
記住我


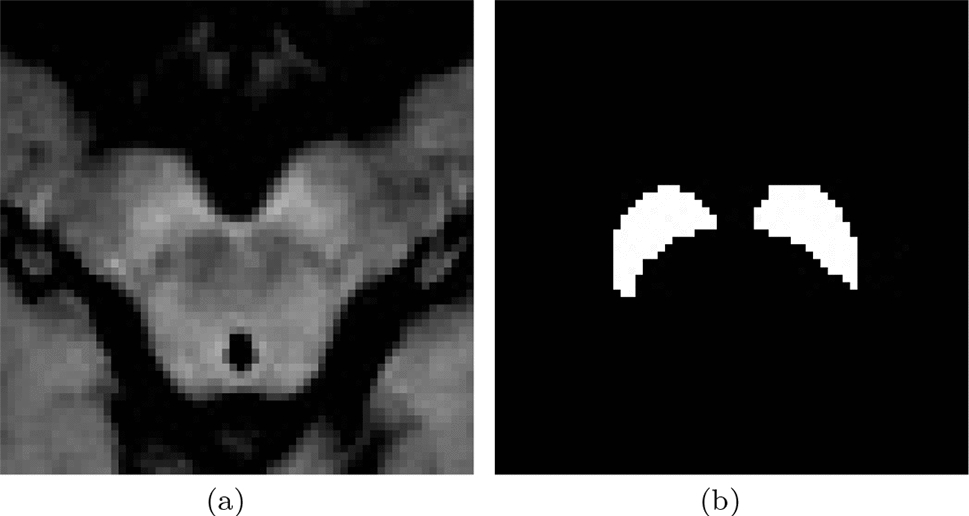



The results of the fourfold cross-validation in the intra-operative domain on dataset A.1 are presented in Table 1(a). Additionally, an evaluation of two variants of the proposed model in comparison with the baseline from our previous work [24], on the intra-operative test set A.2 is shown in Table 1(b). In the simulator domain, results of the fivefold cross-validation are presented in Table 1 (c). Samples from prediction from cross-validation in the intra-operative (A.1) and the simulator domain (B.1) are shown in Fig. 5.
Firstly, from the cross-validation in the intra-operative dataset (A.1), it can be seen that in comparison with the our previous baseline with the value of \(\sigma _1=1\) [24], the performance of the model increases with \(\sigma _1=2\). For both the values of \(\sigma _1=2, \sigma _1=3\), the model performs better than while using a Tanh distribution, with respective values of \(\alpha =7, \alpha =10.5\) (mean \(F_1\) \(+0.0082\) for \(\sigma _1=3, \alpha =10.5\) OR A.1 c.f. Table 1a). To recall, \(\sigma _1\) here denotes the spread of the Gaussian distribution used to create the masks. \(\sigma _2\) refers to the parameters of the local differentiable Gaussian layer used in the proposed model variants.
In the intra-operative dataset, the Variant 1 of the proposed model with \(\sigma _1=3\) outperforms the baseline from our previous work [24] with \(\sigma _1=1\) (mean \(F_1\) \(+0.0082\) for \(\sigma _1=3\) OR A.1 c.f. Table 1a). Variant 1 also outperforms the baseline model with the same \(\sigma _1\) value of 3 (mean \(F_1\) \(+0.0080\) for \(\sigma _1=3\) OR A.1 c.f. Table 1 (a)). In this case, the difference is the differentiable local Gaussian and SoftArgMax layers in the model architecture. A larger spread of the Gaussian distribution provides more likelihood values around every landmark and additionally reduces the imbalance of the pixels in the dataset, thereby helping the model learn better. However, a larger spread around the suture point also means that the model is prone to confounding from nearby points due to overlapping distributions. Similarly, in the Simulator domain, the proposed model Variant 1 with \(\sigma _1=2\) outperforms the baseline from our previous work [24] (mean \(F_1\) \(+0.0865\) Sim B.1 c.f. Table 1 (c)), with \(\sigma =1\), and the baseline model with the same value of \(\sigma _1=2\) (mean \(F_1\) \(+0.0354\) Sim B.1 c.f. Table 1 (c)).
Table 1 Results of baselines and model variants on (a) OR Cross-validation dataset A.1, (b) OR Test dataset A.2, (c) Sim Cross-validation dataset B.1. Best \(F_1\) scores are highlighted in boldIn the intra-operative domain, Variant 2 of the proposed model does not outperform the baseline with the corresponding \(\sigma _1\) value (mean \(F_1\) \(-0.0144\) for \(\sigma _1=3\) OR A.1 c.f. Table 1 (a)). In the simulator domain however, the Variant 2 outperforms the corresponding baseline (mean \(F_1\) \(+0.0324\) Sim B.1 c.f. Table 1 (c)). Binary masks in this case, without a likelihood distribution, constitute a highly imbalanced dataset, which hampers the learning process and affects performance. In both domains, the model Variant 1 yields the best performing model.
Furthermore, for values \(\sigma _1 = 2\), \(\sigma _1 = 3\), the values of \(\sigma _2\) are varied between 1, 2, and 3 and the results are presented in Table 2. In each domain, the best performing model is with the value \(\sigma _2 = 1\). In both the cases of intra-operative and the simulator domains, there is a best-performing value of (\(\sigma _1\), \(\sigma _2\)) after which the performance of the model drops. In the case of the intra-operative domain, this performance occurs at (\(\sigma _1=3\), \(\sigma _2=1\)) and in the case of the simulator domain, at (\(\sigma _1=2\), \(\sigma _2=1\)). This is due to the trade-off that occurs while increasing the spread of the distribution around the suture points. In order to understand this trade-off, the model performance is analysed at the level of two different subsets. Firstly, a subset of close-points are defined as the points that are within a distance of 15 pixels within each other. The rest of the points are categorised as non-close points. Then, the change in the True Positive points, as we go from \(\sigma _1=2\) to \(\sigma _1=3\) is analysed. An example illustration in the simulator domain is shown in Fig. 4. It can be seen that the drop in the percentage of True Positives is higher in the case of the close subset in comparison with the points that are not located close to each other.
Table 2 Comparison of different Gaussian values used for creating the suture masks (\(\sigma _1\)) versus the Gaussian values used in the local differentiable Gaussian layer (\(\sigma _2\)); on the OR (A.1) and simulator dataset (B.1). Highest values for each metric are highlighted in boldMoreover, we compute the root-mean-square error of the Euclidean distance as explained in Sect. 3.3, the results of which are presented in Table 3. As given in Table 3, the results are different as compared to the \(F_1\) score metric presented in Table 2. Although the RMSE distance provides an indication of the closeness of the points to the ground truth labels, it is difficult to analyse a case where the RMSE of two models are the same despite one of the models predicting more False Positives, since the metric is averaged over each predicted point. An example of this is shown in Fig. 3b. Finally, we present an evaluation with three different radii around the ground-truth point for which a match is allocated, namely six pixels, eight pixels, and ten pixels, for the best-performing model in each domain, as given in Table 4.
Table 3 Comparison of the RMSE distance with different Gaussian values used for creating the suture masks (\(\sigma _1\)) versus the Gaussian values used in the local differentiable Gaussian layer (\(\sigma _2\)); on the (a) OR cross-validation dataset (A.1) (b) additional OR test dataset (A.2), and the simulator cross-validation dataset (B.1). Lowest RMSE values are highlighted in boldTable 4 Comparison of evaluation with three different radii around the ground-truth point, for the best performing models on (a) OR cross-validation dataset A.1, (b) additional OR Test dataset A.2, (c) Simulator cross-validation dataset B.1. Highest values for each metric are highlighted in boldDiscussion Fig. 4
A comparison of the percentage of True Positives detected in each fold in the simulator domain cross-validation dataset B.1. Blue bars denote the model with \(\sigma _1=2\), \(\sigma _2=1\); Yellow bars denote the model with with \(\sigma _1=3\), \(\sigma _2=1\); a provides a comparison of the subset containing points close to each other. b Subset not close to each other
In this paper, as an extension to our previous work [24], we tackle the suture detection task by introducing a differentiable 2D Gaussian filter layer, and an additional differentiable convolutional 2D spatial convolutional Soft-Argmax layer. Unlike other works [5, 16] that use a Soft-Argmax layer to directly extract the landmarks from the heatmap from a single channel, we present its use as a form of local non-maximum suppression to filter out points with low likelihood of being a suture. Firstly, we perform experiments comparing the baseline from our previous work [24], with different values of \(\sigma _1\). Here, we also present comparison of the Gaussian distribution with a Tanh distribution with a similar spread. Then, we present two variants of our proposed model in comparison with the baseline (c.f. Table 1). Further, we present experiments by varying values of \(\sigma _1\in 1, 2, 3, 4\) and \(\sigma _2\in 1, 2, 3\) (c.f. Table 2). In addition to the evaluation with the \(F_1\) score, we compute an RMSE metric (c.f. Table 3). The RMSE metric has a limitation by comparing the models while taking into account the False Positives, as explained in Sect. 3.3. In the intra-operative domain, the Variant 1 with values (\(\sigma _1=3, \sigma _2=1\)) is the best performing model with an \(F_1\) score of \(0.4798\pm 0.04\) OR A.1, \(0.4290\pm 0.04\) OR A.2 c.f. Table 1(a) and (b), and Variant 1 with values (\(\sigma _1=2, \sigma _2=1\)) is the best performing model with an \(F_1\) score of \(0.7734\pm 0.06\) Simulator B.1, c.f. Table 1 (c). The intra-operative dataset is a highly heterogeneous dataset comprising of images from different viewing angles, scale, light sources, and white balance. Furthermore, the intra-operative datasets contain endoscopic artefacts caused due to specularities, and occlusions from tissue or surgical instruments in the scene which make it a challenging dataset to learn from. Finally, it is often the case that two sutures are stitched close to each other. This makes it further difficult for the model, and a human reader, to distinguish nearby sutures. In particular, the final 2D Gaussian filter layer and the convolutional 2D spatial Soft-Argmax layer operate locally with a window and are prone to be confounded by closely occurring suture points. This is especially true in the case of higher Gaussian \(\sigma _1\) values, as can be seen in Table 2. Varying the values \(\sigma _1\) and \(\sigma _2\) each have an effect on model performance in relation to the number of points in the dataset that are nearby or farther away from each other. In this regard, an adaptive variation in the Gaussian distribution is a potential future work, to handle these variations (Fig. 5).
Fig. 5
Samples of prediction from a Cross-validation on the OR dataset A.1 b Cross-validation on the Sim dataset B.1. Green—True Positive, Orange—False Negative, Red—False Positive
Besides providing quantitative information for analysis of endoscopic data, the learned representations from the suture detection task can also be used to support other learning objectives. In particular, this task is relevant in the context of generative models to transform data from the simulator to the intra-operative domain [7, 12]. In our recent work [22], we show that suture detection models can be used to mutually improve generative domain transformation in endoscopy.
留言 (0)