Development of the Deduplicator
Work on the Deduplicator began in June 2021, with the goal of making the deduplication of systematic review search results fast, easy and transparent. The initial design focused on replicating the semi-manual method used by the authors at the Institute for Evidence-Based Healthcare (IEBH) (i.e. using the “Find Duplicates” function in EndNote, with multiple iterations of different matches across fields). The full IEBH deduplication method is available in the supplementary materials (Supplement 1). The initial deduplication algorithm was designed on a set of five deduplicated EndNote libraries obtained from reviews published by researchers at IEBH. After internal testing on the Alpha version of the Deduplicator, the Beta version was released. In August 2021, feedback from expert information specialists was sought by emailing information and a link to the Deduplicator to the US Medical Library Association’s (MLA) expertsearching email list. Feedback from multiple users was provided and incorporated into the Deduplicator. The production version of the Deduplicator was then officially released in November 2021. Since its release the Deduplicator has been accessed thousands of times.
Development of the deduplication algorithm
The initial algorithm used in the Alpha version of the Deduplicator was developed using a training dataset of five deduplicated EndNote libraries. These EndNote libraries were constructed from previous systematic reviews performed at the IEBH. These libraries were independently deduplicated manually in EndNote by two authors (JC and HG). Any differences between the two deduplicated libraries were then resolved by discussion and consensus between the authors. The development dataset is available via the IEBH/dedupe-sweep GitHub repository [12].
During development the deduplication algorithms were measured using four values:
1
True positive \(TP\) is the number of correctly identified duplicate records
2
True negative \(TN\) is the number of correctly identified unique records
3
False positive \(FP\) is the number of unique records identified as a duplicate
4
False negative \(FN\) is the number of duplicate records identified as a unique record
These values used to calculate four metrics:
1
Accuracy: provides the total number of mistakes in the deduplication process (Eq. 1)
2
Precision: provides the number of unique studies incorrectly removed in the deduplication process (Eq. 2)
3
Recall: provides the number of duplicates missed in the deduplication process (Eq. 3)
4
F1 score: combines recall and precision metrics and represents the overall performance of the model (Eq. 4)
The equations for calculating these metrics are:
$$\begin \text = \frac \end$$
(1)
$$\begin \text = \frac \end$$
(2)
$$\begin \text = \frac \end$$
(3)
$$\begin \text = \frac \times \text }+\text } \end$$
(4)
The first algorithm (‘balanced’) started as a modified version of the IEBH deduplication method (Supplement 1). Following this, small modifications were iteratively made to the algorithm. These changes were then evaluated on all five libraries to evaluate if the newly modified algorithm achieves a higher accuracy/precision/recall/F1 score. Eventually, an algorithm was converged which achieved a high accuracy and precision. This algorithm was labelled the ‘balanced’ algorithm, and it is the algorithm that was used in the evaluation study presented in the results of this paper. After the completion of the evaluation, further improvements were made to the algorithm to optimise for either high precision or recall. This produced two improved algorithms (‘relaxed’ and ‘focused’). The ‘relaxed’ algorithm is designed to minimise the number of false positives making it suitable for large libraries of records (> 2000 records) as human checking is less necessary. The ‘focused’ algorithm is designed to minimise the number of false negatives making it suitable for small libraries of records (< 2000 records). The results of these evaluations on the development set of libraries (without human checking) can be found in (Table 5).
Along with each algorithm, a set of mutators are specified at the top of the configuration file. These play a key role as they aim to unify differences between fields in each database. For instance, an author rewrite mutator will unify the different ways of writing author names (e.g. ‘John Smith’ vs ‘Smith, J’ vs ‘J. Smith’). An alphanumeric mutator will attempt to resolve differences in Unicode characters between articles and a page number mutator will unify differences between the page numbering systems (e.g. ‘356-357’ vs ‘356-7’). Unicode characters can differ across languages therefore the mutator is needed to standardise them, e.g. changing the author names Rolečková or Hammarström to Roleckova or Hammarstrom. A full table of mutators and what they do can be found in the supplementary materials (Supplement 2). These mutators are applied before deduplication and hence the process of applying all mutators will be referred to as pre-processing.
How the Deduplicator algorithm identifies duplicate records
The Deduplicator works over multiple iterations. For each iteration, multiple fields are specified, along with a primary ‘sort’ field which is used for the initial sort. A comparison method is also specified for each iteration (exact match or Jaro-Winkler similarity [13]). The exact match comparison method only marks a field as matching if the two strings of text match exactly. The Jaro-Winkler comparison method on the other hand returns a value between zero and one based on how closely the strings match. The algorithm works as below:
1
Apply pre-processing mutators to records to ensure they are consistently formatted (Supplement 2)
2
For each ‘step’ specified in the algorithm (Supplement 3):
(a)
Sort the list of records based on the specified ‘sort’ field (e.g. “title”)
(b)
Split the records into separate sub-groups based on matching entries for the specified ‘sort’ field (e.g. If “title”, all records with a title of “Automation of Duplicate Record Detection for Systematic Reviews” will be grouped together)
(c)
Calculate the similarity score for every combination of records inside the sub-group
3
Once all ‘steps’ inside the algorithm have been performed, take an average of the similarity scores calculated for each combination of records
4
If two records have an average similarity score greater than a threshold (e.g. 0.01), the two records are marked as duplicates
Using the base algorithm, deduplication algorithms can be defined in configuration files, which specify each iteration, along with what fields should be compared, what field the records should be sorted by and what comparison method to use. The full code for each deduplication method is provided in the supplementary materials (Supplement 3).
As an example, for the ‘balanced’ algorithm, initially the pre-processing is applied. This would include processes such as converting all title characters to lower case, removing all spaces and any non-alpha-numeric characters. Hence the title “Automation of Duplicate Record Detection for Systematic Reviews” would become “automationofduplicaterecorddetectionforsystematicreviews”.
Next, the first ‘step’ of the algorithm specifies the ‘sort’ field as “title”. This means that all records are sorted and then split into subgroups based on matching titles. The ‘fields’ for this step are specified as “title” and “volume”. Because the ‘comparison’ is specified to be “exact”, both the title and volume of the record need to exactly match to give a similarity score of 1. If any of the fields do not exactly match (including one of the fields being missing), then the similarity score will be 0.
The scores are then calculated in the same way for the four other ‘steps’ specified in the ‘balanced’ algorithm. The five scores (which were calculated at each step) are then averaged to give a final similarity score for each combination of records. If the averaged similarity score is greater than 0.01, then the two records are presumed to be duplicates.
The mean similarity score is also used to classify how likely it is that two records are duplicates. A score greater than or equal to 0.9 will put duplicate records in the “Extremely Likely Duplicates” group. A score greater than or equal to 0.7 will put duplicate records in the “Highly Likely Duplicates” group. Any score less than 0.7 but greater than 0.01 will put the duplicates in the “Likely Duplicates” group. These score thresholds are arbitrarily chosen after testing against various duplication scenarios. These scores were found to be ideal for their relative groups, such that the “Extremely Likely Duplicates” and “Highly Likely Duplicates” groups are very unlikely to contain any unique records (false positives).
Further information and the code for the algorithm is available via the IEBH/dedupe-sweep GitHub repository [12].
Evaluation of the Deduplicator
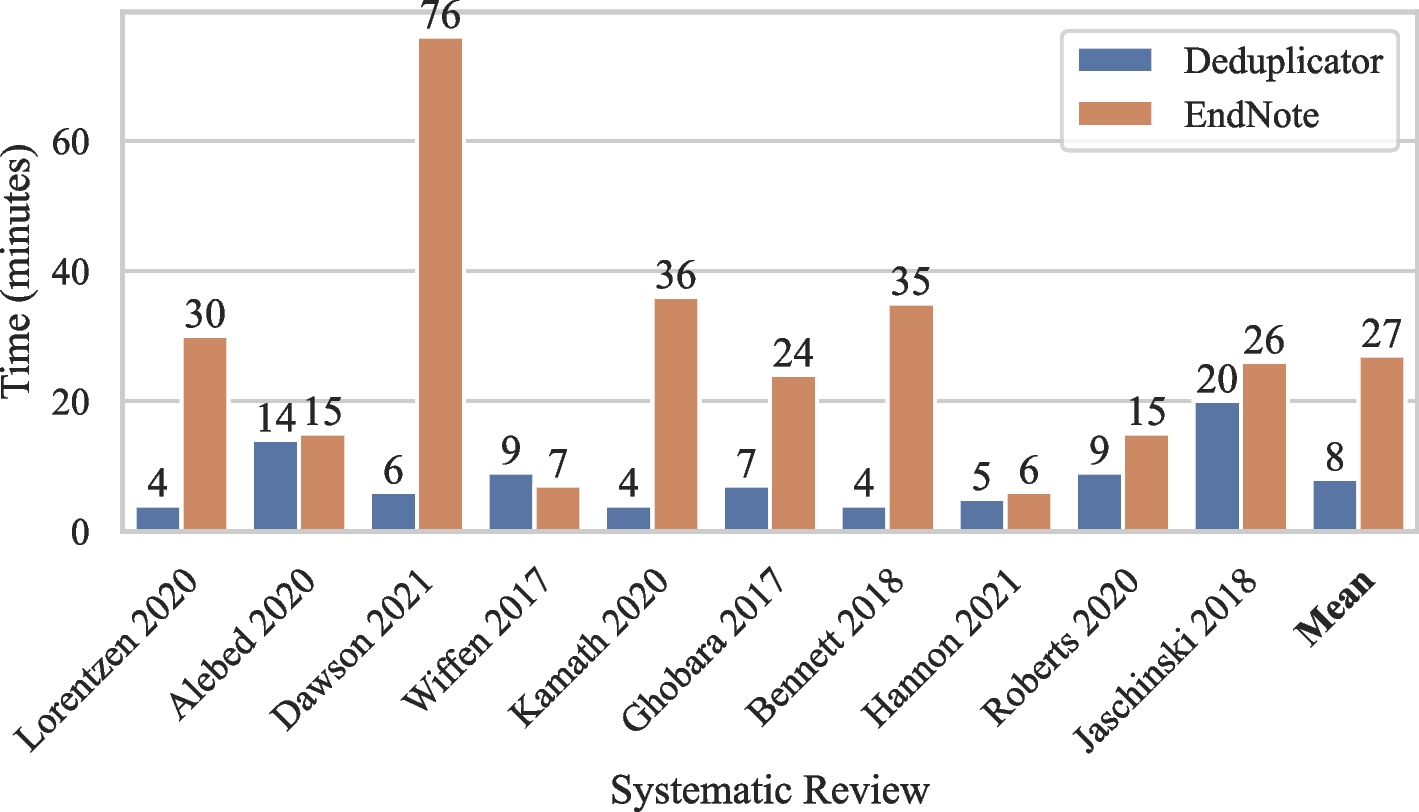
The Deduplicator was evaluated by two screeners (HG and JC) using search results from a set of 10 randomly selected Cochrane reviews. To avoid any confounding from a learning effect, we used a cross-over, paired design where person one would deduplicate the search results using EndNote, while person two would deduplicate using the Deduplicator. They would then switch methods, so person one would deduplicate the next set of search results using the Deduplicator and person two would deduplicate using EndNote. The time taken to deduplicate the search results and the numbers of removed unique studies and missed duplicates were compared.
Definition of a duplicate record
There is currently a lack of an agreed upon definition of what is a duplicate record. For our study we have defined a duplicate as the same article published in the same place, while the same article published in a different place is not a duplicate. An example of this is the PRISMA statement which was published in multiple journals.
These are duplicates:
Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. Moher D, Liberati A, Tetzlaff J, Altman DG; PRISMA Group. J Clin Epidemiol. 2009 Oct;62(10):1006-12. doi: 10.1016/j.jclinepi.2009 .06.005
Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. Moher, D., Liberati, A., Tetzlaff, J., Altman, D. G. (2009). Journal of Clinical Epidemiology, 62(10), 1006-1012. https://doi.org/10.1016/j.jclinepi.2009.06.005
Moher D, Liberati A, Tetzlaff J, Altman DG. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. J Clin Epidemiol. 2009;62(10):1006-1012. doi:10.1016/j.jclinepi.2009.06.005
These are not duplicates:
Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. Moher D, Liberati A, Tetzlaff J, Altman DG; PRISMA Group.Int J Surg. 2010;8(5):336-41. doi: 10.1016/j.ijsu.2010.02.007
Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. Moher D, Liberati A, Tetzlaff J, Altman DG; PRISMA Group.J Clin Epidemiol. 2009 Oct;62(10):1006-12. doi: 10.1016/j.jclinepi.2009 .06.005
Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. Moher D, Liberati A, Tetzlaff J, Altman DG; PRISMA Group.BMJ. 2009 Jul 21;339:b2535. doi: 10.1136/bmj.b2535
Selection of systematic reviews to be deduplicated
To ensure an unbiased sample of search results to be used, we randomly selected 10 Cochrane reviews published in the last 5 years (January 2017–September 2021). To randomly select the systematic reviews, the following search string was run in PubMed; “Cochrane Database Syst Rev[Journal] AND 2017:2021[pdat]”. Then, a random number was generated using the Google random number generator. This number was between one and the total number of search results found (e.g. if 5000 results were found, the random number was set to be between one and 5000). The search result that then corresponded to the random number generated was checked to ensure it meets the inclusion criteria. This continued until 10 Cochrane reviews were identified.
Inclusion criteria of the systematic reviews
To be selected and used in the study, the search strategy in the Cochrane review had to meet the following criteria:
All search strings for all databases needed to be reported in the review
The number of databases searched in the review had to be two or more
The total number of search results found by the combination of all search strings had to be between 500 and 10,000 records
The decision to limit search results to 500 to 10,000 was to reduce variability between samples to be deduplicated and to ensure they were representative of a typical systematic review which have a median size of 1781 records [1].
Obtaining the sample to be deduplicated
After 10 eligible systematic reviews were selected, their searches for all bibliographic databases were run and the results exported and collated in EndNote. No date or language limits were applied, and searches of specialised registers, trial registries and grey literature were excluded.
Deduplication of search results
Two screeners (HG and JC) independently deduplicated 10 sets of search results. HG is a research assistant (now PhD candidate) with 2 years’ experience with systematic reviews but with no experience deduplicating search results. JC is an information specialist with over 15 years’ experience with systematic reviews and deduplicating. HG screened the odd numbered sets of search results using EndNote (1, 3, 5, 7 and 9) then screened the even numbered sets with the Deduplicator (2, 4, 6, 8 and 10). JC screened the even numbered sets with EndNote (2, 4, 6, 8 and 10) and the odd numbered sets with the Deduplicator (1, 3, 5, 7 and 9) (Table 1). EndNote deduplication is defined as using the IEBH EndNote deduplication method (Supplement 1), while Deduplicator is the solution discussed in this paper. In the Deduplicator, the Beta algorithm (referred to as the ‘balanced’ algorithm) was used.
Table 1 Assignment of EndNote vs Deduplicator methods between researchersValidation of deduplication
To identify errors (i.e. a duplicate mistakenly marked as non-duplicate, and vice versa), the screener’s libraries were compared. This was done once all 10 sample sets had been deduplicated. Any discrepancies were manually checked and verified by consensus between two authors (HG and CF). This produced a final “correctly deduplicated” EndNote library for each sample set. This enabled the identification of errors from each screeners’ library, with an incorrectly removed unique article labelled a “false positive”, while a duplicate which was incorrectly missed was labelled as a “false negative”.
Outcomes
We evaluated the Deduplicator by four outcomes:
1
Time required to deduplicate: each screener recorded how long it took to perform deduplication on each library in minutes using a phone timer. The screener started the timer from when the file was first open and stopped the timer when they were satisfied that all duplicates were identified
2
Unique studies removed/False positives: the number of records in the library the screener classified as a duplicate when they were a unique record
3
Duplicates missed/False negatives: the number of records in the library the screener classified as a unique record when it was a duplicate record
4
Total errors: (false positives + false negatives)
Comparison between Deduplicator algorithms
In addition to testing the five development libraries against each Deduplicator algorithm (‘balanced’, ‘focused’ and ‘relaxed’), we also performed an additional head-to-head evaluation between the three Deduplicator algorithms taking a dataset from a previous deduplication study by Rathbone et al. [24]. This dataset contains four sets of search results from studies related to: cytology-screening, haematology, respiratory and stroke. The full breakdown of the dataset is provided in Table 2. All three algorithms were run as is, meaning that there was no manual checking by a human as there was in the EndNote comparison.
Table 2 Breakdown of dataset used for comparison of Deduplicator algorithms [24]Like with the development libraries, accuracy, precision, recall and F1 score were the four measures used for comparison between the Deduplicator algorithms. A high precision score indicates that few unique studies were identified as duplicates. A high recall score indicates that very few duplicate studies were incorrectly classified as unique studies. F1 score is a combination score of both precision and recall. The formula for these measures are presented in Eqs. 2, 3 and 4.


留言 (0)