
記住我


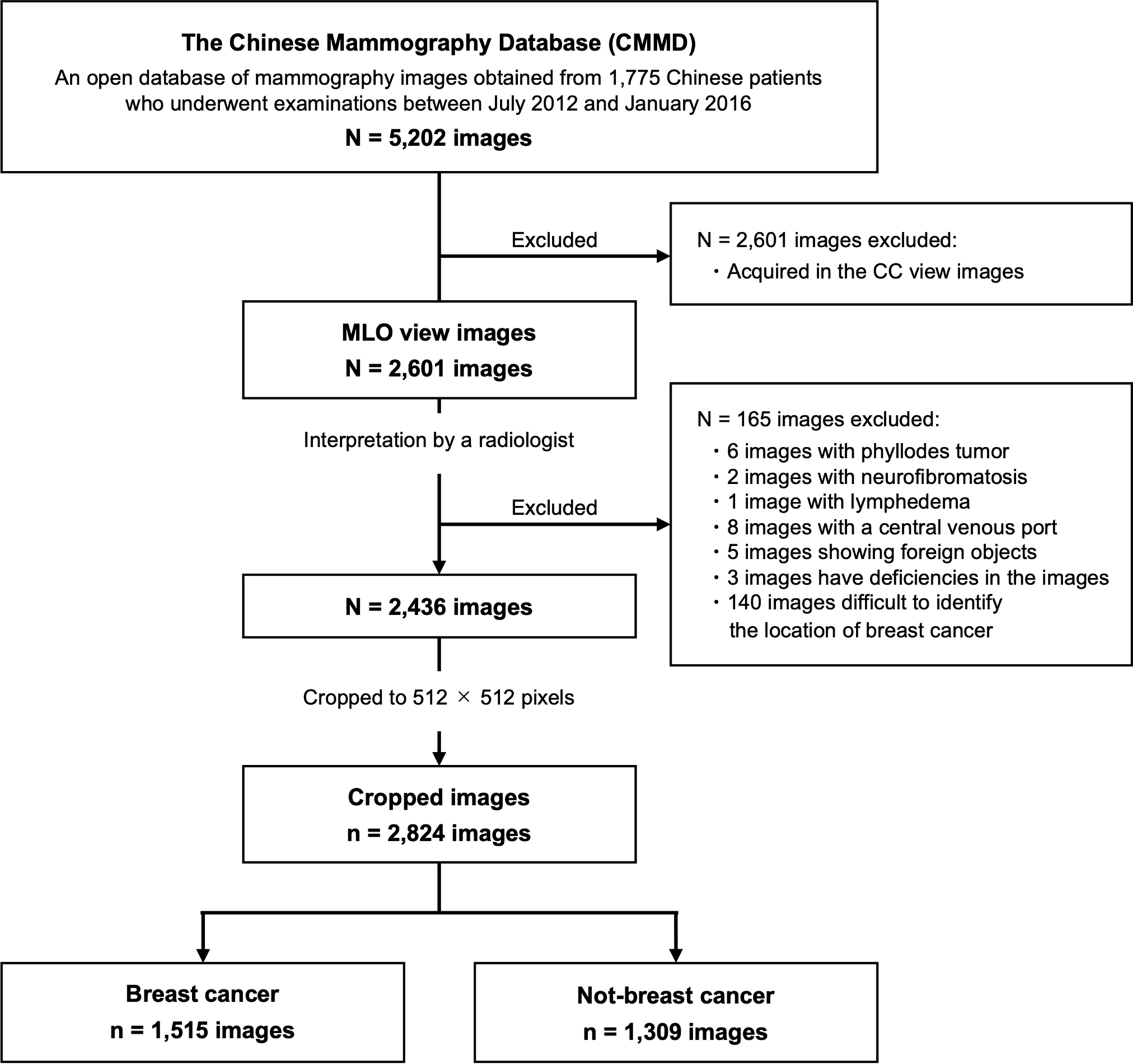

This study utilized the Chinese Mammography Database (CMMD) [23], which includes data from 1775 Chinese patients who underwent mammography examinations between July 2012 and January 2016, with biopsy-confirmed benign or malignant tumors. Of these patients, 826 had bilateral breast images and 949 had images of only one breast. The CMMD dataset contained both medial lateral oblique (MLO) and cranial caudal (CC) views of mammographic images, resulting in a total of 5202 mammographic images. In this study, only 2601 MLO view images, which have fewer blind areas on mammograms compared to CC view images, were analyzed. All images were acquired with digital mammography at a resolution of 2294 × 1914 pixels.
Based on image interpretation by a radiologist with over 20 years of experience in breast cancer imaging, the following cases were excluded from the 2601 images analyzed: those with phyllodes tumors (N = 6), neurofibromatosis (N = 2), lymphedema (N = 1), central venous ports inserted (N = 8), visible foreign bodies (N = 5), image artifacts that hindered diagnosis (N = 3), and those from breast cancer patients where lesions were unidentifiable (N = 140).
Ultimately, a total of 2436 images were included in our analysis, which were categorized as follows: 1167 images with breast cancer, 215 images with benign lesions, and 1054 breasts with normal breast tissue.
2.2 Clinical interpretation of mammographic imagesThe CMMD dataset provides diagnostic labels indicating whether an image contains a benign or malignant lesion; however, it lacks detailed medical information within the images. To enhance the analysis from a medical perspective, all breasts were labeled with radiological findings (mass, calcification, distortion, normal), breast density (dense breast [DB], not dense breast [Not-DB]) and lesion masks based on the image interpretation of a radiologist with over 20 years of experience. For mass and calcification, the lesion mask that accurately captured the boundaries of the lesion were depicted. In contrast, for distortion, bounding boxes were employed to define the lesion mask, as these findings exhibit ambiguous boundaries with the surrounding normal breast tissue. When multiple findings were observed in a patient, images with each finding were counted independently.
Using the lesion masks, original images were cropped to 512 × 512 pixels, centered on the lesion area. For breasts with normal breast tissue, the mammogram was binarized into breast area and background, and the outline of the breast area was extracted. Subsequently, to exclude the pectoral muscle, a 512 × 512 pixels image was randomly cropped from the bottom 80% of the breast area. Consequently, a total of 2824 images were used for our investigation, comprising 1515 images with breast cancer and 1309 images without breast cancer. Figure 1 illustrates the selection process, and Table 1 shows a breakdown of the datasets used in this investigation. Figure 2 shows examples of cropped images, where Fig. 2a–c represents mass, calcification, and distortion, respectively. The mean percentage of the area occupied by the lesion masks in the 512 × 512 cropped images were as follows: mass; 20.7%, calcification; 25.2%, and distortion; 57.5%.
Fig. 1
Flow chart of inclusion and exclusion process of mammographic database. Total 2824 mammographic images were analyzed in the present study
Table 1 Breakdown of radiological findings and breast density informationFig. 2
Examples of cropped images. The upper row and the lower row represents full-field images and cropped images, respectively. The radiological findings, breast density, and the percentage of the area occupied by the lesion masks in the 512 × 512 cropped images for each image are as follows: a (mass, DB, 20.4%), b (calcification, DB, 24.6%), and c (distortion, DB, 56.9%)
2.3 The Jigsaw puzzle task in SSLThe lower part of Fig. 3 shows the overall framework of the Jigsaw puzzle task in SSL used in this study. The input data for the Jigsaw puzzle task consisted of a set of patches cut from a mammographic image. Following the method described by Noroozi et al. [18], we left random gaps between the patches to prevent the model from solving the puzzle by simply matching low-level statistics (such as structural patterns and textures) at the edges of adjacent patches, ignoring the content within the patches themselves.
The set of patches was then reordered via a randomly chosen permutation from a predefined permutation set, and fed into the neural network. The neural network was trained to predict the specific permutation performed on the set of patch images. Although there are 9! (362,880) possible permutations with 9 patches for the 3 × 3 Jigsaw puzzle, a previous study has shown that it is not necessary to consider all 9! [18]. In the study of Vu YNT et al. [19], 31 different segment placement patterns were predefined, including the correct identity permutation and the top 30 permutations with the greatest Hamming distance from the identity.
The architecture used for the Jigsaw puzzle task was the context-free network (CFN) [18], which shares the same weights across all input patches. The features of each patch are extracted independently in each neural network and finally concatenated in a final fully connected layer.
2.4 Comparison of pre-training pipelinesFigure 3 illustrates the pre-training pipelines compared in this study. To assess the effectiveness of the Jigsaw puzzle task and the effect of using the ImageNet pre-trained model, we compared the following four pipelines:
IN-Jig is the model pre-trained with both the ImageNet classification task and the Jigsaw puzzle task. The Jigsaw puzzle task was performed using the ImageNet pre-trained model. The neural network was then fine-tuned for binary classification to distinguish between the presence and absence of breast cancer.
Scratch-Jig is the model pre-trained only with the Jigsaw puzzle task, without utilizing an ImageNet pre-trained model.
IN is the baseline model pre-trained solely with the ImageNet classification task using random initial weights.
Scratch is the model that was trained for binary classification to distinguish between the presence and absence of breast cancer without any pre-training tasks.
2.5 Implementation of the Jigsaw puzzle taskWe adopted ResNet50 [24] as the architecture constituting the CFN. Each 512 × 512 pixels image was divided into a 3 × 3 grid consisting of patches of approximately 170 × 170 pixels. A 150 × 150 pixels-area was then randomly extracted from each patch and input into the CFN. We used the identical permutation and the top 30 permutations having the greatest Hamming distance from the correct permutation, following the reported method of Vu YNT et al. [19]. The mean Hamming distance of the total 31 permutations used in this study was 8.086. Adaptive moment estimation (Adam) was used for the optimizer and cross entropy was used as the loss function (learning rate = 0.001, weight decay = 0). The batch size was set to 128, and the model was trained over 100 epochs.
2.6 Implementation of fine-tuning for breast cancer classificationFor fine-tuning, binary classification was performed to distinguish between the presence and absence of breast cancer, using the same 512 × 512 pixels images as in the Jigsaw puzzle task. Adam was used for the optimizer and cross entropy was used as the loss function (learning rate = 0.001, weight decay = 0). The model was trained with a batch size of 64 over the course of 100 epochs.
2.7 EvaluationsThe overall performance of four models was assessed using receiver operating characteristic (ROC) curves, area under the ROC curve (AUC), sensitivity (true positive rate [TPR]), and specificity (true negative rate [TNR]). Furthermore, to elucidate the characteristics and trends of the model from a medical perspective, the models’ performance was also assessed for each group of radiological finding (mass, calcification, distortion, normal) and breast density (DB, Not-DB). Since AUC cannot be calculated for normal findings, the normal-true negative rate (normal-TNR) was used instead. Cutoff values for sensitivity, specificity, and normal-TNR were calculated using the Youden index (J), defined as J = maximum , which is considered to provide the best balance of sensitivity and specificity [25].
The accuracy of the Jigsaw puzzle task was assessed to compare the performance between the pretext and the downstream task. Gradient-weighted class activation mapping (Grad-CAM) [26] was implemented to visualize regions of mammographic images that were the most relevant for the network’s final classification. The Grad-CAM outputs were analyzed to assess how the regions of interest changed with use of the Jigsaw puzzle task.
To reduce bias due to a lack of data, fivefold cross-validation was employed. The dataset was divided into five equal parts, with four segments used for training and one for validation. This cross-validation process was repeated five times to calculate the mean validation accuracy. All data were separated by patient, ensuring a consistent process from pre-training to the downstream task. To mitigate the effect of randomness in fine-tuning, the fivefold cross-validation for the downstream task, breast cancer classification, was performed ten times. The mean performance scores and the mean ROC curves of ten trials were calculated. The statistical significance of the overall performance of AUC was assessed using a t test, with IN serving as the reference; a p value of less than 0.05 was considered statistically significant.
留言 (0)