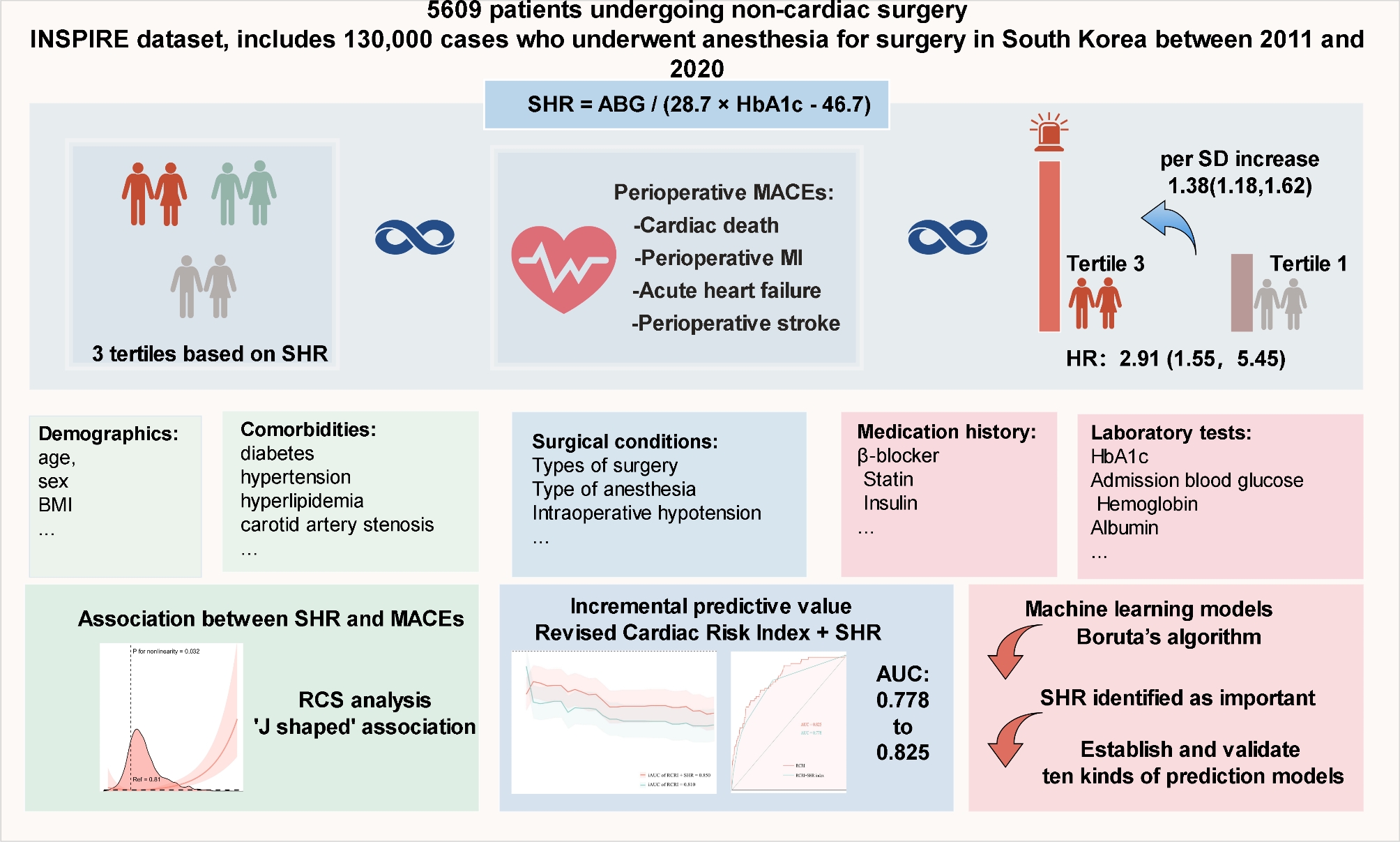
Study population
This retrospective analysis utilized perioperative data from the INSPIRE database (version 1.1), a comprehensive perioperative medical database maintained by a South Korean academic institution. The INSPIRE database, spanning from 2011 to 2020, includes detailed medical records of approximately 130,000 patients who underwent surgery under anesthesia, providing an extensive source of high-quality perioperative information. The study adhered strictly to the STROBE guidelines for reporting observational studies.
The study population comprised individuals aged 18 years and above who underwent noncardiac surgery (including gastrointestinal, orthopaedic, neurosurgery, obstetric, gynaecological, otolaryngology, thoracic and urology procedures) between 2011 and 2020, identified using the International Classification of Diseases, 10th Revision, Procedure Coding System (ICD-10-PCS). Patients were excluded if they lacked preoperative results for ABG or HbA1c; presented with acute myocardial infarction, acute stroke, or acute heart failure during hospitalization prior to surgery; or had more than 20% of missing data.
Clinical outcomes
The primary endpoint of this study was the incidence of MACE within 30 days after surgery, which included cardiac death, perioperative myocardial infarction, acute heart failure, and perioperative stroke. Each component of MACE was also evaluated individually as secondary endpoints.
Cardiac death was defined as any instance of cardiac-related mortality occurring from the intraoperative period through the postoperative phase. Perioperative myocardial infarction and perioperative stroke were identified using ICD-10 codes I21 and I64, respectively. Acute heart failure was defined as the new onset of heart failure following surgery, identified by ICD-10 code I50. Diagnostic information for these events was obtained from the diagnosis table of the INSPIRE database.
Study variables
Data extraction was performed using PostgresSQL (version 13.8), utilizing Structured Query Language (SQL) for precise information retrieval. The extracted latent variables were classified into five categories: (1) Demographics: including age, sex, and body mass index (BMI); (2) Comorbidities: including diabetes, hypertension, hyperlipidemia, carotid artery stenosis, valvular heart disease, atrial fibrillation, chronic obstructive pulmonary disease (COPD), renal insufficiency, hepatic insufficiency, prior stroke, prior myocardial infarction, and cancer; (3) Medications: including β-blockers, statins, calcium channel blockers (CCB), anticoagulants, antiplatelet drugs, and antidiabetic drugs (insulin, sulfonylureas, biguanides, thiazolidinediones, and DPP-4 inhibitors); (4) Surgery details: surgical status (emergency or elective surgery), type of surgery (including gastrointestinal, orthopedic, neurosurgery, obstetric, gynecological, otolaryngology, thoracic and urology procedures), high-risk surgery, as defined by the Revised Cardiac Risk Index (RCRI), includes intraperitoneal, intrathoracic, and suprainguinal vascular surgeries, anesthesia type, and American Society of Anesthesiologists (ASA) classification; (5) Laboratory tests: collected during the first examination upon admission, including HbA1c, ABG, hemoglobin, albumin, white blood cells, platelets, and creatinine. SHR was calculated using the formula: SHR = ABG / (28.7 × HbA1c − 46.7), where ABG is expressed in mg/dL and HbA1c in percentage [18].
Statistical analysis
Variables with more than 20% missing data were excluded from the analysis, while those with fewer than 20% missing data were imputed using multiple imputation by chained equations (MICE) to ensure unbiased estimates. The variance inflation factor (VIF) was calculated to assess multicollinearity among variables, with a threshold of 5 used to exclude variables to mitigate collinearity issues. VIF measures the extent to which the variance of a regression coefficient is inflated by the presence of multicollinearity in the model. Continuous variables with a normal distribution were reported as means ± standard deviations (SDs) and analyzed using analysis of variance (ANOVA). For variables not following a normal distribution, the Mann–Whitney U test or the Kruskal–Wallis test was used.
Univariate (Model 1) and multivariate Cox proportional hazard models were constructed to evaluate SHR’s association with clinical outcomes, considering SHR as both a continuous and categorical variable. Models were partly (models 2) or fully (model 3) adjusted for age, sex, BMI, ASA classification, emergency status, type of surgery, type of anesthesia, diabetes status, hypertension status, hyperlipidaemia status, carotid artery stenosis status, valvular heart disease status, atrial fibrillation status, COPD, renal insufficiency status, hepatic insufficiency status, prior myocardial infarction, IOH status, β-blocker status, insulin status and antidiabetic drug status. The median value of the tertiles was employed as a quasi-continuous variable in the models to determine trends’ p-values.
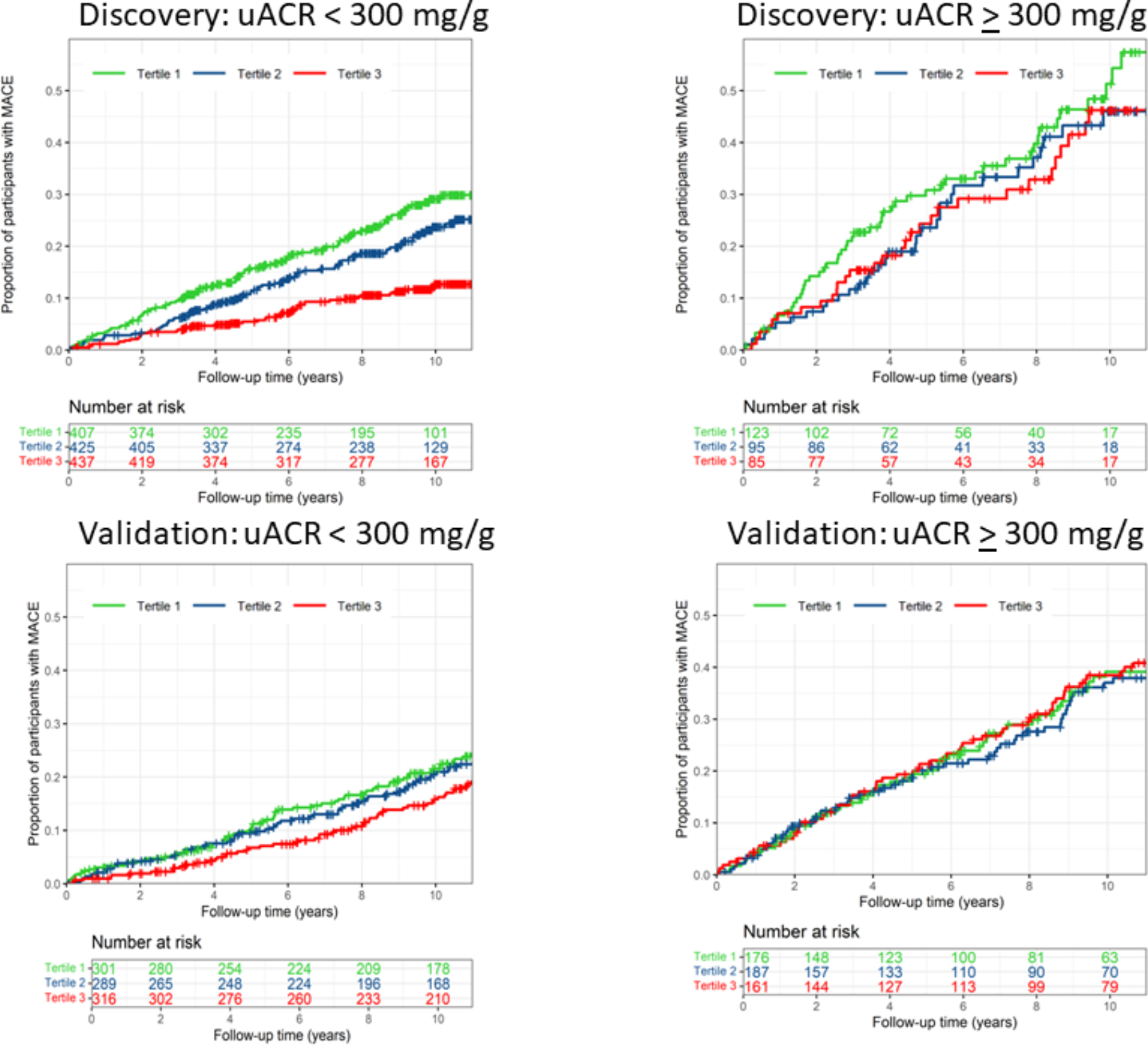
The occurrence rates of MACEs across different SHR tertiles were assessed using Kaplan–Meier survival analysis, and group differences were assessed with log-rank tests. To explore potential nonlinear associations between SHR and patient outcomes, restricted cubic spline (RCS) analyses were performed, using four knots (at the 5th, 35th, 65th, and 95th percentiles). If a nonlinear relationship between the SHR and perioperative MACE risk was revealed by the RCS, we further calculated the inflection point and analyzed the relationship on either side of this point using a two-segment Cox proportional hazards model. The determination of the inflection points was conducted using the “segmented” package in R based on a likelihood ratio test and bootstrap resampling. RCRI is frequently applied clinically to assess cardiac complication risk in noncardiac surgical patients. The predictive performance enhancement of the RCRI by the SHR was evaluated using the receiver operating characteristic (ROC) curve, the area under the ROC curve (AUC), C-statistic, continuous net reclassification improvement (NRI), and integrated discrimination improvement (IDI), alongside likelihood ratio tests to compare model fit improvements with the inclusion of the SHR, which was treated either as a continuous variable or as a categorical variable determined by inflection points identified using RCS. SHR was analyzed both as a categorical and continuous variable. C-statistics, continuous NRIs, and IDIs calculations utilized the “survIDINRI” package in R. The “survival ROC” package was employed for a time-dependent ROC curve analysis.
Feature selection was conducted using Boruta’s algorithm, which identifies key variables by comparing the Z value of each true feature with that of corresponding “shadow features.” Features with significantly higher Z values than shadow features were deemed “important” (green area), while those without significant differences were marked as “unimportant” (red area) [14]. SHR was also analyzed as a predictor variable within this framework. Selected variables were used to develop predictive models for perioperative MACE risk. The dataset was divided into training and validation sets in a 7:3 ratio. Various machine learning algorithms were applied, including Categorical Boosting (CatBoost), Decision Tree, Gradient Boosting Machine (GBM), k-Nearest Neighbors (KNN), Light Gradient Boosting Machine (LightGBM), Neural Network (NN), Random Forest (RF), Support Vector Machine (SVM), and Extreme Gradient Boosting (XGBoost), selected based on their performance in similar prediction tasks. Hyperparameter tuning was conducted using grid search and random search methods to optimize model performance. The performance of each model was evaluated using ROC curves and corresponding AUC values. Clinical usefulness was assessed using decision curve analysis (DCA), and calibration curves were generated to evaluate the accuracy of risk predictions.
Sensitivity analyses were also performed: First, patients with missing data were excluded to verify the robustness of the primary outcomes. Second, we performed propensity score matching for patients across different tertiles to conduct the primary analysis. All statistical tests were two-sided, with significance set at p < 0.05. Data analyses were conducted using SPSS (version 24.0) and R (version 4.3.2).


留言 (0)