
記住我
Cancer is caused by excessive proliferation of cells in the body after losing normal regulation (1). When an organism is affected by chemical, physical, viral, and other carcinogenic substances in the environment or by its own genetic, endocrine, sex, age, and other factors, a series of genetic abnormalities and changes can occur, resulting in the formation of malignant tumors. In the early stages of cancer, there are mostly no obvious symptoms, and it is difficult to detect abnormalities on a general physical examination. However, when the tumor is large or invasive, metastasis occurs and symptoms appear; thus, most patients enter the advanced stages of cancer (2, 3).
Cancer prevention and treatment remain a difficult problem that perplexes the medical community. The complex regulatory mechanisms in the body limit research on cancer pathogenesis. In recent years, Mendelian randomization has been widely used in cancer research owing to its unique advantages.
Mendelian randomization is a statistical method based on genetic variation. The core idea of Mendelian randomization is to study the causal relationship between “exposure factors” and “outcome variables” (4–6). In the process of designing experiments, single nucleotide polymorphisms (SNP) in Genome-wide association studies (GWAS) are often utilized as “instrumental variables” (7), which are ultimately utilized to reveal the causal relationship between the “exposure factor” and “outcome variable,” and to exclude the “confounding factors” associated with the “outcome variable”. Compared with traditional epidemiological research methods, Mendelian randomization can effectively eliminate confounding factors and reverse-proof causality, which avoids bias in the results caused by confounding factors (8). Genome-wide association studies (GWAS) of cancer are becoming increasingly popular in the field of epidemiology. So far, more than 70 cancer susceptibility genes (CSGs) have been identified, which can be effectively identified by comparing the frequency of DNA variation with that of healthy individuals (9). GWAS-based Mendelian randomization studies have constituted a significant advancement in the field of epidemiology, and are of paramount importance in the effort to alleviate the global burden of disease.
Bibliometric analysis is a popular disciplinary analysis method based on applied mathematics and statistics and has been widely used in the research of various disciplinary fields (10). The core idea of bibliometric analysis is to collect metadata (e.g., keywords, references, journals, abstracts) from relevant literature and perform statistical analysis of the data so that the hidden correlations between the data can be identified. The results can be further elaborated with the help of visualization tools, which make it convenient for researchers to have a more comprehensive understanding of the discipline or field (11, 12).
We conducted a bibliometric analysis of publications that used Mendelian randomization methods to study cancer over the period 2003-2024 to understand the research trends in the field of cancer over the last 20 years. We summarize the current state of research and research hotspots in the field and analyze the trends in the field in detail.
2 Materials and methods2.1 Data sources and search strategiesTo ensure the authority of the original file, data were retrieved and downloaded from the Web of Science Core Collection (WoSCC) (Index: Science Citation Index extension [SCI-E]). To further study the latest development trends in this field, the time limit was from January 2003 to January 2024, during which the Mendelian Randomization (MR) experiment was widely used in the field of cancer research. To facilitate the statistical analysis of the literature data, we only included English literature. The search was limited to Web of Science (WOS) database subject terms. The following keywords were used: TS= (Mendelian randomization Study AND Mendelian randomization) AND TS= (cancer).
2.2 Inclusion and exclusion criteriaIt was necessary to screen the retrieved literature to ensure the reliability of the data used for the analysis. Two authors independently reviewed the documents in accordance with the following criteria, and any differences were resolved through consultation with third parties.
Inclusion criteria (1): the research topic of the article involves Mendelian randomization Study and cancer; (2) the document type is “article”; (3) the document language is limited to “English”; (4) the publication time is from January 1, 2003, to January 31, 2024.
Exclusion criteria: (1) the topic of the study is not Mendelian randomization and cancer; (2) the document type is “review articles”; (3) withdrawn or duplicate publications; (4) documents that cannot provide the basic information required for bibliometric analysis.
Each record contained the information required for data analysis, such as title, author, keywords, abstract, time, journal information, references, and country. As the data were retrieved from open databases, there were no ethical issues related to access for this study.
2.3 Data analysis and graph acquisitionAccording to the search strategy, a total of 1400 documents were retrieved; however, after screening according to the inclusion and exclusion criteria, 836 documents were used for further analysis (Figure 1).
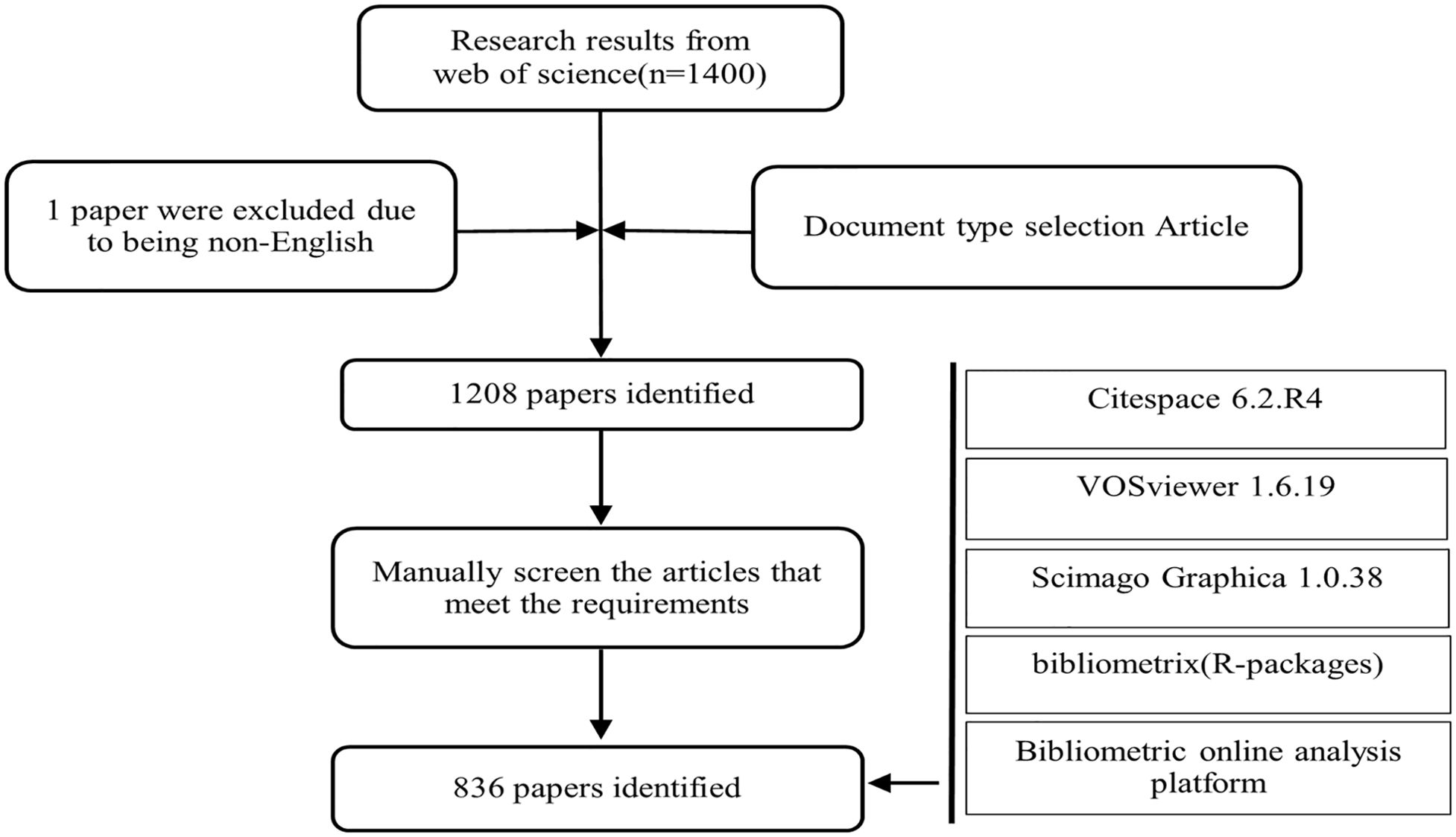
Figure 1. Flowchart of document search, screening, and data analysis.
The data visualization software tools used were CiteSpace 6.2.R4, VOSviewer 1.6.19, Scimago Graphica 1.0.38, Pajek64 5.18, a bibliometric online analysis platform, and Bibliometrix (an R programming language package). CiteSpace is an interactive visual analysis software developed by Professor Chen Chaomei that can carry out different types of network analysis, such as keyword network, state-institution cooperation network, author cooperation network, co-citation periodical cooperation network, and keyword co-occurrence analysis. It is helpful for intuitively analyzing knowledge fields and emerging trends (13, 14). The VOSviewer software was developed by Van Eck and Waltman at Leiden University in the Netherlands in 2009 and is suitable for visualizing data analysis and constructing complex networks of large-scale data (15). Scimago Graphica provides a new way to explore, visually communicate, and understand data. It creates a global map and shows the number of papers published by countries worldwide. Bibliometrix supports the recommended workflow for performing bibliometric analysis. As it is programmed in R, the proposed tool is flexible and can be rapidly upgraded and integrated with other statistical R-packages. It is therefore useful in a constantly changing science such as bibliometrics (16).
3 Results3.1 An overview of the annual growth trendAccording to cancer data released by GLOBOCAN 2020, there would be nearly 19.3 million new cancer cases and nearly 10 million new cancer deaths globally by 2020, and GLOBOCAN’s 2020 cancer data predicts that there will be 28 million new cancer cases globally by 2040 (17) (Figure 2).
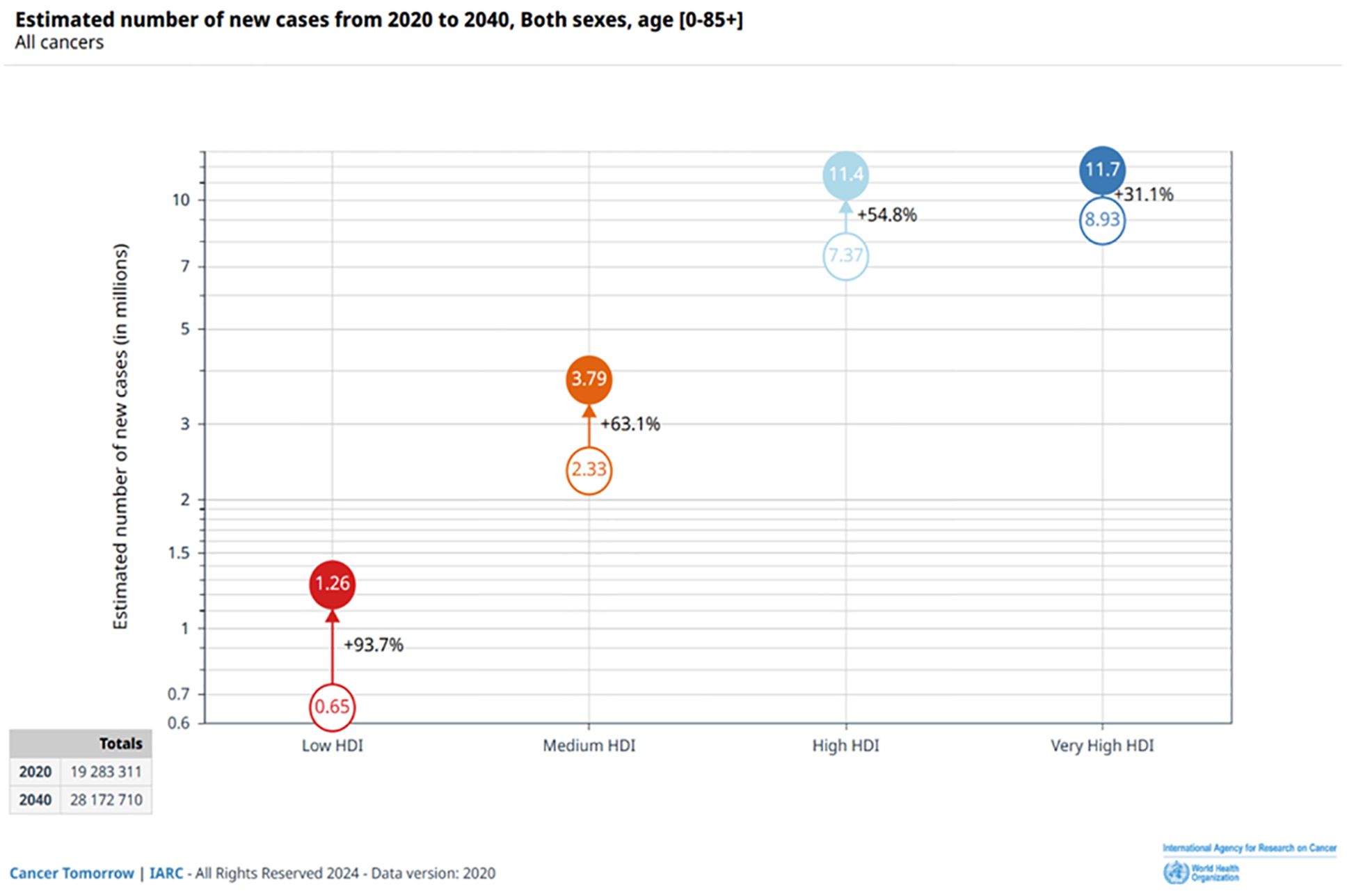
Figure 2. Estimated number of new cases from 2020 to 2040, Both Sexes Combined, age [0-85+], According to the 4-Tier Human Development Index (HDI). Source: https://gco.iarc.fr/.
The data were processed using Bibliometrix R-package, and relevant information about the literature was obtained. According to the literature data, the earliest study on the incidence of cancer using the Mendelian randomization approach was published in 2005. As of January 31, 2024, 836 articles have been published (Figure 3).
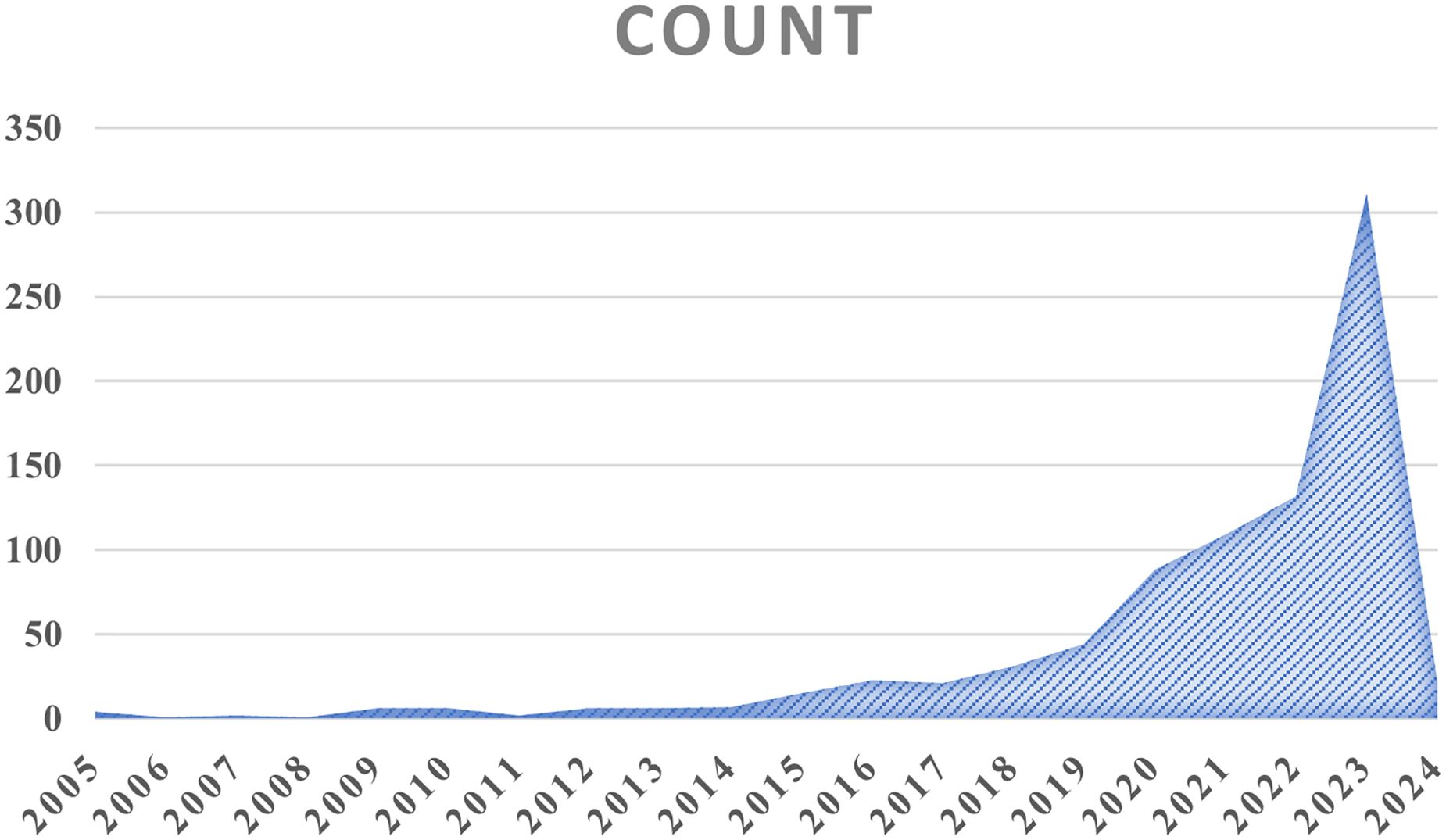
Figure 3. Annual publication volume.
As of January 31, 2024, the annual growth rate of Mendelian randomization and cancer-related articles is 9.12%. These articles were obtained from 243 journals and magazines, and each article cites 15.29 references (Table 1); a total of 24369 references were cited. Starting in 2017, the number of publications exploded until reaching a peak in 2023.
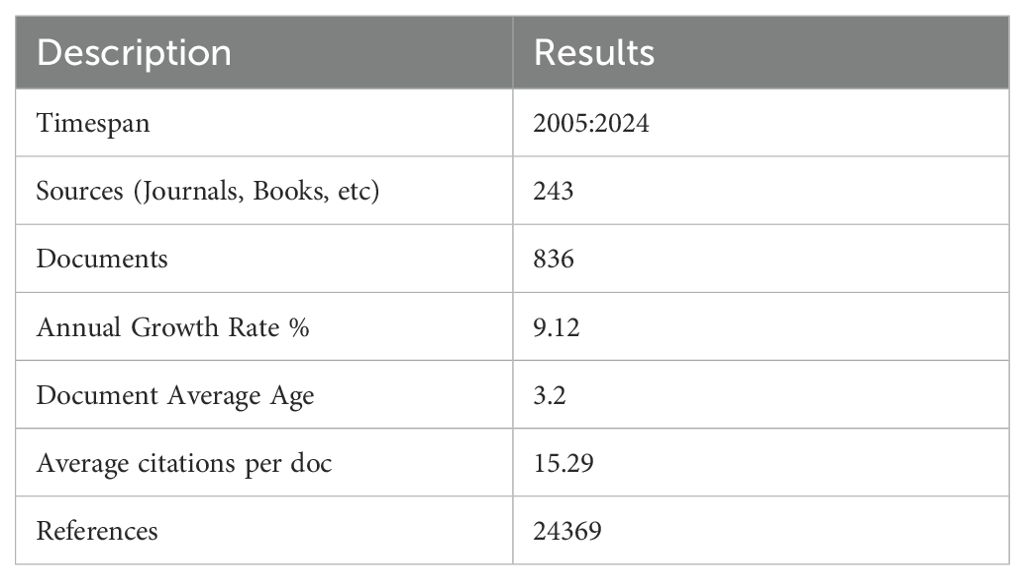
Table 1. Mendelian Randomized-Cancer Literature data.
3.2 Distribution of countries or regions and institutionsThe 836 articles selected in this study came from 72 different countries or regions (Figure 4), of which the top 10 were CHINA (n=478), USA (n=289), ENGLAND (n=313), SWEDEN (n=145), GERMANY (n=127), AUSTRALIA (n=122), FRANCE (n=108), CANADA (n=88), DENMARK (n=79), and SPAIN (n=78). The number of articles jointly published by countries in cooperation with each other is shown in Table 2.
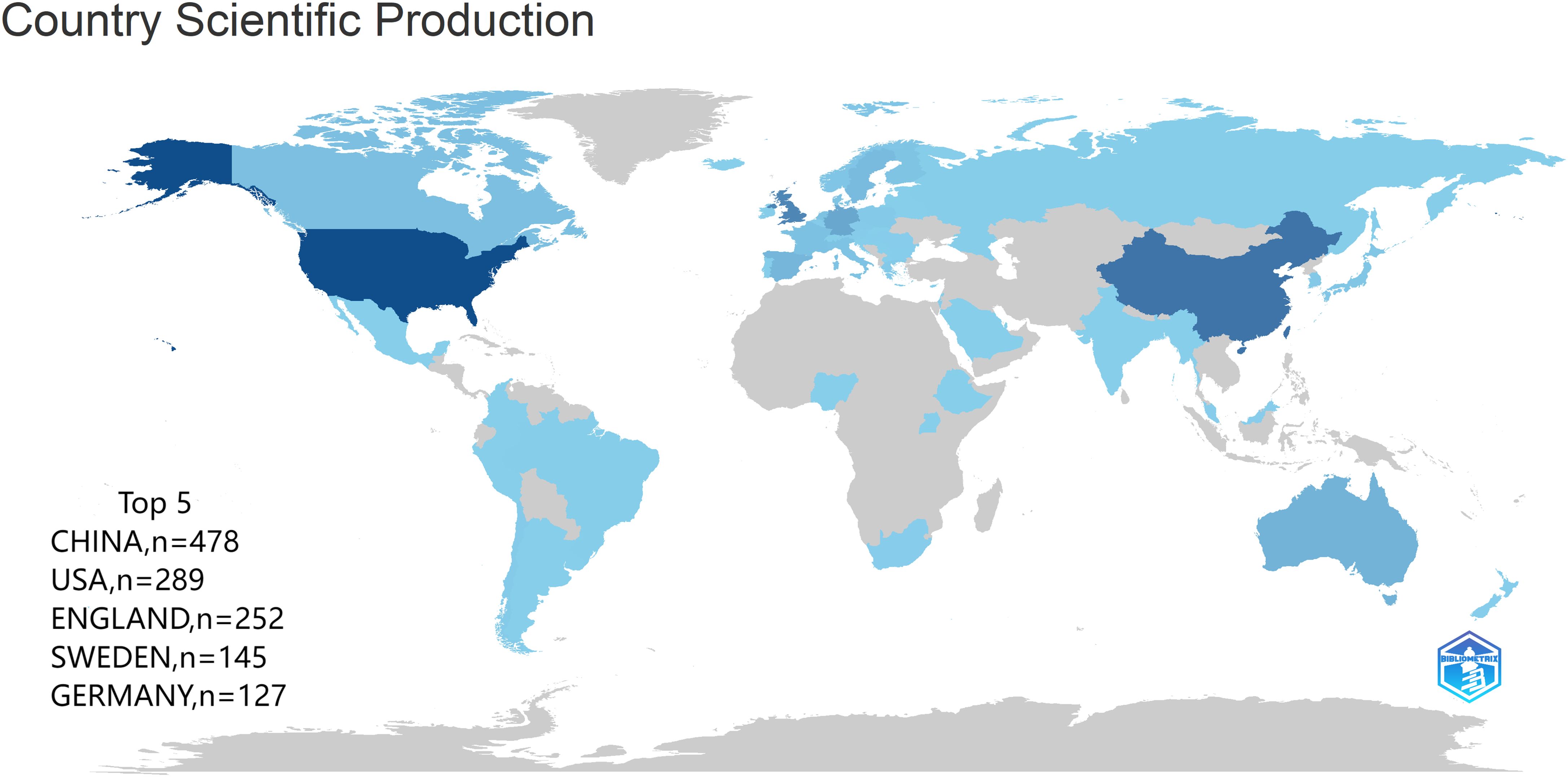
Figure 4. Map of the world (number of articles published by country).
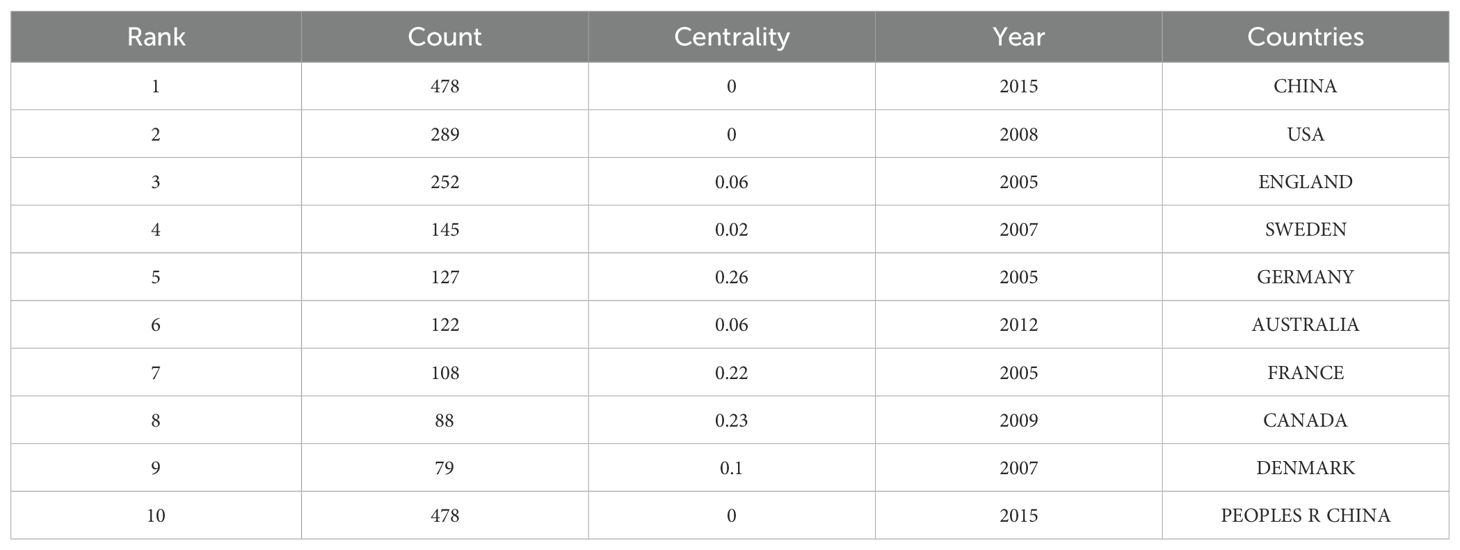
Table 2. Countries with the number of published articles in the top 10.
Germany and the UK were the first countries to publish Mendelian randomization-cancer articles. The number of articles from the United States has increased steadily since 2015, indicating that research in this field has tended to be stable. The first Chinese article on the application of Mendelian randomization in the field of cancer was published in 2015, and the number of articles published has increased since 2019, indicating that an increasing number of Chinese researchers are beginning to explore this field (Figure 5). The country cooperation map shows the academic cooperation between various countries and regions. Italy has the most extensive cooperation with other countries. Among the top 10 countries in terms of the number of articles published, Germany has the most extensive academic cooperation with other countries, and there is also close cooperation among European countries. In addition, communication between other countries and regions needs to be strengthened (Figure 6).
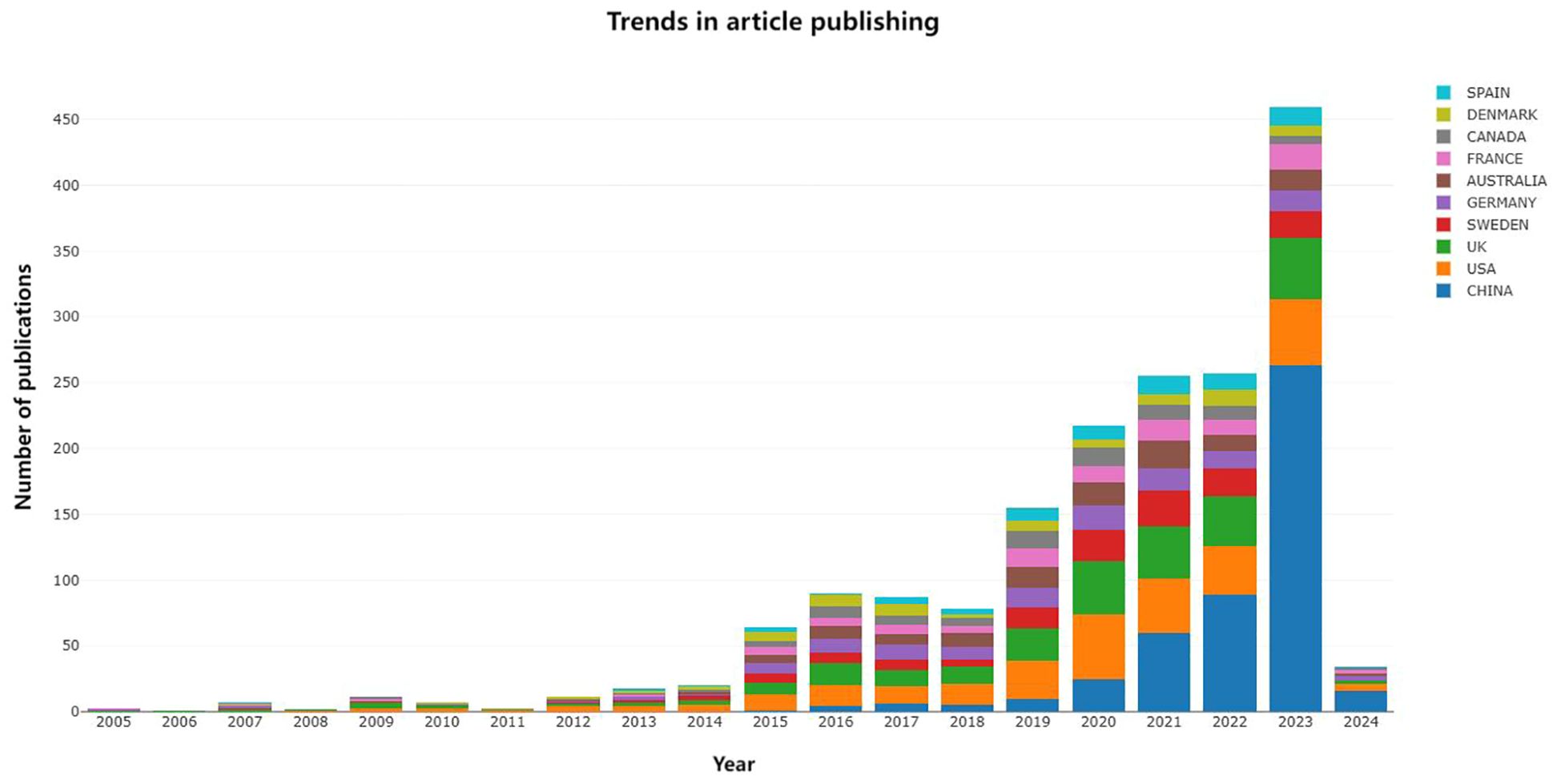
Figure 5. Bar chart of the top ten countries in the number of articles published.
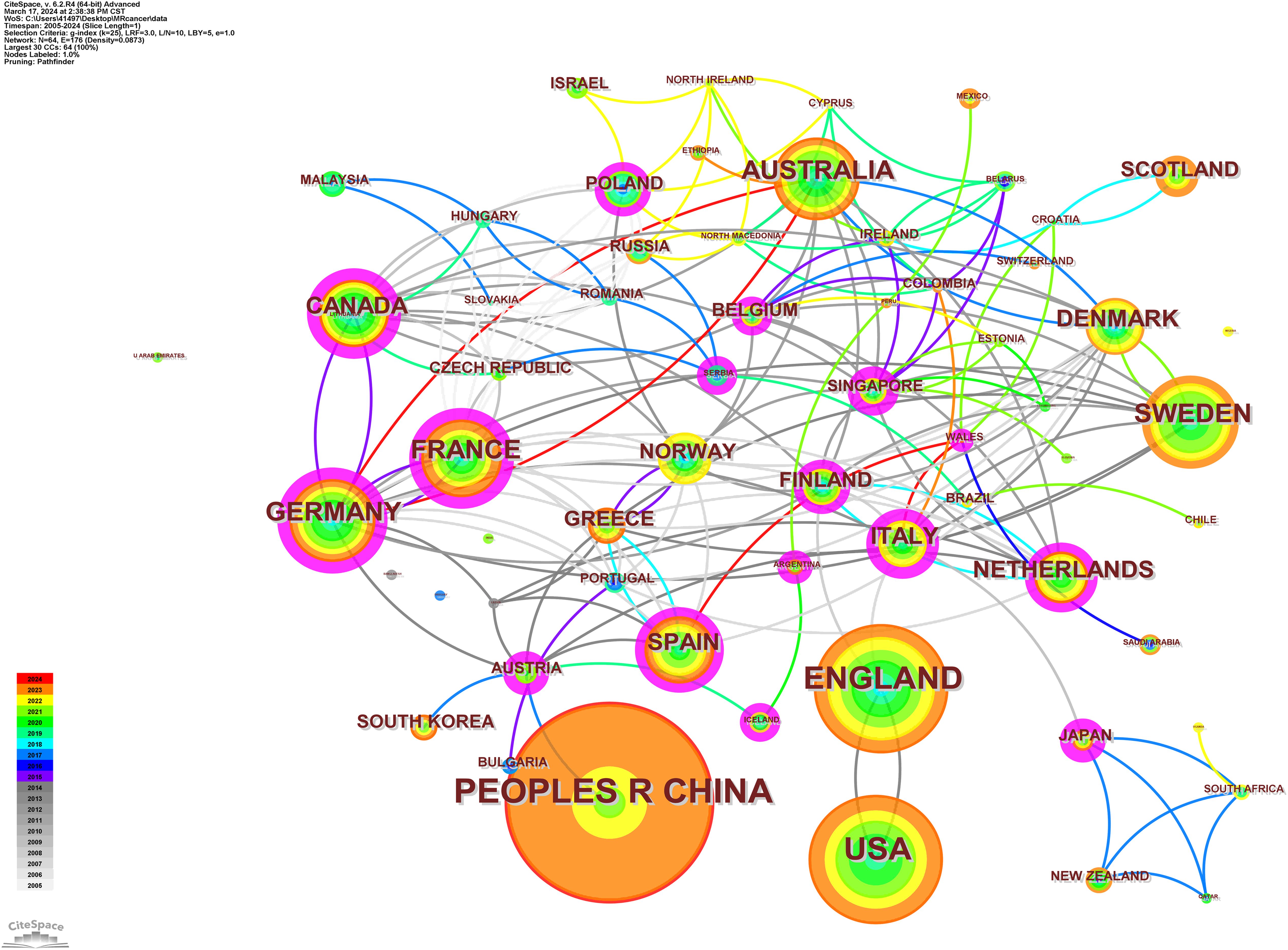
Figure 6. The country cooperation map.
As shown in Figure 7, each node represents an organization. The node size represents the number of articles published by the organization, internal color of the node represents a different publication time, and connection between nodes represents cooperation between the organizations. The thicker the line, the closer the cooperation between the agencies. A total of 413 institutions worldwide have published articles in this field. The top 10 institutions in terms of the number of published papers were mainly from the United Kingdom (n=3), the United States (n=2), Germany (n=2), Sweden (n= 1), Switzerland (n=1), and France (n=1) (Table 3). From the centrality value in Table 3, we can see that among the top 10 institutions in terms of the number of articles published, the Helmholtz Association and German Cancer Research Center (DKFZ) cooperated most extensively with other academic institutions, whereas the remaining eight institutions preferred to conduct research independently. The central value is used to describe the degree of cooperation between organizations. Of the 417 institutions, the top three institutions with the most extensive cooperation are Imperial College London (Centrality=0.25), Kaiser Permanente (Centrality=0.23), and Cancer Council Victoria (Centrality=0.17). (A centrality value of 0 does not mean that there has never been any cooperation with any other organization, but that the amount of cooperation is smaller than other institutions.).
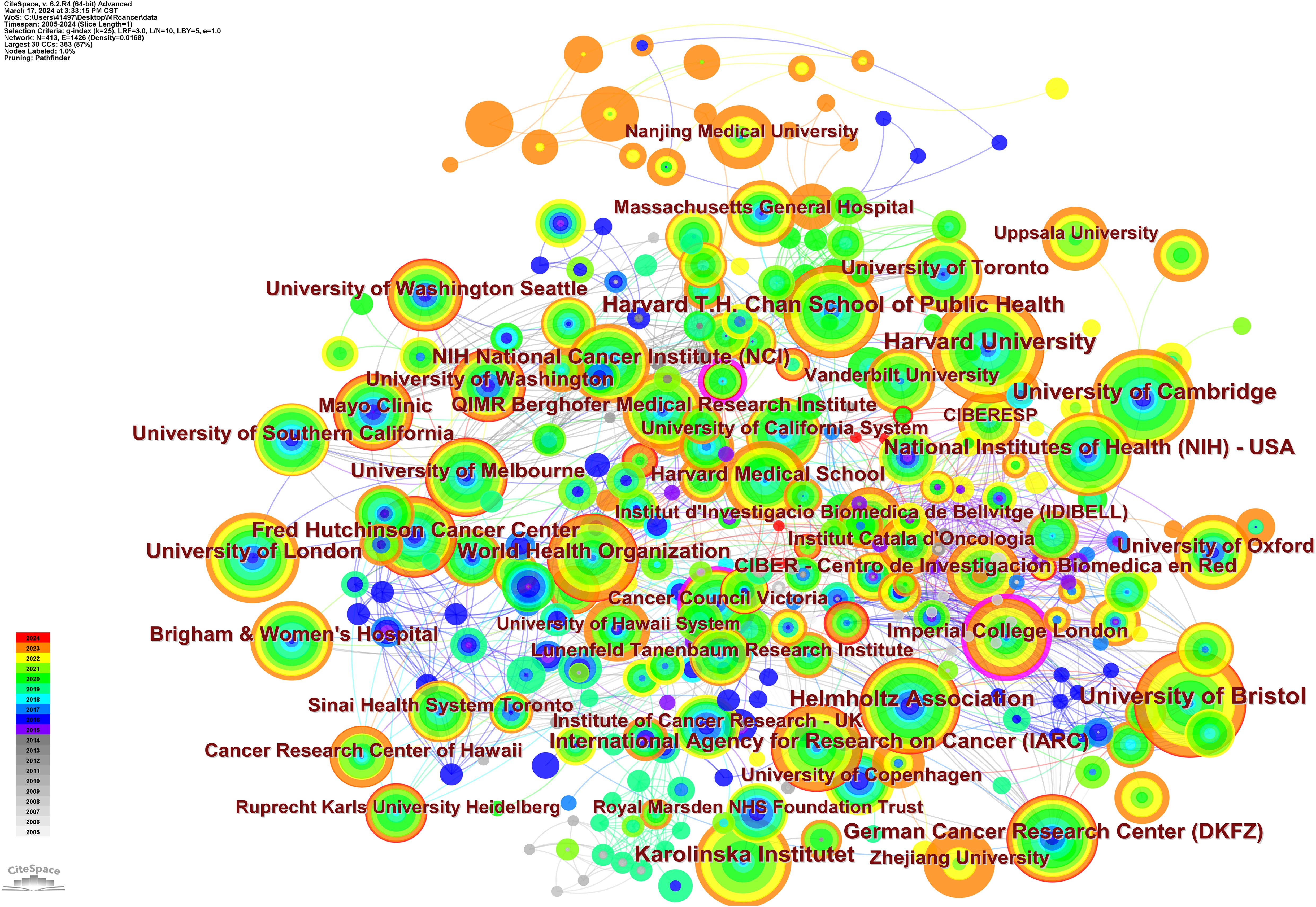
Figure 7. Institutional co-occurrence map.
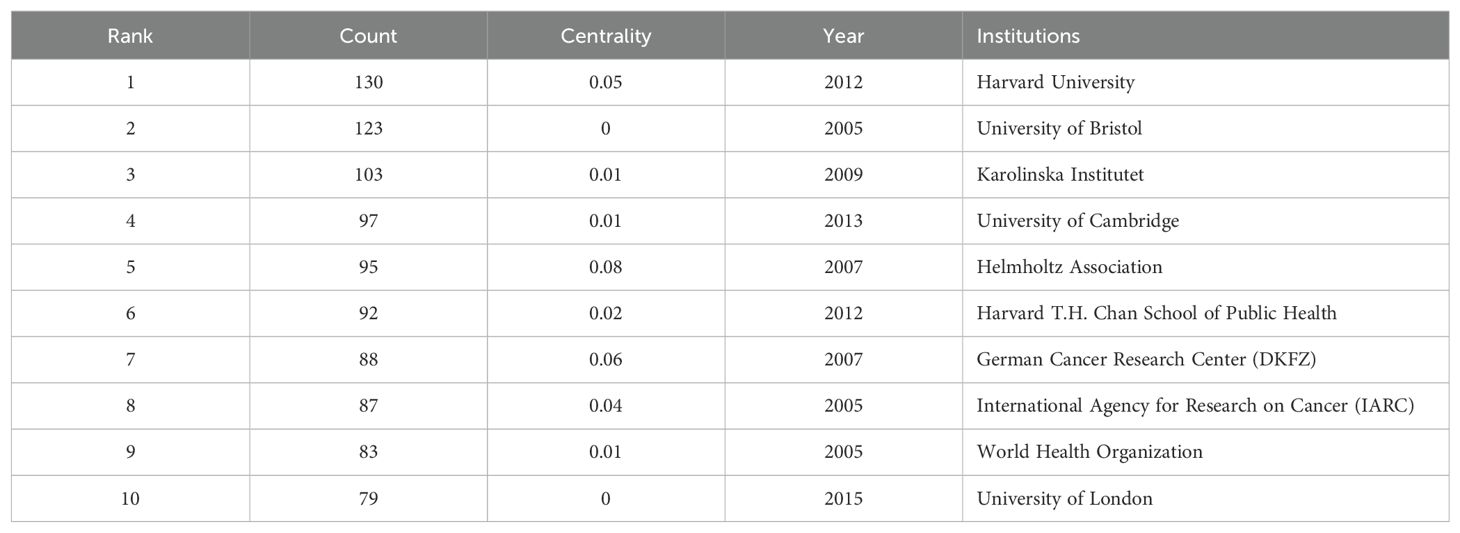
Table 3. The top ten institutions in the number of articles published.
3.3 Distribution and co-authorship of authorsA total of 643 authors worldwide have published articles in the field of Mendelian randomization-cancer. The top ten authors of published articles were from the UK (n=3), Germany (n=2), Australia (n=1), China (n=1), the USA (n=1), France (n=1), and Sweden (n=1) (Table 4). Smith, George Davey—a professor of the University of Bristol—is an expert in many fields, including Environmental & Occupational Health, General & Internal Medicine, Genetics & Heredity, and Cardiovascular System & Cardiology. He specializes in Mendelian randomization research methods for studying disease pathogenesis. One of the most cited articles on Mendelian randomization published by the professor discusses how to properly use data from GWAS and proposes a validation method that provides a sensitivity analysis for the robustness of the findings from a Mendelian randomization investigation (18). He also called on researchers around the world to use the Mendelian method of randomization correctly and carefully, and to apply appropriate statistical methods when screening for “instrumental variables” related to “exposure factors” in order to avoid false-positive results (19).
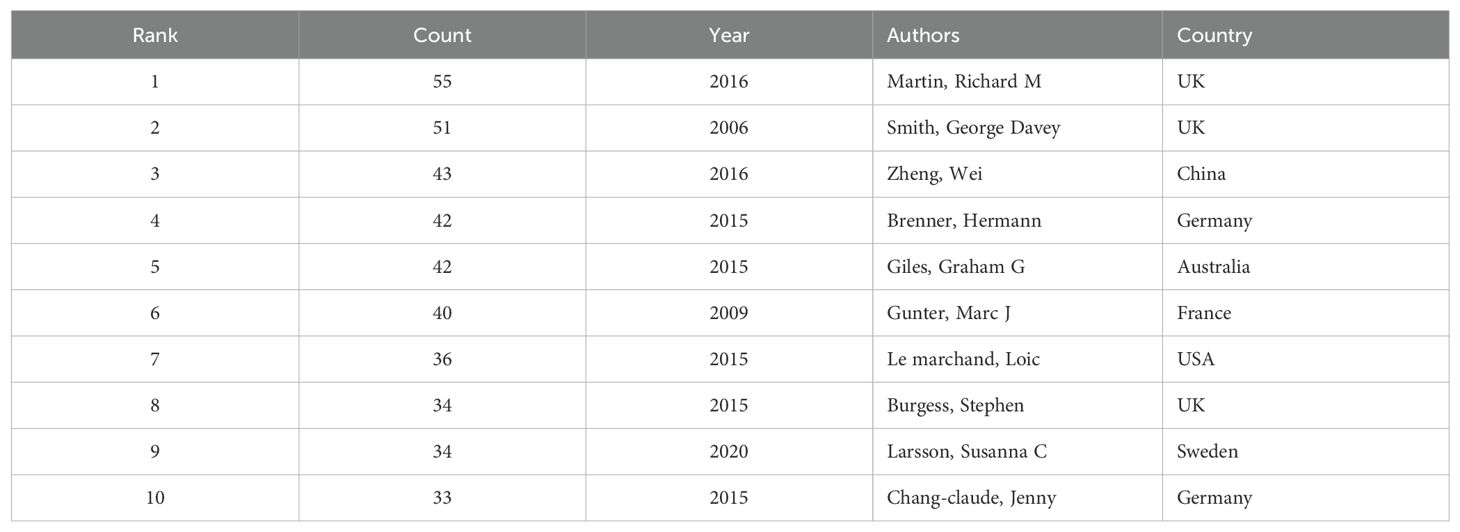
Table 4. The top ten authors of articles published.
He has combined various analytical methods with epidemiology to analyze the pathogenesis of many diseases, making a significant contribution to the global public health field. Martin, Richard M—also from the University of Bristol—is an expert in many fields, including Oncology, General & Internal Medicine, and Nutrition & Dietetics. One of the most cited articles in the field of Mendelian randomization-cancer concerns a study of the causal relationship between telomere length and the incidence of cancer and non-oncologic disease, and the results showed that telomere length was positively associated with cancer risk (20). Professor Smith, George Davey also participated in this study. These two experts are the core authors in the field of Mendelian Randomization – Cancer.
The co-author co-occurrence map visually shows the cooperation of authors. Each node represents an author, the node size represents the number of articles published, color within the node represents the publication time of the article, and the more the line segments between the nodes, the more extensive the cooperation between the authors (Figure 8). The authors with the most extensive collaborations were Haycock, Philip C (n=11, Centrality=0.15); Smith, George Davey (n=51, Centrality=0.14); and Lewis, Sarah J (n=19, Centrality=0.13).

Figure 8. Co-author co-occurrence map.
3.4 Analysis of journals and co-cited academic journalsThis study included 836 articles published in 243 journals. Among the top ten journals with the highest number of published articles in this field, six belong to the field of oncology (International Journal of Cancer, Cancer Epidemiology Biomarkers & Prevention, Frontiers in Oncology, Cancer Medicine, Journal of Cancer Research and Clinical Oncology, and British Journal of Cancer), two belong to comprehensive journals (Scientific Reports and BMC Medicine), and the other issues are related to epidemiology and public health (Table 5). After clustering with the VOSviewer software, there were five clusters in total. As shown in Table 5, each node represents a journal, node size represents the number of articles, line segment represents the association strength between journals, and different colors represent different clusters. The journals in red clustering are mainly related to cancer, journals in green clustering are mainly related to genetics and immunology, and blue clustering and other color clustering belong to comprehensive medical or comprehensive journals (Figure 9).
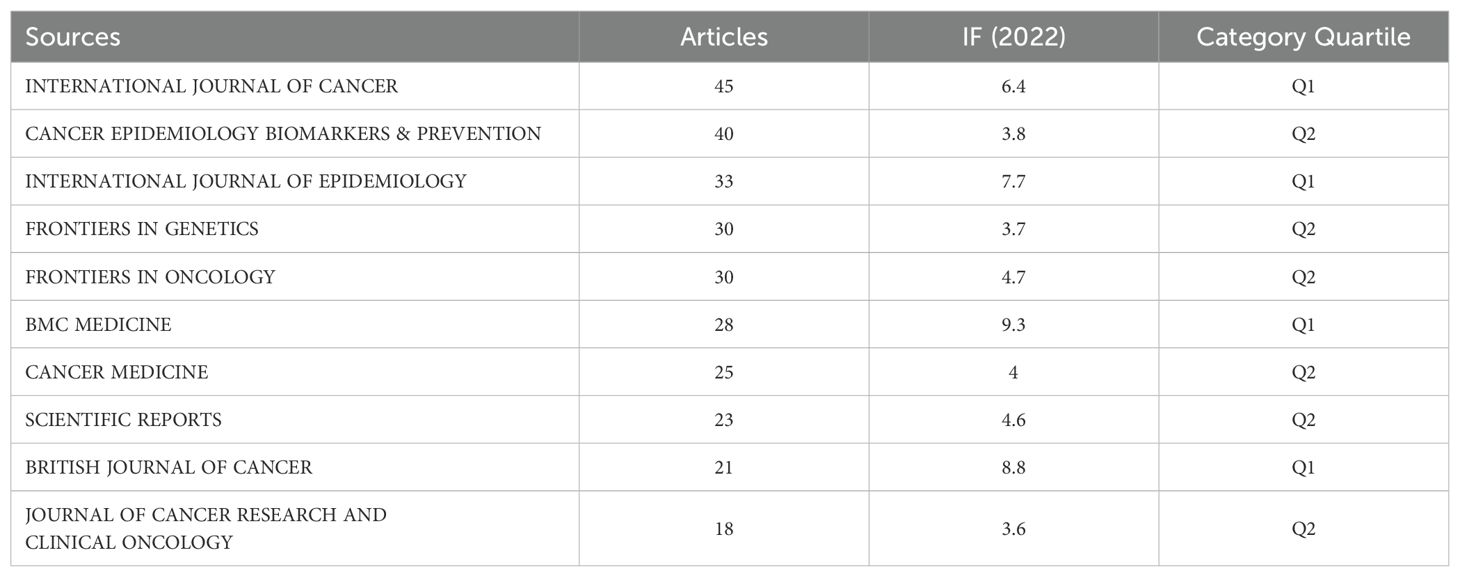
Table 5. Top 10 journals with the largest number of articles in this field.
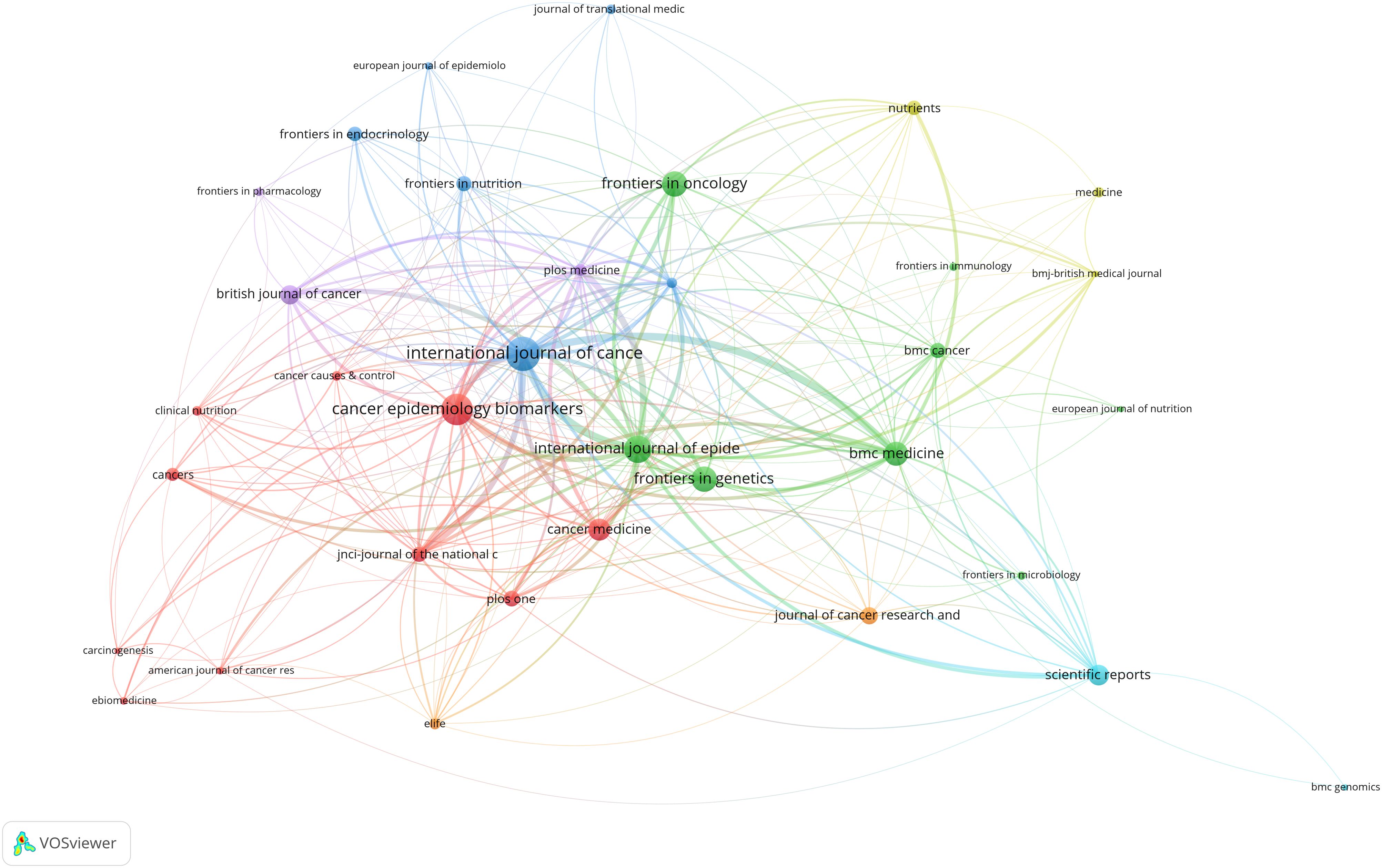
Figure 9. Journal cluster map.
The top three most cited journals were the International Journal of Epidemiology (IF 2022, 7.7; 718 citations), Nature Genetics (IF 2022, 30.8; 688 citations), and the International Journal of Cancer (IF 2022, 6.4; 517 citations) (Table 6).
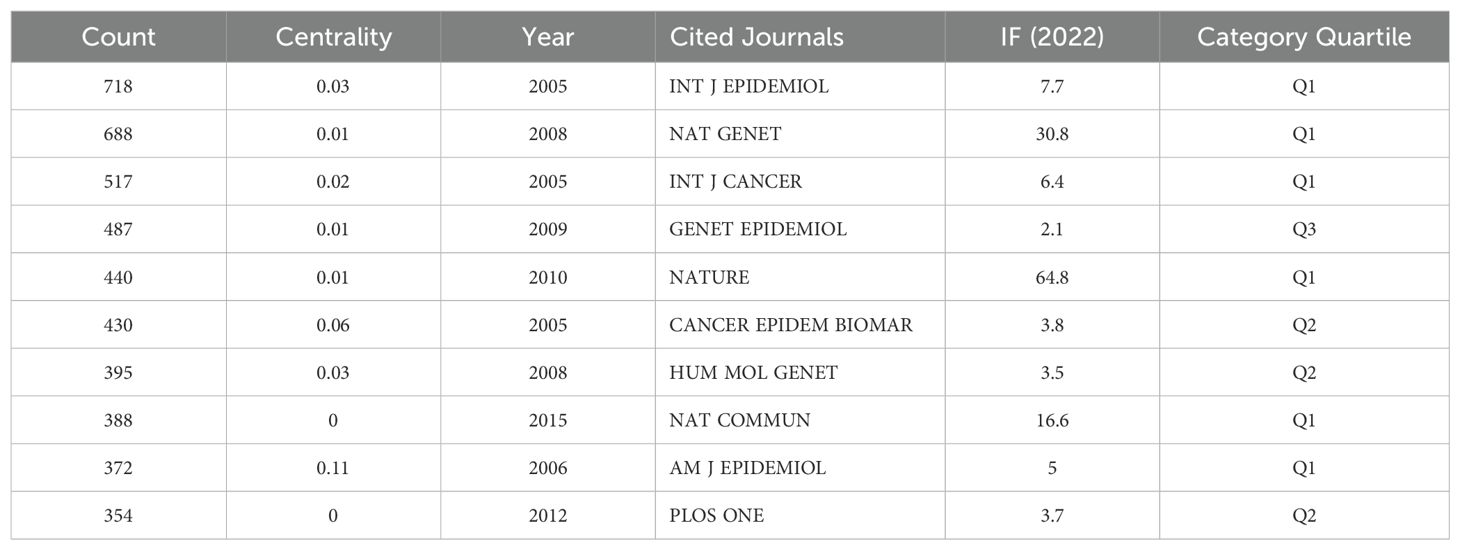
Table 6. The top ten journals with the highest number of cited journals.
The co-occurrence map of the cited journals shows that three journals, Annals of Human Genetics (centrality=0.31), American Journal of Human Genetics (centrality=0.26), and American Journal of Clinical Nutrition (centrality=0.19), have the highest centrality values according to the numerical ranking of centrality, indicating that these three journals are cited along with a large number of other journals (Figure 10). The above impact factor values were derived from Web of Science data.
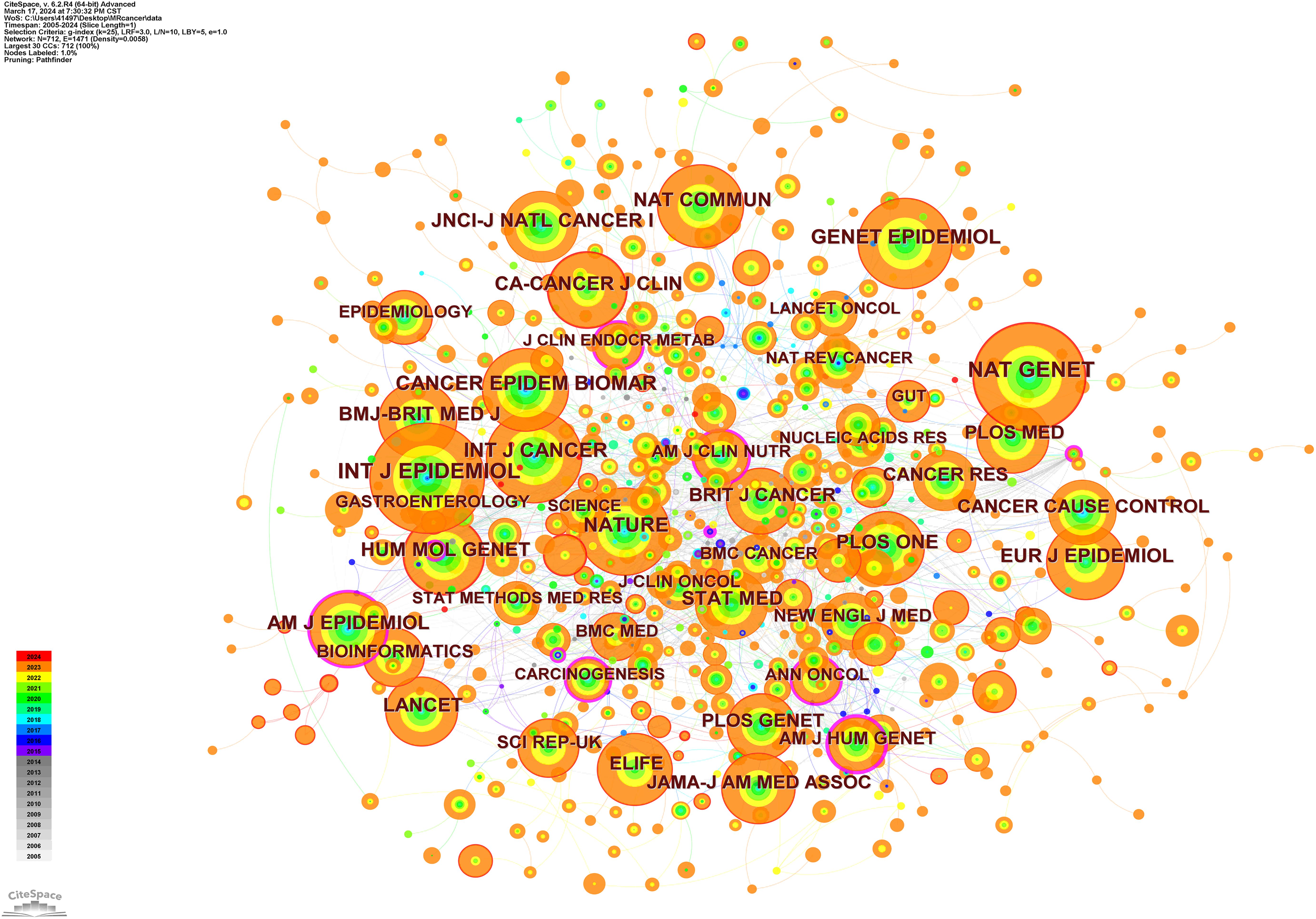
Figure 10. Co-occurrence map of cited journals.
3.5 Keywords analysisFrom the 836 articles included in this study, 546 keywords were used. Table 7 shows the top ten keywords in terms of frequency (excluding the keywords “Mendelian randomization” and “cancer”). We sorted all the keywords related to the types of cancer, and the top four with the highest frequency were “breast cancer”, “colorectal cancer”, “prostate cancer”, and “lung cancer”. “Breast cancer” and “colorectal cancer” were the earliest to be combined with Mendelian randomization research methods. The combination of research on “thyroid cancer,” “liver cancer,” “oropharyngeal cancer,” and “nonmelanoma skin cancer” with Mendelian randomization methods was relatively late, in 2023 (Table 8).
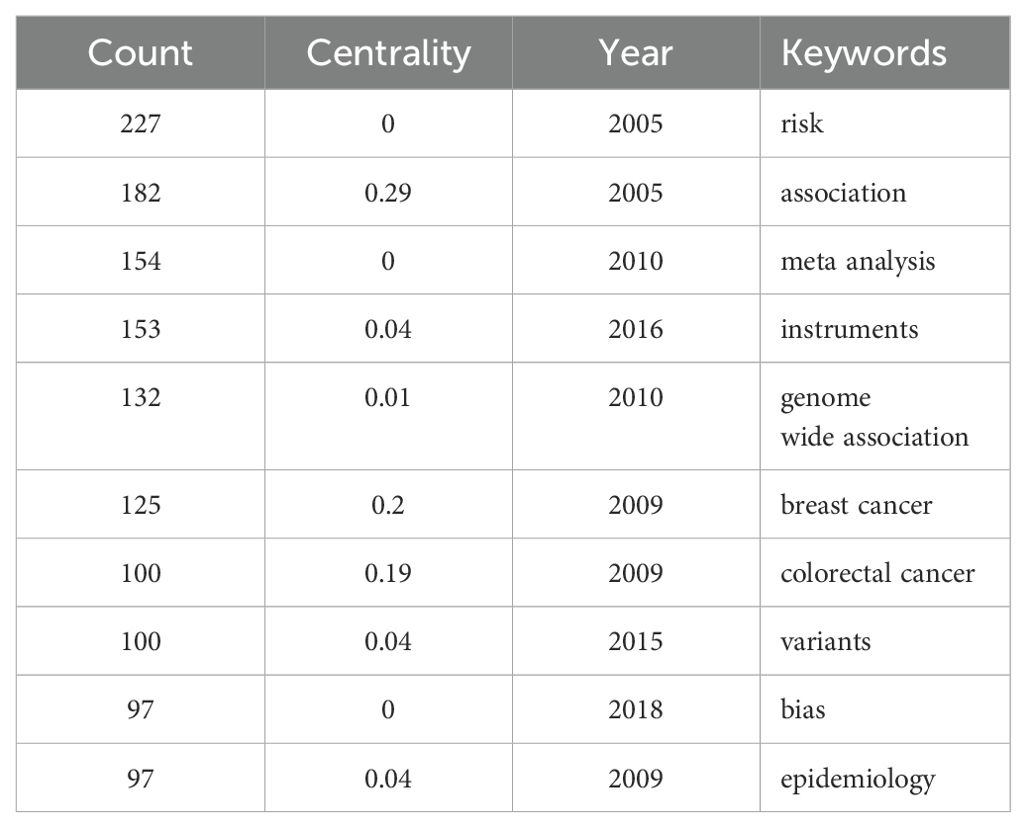
Table 7. The top ten keywords in frequency.
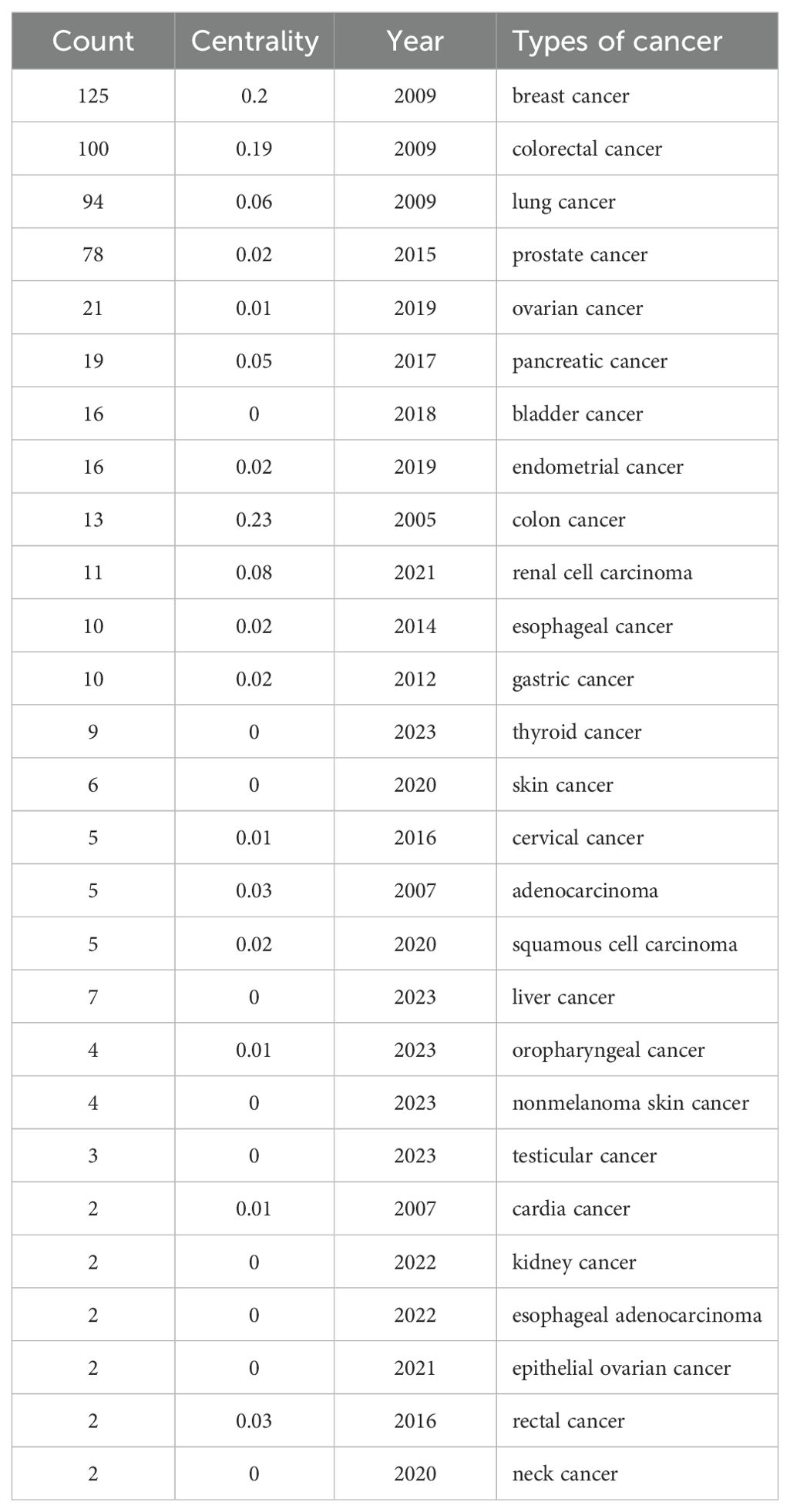
Table 8. The types of cancer in key words.
The keyword co-occurrence map shows the relationship between keywords and that between keywords and time. Each node represents a keyword; the color of the dot represents the time when the keyword appears, and line segment represents the correlation between keywords (Figure 11). The 15 terms with the highest epidemic intensity are listed in Table 9. From the Keywords with the Strongest Citation Bursts table, the keyword “cigarette smoking” has been consistently high since it appeared in 2012. From 2012 to 2021, a total of 16 papers reported on the relationship between smoking and cancer risk, among which the most cited paper was published by Larsson SC, Carter P, Kar S, et al., which discussed whether long-term smoking and alcohol consumption would increase cancer risk. The results showed that smoking may be a risk factor for head and neck, esophageal, stomach, cervical, and bladder cancer (21).
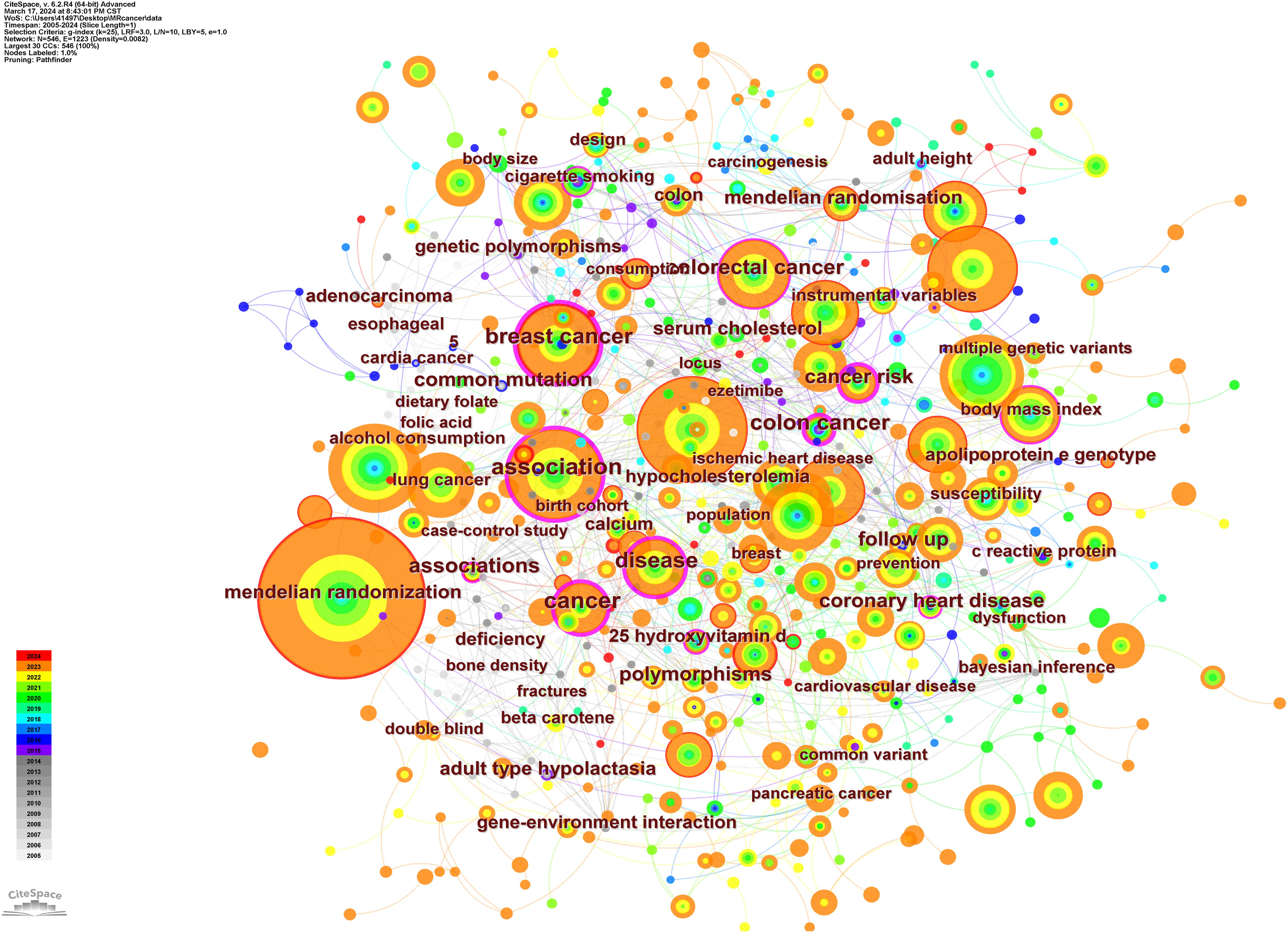
Figure 11. Keyword co-occurrence map.
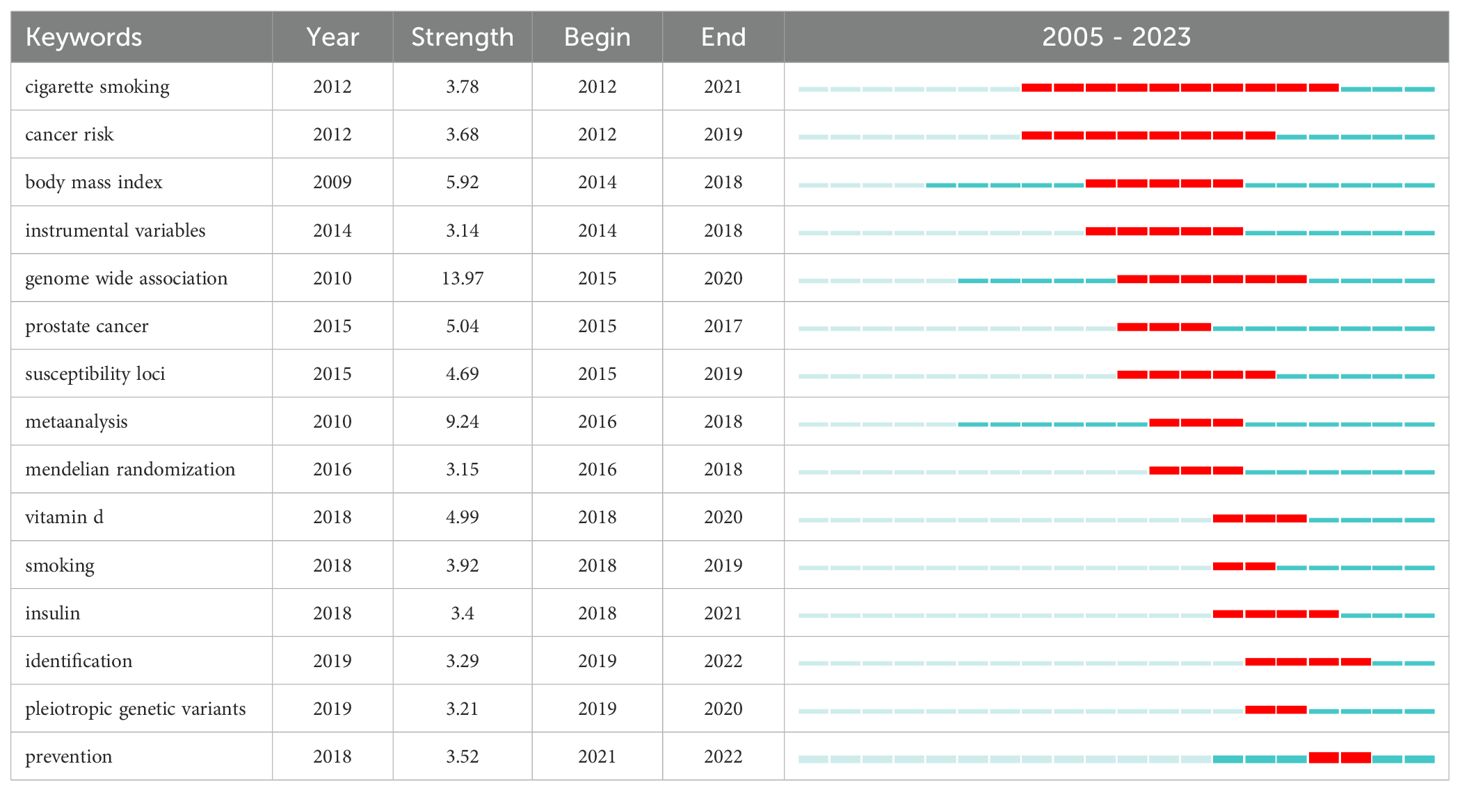
Table 9. Top 15 Keywords with the strongest citation bursts.
3.6 MR data sourceWe analyzed the commonly used MR analysis databases in the included articles. Some of the GWAS data in these MR studies were sourced from relevant GWAS meta-analysis publications, while others were obtained from specialized fields (such as psychiatric GWAS databases) or comprehensive GWAS databases. The UK Biobank is one of the most commonly used GWAS databases in MR research (22). This is an open-source GWAS comprehensive database that collects genetic phenotypes including but not limited to BMI, cardiovascular disease, cancer, diet, and daily behavior. The UK Biobank database collected 7,221 phenotypes from 6 continental ancestral populations for GWAS analysis (Table 10), completed by Neale laboratory (23). The FinnGen database was initiated in Finland in 2017 and encompasses genetic data and health registry data from 500,000 Finns, inclusive of GWAS data for 1,932 diseases (24). The Psychiatric Genomics Consortium (PGC) database is a repository of data and resources dedicated to advancing the understanding of the genetic and molecular basis of psychiatric disorders. Its scope encompasses a range of research areas, including genome-wide association studies (GWAS) and behavioral investigations into the etiology and pathogenesis of bipolar disorder, Alzheimer’s disease, autism, attention deficit hyperactivity disorder (ADHD), and anxiety (25). CKDGen Consortium is an open-source GWAS-Meta database that collects and publishes GWAS-Meta analyses on kidney function diseases (26). The Early Growth Genetics (EGG) consortium is dedicated to the analysis of GWAS data spanning the fetus to young adult period. This encompasses a range of data types, including fetal data, maternal data, birth weight, childhood BMI, and combined data from adolescence (27). The Social Science Genetic Association Consortium (SSGAC) is a database of genetic association studies related to social sciences. The database is a repository of data that can be queried to identify correlations between genetic variants and social phenomena (28).
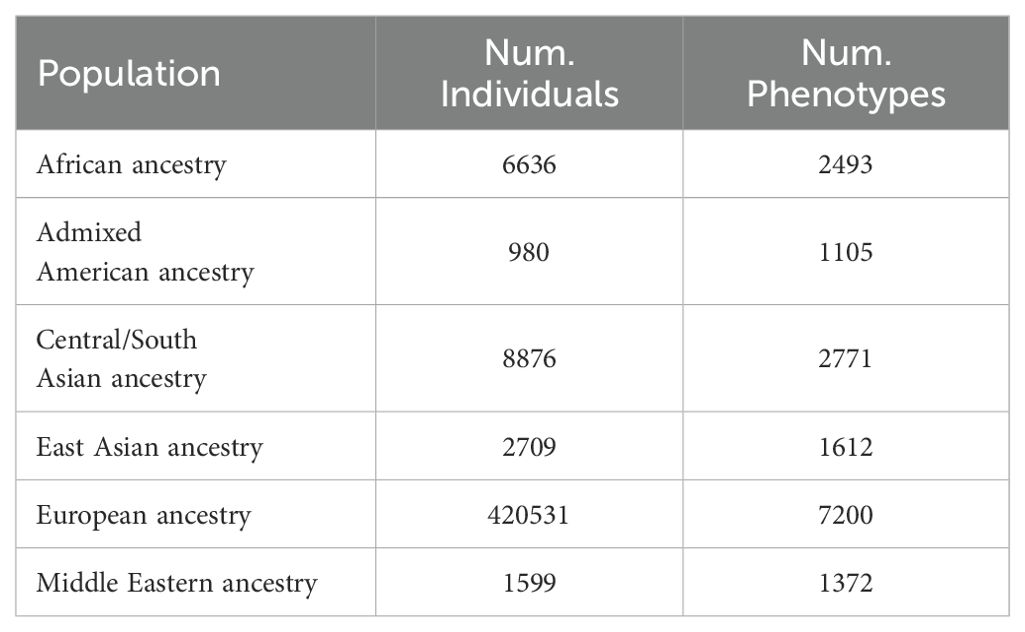
Table 10. UK Biobank population phenotyping data.
4 DiscussionThe dual journal map overlay reveals two main citation pathways (produced by the CiteSpace software) (29): clustering of journals published within the field on the left (cutting-edge knowledge) and clustering of cited journals on the right (basic knowledge). Articles related to the Mendelian randomization-cancer field are published in two main clustering domains: the first clustering domain includes Molecular Biology and Genetics, and the second domain mainly includes Health, Nursing, and Medicine. The two main relevant clustering domains within the field are derived from the two main clustering domains of the journals of the cited literature: the first one mainly includes Molecular Biology and Immunology, and the second category mainly includes Medicine, Medical, and Clinical journals. Figure 12 shows the dual journal map overlay visualization.
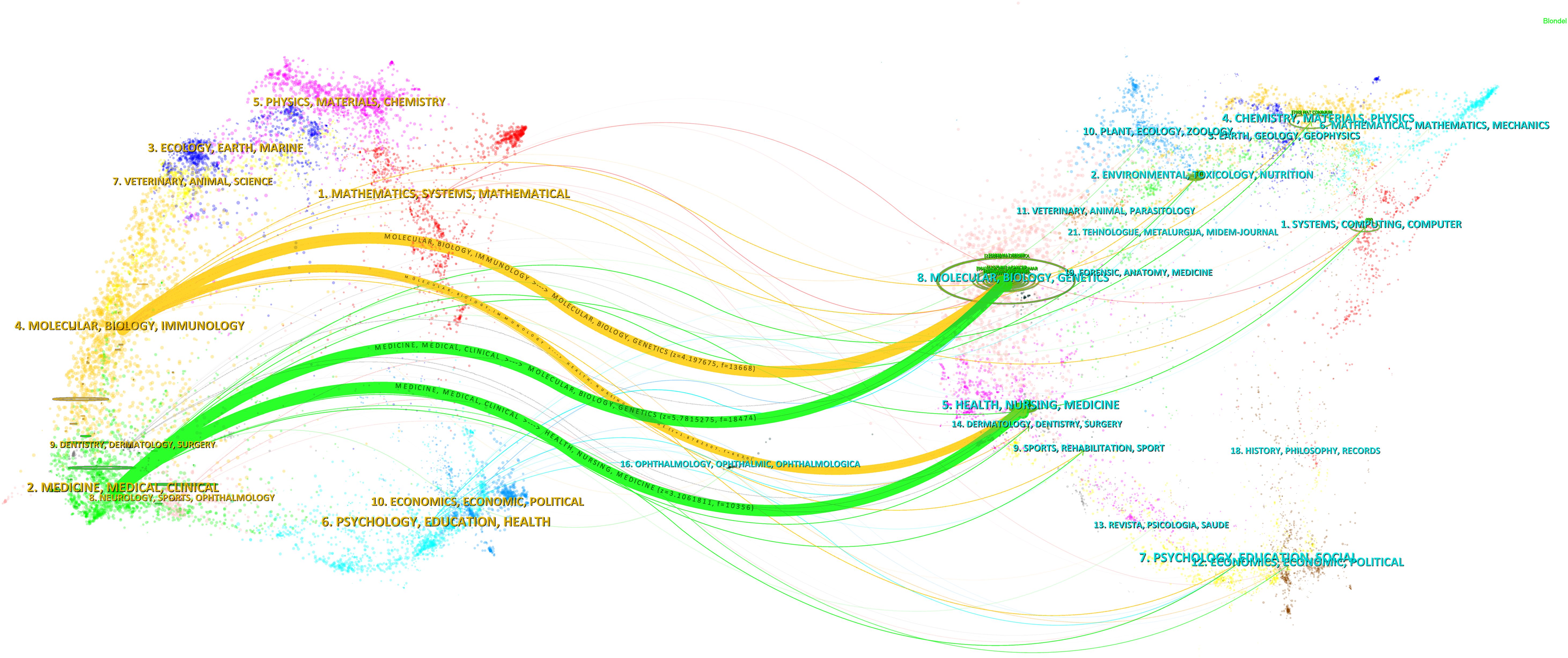
Figure 12. The dual journal map overlay.
The Mendelian randomization research method is based on genetics and epidemiology and derives causality from genetic data according to the Mendelian laws of genetics (30). As GWAS become more and more in-depth, the “instrumental variables” available to researchers in Mendelian randomization studies are becoming increasingly accurate, which is simultaneously more conducive to the diversity of “exposure factor” choices and the breadth and accuracy of “confounding factor” exclusions (31, 32). The continuous improvement of GWAS databases not only promotes the study of cancer pathogenesis but also plays a key role in the exploration of prognostic markers for cancer (33, 34). Open-source data analysis platforms based on GWAS databases also play an important role (35).
Our bibliometric analysis revealed that the most frequently utilized GWAS database is the UK Biobank. Although the database contains GWAS data on 7,221 phenotypes from six continental ancestral groups, its primary focus is on European populations. In addition, since population weights are rarely mentioned in Mendelian randomization studies, the UK Biobank database alone cannot represent all global populations. Our findings revealed a paucity of GWAS studies on Asian populations, resulting in a dearth of two-sample Mendelian randomization studies targeting Asian populations or genetic phenotypes. It remains unclear whether these Mendelian randomization results are biased by race.
We counted all the types of cancer in the keywords of 836 articles, and the most frequently occurring keyword was breast cancer, and there was a wealth of research on the “exposure factors” that contribute to the risk of breast cancer. A higher relative sugar intake can genetically increase the risk of Luminal B and HER2-positive breast cancer (36). There is also an association between the gut flora microbes and breast cancer, with studies showing that an increased abundance of the Genus_Sellimonas is causally associated with an increased risk of ER+ breast cancer (37). In terms of diet, the consumption of dried fruits and oily fish may have a protective effect against breast cancer (38), and the intake of vitamin E may reduce the risk of breast cancer (39). However, further evidence is required. In terms of keywords related to cancer types, thyroid cancer (first article published in 2023 and nine related articles in that year) and liver cancer (first article published in 2023 and seven related articles in that year) are likely to become the next research hotspots.
In cancer research, the more common “exposure factors” are generally related to physical signs and behaviors. Through Mendelian randomization, increased smoking and drinking behaviors have been shown to increase the risk of gastroesophageal reflux disease (GERD), which is associated with an increased risk of lung cancer (40). A Mendelian randomization experiment with six sets of “instrumental variables” and 78 associated SNPs obtained from the GWAS database concluded that smoking frequency was significantly and positively associated with bladder cancer risk (41). A two-sample Mendelian randomization study demonstrated that insomnia was positively associated with the risk of lung cancer and that sleep duration played a protective role in lung cancer (42). Coffee consumption is positively associated with the risk of digestive system cancers, especially esophageal cancer. Coffee consumption was also positively associated with the risk of multiple myeloma (43). The risk of colorectal cancer in men was associated with a high body mass index (BMI), although its association in women remained unclear. Carrying more alleles for BMI is associated with a higher risk of colorectal cancer (44). In addition, there are some unconventional “exposure factors.” Several factors, including income, education, BMI, and smoking were causally associated with squamous cell lung cancer and overall lung cancer (45). Smoking and education independently correlated with overall lung cancer and squamous cell lung cancer (46). A genetic predisposition of 3.6 years of education above the average reduced the risk of developing lung cancer by 52%, and low education was one of the risk factors for the development of lung cancer (47). Similarly, genetic predictions supported the protective effect of higher educational attainment against esophageal cancer and GERD (48).
It is worth noting that changes in mood are an important factor affecting cancer risk. A number of mental illnesses can lead to an increased risk of cancer. Depression can increase the risk of cervical cancer, and bioinformatics studies have shown that these two diseases are highly related to the PI3K-Akt signaling pathway (49). Another Mendelian randomization study demonstrated that depression increases the risk of breast cancer. Depression is considered a chronic stressor, and this long-term stress may lead to immune dysfunction in the body (50). Major depression, schizophrenia, and bipolar affective disorder are all risk factors for thyroid cancer, and in a 5-year follow-up study, patients with major depression had an overall 1.62-fold increased risk of cancer (51).
We analyzed the keywords, abstracts, journals, and other relevant information of 836 articles and followed the bibliometric analysis method to compile and organize the data and analyze the hidden relationships between various types of information (52). The bibliometric analysis method can indirectly discover current research hotspots in the field of Mendelian randomization-cancer, and simultaneously predict the trends of future research hotspots within this field (53). We inferred the following conclusions from the keywords related to cancer types: articles related to cancers other than breast, colorectal, lung, and prostate cancers will increase in the future. Among them, the fastest-growing ones may be uterine, renal cell, and thyroid cancers, because articles related to these three types of cancers appeared later, but the number of articles was relatively high compared to other cancers in the short term. Contrarily, according to the latest data from the International Agency for Research on Cancer (IARC) (the latest statistics are as of 2022), uterine and thyroid cancers are relatively more prevalent globally (Figure 13). In terms of the selection of “exposure factors,” when studying the pathogenesis of various cancers, there are relatively more articles on the selection of more conventional and specific “exposure factors,” such as height, weight, body fat percentage, and smoking or drinking habits, while there are fewer studies on the selection of relatively abstract “exposure factors,” such as education level, economic status, and environmental factors. With the increasing availability of “instrumental variables” and the incorporation of more statistical methods, it is likely that there will be more studies on relatively abstract “exposure factors” in the future.
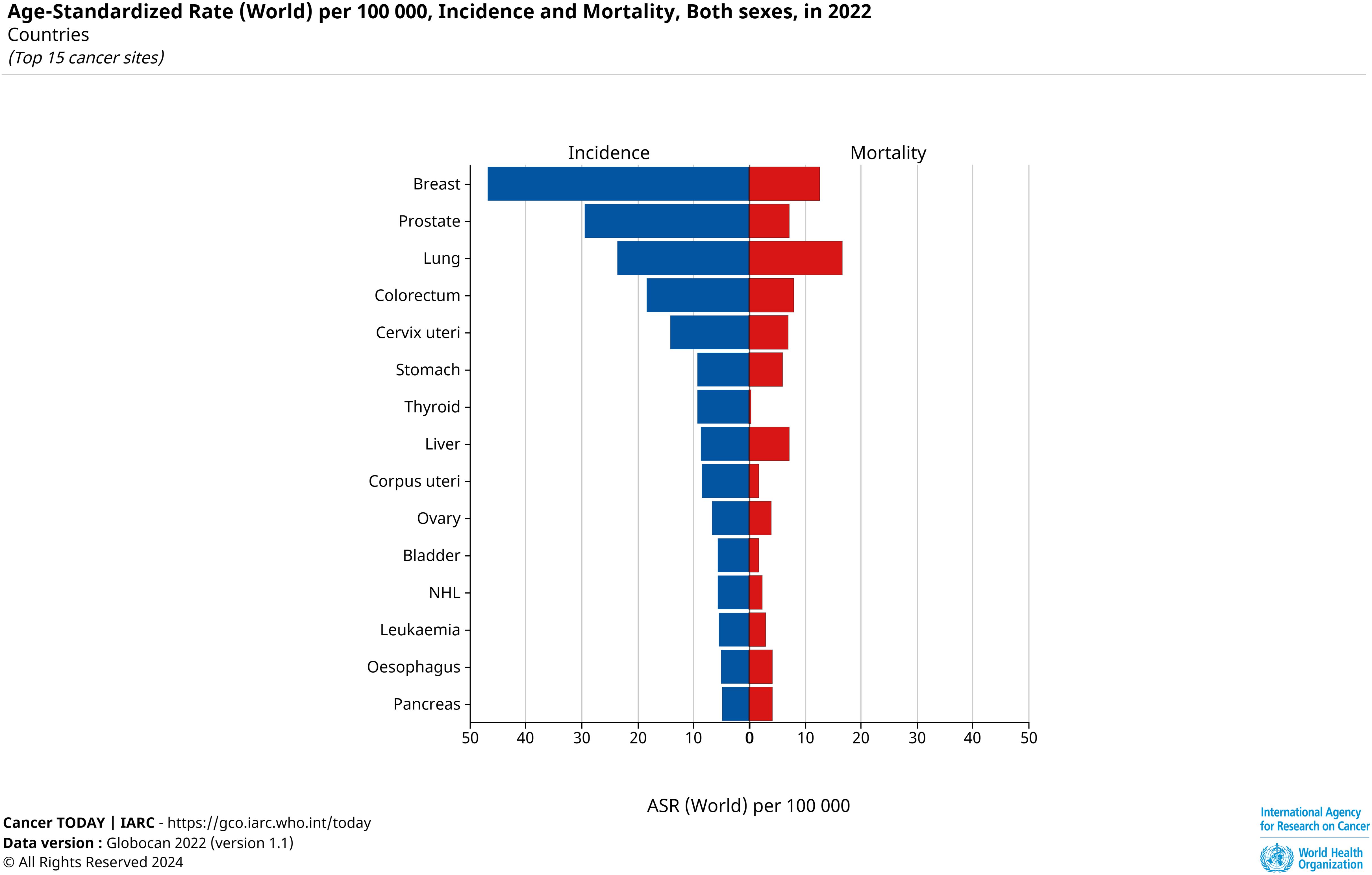
Figure 13. Top 15 cancer incidence rates (per 100,000).
Although an increasing number of researchers worldwide are beginning to use Mendelian randomization methods for more in-depth epidemiological studies, these methods still have some limitations in their current use. For example, when working with genome-wide data, traditional inverse-variance weighted methods can only provide consistent estimates if all genetic variants in the analysis are valid instrumental variables. Depending on the
留言 (0)