
記住我
Research on robot control has been an active area of investigation for several decades, with applications in a wide range of fields including hazardous environments (Tsitsimpelis et al., 2019), disaster relief (Norton et al., 2017), deep space exploration (Diftler et al., 2012), and deep sea exploration (Khatib et al., 2016). With the advent of deep learning techniques, automatic control methods have undergone significant advancements in recent years. These methods often excel in controlling efficiency for a single purpose and within a specific scenario, achieving high efficiency of manipulation. However, they lack task adaptability, particularly when it comes to achieving specific grasps for the same object based on different usage intentions (Brahmbhatt et al., 2019). The integration of human intelligence enables robots to increase the variety of objects used and effectively deal with unpredictable problems in unstructured environments (Hokayem and Spong, 2006). Therefore, the use of human intelligence in teleoperation methods has also received extensive research attention (Moniruzzaman et al., 2022). Both of these methods have their respective advantages in terms of task efficiency and adaptability.
In Figure 1, we investigated the efficiency and adaptability of different control methods and compared them with human performance, all depicted on logarithmic scales. Reasonably, direct human hand grasping demonstrates the highest efficiency and adaptability. Despite modern automatic control algorithms achieving planning times under 1 second (Morrison et al., 2018), their overall work efficiency remains an order of magnitude lower than human operation, particularly noticeable with objects under 8 cm in size, limited by clamp size. Teleoperation can adapt to object sizes similarly to human, with peak efficiency occurring around medium-sized objects, approximately 4.5 cm in size. As objects deviate from this range in either direction, teleoperation efficiency declines, as indicated by the green bold curve.
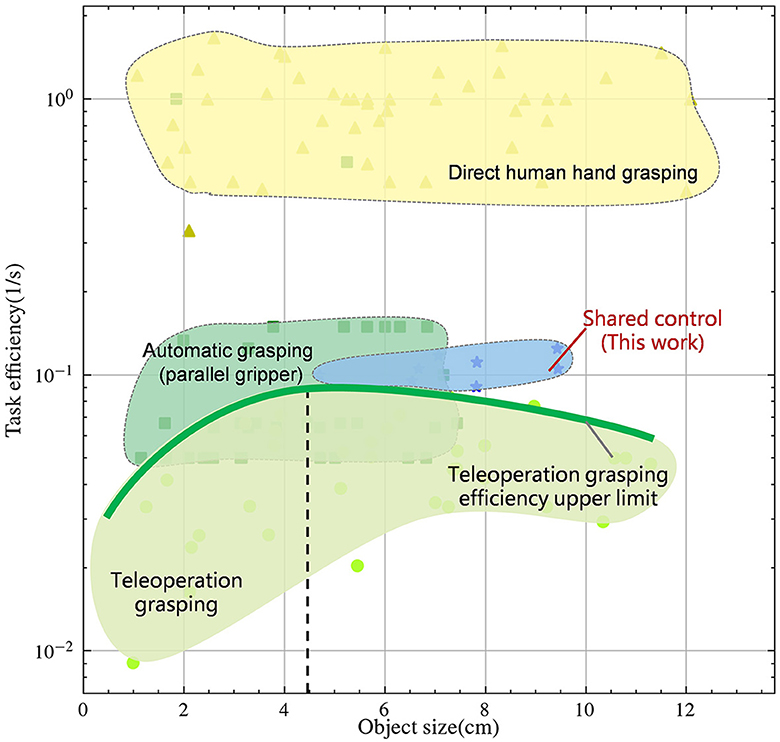
Figure 1. Task efficiency-Object size relationship between direct human control, auto control and teleoperation in logarithmic scales. Detailed data are in the Supplementary material.
Data-driven grasp synthesis are widely used in robotic grasping and manipulation (Mahler et al., 2017, 2019; Morrison et al., 2018). Grasping strategies using parallel clamps and suction cup grippers have been widely used. This approach often utilizes supervised learning to sample and rank candidate grasps. The synergy of precise object positioning through automatic control and the low-dimensional end effector enables rapid grasping. Nonetheless, as shown in Figure 1, this approach is limited by the size of end effector and cannot accommodate objects of all sizes. In recent years, there has been a widespread adoption of model-based approaches (Nagabandi et al., 2019) and model-free reinforcement learning techniques (Chen et al., 2021). These methods leverage deep learning techniques to facilitate the learning of dexterity in multi-fingered hands to enhance the adaptability of this method. However, these methods are known to face challenges due to the high dimensional search space, resulting in low success rates and robot hand configurations that do not emulate natural human movements. As an alternative, learning with demonstration (Rajeswaran et al., 2018) has shown promise as a method to reduce search space and increase the success rate. However, the quality of the demonstration data is often a bottleneck in this approach. Although current state-of-the-art automatic control algorithms have demonstrated success in solving specific tasks and adaptability to objects of various sizes, they still face challenges when it comes to handling unpredictable scenarios. Even with recent advances in deep learning, the challenge of achieving human-like dexterity and adaptability in robotic control remains an open research question, requiring further investigation.
Human-in-the-loop can adapt to complex scenarios with the help of cameras, monitors, motion capture system, etc. It has been shown to be a promising method for achieving high-level control of robots, particularly in tasks that require human-like dexterity and adaptability. As illustrated in Figure 2, due to the highly anthropomorphic structure of the end effector, which resembles the human hand, this approach achieves versatility in grasping objects of all sizes, making it a widely adopted method in robot grasping and manipulation. In addition, research has shown that contact location is largely dependent on post-action with objects (Brahmbhatt et al., 2019). However, teleoperation has certain limitations that need to be addressed. One of the principal hurdles stems from the inescapable sensor noise and communication channel delays (Farajiparvar et al., 2020), which may precipitate a surge in failure rates. Another concern pertains to the dearth of substantial feedback, potentially resulting in reduced operator immersion and an upsurge in time and labor requirements throughout the operation (Moniruzzaman et al., 2022). These limitations have caused teleoperation to operate significantly below human-level efficiency. Fishel et al. (2020) found the performance of the world's most advanced human operator piloting the telerobot to be anywhere from 4 to 12 times slower than that same operator with their bare hands. As such, the shared control method (Kim et al., 2006) has been proposed as a means of combining the advantages of both methods to achieve “fast and accurate” grasping and tool use.

Figure 2. Shared control systems can accomplish different kinds of tasks, e.g., interacting with the cup for different functional intent: use (A) and handoff (B); holding the clamp (C); extrusion nozzle of windex bottle (D).
For human, individuals do not possess exact knowledge of the object's position, but instead receive information about the relative position of the human hand and the object, and subsequently send high-frequency velocity commands to the hand to complete the task (Jeka et al., 2004). However, when the end effector changes from a human hand to an anthropomorphic hand, the change in mechanism and the increase in delay and noise make control challenging. This can lead to a prolonged operation time and a decreased success rate. In this study, we proposed a shared control framework for robotic grasping tasks. The proposed approach combines the advantages of both human and automatic control methods and aims to achieve a balance between performance and adaptability. This study proposes integrating a camera into the teleoperation system to infer the position and size of the object, thereby enabling automatic control to initialize the grasping position. The human operator then takes over control for the adaptability as the human control.
To demonstrate the effectiveness of this proposed approach, a model was constructed to compare the performance metrics of shared control, human control, and automatic control in the presence of noise. It is assumed that the velocity during the operation follows a linear relationship (Jerbi et al., 2007), where the speed of the motion is proportional to the distance from the target position. The modeling results indicate that the shared control method exhibits similar trajectory smoothness and speed as the automatic control method and similar grasping accuracy as the human control method, thus achieving a balance between performance and adaptability. Furthermore, the impact of delay and error on the system was analyzed. The results indicate that only large delays have a significant impact on the system due to human involvement.
This work presents a shared control framework that combines human intelligence and automatic control to improve the performance of robotic grasping tasks in unpredictable environments, as shown in Figure 2. Our main contributions include:
(1) This work proposes a human-robot shared control method by integrating human control with autonomous control. The simulation and practical deployment of this method demonstrates that it effectively resolves the conflict between efficiency and adaptability.
(2) A linear dynamic model was established to quantitatively analyze the performance of the three control strategies.
(3) The proposed quantitative analysis method has been further extended to analyze the impact of delays and position estimation errors on human-in-loop systems.
2 Related workResearch in the field of shared control and teleoperation with assistance aims to enable robots to help operators complete desired tasks more efficiently. In teleoperation with assistance, the system primarily helps to simplify and facilitate the user's manual input, ensuring the user retains direct control over the device. In contrast, shared control systems aim to understand and predict the user's intent, allowing the system to autonomously perform some tasks and reduce the cognitive load on the user.
Recent advancements in machine learning techniques have led to the development of methods such as glove-based (Wang and Popović, 2009) and vision-based (Handa et al., 2020) tracking to achieve accurate joint position tracking. The structural differences between human and robot hands have led to the proposal of techniques such as kinematic remapping (Handa et al., 2020) and retargeting (Rakita, 2017), which simplify the manipulation task and allow the execution of complex manipulation tasks beyond simple pick-and-place operations.
To provide operators with sufficient feedback to understand the situation and provide a suitable control interface for efficient and robust task execution, haptic feedback and model prediction (Lenz and Behnke, 2021) have been incorporated into the systems, significantly increasing work efficiency. Despite this, operators may still experience prolonged task completion times when working in close proximity to the environment, and may encounter difficulties when working remotely due to increased latency and an incomplete visual field. To address this, researchers have proposed methods for robots to complete tasks autonomously.
Techniques such as those proposed in Zhuang et al. (2019), which aid in object grasping by maximizing the contact area between the hand and the object after collision, and in Rakita et al. (2019), which construct action vocabularies to predict intent based on user actions, limited by the quantity and quality of the action vocabulary, have been proposed. Furthermore, methods such as those outlined in Rakita (2017), which relax the constraint of direct mapping between hand position and orientation and end effector configuration to smooth out the motion trajectory, have also been proposed. However, there remains a dearth of research on techniques that automatically adjust trajectories to reduce energy expenditure by operators and improve the efficiency of robot systems.
3 MethodologyThe output of the robot performing the grasping task includes the wrist's pose (P, Φ) and hand's joint angle θ. Current control methods are categorized into automatic control, teleoperation, and shared control. Shared control is a method that combines the advantages of both automatic control and teleoperation, which synergizes human intelligence with automation to optimize task performance and efficiency. As depicted in Figure 3, the system consists of two distinctive modes: Human-Operator Control Mode and Automatic Control Mode. In Human-Operator Control Mode, the target pose of the robot wrist is (PHtarget,ΦHtarget) and the hand's joint angle is θHtarget, which are controlled by the operator's wrist pose (PH, ΦH) and hand angle θH. This comprehensive system harnesses the operator's cognitive capabilities to adeptly select objects and the appropriate manipulation methods, especially within complex environments. In Automatic Control Mode, the target pose of the robot wrist is (PAtarget,ΦAtarget), where the thumb of the robot hand aligns with the edge of the object. The position and size of the object is estimated through the changes in the robot wrist pose (PR, ΦR) and image y. Thus, the shared control combines the two methods to achieve control of the robot (PStarget,ΦStarget,θStarget).
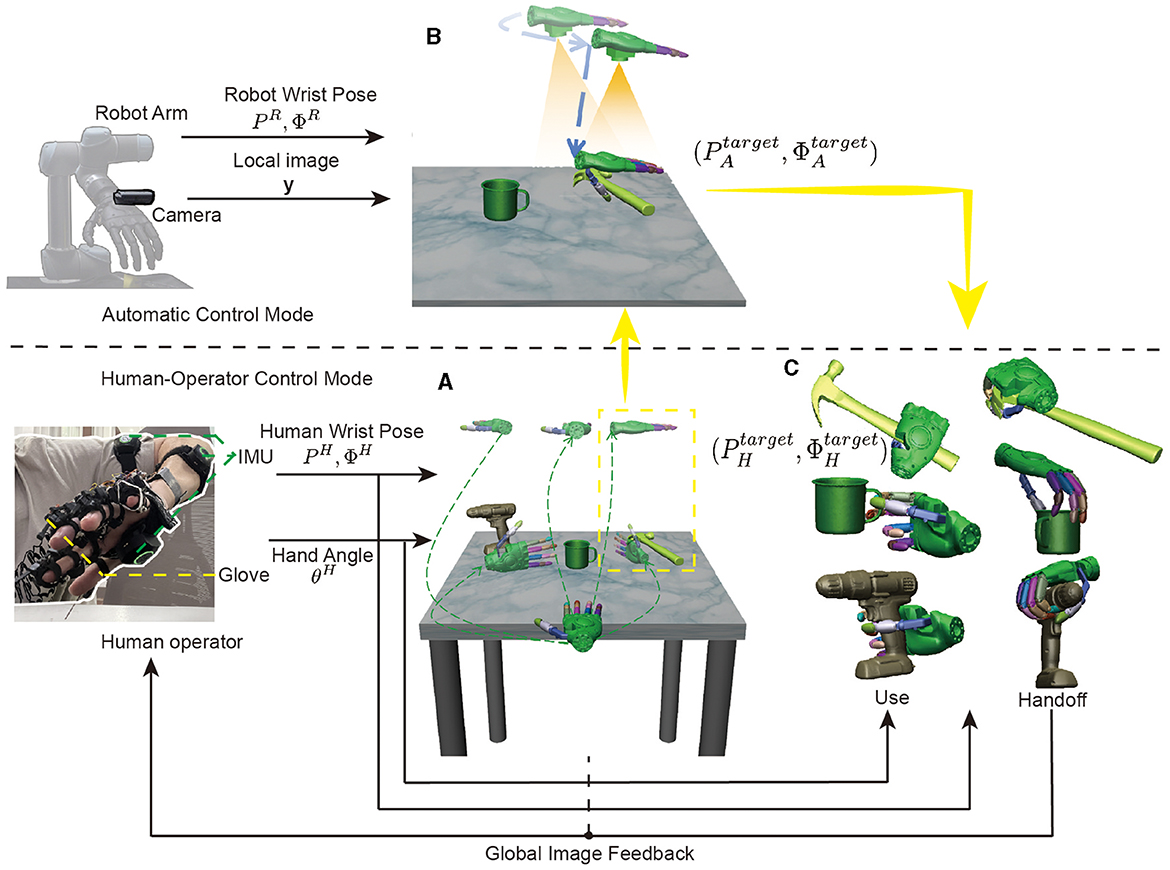
Figure 3. Overview of the shared control architecture for object grasping. (A) The operator uses the inertial measurement unit (IMU) to obtain the pose of the wrist (PH, ΦH) and the data gloves to obtain the position of the hand joints θH to select the target object. (B) is the Automatic Control Mode, which estimates the position and size of the object through the changes in the robot wrist pose (PR, ΦR) and image y, and then gives the robot wrist command (PAtarget,ΦAtarget), where the thumb of the robot hand aligns with the edge of the object. (C) The human operator resumes control to choose the robot wrist pose (PHtarget,ΦHtarget) based on the specific purpose of use, such as picking up or handing off the object.
The entire shared control process is shown in Figures 3A–C. Firstly, as shown in Figure 3A, there are three objects on the table from the YCB database: a power drill, a cup, and a hammer. The operator uses the image feedback from the global camera to select the object to be grasped and the direction of the object to be grasped, as shown by the different trajectories in the figure.The operator's finger and external joint instructions are seamlessly transmitted to the robot via a data glove and a motion capture device. Suppose that we have chosen to grasp the hammer from the top down, then as shown in Figure 3B, the automatic control mode takes over the program seamlessly. Initially, the manipulator is moved to align the object within the field of view through visual positioning, followed by a downward movement to compare pre and post movement image changes, enabling accurate depth information retrieval. This valuable data guides the manipulator to an optimized initial position for grasping. Finally, as illustrated in Figure 3C, the operator strategically considers the purpose of use and hand off, adeptly adjusting the grasping position to successfully complete the manipulation task.
3.1 Human-operator control modeIn this mode, the operator leverages their cognitive abilities and physical movements to guide the robot's actions. The system implemented in this study incorporates a human-operator control mode, which facilitates selection of the target object and the manipulation method. As it is challenging to parse control signals directly from the human brain, a motion capture device was designed to interpret brain signals and transmit commands to the robot. This device includes data gloves for recording the position of finger joint and IMU for recording the position of arm joint, as the operation-site depicted in Figure 4. The data gloves use serial communication, and the IMU uses Bluetooth communication. video is available in the Supplementary material.
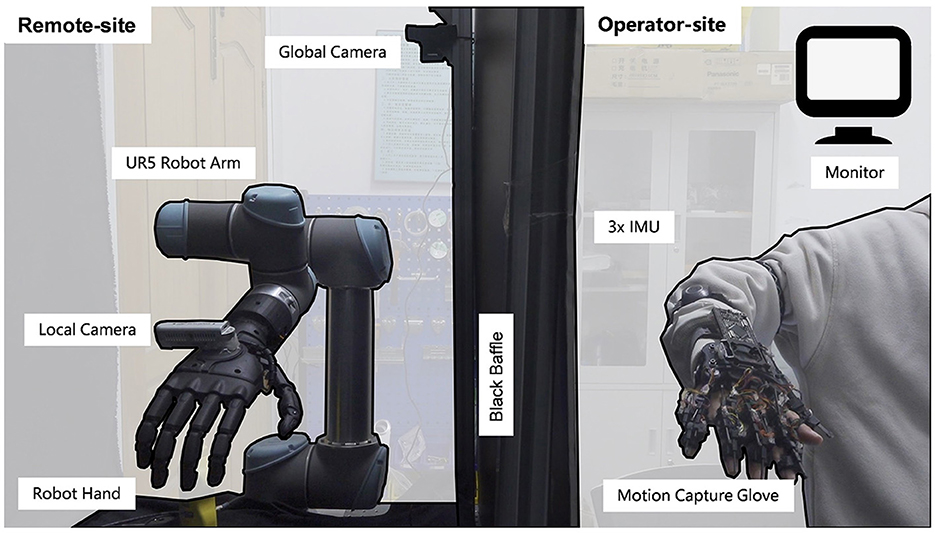
Figure 4. The hardware platform for shared control. The Remote-site and the operator-site are separated by a black baffle. The left half is remote-site and the right half is operator-site. The remote site consists of an UR5e robot arm and a custom robot hand to interact with the environment, a local camera to estimate the position and size of objects, and a global camera to provide feedback. The operator-site consists of three IMUs for obtaining the arm joint position and gloves for obtaining finger joint position.
The shared control hardware platform comprises of an operation-site and a remote-site with a delay of approximately 30 ms. The remote site comprises a robot arm and a custom robot hand (bin Jin et al., 2022), which is optimized to replicate the natural movement of the human hand, and is equipped with 6 active and 15 passive degrees of freedom. The custom hand is designed to adapt to the shape of objects and has a loading capacity of 5 kg. Furthermore, it passed 30 out of 33 grasp tests on everyday objects according to the taxonomy of Feix et al. (2016), demonstrating its suitability for manipulation and using objects in daily life. The remote-site also includes a local camera Realsense D435 for estimating the position and size of objects, and a global camera logitech carl zeiss tessar hd 1080p for providing feedback to the operator.
In the operation site, a full-degree-of-freedom data glove is employed to record 20 finger joints with high precision (< 1 accuracy). The pip joint, which offers the largest workspace, controls the bending of the fingers. Moreover, the ab/ad joint directly corresponds to the respective human hand joints. To mitigate the jitter effect during hand movement, a low-pass filtering method is applied for a smooth and stable hand motion.
The robot hand's palm pose is entirely governed by the human hand's wrist. The control signal is derived from the wrist's pose relative to the shoulder, inferred from the angles of the arm joints recorded by three inertial sensors secured to the arm. Specifically, three IMU sensors are attached to the upper arm, forearm, and wrist to measure the angle information of the shoulder joint, elbow joint, and wrist joint. With the shoulder joint as the reference point and considering the arm's length information, the position and posture of the wrist joint relative to the shoulder are calculated for system control.
In a two-dimensional visual field teleoperation system, inefficiency can significantly arise from the operator's inadequate ability to perceive depth. Figure 5, depicts the depth estimation test of the operator. Figure 5A is a test scenario in MuJoCo, where the red ball represents the actual position of the wrist, with a diameter of 1.6 cm; the green square is the target position of the wrist, with a side length of 2 cm, and each test varies randomly within the range x, y, z∈ [–5 cm, 5 cm]. The operator estimates the depth by comparing the size of the objects in the field of view. The camera's field of view direction is vertically downward along the z-axis, and the initial distance from the target position is 50 cm. Two groups of experiments were conducted with different operators, each experiment being conducted 20 times, resulting in the outcome shown in Figure 5B. The average error was 2.4 cm, and the fluctuation range was large. Among them, 30% of the results exceeded a range error of 5 cm, which would significantly reduce the success rate of the task.
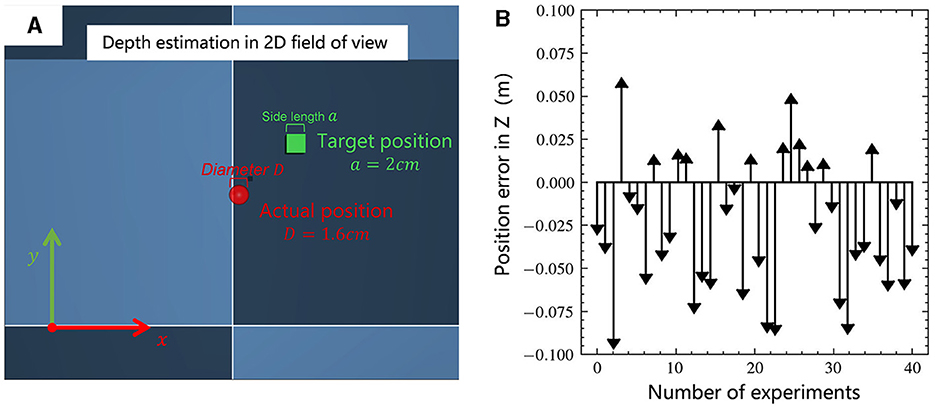
Figure 5. (A) Teleoperation of a two-dimensional visual field depth estimation scenario, with the goal of aligning the center of the red ball with the center of the green square; (B) Statistical results of the position error in depth direction.
3.2 Automatic control modeThe Automatic Control Mode employs the camera to verify the spatial position of the target object for grasping and subsequently initializes the position of the robot hand. Once the target object is detected within the local camera's field of view, the Automatic Control Mode is activated. The robot hand is then moved to align the camera's center with the object's center, while keeping their relative posture unchanged.
The cornerstone of this feedback control system lies in the precise measurement of the object's size and spatial measurement relative to the hand. To achieve this, a monocular vision method is employed in conjunction with the high-precision position measurement of the robot arm. This combination ensures accurate and reliable detection of the target object's location and size, enabling the system to execute manipulation tasks with efficiency and precision.
In Figure 6A, the high-precision position measurement of the robot arm is used to record position differences before and after movement, along with changes in the object's image size, facilitating the inference of the object's information. Derived from the pinhole imaging principle, we can obtain the following two algebraic relationships:
In the above two formulas, the pixel length h1, h2 of object is known using the minimum area rectangle; The focal length of the camera f and the distance d2 moved by the robot arm. So we can get the real geometry length H of the object:
H=h1h2d2f(h1-h2) (3)As illustrated in Figures 6B, C, this method can accurately estimate the size of the object H and the distance d1 between the object and the camera, reducing both depth distance estimation and object size estimation to less than 1 cm. Based on these two pieces of information, the automatic control method can achieve autonomous positioning of the robot wrist location, reducing the wrist position error in the depth direction from 2.4 cm to less than 1 cm, thus enhancing the efficiency and success rate of the task.
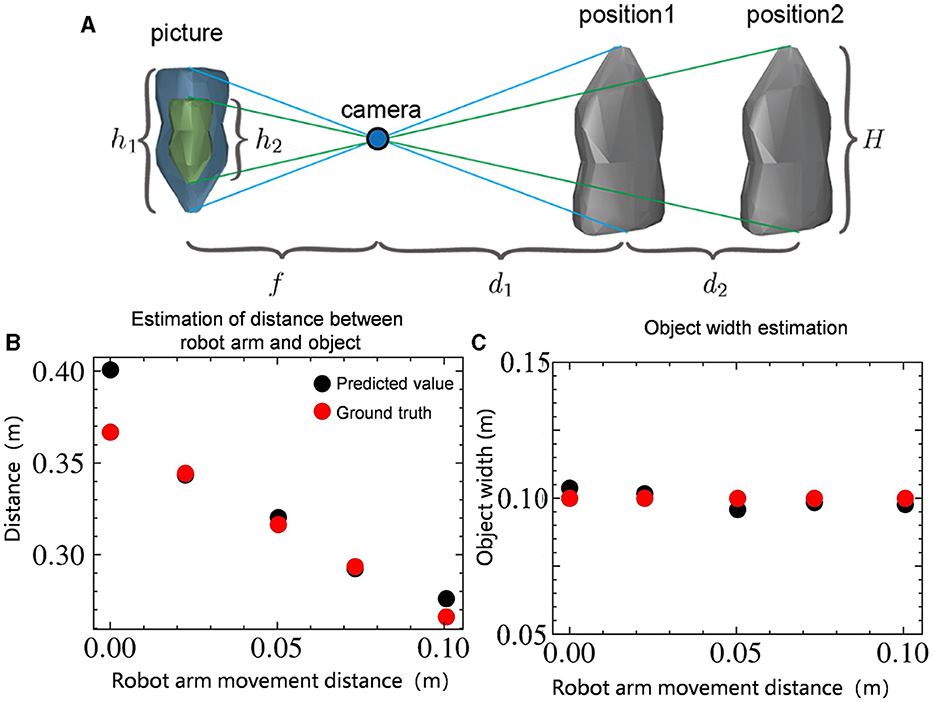
Figure 6. (A) Infer the position and size of the object based on the camera imaging principle. H represents the actual length of the object. h1 and h2 represent the pixel length of the object. f represents the focal length of the camera. d1 represents the distance of the object from the camera and d2 represents the distance moved. (B) Estimation of distance d1 between the size of the object and the camera. (C) Estimation of size of the object H.
After successfully aligning the camera with the target object, following the aforementioned pinhole imaging principle, the robot proceeds to approach the object. Throughout this phase, the system continuously calculates the size and centroid position of the object. The robot diligently continues this approach until the distance between the hand and the object reaches a predefined threshold. At this point, the robot transitions to the target position, as illustrated in Figure 3B, where the thumb of the robot hand aligns perfectly with the edge of the object. This precise alignment facilitates subsequent operational tasks, such as grasping, manipulating, or interacting with the object effectively and accurately. Automatic control provides an effective initialization of the robot's position, thereby improving overall task performance by minimizing errors and increasing the success rate of subsequent actions.
3.3 Shared control frameworkThe shared control framework adjusts the proportional coefficient α of the above two control methods to manage the robot wrist pose (PStarget,ΦStarget).
(PStarget,ΦStarget)=α(PAtarget,ΦAtarget)+(1-α)(PHtarget,ΦHtarget) α={1, target object is detected and |PAtarget-Phtarget|<0.3m0, otherwise (5)As shown in Equation 5, the proportional coefficient α is a binary variable. When the target object is within the local camera's field of view and the position commands of both control methods are within 30 cm of each other, the proportional coefficient is set to 1, utilizing the Automatic Control Mode. If a discrepancy occurs, the operator can send a position command opposite to the automatic control to increase the distance beyond 30 cm, causing the program to revert to Human-Operator Control Mode for object reselection. Additionally, when the target object is not detected or after the Automatic Control Mode has completed, the proportional coefficient α is set to 0, switching to the Human-Operator Control Mode.
As illustrated in Figure 7, the process of grasping an object using shared control alternates between the two control modes. Figures 7A, E, F all utilize the Human-Operator Mode. Specifically, Figure 7A represents the search for the target object, while Figures 7E, F indicate the adjustment of the wrist's pose during grasping. Figures 7B–D shows the process of the robot wrist approaching the object in the Automatic Control Mode. In the local image, object segmentation and detection are carried out using OpenCV algorithms. The process begins with Gaussian blur to reduce image noise, followed by conversion to grayscale. Otsu's thresholding method (Otsu, 1979) is then applied to segment the target object from the background. Rectangular contour detection is used to identify the object's outer contour, as indicated by the red rectangle in the figure. This allows for the calculation of the object's position on the plane to align the object's center with the camera. Finally, based on the pinhole imaging principle, two images are obtained by moving the robotic arm to a fixed position, and the estimate of object's position and size information is derived, as shown in Figures 7C, D.

Figure 7. Implementation of the shared control framework in physical systems. (A, E, F) Are Human-Operator Mode, (B–D) are Automatic Control Mode.
Using this shared control method for object grasping significantly improves the process's efficiency. While maintaining task adaptability, the task completion time is reduced to approximately 10 seconds.
4 System analyzeIn order to evaluate the performance of the three control methods, namely automatic, teleoperation, and shared control, a system identification method was employed to model the operation process to get quantitative metrics. Furthermore, the impact of errors and noise on the system was also analyzed. The system identification method is a widely used technique in control systems that can be used to identify the dynamic characteristics of the system by analyzing the input-output data of the system.
The results of the modeling indicate that the shared control method combines the advantages of the other two approaches and compensates for their respective limitations. Specifically, it not only exhibits fast grasping speed and smooth trajectories, similar to automatic control, but also maintains high grasping accuracy through the incorporation of human intelligence. This highlights the potential of the shared control method in improving the performance and efficiency of robot systems in real-world scenarios.
4.1 ModelingInspired by Jeka et al. (2004), velocity information is more accurate than position and acceleration. Therefore we assume that this system is a linear system and the velocity is proportional to the distance from the target position. The mathematical model of the system can be represented by the following equation:
x(t+ΔT)=x(t)+(xref(t)-x(t))vΔT+e(t) (6)This equation can be transformed into the following form:
x(t+ΔT)=(1-vΔT)x(t)+vΔTxref(t)+e(t) (7)In Equation 7, the target position xref(t) is represented by the input variable u(t) and can be considered as an input quantity of the linear stochastic dynamical system. The variable x(t) represents the current position, ΔT represents the time step, the scale factor v represents the proportionality constant between speed and distance, and e(t) represents the noise present throughout the process, which can affect the smoothness of the trajectory.
As illustrated in Figure 8, there are red, green, and blue balls in the image. The goal is to move the red ball to the position of the green ball. The red ball represents the current position x(t) of the robot hand, the green one represents the actual target position xref(t), and the blue one represents the observation target position y(t) due to the presence of noise in the environment. The variable δ represents the grasping inaccuracy, which is the distance between the final position and the target position.

Figure 8. The modeling of robot system. The red ball represents current position of the robot x(t). The blue ball represents observation target position y(t). The green ball represents actual target position xref(t). The goal of the system is to move the red ball to the green ball. Black lines, yellow lines and orange lines represent automatic control, shared control and human control respectively. The distance δ between the final position of the system and the target represents the grasping inaccuracy.
4.2 System identificationAfter establishing the hypothetical model presented earlier, the method of system identification was utilized to fit the model. Figure 9 illustrates that the black line represents the target position, the red line represents the position of the robot hand, and the blue line represents the data predicted by the model. As shown in lower right corner of figure, the predicted position of the model is in close agreement with the actual position, indicating that it is reasonable to describe the whole system with a linear model.
[x(t+ΔT)y(t+ΔT)]=[1-kdx//1-kdy][x(t)y(t)]+ [kdx//kdy][ux(t)uy(t)]+[ex(t)//ey(t)] (8)The method of system identification was used to separately identify the system for the three control methods. The general system model is represented by Equation 8. In order to quantitatively compare
留言 (0)