
記住我
With the widespread application of artificial intelligence and Internet of Things technologies in Industry 4.0, Industrial Internet of Things (IIoT) technology greatly improves and optimizes the operational and production efficiency of industrial equipment while reducing enterprises’ human resource costs (Liu et al., 2023; Zhang et al., 2024; Feng et al., 2022). However, IIoT technology also increases the complexity of production equipment. As a result, the large amount of sensor data generated raises the probability of equipment failure. Additionally, industrial equipment is influenced by the external environment and its own harsh operating conditions during actual industrial production. Therefore, the sensor data exhibits spatio-temporal correlations and high-dimensional characteristics, such as bearing wear data, motor condition data, and air pressure, humidity, and temperature data from aircraft in the aerospace sector (Wang et al., 2021; Xu et al., 2022). This complexity poses significant challenges to traditional fault detection techniques (Zhang et al., 2023; Aboelwafa et al., 2020; Akgüller et al., 2024). Consequently, accurate and timely detection of abnormal phenomena is crucial for ensuring the safety and efficient operation of industrial equipment. Currently, fault detection research methods can be classified into three main categories:
Univariate and multivariate probability statistical methods are utilized based on the characteristics of equipment data. A single index, such as the mean, variance, and peak, is commonly used for fault detection in single-feature equipment sensor data. Wang et al. (2022) proposed a fault detection method for wind turbine blades based on the transmissibility function of wavelet packet energy, which enhanced high-frequency resolution while maintaining its low sensitivity to noise. Zhang et al. (2022) adopted L2-norm shapelet dictionary learning to improve the bearing fault recognition rate under uncertain working conditions. Meanwhile, Peng et al. (2021) realized wind turbine fault detection based on fault characteristic frequency recognition by using compressive-sensing-based signal reconstruction technology and signal reconstruction analysis. Additionally, Shi et al. (2022) designed a generalized variable-step multiscale Lempel-Ziv algorithm to extract features of rolling bearings. The univariate fault detection method is simple and efficient, but performs poorly in identifying equipment failures caused by multiple factors. To provide a comprehensive analysis of equipment operation, a statistical method based on multivariate fault detection is proposed. Lei et al. (2021) proposed Hertz contact theory to detect faults in angular contact ball bearings by taking into account the influence of centrifugal force, thermal impact on bearing operation, and gyroscopic moments. Bhatnagar et al. (2022) used the discrete wavelet transform to obtain discriminative features of fault current signals for detecting faults in distribution networks. This study can effectively identify common shunt faults and high-impedance faults in distribution lines. Multivariate fault detection methods can provide a comprehensive view of equipment status. However, the overall fault detection rate may decrease in the presence of numerous missing sample data and complex high-dimensional scenarios.
An equipment fault detection method based on spatial distance and region. Wang (2018) mentioned that the fault in nonlinear processes can be detected by the modified conventional kernel partial least squares method, which has definitely improved the computing speed. To overcome the limitations of the principal component analysis algorithm, Shah et al. (2023) proposed a manifold learning method based on the weighted linear local tangent space alignment to provide local tangent space estimates under the condition that uniformly distributed data is not close to linear subspaces. Qin et al. (2022) used a combination of correlative statistical analysis and the sliding window technique for diagnosing initial faults, which improved the recognition rate and reduced the computational complexity. Zhang et al. (2021) proposed an SR-RKPCA model based on subspace reconstruction for detecting wind turbine faults. Compared with traditional principal component analysis and KPCA methods, this approach can better extract nonlinear features of wind turbine data. Sarmadi and Karamodin (2020) worked on removing the environmental variability conditions and estimating local covariance matrices to find sufficient nearest neighbors for training and testing datasets in a two-stage procedure. The study used adaptive Mahalanobis-squared distance and one-class KNN algorithms to classify the fault patterns. Wang et al. (2021) considered relevant hidden information in the temporal dynamics of frequencies and spatial configuration for training a K-nearest neighbor classifier based on a temporal-spatio graph to improve fault diagnosis performance. Distance-based fault detection methods are straightforward, yet their computational time increases rapidly with large-scale and high-dimensional fault data, rendering them unsuitable for real-time detection in industrial settings.
A fault detection method based on machine learning. To enhance the intelligence and efficiency of fault detection, some scholars have applied machine learning technology to the field of fault detection and have achieved certain results. In their study, Sun and Yu (2022) proposed an innovative adaptive technique based on sparse representation and minimum entropy deconvolution for identifying bearing faults, which promoted the effectiveness of impulse enhancement and the robustness of the inverse filter length. To overcome the problem of significant noise interference in bearing vibration signals, Chen et al. (2023) extracted the signal features by using a hierarchical improved envelope spectrum entropy method and identified the bearing faults using a support vector machine. Dhibi et al. (2020) proposed a reduced kernel random forest method to address the limitations of a single random forest algorithm in industrial processes and applied it to the fault detection of grid-tied photovoltaic systems.
Machine learning methods transform fault detection into classification problems, which offers the advantages of short training times and strong generalization abilities. Nonetheless, significant noise pollution can lead to suboptimal fault detection rates. Therefore, Xue et al. (2022) proposed a stacked long short-term memory (LSTM) network to enhance the performance of fault diagnosis. However, the hyperparameters of the LSTM network are mostly obtained through experience (Zhi et al., 2022). Unreasonable allocation of important feature weights and hyperparameter settings directly impact the fault classification results. Furthermore, the IIoT data are characterized by large scale, multi-source heterogeneity, and high noise, which brings many difficulties and challenges to cloud-based IIoT systems. The challenges include processing real-time data, managing core network loads, maintaining user data security, and ensuring system scalability. To address the aforementioned problems, this article proposes and implements a fault detection model based on the LSTM model, the genetic algorithm, the attention mechanism, and edge-cloud collaboration (GA-Att-LSTM) framework. The major contributions of the article are summarized as follows:
To improve detection speed and reduce the pressure on cloud storage, we utilize an edge-cloud collaborative framework to lower more sensor data computation and storage from the “core” to the “edge,” which have high storage, efficient processing speed, and strong multi-source heterogeneous adaptability.
To extract key temporal features of sensor data, achieve intelligent fault detection, and reduce manual intervention, we use Att-LSTM network to transform complex fault detection problems into classification problems, which has enhanced detection efficiency and decreases equipment maintenance costs.
To obtain appropriate hyperparameters of the LSTM network, we use an improved genetic algorithm (GA) to optimize Att-LSTM network, which has improved the efficiency of fault detection.
The remainder of the article is described as follows: Section2 introduces the architecture principle of edge-cloud collaborative including intelligent terminal layer, edge node layer and cloud platform layer; Section 3 illustrates the methodologies, LSTM structure and GA-Att-LSTM network structure; Section 4 introduces the fault detection principle and design; Section 5 discusses the performance evaluation of data preprocessing and result analysis; Finally, contributions of this article are summarized in Section 6.
2 Architecture principle and designIn traditional manual fault detection under IIoT facilities, the operating status of the facilities usually needs to be manually detected, recorded, analyzed, and judged. This method is inefficient, leading to higher maintenance costs and inaccessible, non-real-time results (Huang et al., 2020a). Therefore, the demand for intelligent facility fault detection without human intervention is urgent in Industry 4.0. A facility fault detection model based on cloud-only computing provides some advantages and plays a crucial role in IIoT. Storing data on the cloud server allows a centralized operations facility to monitor systems and process information from various regions and databases (Li et al., 2024a). In cloud-only computing, the delay problem cannot be solved merely by increasing the speed of data transmission without limit (Fu et al., 2018; Li et al., 2024b). To effectively alleviate the latency issue, the distance data must travel needs to be shortened as much as possible. This is why edge computing is used in IIoT. In response to the above problems, this article proposes a model based on edge-cloud collaboration for facility fault detection. The traditional detection model is shown in Figure 1a, while Figure 1b illustrates how the arrangement operates via edge-cloud collaboration.
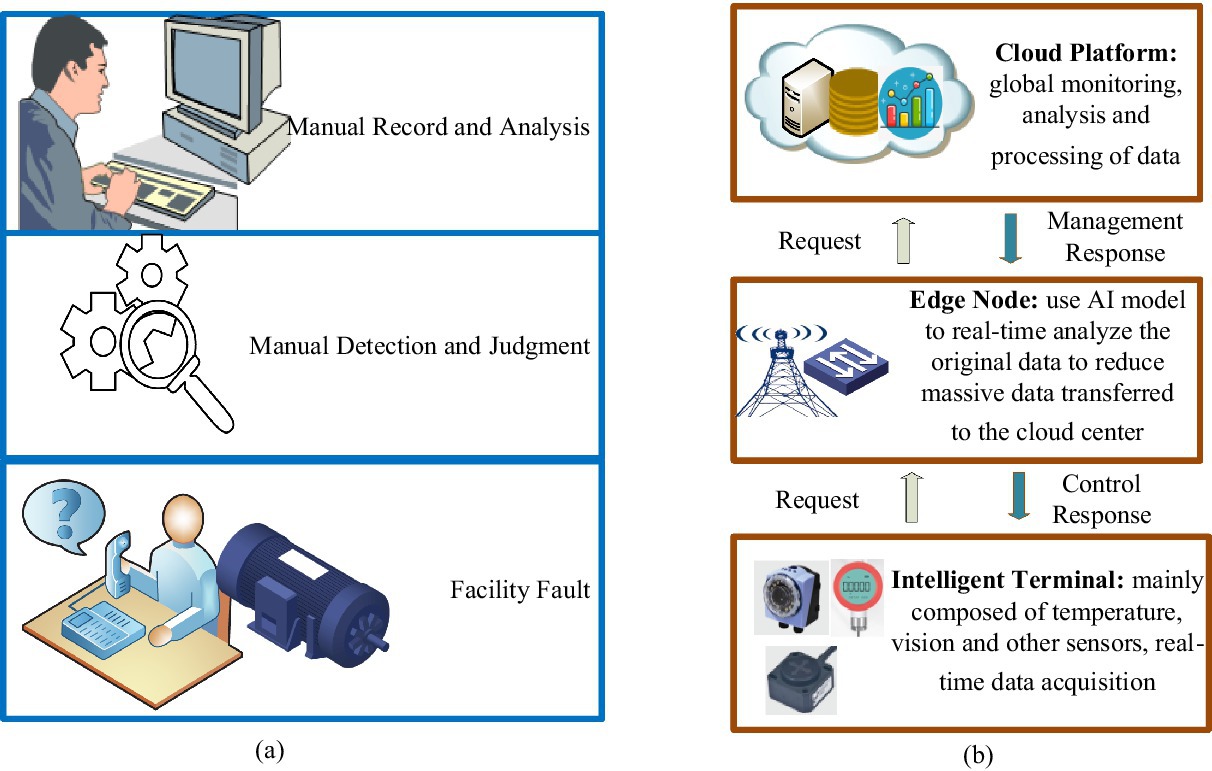
Figure 1. Elucidation of traditional model and state-of-the-art system for facility fault-detection in IIoT. (a) Traditional manual fault detection model; (b) the advanced edge-cloud collaboration fault detection model.
As shown in Figure 1b, a fault detection framework based on edge-cloud collaboration is composed of three layers. The intelligent terminal layer comprises the industrial infrastructure, where sensors and industrial facilities are installed. The edge layer is deployed to process collected data in real time. The cloud platform layer is used to train GA-Att-LSTM network models and save weight parameters. The collaboration between the edge and the cloud, along with various sensors and devices, is demonstrated as follows:
1. Intelligent terminal layer: the intelligent terminal layer is the most basic component of a typical edge-cloud-based infrastructure for collecting information. It is mainly composed of sensors, radio-frequency identification, GPS, and cameras (Li et al., 2023a). First, real-time heterogeneous data are primarily obtained using cameras and sensors (for position, speed, energy consumption, pressure, temperature, etc.). Sensors employ a process to convert various signals into electrical signals, which are then processed by related equipment (Kaur et al., 2022; Kaur and Chanak, 2023; Liu et al., 2021). The data are ultimately transmitted to the upper layer using various transmission technologies, such as industrial fieldbus, industrial Ethernet, industrial wireless networks, Bluetooth, and infrared.
2. Edge node layer: the edge node layer is the middle part of the system, mainly composed of gateways and computing nodes (e.g., mobile phones, computers, servers). Gateways provide both visibility and control over connected devices that use the same IIoT protocol. Moreover, they standardize the codec for control commands and device data, after which they transmit the information to the upper layer. This approach avoids the problem of disparate data from multiple collection devices in the cloud (Li et al., 2023b). The computing node layer consists of various nodes through which facility data passes from the gateway to the cloud. During the system’s initialization phase, it acts as a relay device, transmitting the environmental monitoring data collected by wireless sensor nodes to the cloud platform (Yu et al., 2023; Song et al., 2023; Natesha and Guddeti, 2021). Fault detection is performed on the collected data during the system’s routine operation phase. When an abnormal situation is detected, the edge computing node reports the issue to the data and control center on the cloud platform. Simultaneously, it prompts the controller at the bottom layer to offer an emergency response plan. Figure 2 shows the role of the edge computing nodes.
3. Cloud platform layer: the cloud platform layer sits at the top of the architecture, providing significant advantages and influencing the IIoT. The cloud computing platform offers exceptional computational power and large storage capacity, serving as a remote data and control center for the system. This enables a centralized operations facility to monitor systems and optimize parameters for artificial intelligence algorithms (Bui et al., 2020). It is primarily used for processing, storing, and analyzing large-scale global historical data with complex computational requirements. In this article, the edge-cloud collaboration framework is applied to fault detection in equipment to improve maintenance efficiency and leverage the strengths of both technologies. To achieve real-time functionality, edge computing mainly handles short-term, localized data. The LSTM network is an artificial neural model that requires complex parameter training for feature extraction. The computational demands and resource consumption associated with this complexity are challenging for both wireless sensor nodes and edge computing nodes. To address this issue, model training is performed on a cloud-based platform. Real-time fault detection is then carried out by sending the trained model parameters back to the edge computing node.
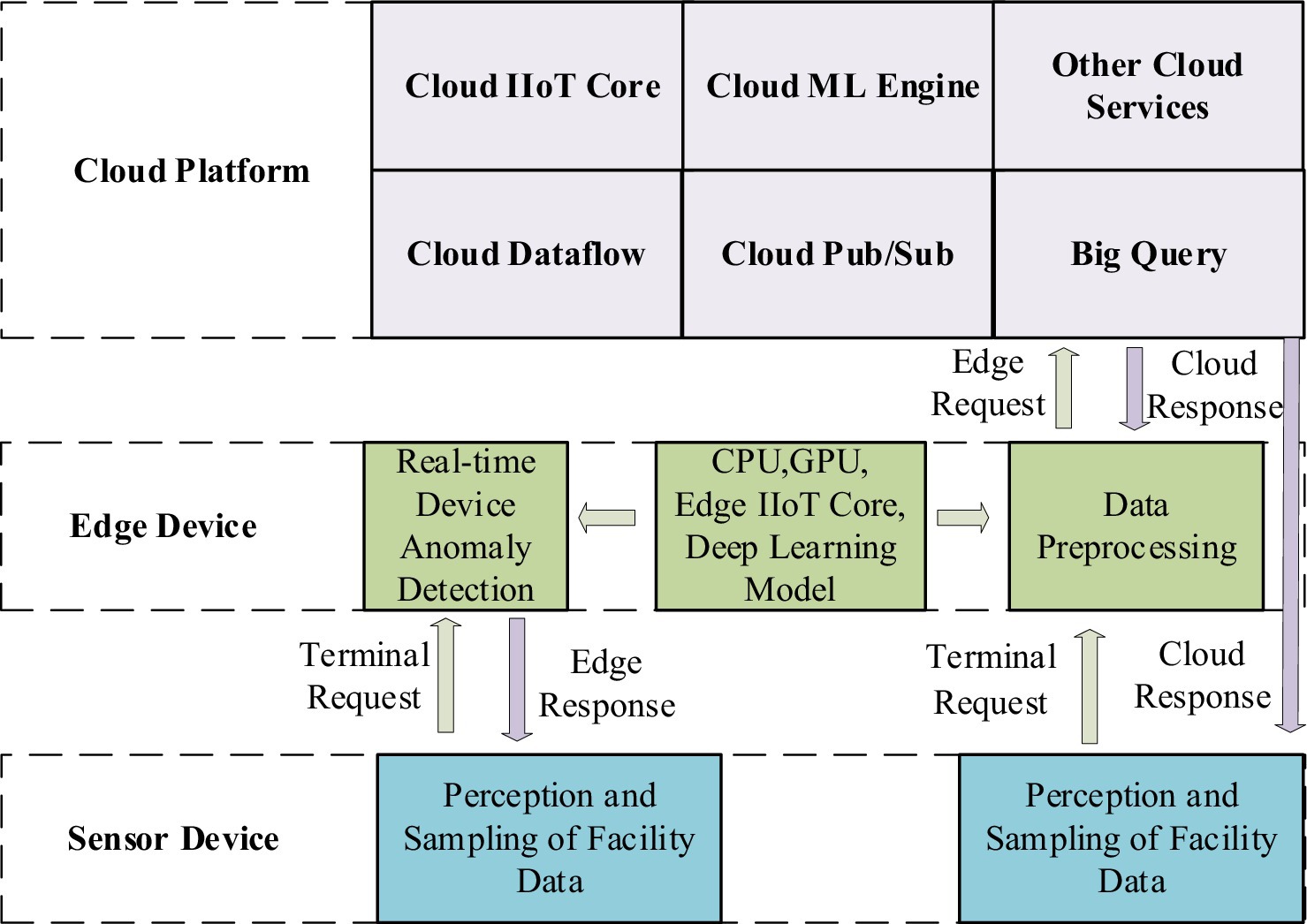
Figure 2. The role of edge nodes in the proposed overall architecture.
3 MethodologyIn this section, we introduce the methodology for developing the edge-cloud collaboration framework for IIoT systems. First, we briefly review Recurrent Neural Networks (RNN) and LSTM models, which are essential for building the proposed GA-Att-LSTM framework. This is followed by a discussion of the system architecture and model development. Finally, we introduce the framework for optimizing the LSTM network using a GA.
3.1 Basic recurrent neural networkThe RNN is an architecture with a memory function that stores the previous network operation’s state value and leverages it to generate input for the current moment. It stores the previous network operation’s generated state value and utilizes it to generate the present moment’s input value, enabling RNN to handle time-series sensor data (Abdul et al., 2020). Figure 3 shows the RNN architecture.
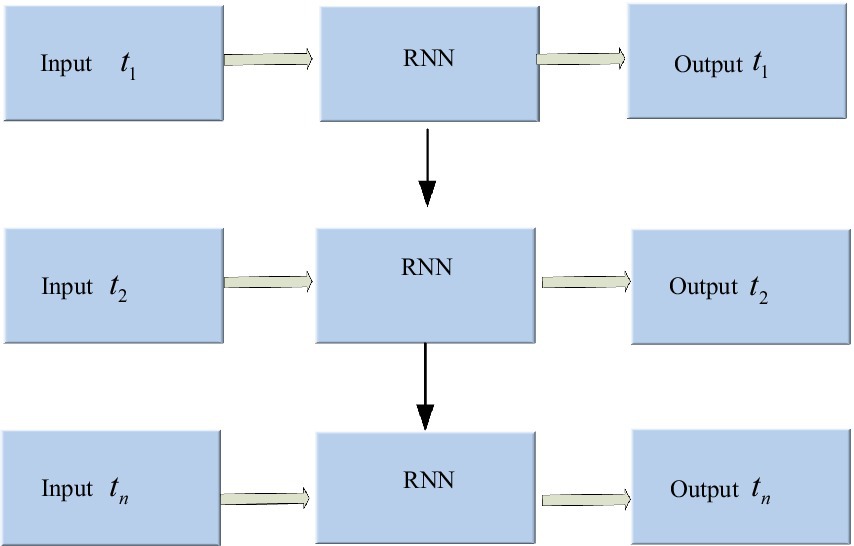
Figure 3. Architecture of recurrent neural network.
In Figure 3, the hidden layer blocks are unfolded along the timeline as shown in Figure 4, and their nodes are connected to the corresponding weights through directed loops. Where x is the input vector, s represents the hidden layer vector, y denotes the output vector, weight matrix from the hidden layer to the output layer is defined as U , weight matrix from the hidden layer to the output layer is defined as V and Wis the connection weight between the hidden layer cells.
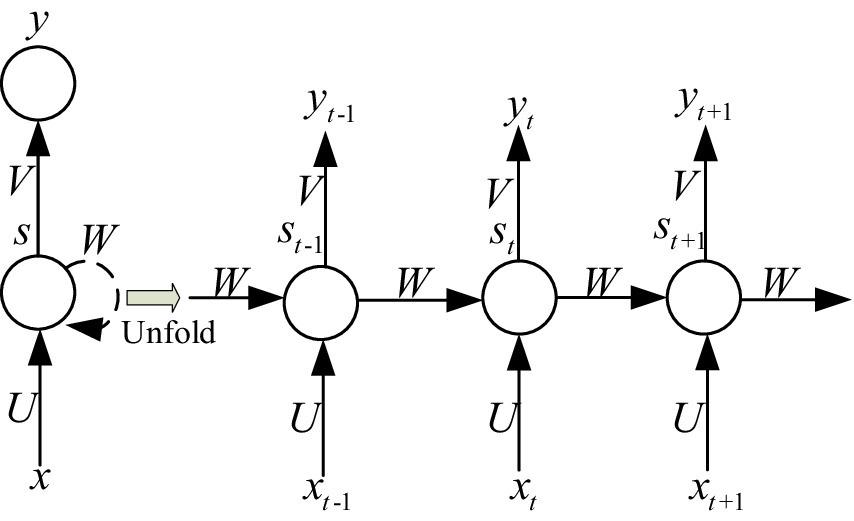
Figure 4. The hidden layer of RNN is expanded according to the time axis.
In IIoT systems, the input values at different time steps are denoted as xt−1 , xt and xt+1 , where each represents the input at a specific time step in a sequence. The input xt−1at time step t−1 represents the value immediately preceding the current input. The input xtat time step t is combined with the previous hidden state to update the current hidden state. The input xt+1at time step t+1 is used as the network advances through the sequence. xt , st , and yt represents input value, memory value, and output value at time step t respectively. The value of st is related to the xt at current moments and the st−1 at the previous time. These internal relationships between the input, hidden, and output layers are expressed as shown in Equations (1, 2):
st=fUxt+Wst−1 (1)where g· and f· denote activation functions, respectively. From the given (1)–(2), it is clear that the weights are indicative of the dependence relationship between input values at time step t and t−1 . Thus, they are commonly used in many sequence learning tasks. However, as the time series grows, the initial gradient contribution diminishes and the chain of gradients lengthens, resulting in gradient vanishing. To address this issue, the LSTM network is proposed.
3.2 Long short-term memory modelThe LSTM network can solve the problem of vanishing or exploding gradients that exists in ordinary RNN by designing input gates ( it ), forget gates ( ft ), and output gates ( ot ) (Huang et al., 2024; Lin and Zhang, 2024). Where ctstands for the long-term memory unit, ⊙symbol represents the multiplication of the corresponding elements. σxdenotes the non-linear sigmoid activation function with the value range from 0 to 1, which is used to describe the number of information passing through. Wand b are the weight matrices and bias terms, respectively. xt represents the input vector, the short-term state is ht . The unit structure of hidden layer is shown in Figure 5. Since LSTM has a memory block and gate structure, it can learn information with a long span and determine the optimal time lag autonomously. When processed time series data are fed into the LSTM network, the forgetting gate first determines which information needs to be discarded. An input vector xt and a previous short-term state ht−1are utilized for inputs to the forget gate. The output value is calculated using the sigmoid function. The range is 0 to 1. A value of 0 implies that information may pass through while 1 implies the opposite. After passing through the input gate, the relevant information is selected for storage in the cell state. The sigmoid layer determines which values should be updated, while the tanh layer generates a new candidate value vector and calculates the new cell state. Lastly, the output gate decides which information to output. The current cell state is processed by tanh and multiplied by the sigmoid layer’s output to produce the final output.
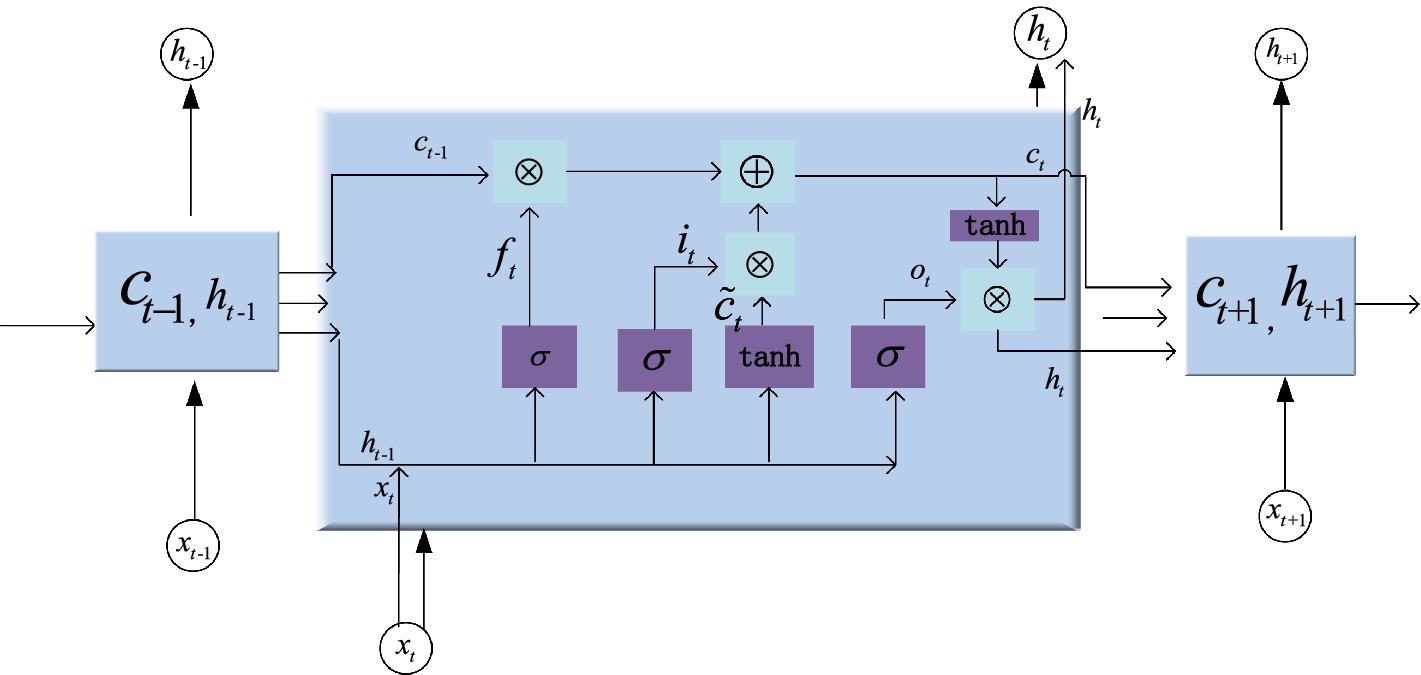
Figure 5. Internal structure of LSTM block.
The input gate decides the amount of information flows from the input xt that is retained in the cell state ct at the present time. The output vector it of the input gate is given by He et al. (2023) as shown in Equation (3).
it=σWxixt+Whiht−1+bi (3)The forget gate has the function that saves partial information flow of the previous moment in the cell state ct−1to the current moment ct . The candidate cell state c˜t is a crucial element in LSTM that serves as a proposed update to the existing cell state. It is based on both the current input and the past hidden state. The output of the forget gate ft and the memory cell ct at time t are defined as shown in Equations (4–6).
ft=σWxfxt+Whfht−1+bf (4) c˜t=tanhWxcxt+Whcht−1+bc (5) ct=ft⊙ct−1+it⊙c˜t (6)The output gate in Equation (7) mainly controls the influence of long-term state ct on the current short-term state ht , i.e., the data in ct will be output at time t . The output of the output gate ot and output value of short-term state ht in Equation (8) are given as follows:
ot=σWxoxt+Whoht−1+bo (7) ht=ot⊙tanhct (8)When training LSTM network model, it’s common to use a loss function to evaluate the error between prediction and actual values. The smaller the loss function, the better the performance of the model. To measure the degree of difference between two probability distributions in the same random variable, we use the cross-entropy loss function in Equation (9) for measurement. Its expression is derived as follows:
Jθ=−1N∑i=1Nyi×lnŷi (9)where N represents the number of samples, yi is the real value of samples, and ŷi stands for the predicted value of samples. Firstly, Adam algorithm is used as an optimizer to update the weight of the neural network model, which is simple to implement, computationally efficient and low memory requirement. Then, the loss function is used to calculate the error of each iteration. Finally, the trained neural network model is used to predict the results.
3.3 Attention mechanismThe attention mechanism model, jointly proposed by Treisman and Gelade, aims to mimic human attention and is particularly suitable for optimizing the performance of traditional models. The core function of the attention mechanism is to calculate and analyze the data features input into the model, assigning corresponding probability weights to each feature in the neural network’s hidden layer based on the analysis results. In this process, more important features receive higher weights, thereby improving the output accuracy of the network model (Yuan et al., 2021). The structure of the attention mechanism is shown in Figure 6. The variables x1,x2,x3⋯xn represent the input sequences, the variables h1,h2,h3⋯hn represent the hidden sequences, and y1,y2,y3⋯yn are the output sequences. wn is the attention weight.
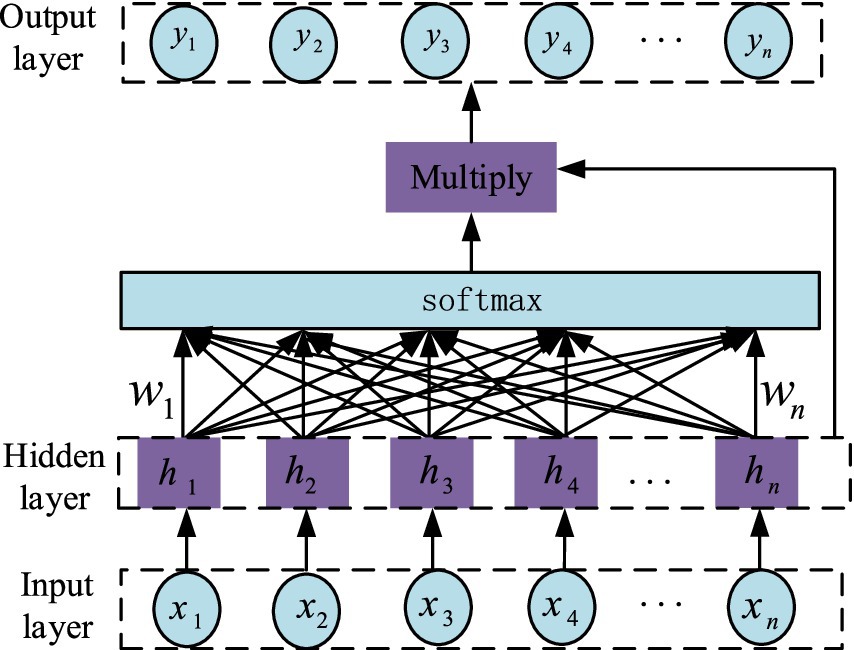
Figure 6. Internal structure of Attention mechanism.
3.4 GA-Att-LSTM modelThe GA is a highly efficient, parallel, and adaptive global probabilistic search method that mimics the process of biological evolution and inheritance in natural environments. By using GA to optimize the number of layers and neurons in each layer of an LSTM network, the architecture selection process can be automated, significantly reducing the complexity of manual tuning. The algorithm continuously generates, evaluates, and selects new architecture candidates by simulating natural selection and genetic mechanisms. Through crossover and mutation of high-fit individuals, it creates increasingly diverse network structures, gradually eliminating less effective models while refining both the number of layers and neuron allocation. As iterations progress, the GA effectively explores the parameter space and ultimately identifies the optimal LSTM model for a given task, striking an optimal balance between network complexity and predictive accuracy. The main process of the GA-Att-LSTM model is illustrated in Figure 7.
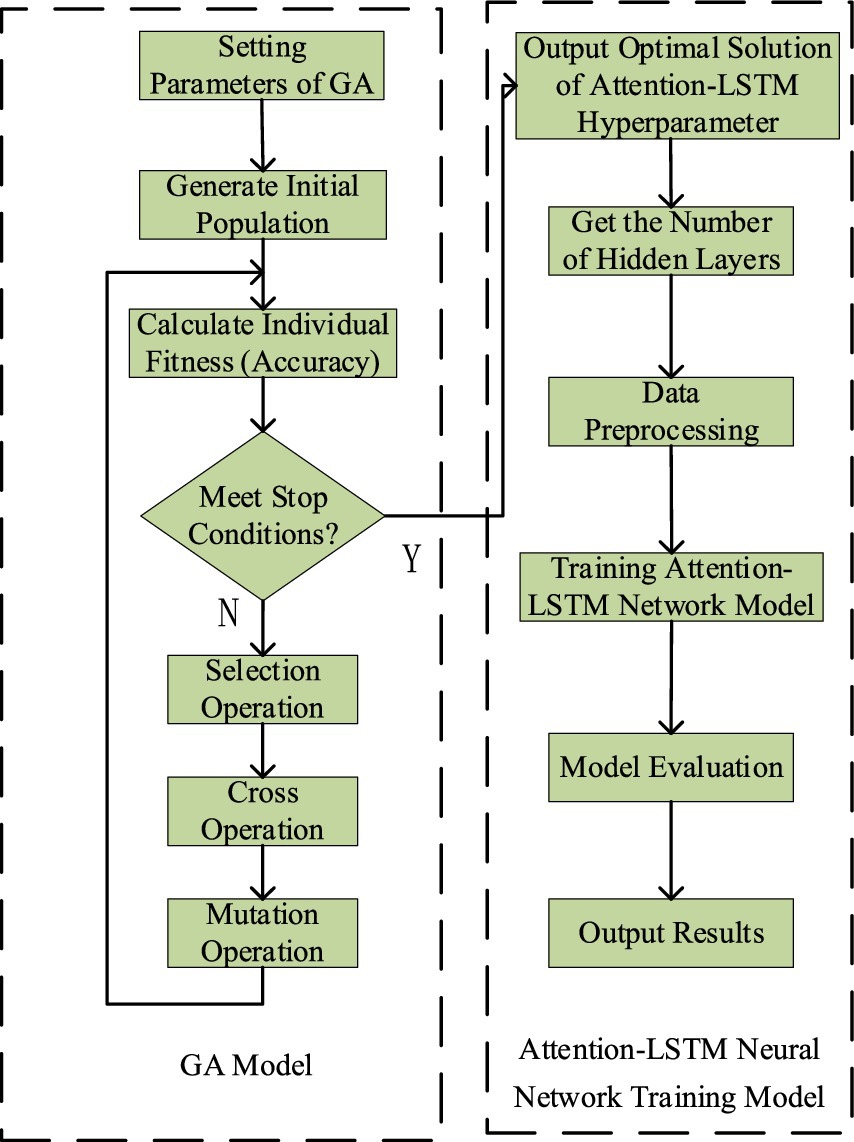
Figure 7. Flow chart for optimizing attention-LSTM network with GA.
4 Fault detection principle and design 4.1 Fault detection with traditional methodFault detection aims to identify the abnormal data points. In IIoT systems, the irregular data can be detected by analyzing regular sensor data within the spatio-temporal domain. There are many reasons for outlier data, including unexpected events within the monitoring area (e.g., abnormal device shutdown or sudden power failure) and abnormalities within the sensor node itself (e.g., hardware module damage, low node power). Many traditional methods have been exploited to predict the facilities failure (Li et al., 2024c). The fault detection methods commonly used are mainly multinomial naive bayes (MNB) (Bennacer et al., 2014), logistic regression (LR) (Huang et al., 2020b), principal component analysis-recurrent neural Network (PCA-RNN) (Mansouri et al., 2022), k-nearest neighbor (KNN) (Zayed et al., 2023), AdaBoost (Hussain and Zaidi, 2024), and gradient boosting classifier (GBC) (Al-Haddad et al., 2024). Despite their widespread use, these algorithms have significant limitations. For example, MNB assumes independence between features, resulting in reduced classification performance in situations with strong feature correlations or class imbalances. LR, on the other hand, is limited to linear decision boundaries and performs poorly in the presence of complex non-linear relationships unless features are transformed or interaction terms are included. KNN, on the other hand, faces challenges related to high computational complexity, particularly when calculating distances between each sample and all training instances in large datasets, and is sensitive to high dimensionality and noise. AdaBoost is prone to overfitting in noisy environments or unbalanced datasets due to its tendency to continuously increase the weights of misclassified samples. Finally, the GBC is characterized by prolonged training times and high computational complexity, particularly when handling large datasets. It is also susceptible to overfitting if hyperparameters are not adequately optimized, especially in the presence of noisy data. Traditional methods struggle to achieve same-layer capabilities in spatio-temporal problems, mainly due to their inability to connect nodes within the same layer. In contrast, RNN not only learn data features independently, but also allow the current state to receive feedback from the previous state (Li et al., 2021). Given the inherent correlations between asset data points, RNN can detect outliers in asset data more accurately than traditional methods.
4.2 Fault detection with GA-Att-LSTM algorithm 4.2.1 Principle of fault detection for edge-cloud collaborationIn fault detection for IIoT facilities, the GA-Att-LSTM model is proposed. Figure 8 illustrates the calculation process which is primarily divided into three layers: system data acquisition, network model training, and fault detection.
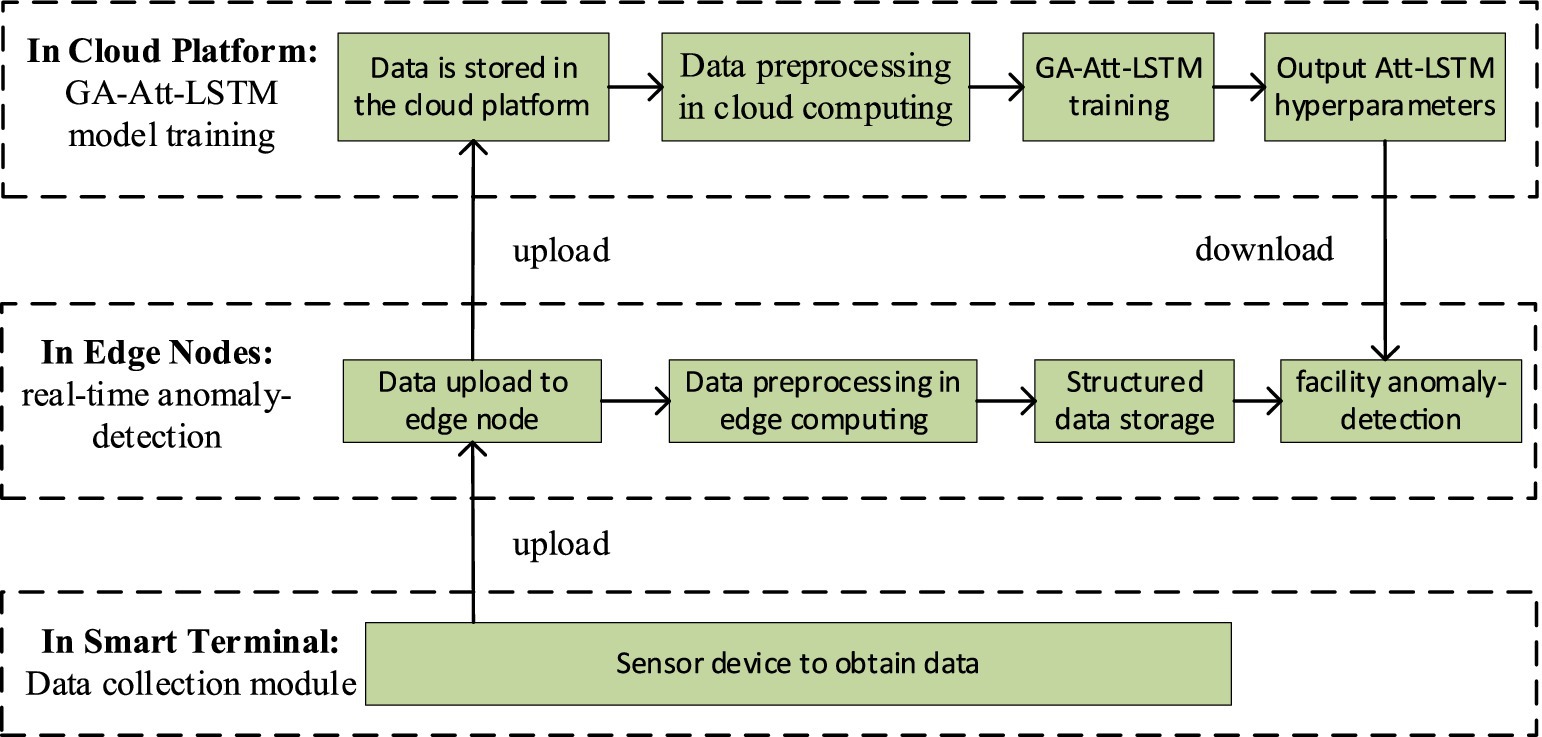
Figure 8. Fault detection process of the GA-Att-LSTM model in IIoT facilities.
4.2.2 Data acquisition stageData acquisition layer establishes connections between the control system, sensor system, system integrated control, and other core nodes in industrial equipment, which mainly rely on industrial ethernet, edge gateways, various sensor devices to communicate with the system. In the process of sensor data acquisition, the data acquisition layer connects the core nodes of industrial equipment such as control systems, sensor systems, and system integration control. These nodes mainly rely on industrial Ethernet, edge gateways, and different kinds of sensor devices to communicate with the system. Therefore, the control system gets operation data of the equipment, which is acquired by the sensor nodes periodically through the network. The data vector generated by node at time t are shown in Equation (10).
xit=xi,1txi,2txi,3t…xi,jtT (10)where j is the number of physical variables monitored by node i .
Usually, the sensor data are uploaded to the cloud platform for storage, calculation, and analysis. However, this transmission process takes a long time. As a result, equipment may be damaged due to delayed data transmission. To solve the above problems, we deploy business data that needs to be processed in a timely manner on the edge platform, which can alleviate the huge pressure of massive data on the network bandwidth and satisfy the demand of connected devices for low latency. Further analyzed from a security perspective, the risk of leaking sensitive data during transmission on the public network is avoided because industrial data are stored and analyzed on the edge platform.
4.2.3 Training model hyperparameters in the cloud server service layerThis article utilizes the GA-Att-LSTM model, which is mainly composed of an input layer, a hidden layer and an output layer. During the training phase, the large amount of data consumption requires significant computing resources such as memory, CPU, and hard disk. To mitigate this, training takes place in the cloud service layer. Following this, the trained network parameters (weights, biases, etc.) are passed to the edge computing node, where real-time facility fault detection is performed. Finally, the prediction result is outputted and the relevant response (alarm, shutdown, automatic cooling, etc.) is executed. The historical data stored in the cloud service layer is used as the training data for the model, then the data matrix of sensor node at time is represented as shown in Equation (11):
Xi=xi1xi2xi3…xit−1xit (11) 4.2.4 Real-time fault detection process in the edge node layerThe computational process of the fault detection model proposed in this article is clearly defined. First, the edge computing system preprocesses the state data collected by sensors from industrial equipment. Next, the GA-Att-LSTM model is employed to assess the abnormality of the equipment. The steps are as follows:
Step 1: Obtain and preprocess sensor data.
Step 2: Split the dataset into training and testing sets using cross-validation.
Step 3: Extract important features from both the training and testing sets.
Step 4: Initialize the parameters of the GA-Att-LSTM network model.
Step 5: Train the GA-Att-LSTM model using the training and testing sets.
Step 6: Output the classification results regarding the operational conditions of the industrial equipment.
5 Experiment validation and discussion 5.1 Dataset descriptionTo evaluate the efficiency of the proposed GA-Att-LSTM model in IIoT fault detection, we utilize a publicly available machine failure dataset provided by BigML (Huang and Guo, 2019). This dataset consists of 8,784 entries and 28 features, categorized into seven date variables, fifteen numerical variables, and four string variables.
5.2 Data preprocessingData preprocessing is crucial in fault detection, as sensor data from equipment may encounter issues such as noise, missing values, inconsistencies, redundant data, and class imbalance. These challenges must be addressed through preprocessing techniques to enhance the accuracy of analysis and prediction. Figure 9 illustrates the framework for data preprocessing.
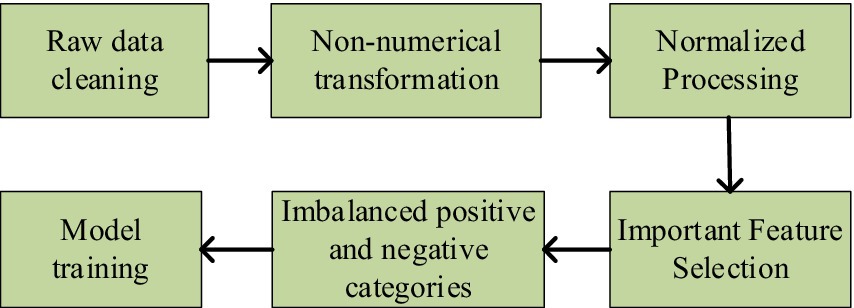
Figure 9. The proposed framework for data preprocessing.
As shown in the figure above, the data preprocessing process outlines five key steps. Firstly, data cleaning is performed to remove noise and incomplete entries. Next, non-numerical data is transformed to ensure consistency. Next, normalization is applied to enhance data uniformity. Subsequently, important features are selected to improve model performance. Finally, the issue of imbalanced positive and negative categories is addressed to ensure more accurate predictions. The specific steps are detailed as follows:
5.2.1 Data cleaningUsually we use raw data which may have problems like redundancy, missing, garbled etc. Therefore, we need to perform deletion, averaging, filtering and other measures before using the data.
5.2.2 Non-numerical transformationOne-hot encoding is a technique that transforms discrete features into binary vectors in Euclidean space, enabling classifiers to better process categorical data. By mapping each unique value to a binary representation, such as encoding eight operator values as vectors like [1 0 0 0 0 0 0 0] for operator1, this method enhances feature representation and increases dimensionality.
5.2.3 Normalized processingThe data are normalized, i.e., the eigenvalues of the sample are converted to the same dimension, and the range of values of each feature is mapped uniformly linearly to the interval [0,1]. The normalized formula is shown in Equation (12).
x¯i,qt=xi,qt−minxi,qmaxxi,q−minxi,q (12)where xi,q=xi,q1xi,q2xi,q3…xi,qt−1xi,qt represents the physical variable qmonitored by the sensor node i and the historical data vector stored in time t . maxxi,q and minxi,q are the maximum and minimum values of xi,q respectively. The optimization process of the optimal solution will obviously become smoother and it will be easier to correctly converge to the optimal solution after the error data cancel the errors caused by different dimensions during training and after the data are normalized.
5.2.4 Important feature selectionWhen the data collected by various sensors involve multiple feature values, not all data’ feature is helpful to the prediction of facility failure. To improve calculation efficiency, this article only selects the 20 important features that are closely related to the equipment operation state by using the random forest classifier method. The important feature values are defined in Figure 10.
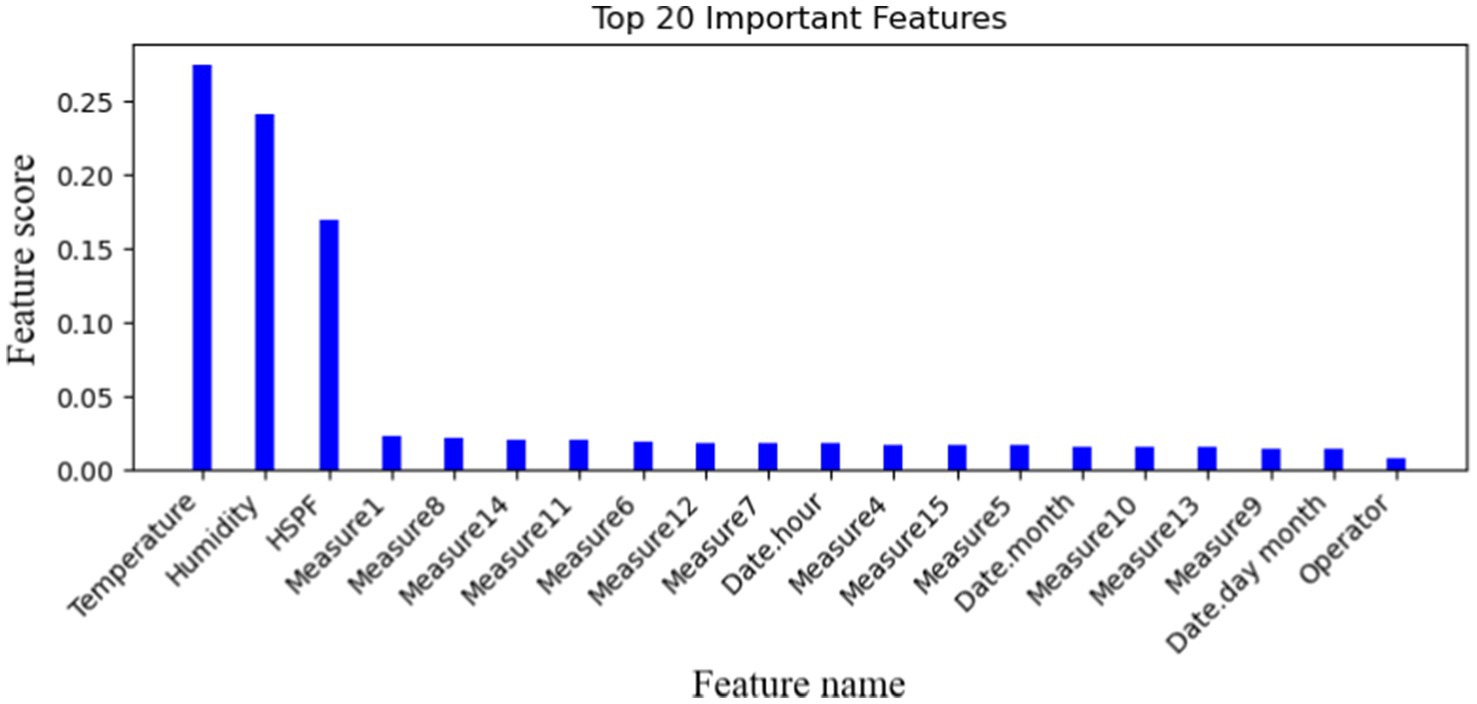
Figure 10. The most important 20-dimensional features proposed.
5.2.5 Imbalanced positive and negative categoriesThe failure feature is utilized as a label and is composed of two values: yes and no. “No” represents the normal operation of the facilities and refers to positive samples, while “yes” indicates that the device is functioning abnormally and refers to negative samples. After conducting a statistical analysis, the dataset shows that the ratio of positive samples to negative samples is around 107:1. It is important to note that the raw dataset is extremely imbalanced since there are significantly more normal records. In particular, we utilized the synthetic minority oversampling technique algorithm (SMOTE) to preprocess the data and balance the number of normal and failure cases. This entailed increasing the number of failure label samples through interpolation to eliminate category imbalances in the training set. Figure 11a depicts the actual ratio of positive and negative samples in the database, while Figure 11b illustrates the ratio of positive and negative samples after preprocessing.
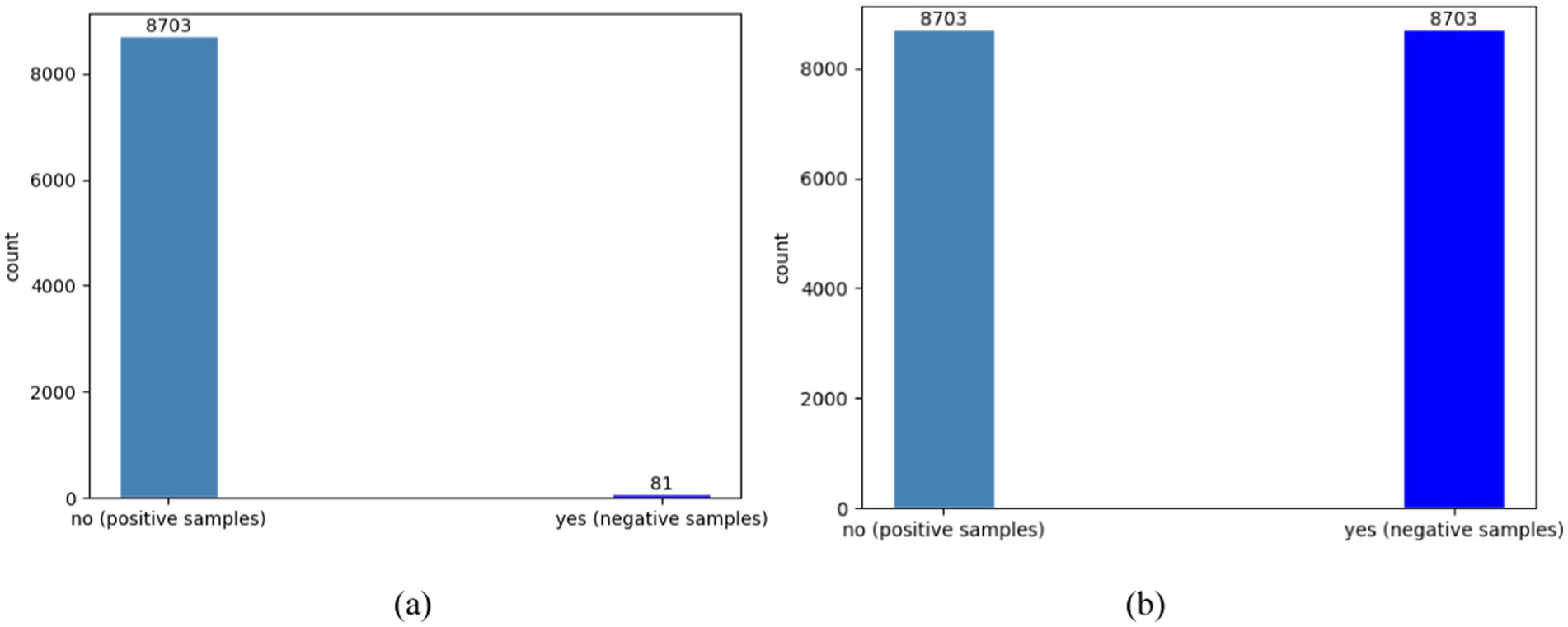
Figure 11. The comparison of positive and negative sample counts before and after optimization using SMOTE. (a) The original number of samples; (b) the number of samples after preprocessing.
5.3 Validation and evaluation of performanceIn this paper, common classification metrics are used to evaluate t
留言 (0)