
記住我
At present, self-driving technology is one of the research hotspots in the field of artificial intelligence, and reinforcement learning (RL) has drawn significant attention in recent years. In self-driving systems, the most fundamental challenge is the control of path tracking (Yuan et al., 2021). The goal of path tracking control is to enabling vehicles to travel along a predetermined path and approach the fixed trajectory as closely as possible. SLAM is one of the rapidly developing robot perception technologies in recent years, which has been applied in fields such as autonomous navigation (Zheng et al., 2023), augmented reality (Shoukat M. U. et al., 2023), and medical equipment (Shoukat K. et al., 2023). Path tracking control methods are mainly divided into two categories: model based and non-model based. Among them, model-based path tracking control methods mainly rely on the kinematic and dynamic models of the robot, and control the robot’s motion by outputting control signals from the controller. Common model-based control methods include proportional integral differential (PID) control (Arrieta et al., 2023; Gopi Krishna Rao et al., 2014; Huba et al., 2023), fuzzy control (Benbouhenni et al., 2023; Zhang et al., 2023), model predictive control (MPC; Fiedler et al., 2023; Wei and Calautit, 2023; Bayat and Allison, 2023), etc. Non-model based path tracking control methods do not require an accurate robot model, but control is achieved through perception and decision-making modules. Common non-model based control methods include neural network control methods (Legaard et al., 2023; Sun et al., 2023).
In the past, researchers have sought solutions from model-based algorithms to address issues such as low tracking accuracy and poor robustness of AVs towards target paths during operation. Mendoza and Yu (2023) proposed a fuzzy adaptive PID control method based on vehicle kinematics and dynamics is used to plan the next driving path based on preview theory. They first used the position relationship between the vehicle center of mass and the desired path preview point to calculate the lateral deviation and heading deviation, and then used the fuzzy adaptive PID controller to adjust the front wheel angle by adjusting the error. Although this method is simple and feasible, its adaptability and control accuracy are limited in high demand control situations. Chen et al. (2023) proposed a horizontal and vertical fuzzy control method based on dynamic dual point preview strategy, which dynamically controls the dual point preview distance through fuzzy control, thereby controlling the vehicle to track the corresponding trajectory. However, the effectiveness of fuzzy control is greatly affected by changes in the preview distance. Wu et al. (2023) proposes a composite fuzzy control method based on lateral error and heading error. This method adjusts the output of two fuzzy controllers by specifying corresponding weight variables, and uses integral compensation to solve the problem of low steady-state accuracy in traditional fuzzy control. However, this method has poor path tracking accuracy in complex roads.
In order to ensure the stability and overall performance of the control-loop system, Roman et al. (2024) suggested a data-driven approach that combines an algorithm with continuous-time active disturbance rejection control. Nguyen et al. (2023) proposed a control algorithm for vehicle trajectory tracking using linear time-varying MPC. Compared to nonlinear control, this method has a global optimal solution and smaller computational complexity. Nevertheless, this method requires high modeling requirements for vehicles, linear approximation for nonlinear systems, and the construction of a quadratic cost function. At the same time, this method requires high hardware storage space and computing power, and needs to consider the limitations of computing resources appropriately. Xue et al. (2024) suggested a novel control technique, which utilizes a neural network (NN) and policy iteration (PI) algorithm to achieve H∞ control in a nonlinear system. Jing (2024) introduced a NN modelling method that utilizes evolutionary computation (EC). The method includes techniques such as NN model compression, distributed NN model, and knowledge distillation. Although the control algorithm can stably track the path, but the system is too complex and has poor stability performance. Chi et al. (2022) presented a method for improving the P-type controller using set point learning called indirect adaptive iterative learning control to improve both linear and nonlinear systems. Zhou et al. (2023) adopts a combination of neural network and fuzzy control method to control the driving direction of the vehicle by controlling the steering wheel angle. The control effect of this method is relatively stable, but there are problems such as untimely steering control and large tracking errors. Model based control algorithms in path tracking rely on robot models, and robot modeling is a complex process that not only needs to consider the influence of various factors such as mechanical structure, dynamic characteristics, control strategies, etc., but also needs to consider the influence of various uncertain factors, making modeling difficult. There are primarily three problems in raising and ensuring the proper functioning of the intelligent vehicular path optimization system.
• Model based control algorithms have a high degree of dependence on the model in the path tracking process, but robot modeling is difficult, which can lead to poor tracking accuracy.
• Non model based control algorithms require a large amount of robot and environmental data for neural network learning, and the completeness of environmental data collection is difficult to meet, which leads to poor tracking performance.
• Current technical conditions are difficult to ensure the integrity of environmental data collection. Lack of complete environmental data can lead to inaccurate information learned by neural networks, resulting in poor tracking performance.
An integrated method combining DRL’s adaptability for learning optimal pathways and SLAM’s robustness for reliable localization and mapping is necessary to address these problems. To fill in data gaps, the suggested system fuses inputs from several sensors (e.g., LiDAR, radar, and cameras) and using SLAM to produce a continuous, real-time environment map. Table 1 shows the advantages, disadvantages, and main application scenarios of several common visual sensors.
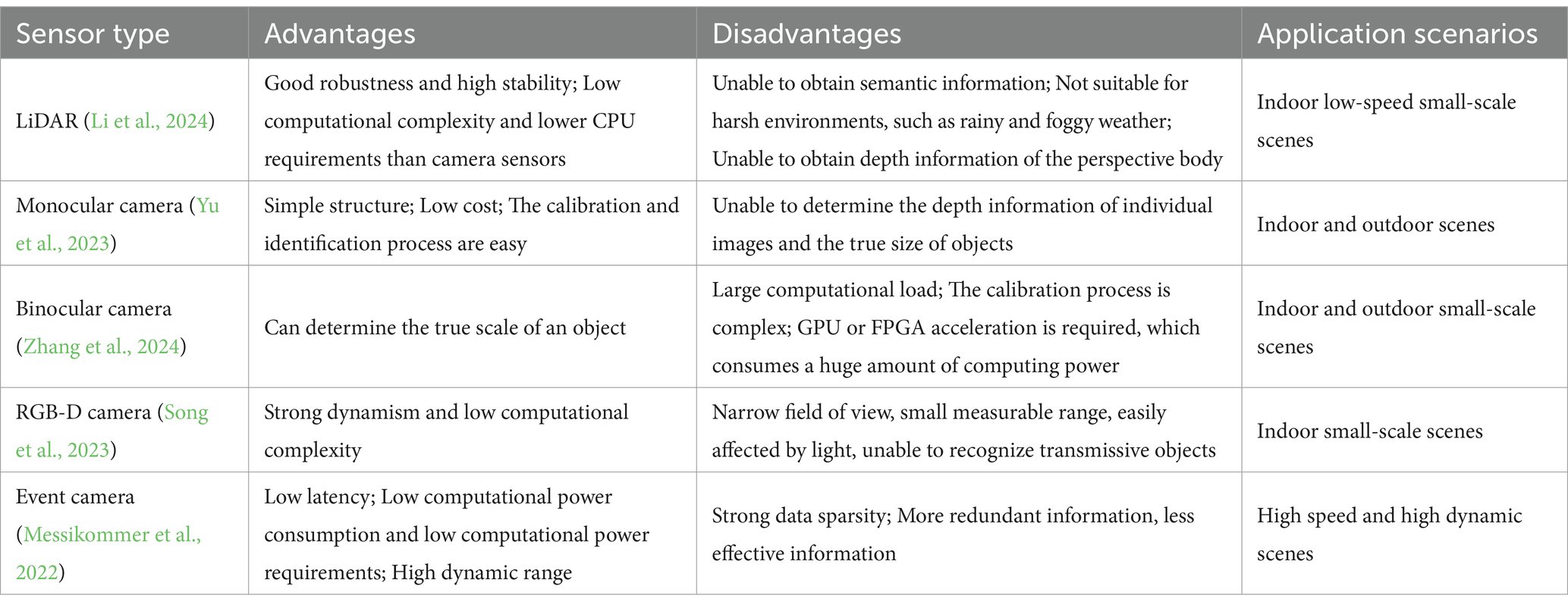
Table 1. Sensor performance.
From Table 1, it can be seen that the visual SLAM using cameras as sensors has gradually become one of the main research directions in the field of SLAM. Yuan et al. (2023) calculated the transformation matrix between two frames based on the results of feature point matching and then used this matrix to extract line features and evaluate their static weights. Finally, the remaining static features were used for camera pose estimation to complete the tracking task. Montemerlo and Thrun (2003) proposed FastSLAM by combining EKF and RBPF algorithms. This algorithm estimates the robot pose using the RBPF algorithm and then updates the map using EKF, achieving accurate localization of the robot in unknown environments. Shoukat et al. (2024) introduced a graph SLAM system that utilized YOLOv5 and Wi-Fi fingerprint sequence matching. This algorithm aims to improve the accuracy and resilience of closed-loop detection for robot navigation. Zhang et al. (2018) improved the traditional SLAM system and proposed a dynamic object detection algorithm based on geometric constraints. Dai et al. (2020) used the Delaunay triangulation method to establish a structure similar to the graph for map points, in order to determine their adjacency relationship.
This balanced strategy improves tracking precision, data integrity, and system resilience under real-world uncertainty. This system could improve self-driving technology by improving navigation accuracy, reliability, and adaptability in changing surroundings. The algorithms for RL include SARSA (state action reward state action; Naderi et al., 2023), Q-learning (Puente-Castro et al., 2024), DQN (deep Q-network; Yang and Han, 2023), DDPG (Na et al., 2023), etc. SARSA first creates a Q table and updates its status through interaction with the environment, then takes actions based on the values in the Q table. However, SARSA can only target some simple games. Q-learning is similar to SARSA. The difference in Q-learning is that different strategies are chosen when updating the Q-table, but it is essentially in the form of a table. Q-learning selects the optimal strategy through the Q-table. Moreover, Tampuu et al. (2017), utilizes DQN to train individual agents in a two-player Pong game. However, considering other agents as part of the environment causes instability because agents may adjust their strategies independently. DQN is based on Q-learning and introduces neural networks instead of Q-tables to save software space, but it is not suitable for continuous spaces.
DDPG is a strategy that facilitates depth function approximation, which can be applied in high-dimensional and continuous spaces, while the first three algorithms are only applicable to low dimensional and discrete behavioral spaces. However, in high-dimensional, continuous action autonomous driving, the reward and penalty mechanism of DDPG cannot be well set. Based on the above analysis, it can be concluded that both models based and non-model based path tracking control algorithms have some shortcomings in the path tracking process. Within this particular context, the primary contributions of this paper can be summarized as follows:
• In response to the drawbacks of the above path tracking control algorithms, we developed a reward-shaping deep deterministic policy gradient (RS-DDPG) algorithm for path tracking control maneuvers. This algorithm does not rely on precise data models of the system or requires a large amount of environmental data.
• This article proposed a visual SLAM method for dynamic scenes by combining semantic segmentation networks and multi view geometry methods.
• RS-DDPG for continuous-action tasks in DRL framework to address optimization and robustness concerns. This approach promotes agent collaboration.
• In the proposed algorithm, the robot’s path tracking control is achieved by designing reward functions and adaptive weight coefficients based on factors such as the yaw deviation between the robot and its expected trajectory, the lateral angular velocity of the robot, and other relevant parameters.
2 Preliminary 2.1 Markov decision processThe essence of DRL is the interaction process between intelligent agents and the environment, which can be regarded as a Markov decision process (MDP). MDP is a time-dependent sequential decision-making process, where the state at the next moment depends only on the current state and action. MDP defines a five tuple SARPγ , where, s=s1s2s3… represents the state of the robot; A=a1a2a3… signifies the actions output by the intelligent agent in the current state; R=r1r2r3… denotes the reward for the output action in the current state, with lag effect; P=pst+1,rt|st,at represents the probability function of st output action at at transferring to the next state st+1 and receiving reward rt in the current state; and γ is the discount factor, and γ∈01 .
This study specifies the state-action rate role for any policy π in a very large state-action space. Because getting an exact estimate of Qπsa is not practicable, function approximations such linear functions and neural networks are used (Yang et al., 2022; Yang et al., 2022). Neural networks’ strong function approximation abilities have led to their extensive practical application across many domains.
2.2 Reinforcement learning processIn the process of RL, the agent gives action A based on the current state parameter S at each time point, and then enters the next environmental state, providing feedback reward R (schematic diagram of RL process is shown in Figure 1). Then a series of data ( s1,a1,r1,s2.a2,r2,…,st,at,rt ) will be recorded in the memory pool, and the cumulative return Gt will be calculated using the following formula:
Gt=Rt+1+γRt+2+…=∑k=0+∞γkRt+k+1 (1)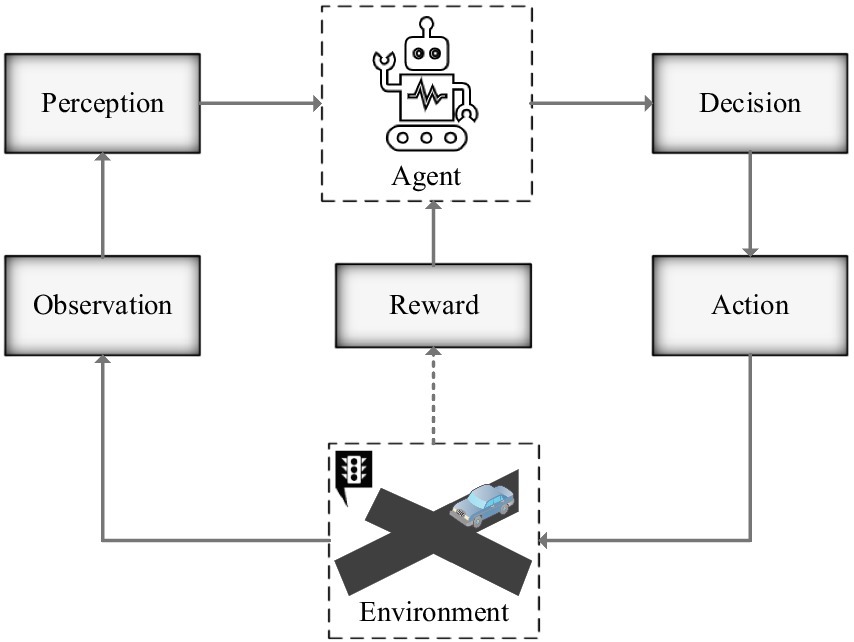
Figure 1. Schematic diagram of reinforcement learning process.
Use πto represent the policy of the intelligent agent πas=pAt=a|St=s , and select the probability of outputting action a based on the current state s . Use the value function Q to represent the value of action a taken by sin the current state as Qsa=EπGt|At=a,St=s . Where, Ex is the expected function. The value function obtained by recursion using the Bellman equation is as in Equation 2:
Qsa=EπRt+1+γQSt+1At+1|At=a,St=s (2)The core task of RL is to continuously adjust strategies to maximize the value of the reward function. In the process of reinforcement learning, the agent updates the strategy by maximizing the value of the reward function. The strategy then gives the next action and receives the reward, which loops through to ultimately achieve the system control goal.
In the camera mode of SLAM, combined with semantic segmentation, a semantic segmentation module and a thread for constructing a semantic octree map are added on top of the original front-end odometry, local mapping, and loop detection threads. The overall framework is shown in Figure 2. Firstly, the RGB image obtained by the RGB-D camera is fed into the tracking thread. In the tracking thread, the GCNv2 network is used to extract the key points and descriptors of the current frame. Afterwards, pixel level semantic segmentation is performed on the RGB image through a semantic segmentation network to segment specific objects, including dynamic and static target objects, and preliminary removal of dynamic feature points, such as walking people, is performed. And combined with multi view geometric methods for detection (Cui and Ma, 2019), further removing dynamic objects, and using the remaining static features for pose estimation. Finally, in the semantic map construction thread, the semantic information extracted through semantic segmentation is used to generate a point cloud map and convert it into an octree map.
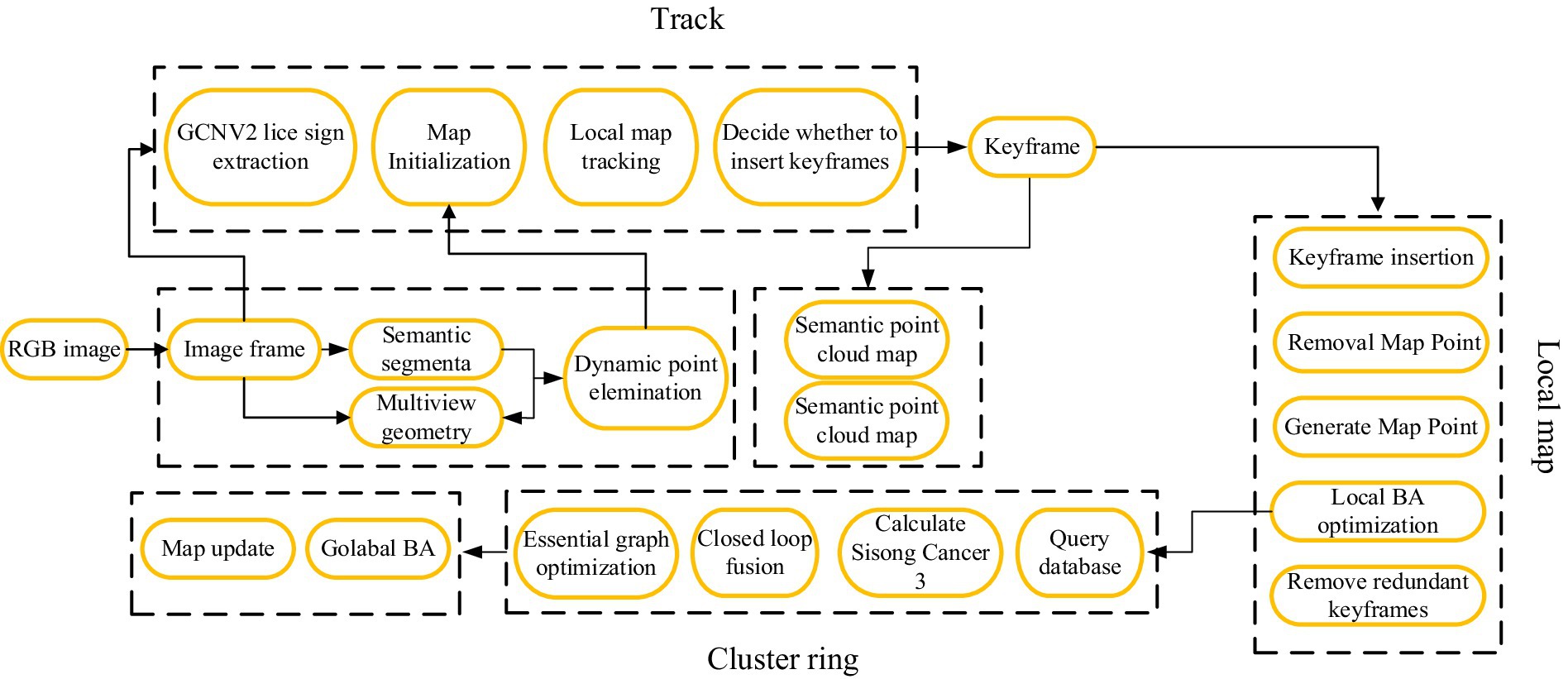
Figure 2. Overall framework of visual SLAM algorithm.
2.3 Feature extractionThe GCNV2 is a network trained for 3D projection geometry that can be used to extract feature points and descriptors. In contrast to the conventional approach of training with a single image, GCNv2 trains on the TUM and SUN-3D datasets using image pairs. In order to obtain feature points and their corresponding descriptors that are uniformly distributed, GCNv2 takes the input single-channel image and scales it to 320 × 240. The network then takes this adjusted image, extracts its features, and processes them using homogenization and non-maximum suppression. The GCNv2 method’s feature extraction procedure is shown in Figure 3 (Shao et al., 2022). It can clearly see from the graph that the extracted features are evenly distributed throughout the entire image.
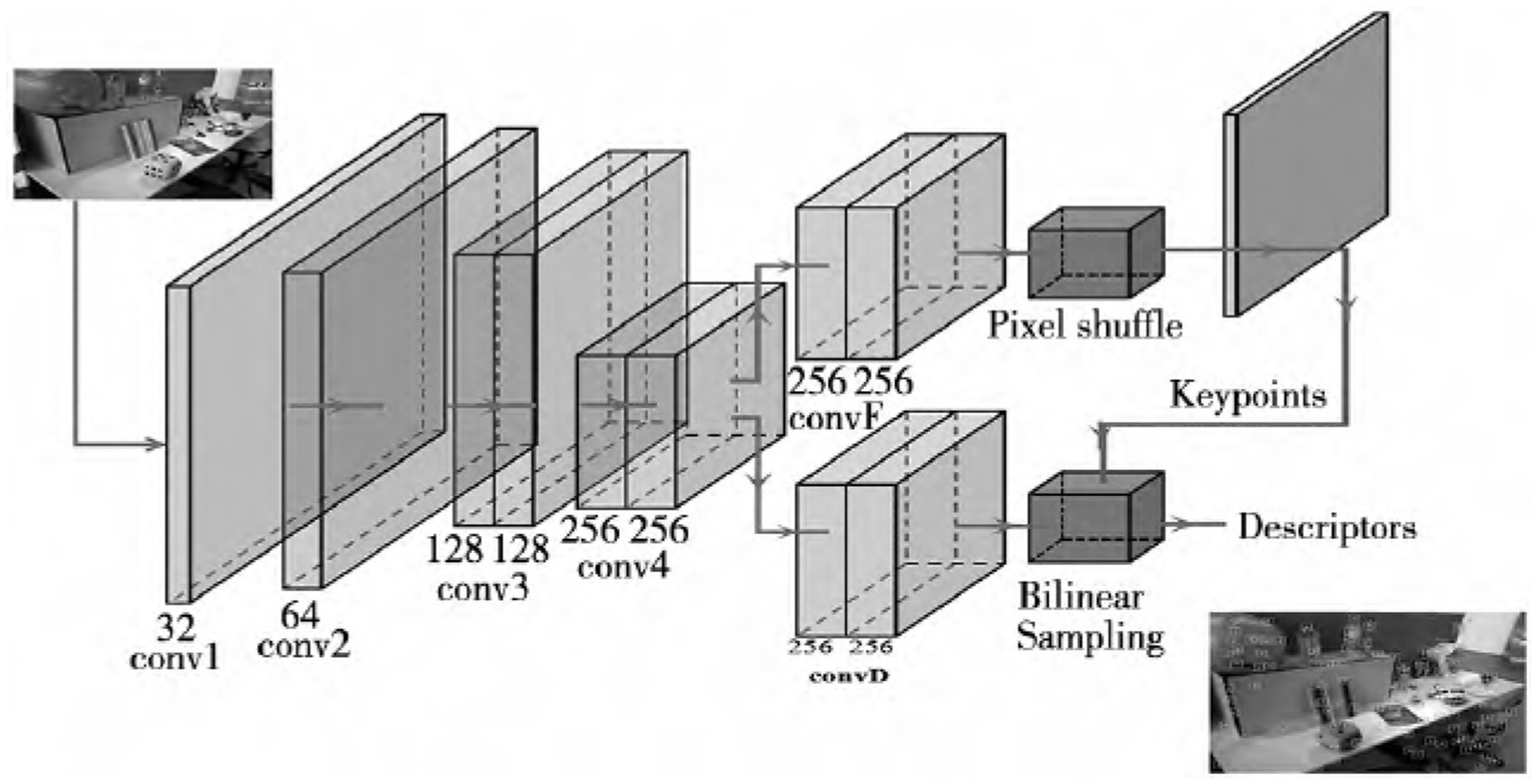
Figure 3. GCNv2 network structure.
2.4 Semantic segmentation networkThis paper uses the segmentation network DeepLabv3+ (Hu et al., 2022) to complete the semantic segmentation task of image frames. In recent years, many scholars have continuously proposed new semantic segmentation networks, such as PSPNet with a pixel accuracy of 0.9293 and BiSeNet with a pixel accuracy of 0.9337. DeepLabv3+ adds a decoder module to the framework of DeepLabv3, and integrates multi-scale information in the atrous spatial pyramid pooling layer (ASPP) module based on dilated convolution. In the decoder architecture, more accurate object boundaries are obtained through spatial information recovery, optimizing segmentation results, and achieving a pixel accuracy of 0.9431, so, this article chooses DeepLabv3+. Figure 4 shows the process of semantic segmentation algorithm, where pixels represent people and blue pixels represent display screens. After inputting the image into the network, two output values are obtained through DCNN feature extraction: feature map 1 containing high-level semantic information and feature map 2 containing low-level features. Map1 first passes through the ASPP module, and then utilizes 1 × 1 to adjusting the number of channels for convolution yields map1’. Map2 utilizes 1 × 1 to adjust the number of channels for convolution to obtain map2’. Perform 4 up-sampling operations on map1’ and concatenate it with map2’. Finally, use 3 × 3 for channel adjustment with 3 convolutions, the final segmentation result is obtained through quadruple up-sampling.
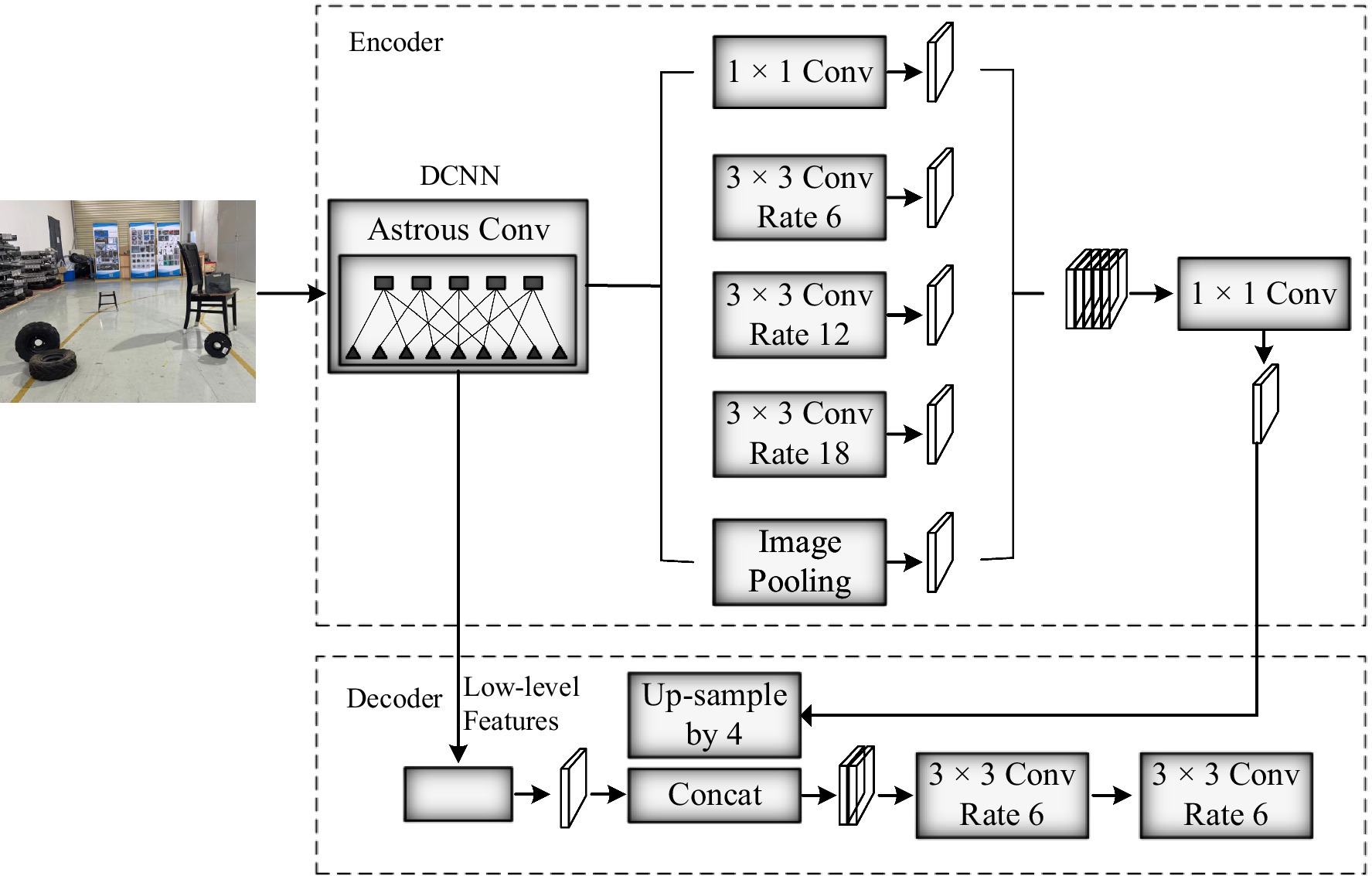
Figure 4. DeepLabv3+ semantic segmentation.
2.5 Semantic map constructionIn the semantic map construction thread, PCL library is used to generate point clouds by combining keyframes and depth maps. Then, the pose of the current frame and its point cloud are used for point cloud stitching and filtering processing to generate a point cloud map, and semantic information is annotated in the point cloud map. However, although point cloud maps give people a very intuitive feeling, they have disadvantages such as occupying a large amount of storage space, redundant location information, and cannot be directly used for navigation. Compared to this, octree maps (Ju et al., 2020) also have the intuitiveness of point cloud maps, but their storage space is much smaller, making them suitable for various navigation purposes. Therefore, this article further processes point cloud maps by converting them into octree maps and constructing semantic octree maps based on semantic information. However, during the mapping process, due to camera noise and errors caused by dynamic objects, the same node may have different states at different time points. So, we use probability to explain whether a node is occupied or not. However, this method may result in a probability greater than 1, which can interfere with data processing. Therefore, the probability logarithm is used to describe whether a node is occupied. Let y∈R (real number set) represent the probability logarithm, and the range of occupied probability p is [0,1]. The logit transformation formula is y=logp=logp1−p . The reversible transformation for logit transformation is as in Equation 3:
p=logit−1y=11+exp−y (3)Assuming that the observation probability of a node n at time T is Pn|Zt , where Z represents the observation data. The probability of its occupation Pn|Z1:T is represented as in Equation 4:
Pn|Z1:T=1+1−Pn|ZTPn|ZT1−Pn|Z1:T−1Pn|Z1:T−1−Pn1−Pn (4)where, Pn represents the prior probability of node n being occupied, and Pn|Z1:T−1 represents the estimated probability of node n from the beginning to the T−1 moment. In this article, we set the prior probability Pn to 0.5, and the above equation is transformed into a probability pair in the form of Ln|Z1:T , which represents the logarithmic value of the probability of node n from the beginning to time T . Therefore, at time T+1 , it is as in Equation 5:
Ln|Z1:T+1=Ln|Z1:T−1+Ln|ZT (5)here, Ln|Z1:T+1 and Ln|ZT represent the logarithmic values of the probability of node n being occupied before and at time T . According to Equation 3, when a node is repeatedly observed and occupied, its probability logarithm increases, otherwise it decreases. Based on the obtained information, the occupancy probability of this node can be dynamically adjusted to continuously update the octree map.
This article treats a moving person as a dynamic object, and uses a KinectV2 camera mounted on a mobile robot to move uniformly in a dynamic environment according to a previously designed rectangular path, perceive the surrounding environment, and collect information in the scene. Subsequently, using ROS tools, the obtained real scene data was split into frame images, and the TUM dataset was used as the standard to produce the obtained real scene data in the format of the TUM dataset. The algorithm proposed in this paper and the ORB - SLAM2 algorithm were tested to verify their effectiveness and feasibility. Figures 5A,B respectively represent the three-dimensional motion trajectories generated by our algorithm and ORB - SLAM2 algorithm. From Figure 5, it can be clearly seen that due to the presence of moving objects in the experimental scene, the trajectories generated by ORB - SLAM2 algorithm show significant fluctuations compared to the actual motion trajectories. However, the trajectories generated by our algorithm are basically consistent with the actual motion trajectories, and the fluctuation amplitude is relatively small.
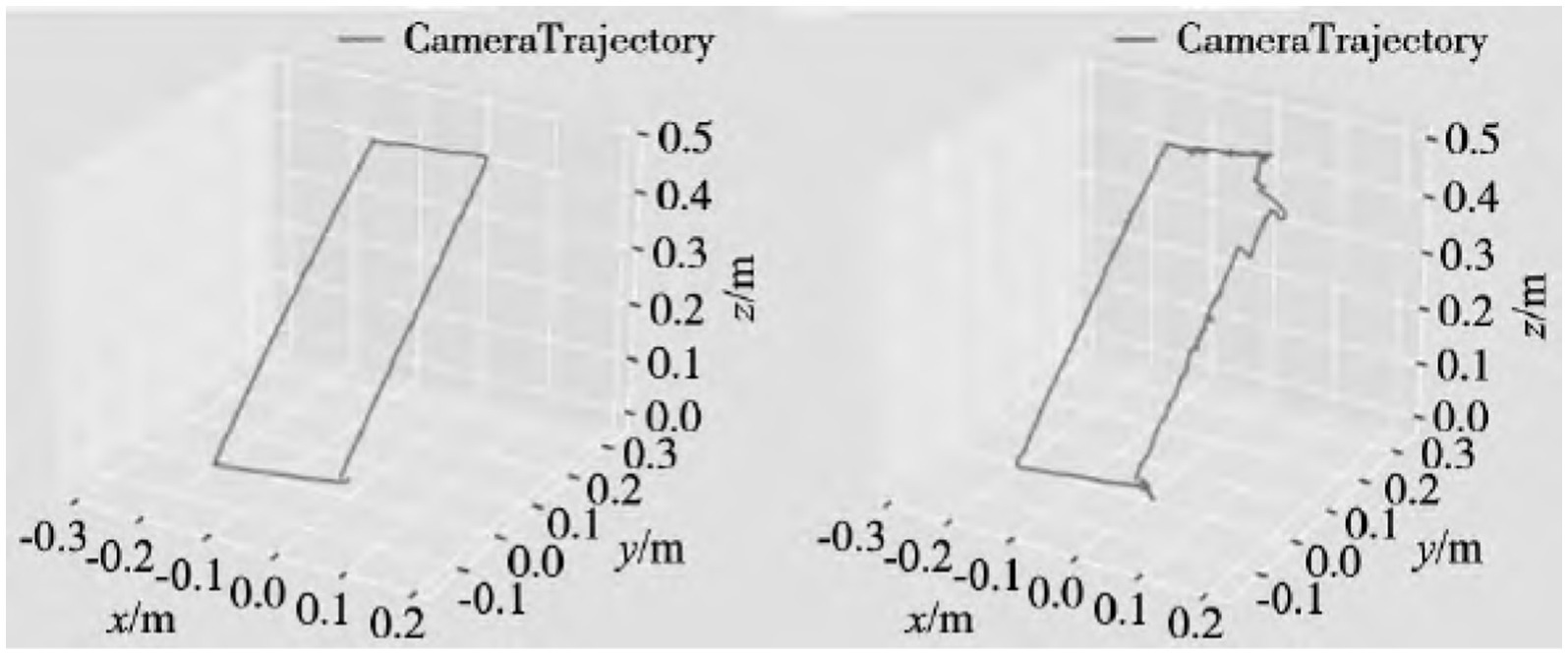
Figure 5. Comparison of motion trajectories: (A) Algorithm (B) ORB-SLAM2 algorithm in this article.
This study uses GCNv2 for feature extraction, compared with traditional SLAM system feature extraction methods, the extracted feature points are more evenly distributed. The semantic segmentation network DeepLabv3+ is used to assign semantic information to the image frames in the visual SLAM system, detect moving targets in the objects, and then combine geometric information to detect dynamic feature points.
3 Reward shaping DDPG algorithm 3.1 DDPG algorithmAmong the many actor-critic algorithms that use neural network approximations, DDPG is among the most well-known. DDPG is a model shaping algorithm based on deterministic policy gradients, which is based on the actor-critic framework and can be applied to continuous behavior spaces. The actor network denoted as μs|θμ , maps a state s to an action a using parameters θμ . The critic network Qs,|a,|θQ , evaluating actions with a learning rate αQ with parameters θQ . Training parameters like the total number of episodes and steps per episode establish the overall training duration. The function of the actor network is to output action A based on the state S feedback from the environment; The function of the critic network is to output the Q value based on the state S feedback from the environment and the corresponding action A of the actor. The function of actor target network and critic target network is to improve the stability of the network. The network first fixes its own parameters for a period of time, and then updates its own parameters by copying the parameters of the actor network and the critic network, as shown in Figure 6.
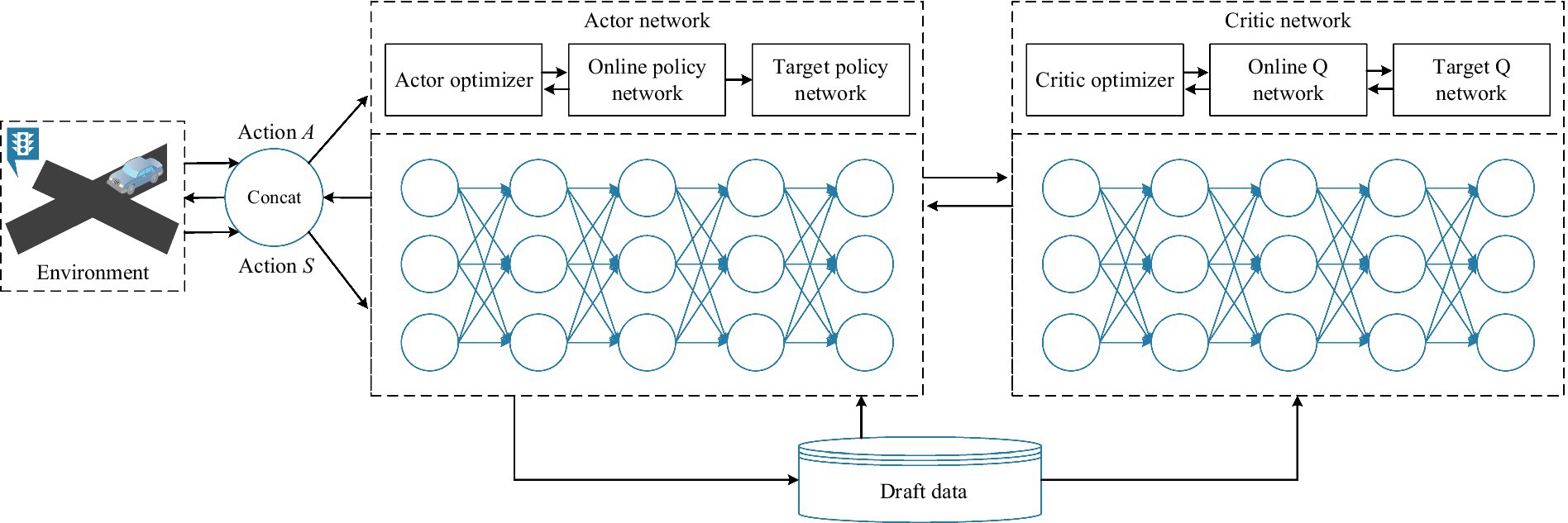
Figure 6. DDPG algorithm with actor and critic networks.
On the basis of state observation, the actor network outputs corresponding decision behaviors and parameterizes these behaviors into an n-dimensional vector θ with policy π is πa|s,θ=pAt=a|St=s . The projected long-term return is estimated by a critic parameterized by ω in DDPG, while an actor parameterized by θ generates a deterministic policy πθ .
The actor network is updated based on the policy gradient method, and the policy is improved through the policy gradient. The policy gradient ∇θJθ expression is represented in Equation 6:
∇θJθ=∂Jθ∂θ1∂Jθ∂θ2…∂Jθ∂θnT (6)where, Jπθ is the policy objective function. The policy gradient ∇θJθ expression for stochastic policies is ∇θJπθ=Eπθ∇θlogπθsaQπsa . ∇θlogπθsa is a fractional function, which can be expressed in Equation 7:
∇θlogπθsa=∇θπθsa/πθsa (7)In deterministic strategy, a=μθs , the gradient of deterministic strategy is a special form of stochastic policy where the gradient variance approaching 0 , and its gradient expression is as in Equation 8:
∇θJμθ=Eμθ∇θμθsQμsa|μθS (8)In the learning process of intelligent robot trajectory tracking control, the input of the actor neural network is the observed environmental state variables, such as position, angle, speed, etc. Its output is decisions made based on strategies, such as steering wheel angle and throttle braking. At the same time, critic’s approach is based on the behavioral value function, where the input variables are state and behavior, and the output variables are return values. During the learning process, critic uses the estimated value function as the benchmark for updating the actor function, while evaluating the actor’s strategy. The advantage of the actor-critic method is that critic provides a more accurate evaluation through the value function, thereby improving the actor strategy and making it more optimized. In addition, the actor-critic method can not only use critic to update actor policies, but also update the value function of critic, which can better evaluate behavioral value.
In practice, the value function of critic is updated using the Bellman equation Q′sa=Qsa+αRsa+γmaxQsa−Qsa , where, α is for learning rate and Q′ is a new value function. The actor network updates the parameter θ using chain differentiation (Equation 9).
∇θJθ=1n∑i=1n∇Qsiai∇πθai|si (9)The critical network updates the parameter w, by taking the mean square error (MSE) between the expected and actual values, i.e, as represented in Equation 10.
Jw=1n∑t=1nQs′a′w′−Qsiaiw2 (10)here, Qs′a′w′ is the target value calculated by the critic target network.
3.2 Reward function designThe quality of the reward function is a key factor affecting the results of the model. Intelligent agents for a single task have clear reward goals, so it is necessary to maximize the reward value. However, in dealing with complex autonomous driving tasks, it is difficult to have a single clear reward objective. Therefore, this paper intends to design a reward function through a combination approach, known as:
1) Path tracking capability. The lateral distance between the robot’s center of mass position yi and the expected trajectory yj was designed to describe the tracking accuracy of the robot as in Equation 11:
R1=Δy=yi−yj (11)The ratio of tracking accuracy error to allowable error is ∆1, and its mentioned in Equation 12.
2) Speed. R2=Vxcosθ , where, Vxcosθ is the speed of the vehicle along the expected path direction, and it is expected to complete the driving task quickly in limited time and safety.
3) Robot stability. The stability of a robot is mainly reflected by its yaw rate and center of mass lateral deviation angle. The yaw rate is R3=Δω=ωp−ωt and described as the difference between the actual yaw rate ωp and the expected yaw rate ωt , where, ωt=mimωdesωdsgnδ and ωd is the upper limit of lateral angular velocity. ωdes is the yaw rate under steady-state steering, and ωdes=Gωzss×δ . Here, Gωzss is known as steady-state gain of the yaw rate and δ is the angle of the steering wheel.
The ratio of lateral angular velocity error to expected angular velocity is Δ2=Δω/ωt . Similarly, the center of mass deviation angle is described by the difference between the actual center of mass deviation angle βp and the expected center of mass deviation angle βt as represented in Equations 13, 14.
R4=Δβ−βp−βt (13) βt=minβdesβdsgnδ (14)where, βd is the upper limit of the lateral deviation angle of the center of mass. βdes is the lateral deviation angle of the center of mass under steady-state turning, and βdes=Gβzss×δ . Gβzss is the steady-state gain of the center of mass sideslip angle.
The ratio of the deviation angle of the center of mass to the expected deviation angle of the center of mass is Δ3=Δβ/βt .
4) Steering stability. The smoothness of steering represents the degree of steering wheel oscillation, and a coefficient of variation R5 is R5=Cv=σ/θ˜ . Where, σ is the standard deviation of the steering wheel angle and θ˜ is the average value of the steering wheel angle. The aforementioned RS-DDPG approach involves a collective reward shaping that is distributed across all agents in collaborative circumstances. Nevertheless, this factor is frequently ignored in several real-world scenarios.
3.3 Adaptive weight designThe accuracy of path tracking and the stability performance of robots have a significant impact on the control of autonomous driving path tracking. When both cannot be met simultaneously, it is necessary to determine which indicator with a large gap should be dealt with first. This study designed adaptive weight coefficients. When the percentage of tracking accuracy error is greater than the percentage of stability error, the weight of the reward function for tracking accuracy will increase, and vice versa. The weight and stability weight coefficients for tracking accuracy are in Equations 15, 16
C1=0.5+eΔ1/eΔ1+eΔ2+Δ3 (15) C2=0.5+eeΔ2+Δ3/eΔ1+eΔ2+Δ3 (16)The tracking accuracy weight coefficient and stability weight coefficient satisfy C1=C2=2 expressions. During the training process, AVs may encounter two situations: normal driving and exceeding the lane. The reward function for normal driving has been designed, and the situation of exceeding the lane is uniformly set to 0 here. The expression for the reward function is represented in Equation 17:
R={R2−C1R1−C2R3+R4
留言 (0)