Data source and study population
We analyzed routinely collected data obtained from 2018 Medicare Fee-for-Service Beneficiaries. Medicare is a national health insurance program in the USA for people 65 and older, people under 65 with certain disabilities or people with end-stage renal disease. The program provides coverage through two payment mechanisms: either fee-for-service or managed care. For our purposes, beneficiaries were included if they were 65 years of age or older on January 1, 2018, resided in the USA, were continuously enrolled in Medicare under the fee-for-service mechanism for the entire year or until death. At the time of data preparation, the majority of older adults in the USA were managed as fee-for-service. We included only beneficiaries with diagnosed ADRD identified using a validated claims-based algorithm [25].
We obtained patient demographic characteristics (age, sex, race classified using the Research Triangle Institute race code), beneficiary ZIP code, and outcome information (death, hospitalization, and ED visit for any cause) from the administrative data. Age, sex, race, ZIP code and date of death were obtained from the Medicare Beneficiary Summary File. Medicare Provider Analysis and Review (MEDPAR) and Carrier (Physician/Supplier Part B claims) files were used to obtain hospitalizations and ED visit counts. A crosswalk from the Dartmouth Atlas was used to assign beneficiaries to their Hospital Referral Region (HRR) and Hospital Service Area (HSA) based on beneficiary ZIP code [26]. The HSAs were considered clusters in our analysis and HRRs as fixed strata. Note that the concept of the HSA is well-established in the USA, defined as geographic areas around hospitals where individual Medicare beneficiaries tend to be admitted [27]. HSAs are made up of ZIP code region groups based on tertiary medical care referral trends, defined by assigning HSAs to the region with the highest number of major cardiovascular operations performed, with minor adjustments. Thus, HSAs are larger geographic areas in which most Medicare beneficiaries secure specialty care [28]. Each HSA belongs to one HRR.
This study received expedited review approval from the Institutional Review Board of the University of Michigan.
Analytical dataset creation and descriptive analysis
The analytical dataset was constructed first by identifying all eligible beneficiaries and the presence of an ADRD diagnosis in 2018. For each individual, demographic characteristics and the occurrence of outcomes (any hospitalization, any ED visit or death in 2018) were identified. Each beneficiary was followed for one calendar year to assess outcomes. Individual-level patient records were clustered by HSA, with each HSA belonging to one HRR (treated as fixed strata in our analysis). The resultant dataset contained all Medicare Fee-For-Service beneficiaries in the USA in 2018 with a diagnosis of ADRD, across all 3436 HSAs and 306 HRRs across the USA.
To describe the analytic dataset, we present the mean (SD), median (inter-quartile range, IQR) and range of the population size across all HRRs and HSAs. Then, we summarize the outcomes and demographic characteristics (i.e., prevalence of death, hospitalization, and ED visits, as well as average age, proportion of males, proportion of whites) overall as well as by HRR. We show the variation in HRR-specific prevalence by presenting the mean (SD), median (IQR and range) across regions.
Estimation of intra-cluster correlation coefficients
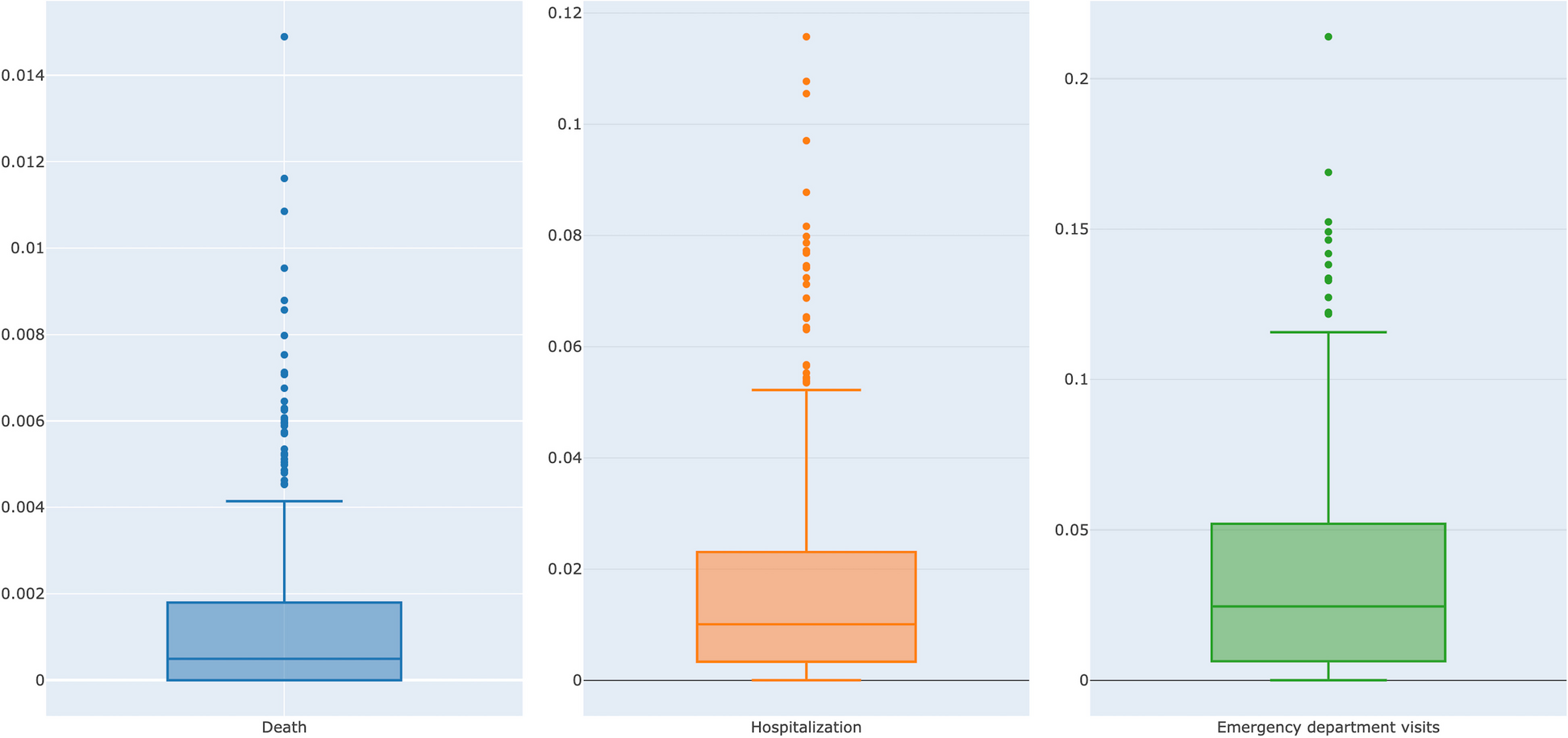
We calculated ICCs for three binary outcomes (death, any hospitalization, any ED visit without hospital admission) and three covariates (age [continuous], sex [male vs female], and race [white vs non-white]). For each variable, we report four types of ICC estimates: (1) unadjusted overall ICC across all HRRs, (2) unadjusted HRR-specific ICC, (3) age-, sex-, and race-adjusted overall ICC across all regions, and (4) age-, sex-, and race-adjusted HRR-specific ICCs.
We chose the ANOVA estimator to obtain the unadjusted ICC estimates for our binary outcomes as the ANOVA estimator is commonly used for binary outcomes and conveniently yields estimates on the proportions scale, which is the scale needed for sample size calculation for binary outcomes. In particular, to obtain the overall unadjusted ICCs for binary variables across all HRRs, we used the stratified ANOVA estimator, with regions treated as fixed strata [29, 30]:
$$\widehat=\frac_-1)MSE}$$
where
$$_=\left[N-\sum_^\sum_^_}\frac_}_}\right]/\sum_^_-1)$$
$$MSG= \frac^\sum_^_}_ }_- }_)}^}^_-m}$$
$$MSE=\frac^\sum_^_}\sum_^_}_- }_)}^}^_}$$
In these formulae, \(\widehat\) is the ICC estimator, \(i\) indexes HRRs, \(j\) indexes HSAs, and \(l\) indexes individuals. We have \(m\) regions (in our case, m = 306), \(_\) service areas in the \(i\) th region, and \(_\) individuals in the \(i\) th region and \(j\) th service area. Let \(_\) be the binary response of the \(l\) th individual in the \(i\) th region and \(j\) th service area. Let \( }_\) Denote the mean response across individuals in the \(i\) th region and \(j\) th service area, and \( }_\) the mean response for all individuals the \(i\) th region (or in the case of binary variables, the proportion). \(_=\sum_^_}_\) is the total number of individuals included in the \(i\) th region, and \(N=\sum_^_\) is the total sample size. To calculate HRR-specific ICCs, we applied the standard ANOVA estimator within each region [29].
As the ANOVA estimator does not permit covariate adjustment, the adjusted ICC estimates for all three outcomes were calculated using a model-based generalized estimating equation (GEE) approach with an exchangeable correlation structure; GEE was chosen as it yields correlation estimates on the natural scale of the outcome [31, 32]. We fitted the model for each outcome adjusting for three demographic covariates (age, sex and race) for each HSA; for the overall ICC, we also included HRR as a fixed covariate (stratum indicator). For each variable, we presented the overall ICC estimates and the distribution of the 306 HRR-specific ICCs using mean, median, IQR, and boxplots. We did not report the individual HRR-adjusted ICCs due to the small number of HSAs in some regions.
The unadjusted ICCs for age, a continuous variable, were calculated using a linear mixed-effect model, treating HSA as a clustering variable. When obtaining overall ICCs, we added HRRs as a fixed covariate. Because negative ICCs are typically regarded as improbable in the context of CRTs, we set negative ICCs to zero [3]. All the analyses were conducted using SAS System for Unix.

留言 (0)