
記住我
This study was based on data from the ESTHER study. The ESTHER study (Epidemiologische Studie zu Chancen der Verhütung, Früherkennung und optimierten Therapie chronischer Erkrankungen in der älteren Bevölkerung [German]) is a prospective cohort study conducted in Saarland, Germany. Participants were recruited during a general health checkup at their general practitioners (GP) between 2000 and 2002 and were followed up 2, 5, 8, 11, 14, 17, and 20 years after baseline. The study comprises 9940 men and women between 50 and 75 years. Details have been described elsewhere [20]. Sociodemographic baseline characteristics were similarly distributed in the respective age categories as in a German National Health Survey conducted in a representative sample of the German population around the time of recruitment [20]. The study was approved by the ethics committees of the Medical Faculty of Heidelberg and the state medical board of Saarland, Germany.
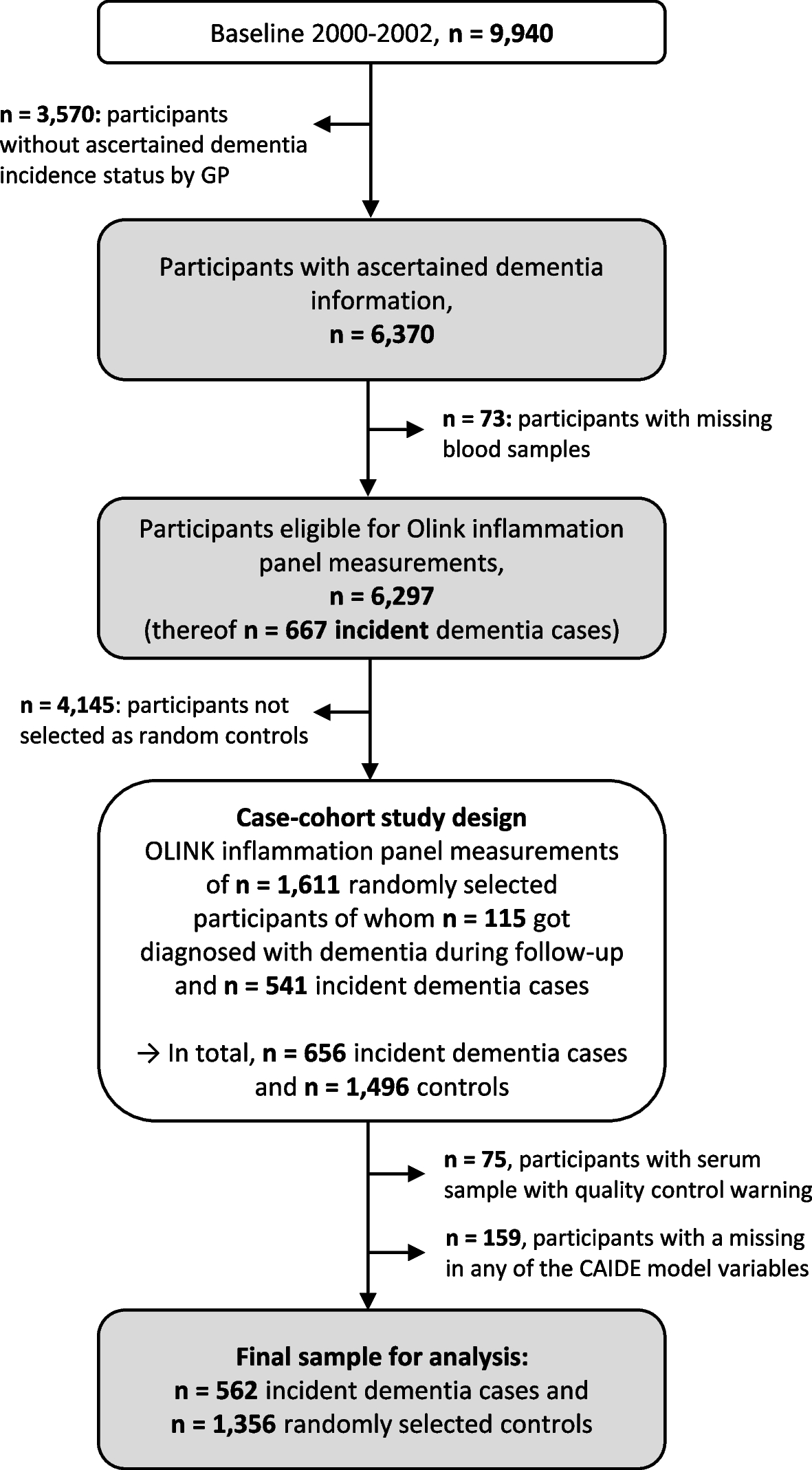
Dementia ascertainment and case-cohort design sampleDementia information was collected during the 14-, 17-, and 20-year follow-up (median (interquartile range) follow-up time: 16.3 years (13.5–17.0 years)) via standardized questionnaires sent to the GPs of the ESTHER study’s participants. In this questionnaire, the GPs were asked whether dementia has been diagnosed among their patients and, if so, to provide all medical records from neurologists, psychiatrists, memory clinics, or other specialized providers. This query was also sent to the GPs of study participants who had already dropped out due to ill health or death. Overall, information on whether dementia was diagnosed during 20 years of follow-up or not could be ascertained for n = 6,466 study participants (65% of the original cohort). A flowchart of the study population is shown in Fig. 1.
Fig. 1
Flowchart of dementia ascertainment during the 14-, 17-, and 20-year follow-up of the ESTHER study and study participant selection. Abbreviations: GP General practitioner
After excluding subjects with missing blood samples (n = 73) from participants with ascertained dementia information, 6,297 participants were eligible to be drawn for the case-cohort sample and measurements of the Olink Target 96 inflammation panel. The randomly selected sample consisted of 1,611 study participants, of whom 115 were diagnosed with dementia during follow-up. Among the remaining 4,686 study participants not randomly selected, 541 were incident dementia cases and added to the data set as well, resulting in 656 dementia cases overall. However, due to quality control warnings during the biomarker measurements, 75 participants were additionally excluded. Participants with missing data for any of the aforementioned CAIDE model variables were further excluded (n = 159). For the last exclusion step, we compared the data of included and excluded participants with respect to age, sex, and education, and no indication of selection bias was detected (Supplemental Table 1). The final sample included a total of 562 dementia cases and 1,356 controls.
Origin, assessment and modifications of the CAIDE modelThe CAIDE model originates from the CAIDE study, a population-based cohort study from Finland assessing cardiovascular risk factors, aging, and dementia [21]. For the development of the CAIDE model, 1,409 participants aged between 39 and 64 years of the original CAIDE study were included [10]. Of those, 61 developed dementia during 20 years of follow-up. CAIDE model 1 consists of the variables age, education, sex, systolic blood pressure, body mass index (BMI), total cholesterol, and physical activity, while CAIDE model 2 additionally includes APOE ε4 status.
In the ESTHER study, the CAIDE model variables age, sex, education, body mass index (BMI), and physical activity of participants were assessed during the baseline assessment by standardized self-administered questionnaires. The systolic blood pressure of participants was measured at baseline by the GP. Total cholesterol levels were measured from serum samples by an enzymatic colorimetric test with the Synchron LX multicalibrator system (Beckman Coulter, Galway, Ireland). APOE genotypes were determined by TaqMan single-nucleotide polymorphism (SNP) genotyping assays (Applied Biosystems, California, USA). Endpoint allelic discrimination reads were used to analyze genotypes with the Bio-RAD CFX Connect System (Bio-Rad Laboratories, CA, USA). In the case of missing directly genotyped APOE data (n = 70), imputed quality-controlled data was used. For details, see Stocker et al. 2020 [22].
All variables used in the CAIDE model were available but it needed to be newly calibrated because the ESTHER cohort has a different age range, school education history and physical activity assessment than the CAIDE study. Fractional polynomials were utilized to determine the best fitting function of the continuous variables in the prediction of all-cause dementia, AD, and VD [23] (data not shown). Because the linear function was the best fitting for systolic blood pressure and BMI, they were kept as continuous variables. Although the best fitting function was x(−2) for age and total cholesterol for all-cause dementia and VD, they were still modelled with the linear function because the difference in model fit was small. Education, physical activity, and APOE genotypes were dichotomized by summarizing categories with very similar odds ratios (ORs) for the association with all-cause dementia (data not shown).
Measurement of inflammation-related biomarkersLevels of inflammation-related proteins were measured in baseline serum samples using the Olink Target 96 inflammation panel (Olink Proteomics, Uppsala, Sweden). Details are described in Supplemental Text 1. In addition, a list of all biomarkers is depicted in Supplemental Table 2.
Statistical analysesThe associations of the CAIDE model variables with the outcomes of all-cause dementia, AD, and VD were determined by a multivariate logistic regression model adjusted for age, education, sex, systolic blood pressure, BMI, total cholesterol, physical activity, and APOE ε4 status.
The predictive accuracy of the CAIDE model, including baseline variables and the inflammatory biomarkers measured from baseline serum samples, was assessed for dementia diagnoses collected over 20 years of follow-up, using least absolute shrinkage and selection operator (LASSO) logistic regression models. LASSO is a form of linear regression that uses shrinkage to exclude variables that are not useful for the prediction [24]. This makes the final equation simpler and easier to interpret. The CAIDE model variables were defined as not being penalized by the LASSO regression and thus forced into the model. In a sensitivity analysis, all variables were penalized. The parameter λ was determined by five-fold cross-validation. The AUCs and 95% CIs were estimated using 500 bootstrap samples for the CAIDE model and CAIDE model + inflammatory biomarkers for all-cause dementia, AD, and VD as the outcome, respectively. While the CAIDE model only included the CAIDE model variables, the CAIDE model + inflammatory biomarkers additionally included those of the 69 inflammation-related biomarkers selected by the LASSO regression. Moreover, we distinguished CAIDE models 1 and 2, with only the latter including APOE ε4 carrier status among the unpenalized CAIDE model variables. To determine if the differences between the CAIDE model and the CAIDE model + inflammatory biomarkers models were statistically significant, bootstrap intervals for the differences in AUCs were computed. This involves the calculation of the AUC difference between the two models for every bootstrap sample, sorting and assessing the true AUC difference. The probability of a variable to be selected by the LASSO regression was additionally determined using bootstrap inclusion frequencies [25, 26], providing insights about the number of selections for each variable throughout the bootstrapping procedure. High inclusion frequencies indicate a continuous impact on the model’s performance by the respective variables.
Besides calculations for the total sample, the models' discrimination performance was also evaluated in subgroups for mid-life (50–64 years) and late-life (65–75 years) for all three dementia outcomes and CAIDE model 1 and CAIDE model 2.
The Statistical Analysis System (SAS, version 9.4, Cary, North Carolina, USA) was used for multivariate logistic regression. Statistical tests were two-sided, using an alpha level of 0.05. LASSO regression was performed using the R package “glmnet” (R, version 3.6.3; glmnet package version 4.1–2) [27]. For AUC computation and bootstrapping, the R package ModelGood (R, version 3.6.3; ModelGood package version 1.0.9) was used [28].
留言 (0)