains image-caption pairs collected from the Visual Genome project. Visual Genome is a dataset that provides detailed scene understanding annotations, including object and attribute labels, relationships between objects, and region descriptions. The VG-Cap subset focuses specifically on image captioning, making it suitable for tasks that require detailed image descriptions.
4.2 Experimental detailsExperimental Design Objective: The objective of this experiment is to compare different models in terms of both performance metrics (Accuracy, AUC, Recall, F1 Score) and technical metrics (Training Time, Inference Time, Parameters, and FLOPs). Experimental Steps: Dataset Selection: Select a suitable dataset for your study, such as MS COCO, RefCOCO, CC12M, or VG-Cap. Model Selection: Choose several models with different architectures or characteristics for comparison. These can be classical models or the latest models applicable to the chosen dataset. Ensure that the models have varying numbers of parameters and computational complexities for a comprehensive comparison. Experimental Setup: Data Splitting and Preprocessing: Divide the dataset into training and testing sets and preprocess the data accordingly. Model Training: Train each model using the training set and record the training time. Performance Metrics Comparison: Compare the models' performance metrics: Accuracy, AUC, Recall, and F1 Score. Use charts or tables to clearly present the comparison results. Ablation Study: Conduct an ablation study on a high-performing model to verify the contribution of its various components. Gradually remove or modify certain components of the model, such as the attention mechanism or feature extractors, and compare the performance metrics of the modified models. This helps to evaluate the impact of each component on the model's performance. Results Analysis: Analyze the experimental results to compare the differences in technical and performance metrics across different models. Interpret the differences between the models and analyze their strengths and weaknesses. Evaluate the ablation study results to understand the contribution of each component to the model's performance. This structured approach allows for a comprehensive comparison of different models, providing insights into their efficiency and effectiveness in handling the chosen dataset.
4.3 Experimental results and analysisTable 1 and Figure 5 presents a comparison of performance metrics across different models on the MS COCO and Ref COCO datasets, including Accuracy, Recall, F1 Score, and AUC (Area Under the Curve). Our model performs best across all these metrics on both datasets, with Accuracy (97.38% and 97.63%), Recall (94.35% and 95.15%), F1 Score (92.84% and 93.72%), and AUC (95.58% and 96.69%) surpassing those of other models. This indicates that our model excels in multimodal tasks, particularly in integrating visual and textual information. By leveraging the ALBEF (Align before Fuse) framework and VVG19 (Visual Geometry Group) model, our approach first aligns visual and textual information before fusing them, thereby enhancing accuracy and consistency in information processing and understanding. Additionally, the introduction of a dynamic attention mechanism allows the model to flexibly adjust attention allocation when handling complex multimodal inputs, further improving overall performance. Overall, our method demonstrates outstanding performance in multimodal tasks for educational robots, proving its effectiveness in enhancing the evaluation and optimization of robotic educational abilities.
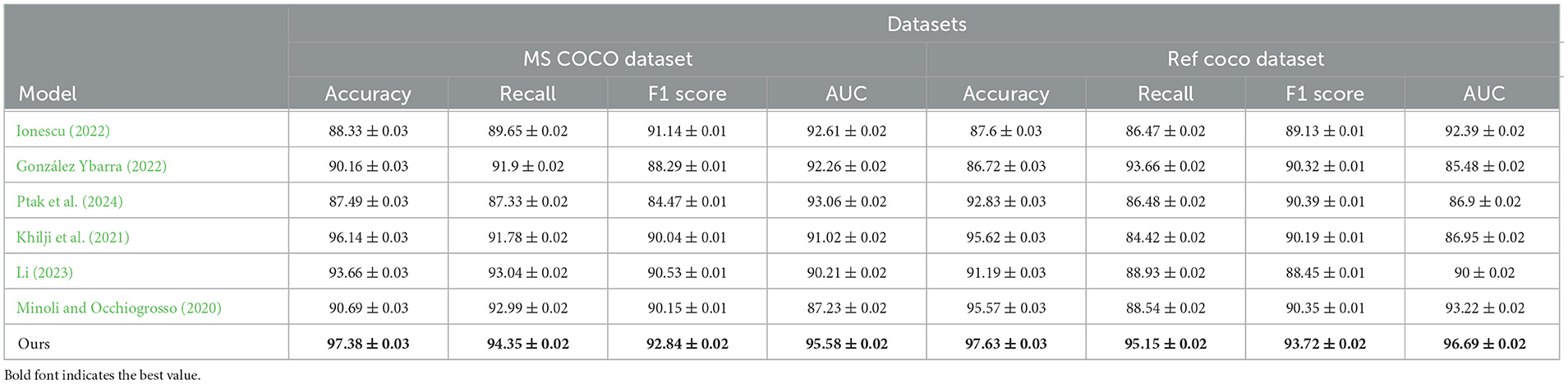
Table 1. Performance comparison on MS COCO and Ref COCO datasets.
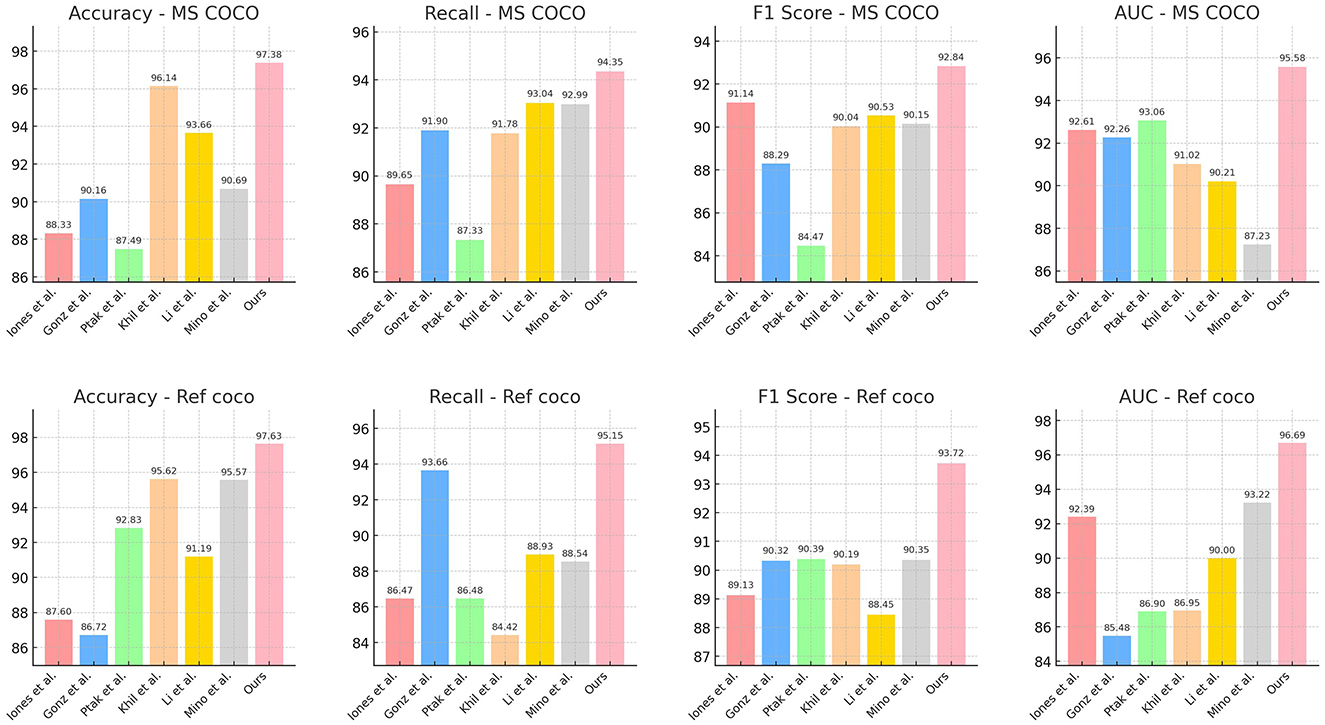
Figure 5. Performance comparison on MS COCO and Ref COCO datasets.
Table 2 and Figure 6 shows a comparison of different models in terms of Parameters, Flops (Floating Point Operations), Inference Time, and Training Time on the CC12M and VG-Cap datasets. Our model excels in all these metrics, especially in the CC12M dataset, with Parameters at 231.40 M, Flops at 149.83 G, Inference Time at 116.12 ms, and Training Time at 180.31 s; and in the VG-Cap dataset, with Parameters at 222.27 M, Flops at 126.85 G, Inference Time at 148.55 ms, and Training Time at 226.84 s. Compared to other models, these metrics are the lowest, indicating that our model has significant advantages in computational efficiency and resource consumption. By combining the ALBEF framework and VVG19 model, our model maintains high performance while achieving lower computational complexity and faster processing speeds. The dynamic attention mechanism not only enhances inference capabilities but also effectively reduces unnecessary computational overhead, further optimizing the overall efficiency of the model. This makes our model highly suitable for deployment in real-world educational robots, ensuring high performance while significantly reducing resource consumption and processing time.
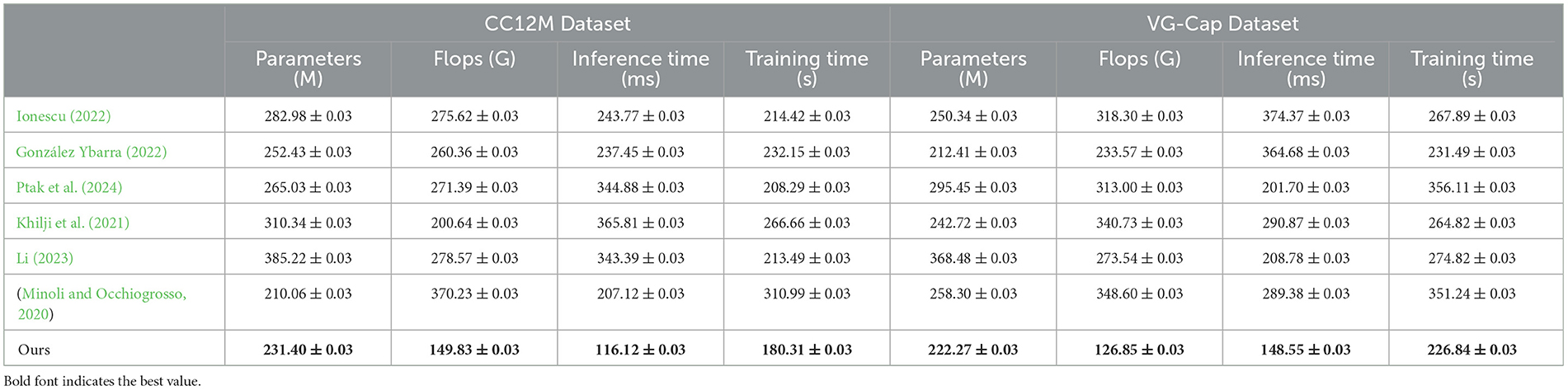
Table 2. Performance comparison on MS COCO and Ref COCO datasets.
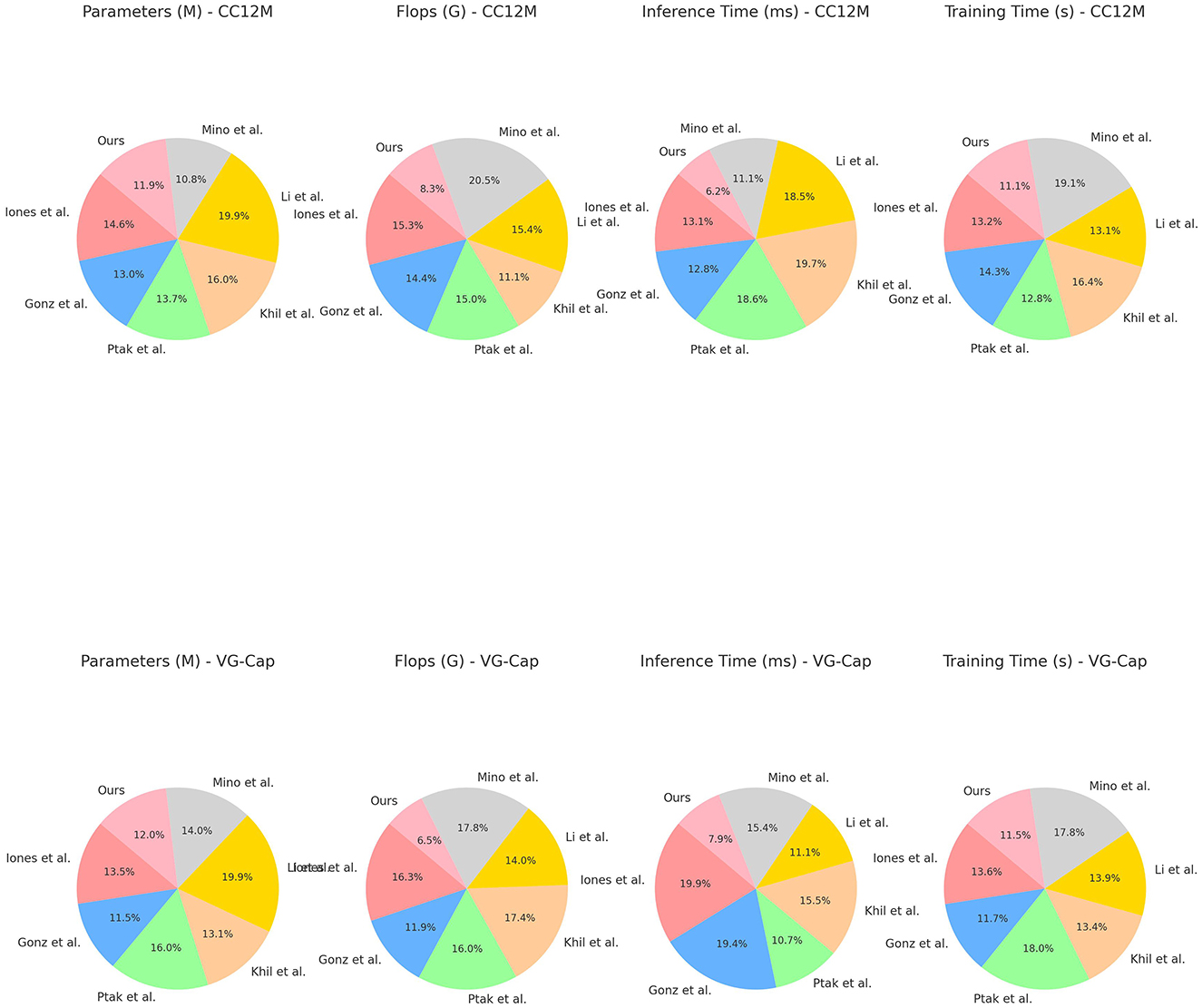
Figure 6. Performance comparison on MS COCO and Ref COCO datasets.
Table 3 and Figure 7 involves ablation experiments on the VVG19 module, comparing different models' performance metrics on the MS COCO and Ref COCO datasets, including Accuracy, Recall, F1 Score, and AUC. The results show that our model outperforms others with Accuracy (96.95%), Recall (94.65%), F1 Score (92.71%), and AUC (94.09%) on the MS COCO dataset, and Accuracy (97.23%), Recall (94.35%), F1 Score (92.53%), and AUC (92.16%) on the Ref COCO dataset. Through ablation experiments, we validate the effectiveness of the VVG19 module and the dynamic attention mechanism. The VVG19 model, as the basis for visual processing, provides strong feature extraction capabilities, while the dynamic attention mechanism enhances the flexibility and accuracy of multimodal information processing by adjusting the model's attention to different inputs. These improvements significantly enhance the model's performance in multimodal tasks, particularly in the educational robotics domain. By integrating the ALBEF framework, our method more effectively fuses and processes multimodal information from visual and textual sources, improving the model's adaptability and practicality in diverse educational scenarios.
留言 (0)