Ethics
Adult patients who were admitted to the ICU in Galway University Hospital who had capacity were approached for inclusion in the study and informed consent for participation was obtained. Informed consent was taken by an investigating doctor conducted in accordance with the ethical principles outlined in the Declaration of Helsinki. Ethical approval for the study was obtained from the Galway University Hospital Research Ethics Committee on 27/7/2023(C.A. 2973).
Participants and dataset
We used clinical notes generated during each consecutive ICU admission. Notes were stored in an electronic health record system (Metavision®, Tel Aviv, Israel). Laboratory or radiology data were not included unless their findings were summarised in the clinical notes. The clinical notes were a combination of nurses’, doctors’, and pharmacists’ notes. The notes consisted of unstructured text, containing clinical terminology and abbreviations. The notes were divided into “sessions”, each of which was preceded by a header indicating the date and time of the entry. Before submission for processing by the LLM’s, the patient notes were fully anonymised by clinical staff and all personal identifiers were removed. Anonymisation of dates in each set of patient notes was performed by writing a program to subtract a random, fixed number of months from each date. This was necessary to ensure that the continuity of the timeline of the patient’s ICU stay was maintained.
Large language models
The LLM’s tested were ChatGPT, GPT-4 API, and Llama 2. Rationale for choice of LLM is outlined in the supplementary appendix. ChatGPT currently uses OpenAI’s GPT-4 large language model [11]. The version released on August 3, 2023 was used throughout this study. For GPT-4 API, at the time of development, the latest model was gpt-4-0613 and this was used in all experiments. The context window length of the model was 8000 tokens. The Llama-2-70b-chat model with the HuggingFace inference API was used for testing the capabilities of this model at performing the summarisation task. Since patient notes may be longer than the input length limits of LLMs, for the analyses with GPT-4 and Llama 2, the Langchain framework [12] was used to split and notes into manageable lengths, process them, and recombine outputs. ChatGPT had no programming interface to enable it to be used with Langchain, so documents were submitted as a series of smaller chunks.
Prompting and managing hallucinations
Alongside recent advancements in LLMs, prompt engineering has emerged as an effective, low-cost method of enhancing the quality of LLM outputs for specific tasks. Recent literature has investigated the application of prompt engineering to the healthcare domain, as a means of exploiting the potential of LLMs to extract information from large volumes of medical data [6, 21,22,23]. In this study, we used zero-shot prompting, whereby the prompt alone outlined the output requirements, without providing examples. To minimise creativity or diversity, temperature was set to zero or almost zero in the case of Llama 2 (see Supplementary Appendix). There was no limit of word count but instructions in prompts were to “generate concise summaries”. As noted in the Supplementary Appendix, we saw significant hallucinations in previous work [11], and in this work we carried forward prompting techniques to minimise them, such as prompting “Please ensure that the summary is based purely on information contained within the notes”, and by reducing temperature.
Development and evaluation
The development and evaluation are outlined in supplementary Fig. 1. The notes of five episodes were used in the development phase and the notes of the remaining six episodes in the evaluation phase (Supplementary Fig. 1). The outputs from each iteration were analysed by the clinicians involved in the development process (BM, JR, SH), who provided feedback which guided improvements. Prompts were iteratively developed, beginning with a baseline version which outlined the basic requirements for the summaries. These included instructing the model to highlight key interventions and developments, to use language suitable for a medical doctor and to only include information contained within the notes. Five iterations were carried out in total. Each iteration entailed generating a summary of a specific episode, which was then reviewed by clinicians. The prompt was updated to address the feedback provided by the clinicians and the summary was re-generated to confirm that the requested improvements had been included. Any summaries generated in previous iterations were re-generated each time the prompt was modified to verify that the results had not been adversely affected. Clinicians identified extraneous information within summaries, which was resolved by requesting a “concise” summary within the prompt. To generate notes relevant to a healthcare provider subgroup (doctor/nurse/pharmacy), prompts were generated stating that their notes should be given precedence for inclusion and headers distinguished between the types of notes generated by each healthcare providers subgroup. After addressing the feedback for the five episodes used in development, the prompt was finalised and used to generate summaries of unseen patient notes during the evaluation phase.
In the evaluation phase, three consecutive runs for each set of patient notes on each LLM were analysed by the clinicians involved in the development process (BM, JR, SH). They selected the best one in each case for evaluation by independent blinded evaluators (RJ, PM, JB, JL, CH).
Scoring
A checklist specifying essential information template for scoring LLM-generated summaries was developed from clinical notes by three investigators involved in the development process (BM, JR, SH). This was completed prior to evaluation of the generated LLM transcript. The scoring criteria included the presence of information and its correct placement within the summary.
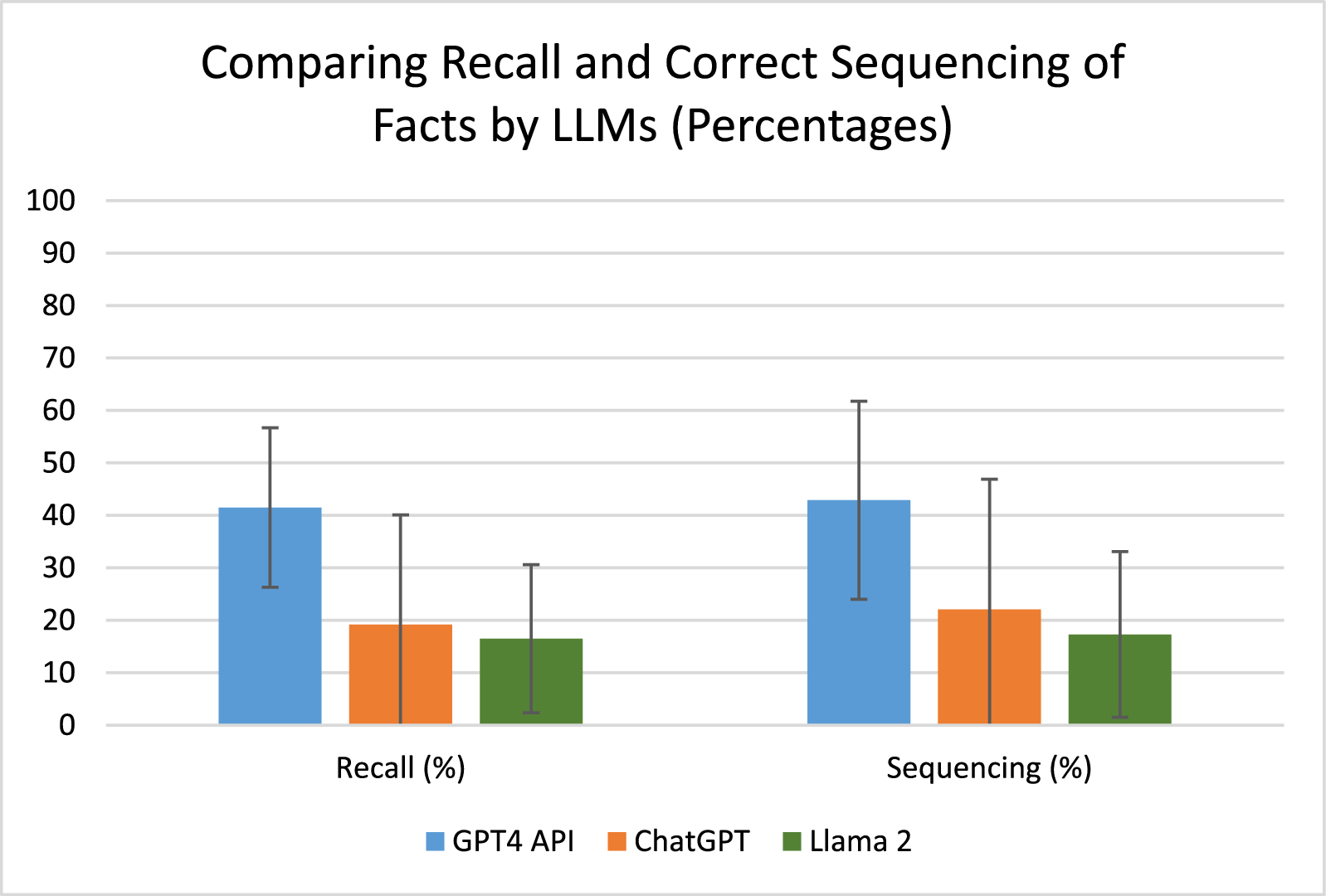
Each summary were scored on their inclusion of a pre-defined number of relevant clinical events. Evaluators assigned scores based on the accuracy of reporting of these events: 1 point for properly noted events, 0.5 points for partially noted events, and 0 points for omitted events. Additionally, the placement of each clinical event was scored: 1 point for appropriate placement, 0.5 points for moderately appropriate placement, and 0 points for inappropriate placement. The scores for both inclusion and placement were totalled, divided by the maximum possible score, and then converted to a percentage. Readability, organisation, succinctness, and accuracy were assessed using a five-point Likert scale, with 1 indicating the lowest and 5 the highest quality. Evaluators ranked the LLM summaries with 1 being the best and 3 being the worst. Definitions for readability, organisation, succinctness and accuracy of reporting and instructions for are outlined in supplementary appendix. Evaluators, who were not involved in LLM transcript generation, were provided with the checklist, all the patients’ data used to generate LLM transcripts, and patients’ chart numbers, so clinical data generated by LLM could be verified. Finally, a free-text column in which overall opinion on the summary was collected. Each evaluator was responsible for evaluating the 3 selected outputs for each of two sets of patient notes. The outputs for each set of patient notes were evaluated by two independent evaluators.
Statistical analysis
Quantitative variables are reported using either the mean and standard deviation (SD) for normally distributed data or the median and interquartile range (IQR) for non-normally distributed data. The non-parametric Kruskal–Wallis test was utilised for the comparison of ordinal and rank data. The Kappa statistic was calculated to assess interrater reliability between evaluators. Statistical significance was established at a p-value threshold of less than 0.05.



留言 (0)