
記住我




Working memory (WM) is generally defined as a set of memory processes that enable the maintenance of information during concurrent processing of other information [1]. The Time-Based Resource Sharing (TBRS) theory [2] assumes that this is achieved by a rapid switching between processing new stimuli and refreshing already encoded information. According to the theory, any information that is not in the focus of attention suffers from time-based decay. Hence, there is a need for frequent refreshing of to-be-maintained information. Due to the central attentional bottleneck [3], though, attention can be devoted to only one central process at a time. Thus, the sharing of attentional resources between processing and refreshing needs to be time-based [2].
Being a general theory of WM, TBRS is not concerned with expertise. However, other theories of WM such as template theory [4] or long-term WM theory (LT-WM) [5] have conceptualized WM as being inherently influenced by expertise. Experts’ WM has been repeatedly found to be better [6] and this advantage is commonly explained with both the concept of chunking [7,8,9] and the rapid access to long-term memory (LTM) [10, 11]. The main idea of chunking is that experts’ memory system detects known structures in processed stimuli and recodes them as single, meaningful units [12].
Besides these theoretical explanations, there is biological evidence for expertise differences in WM. James and colleagues [13] compared gray matter density between participants of three levels of musical expertise. Their analysis revealed that a higher level of expertise is associated with an increase in gray matter density in areas involved in higher-order cognitive processing, including the left inferior frontal gyrus which is involved in working memory processes.
In the context of the TBRS theory, an account of how central WM processes and chunking change with expertise is lacking. The present work addressed this issue by analyzing expertise differences in WM and chunking in the processing of musical note symbols. To this end, we created a musical complex span task. In complex span tasks, memoranda have to be maintained while a secondary distractor task is performed [14]. In the most classical example, the reading span task, numerous sentences have to be read aloud and the last word of each sentence has to be memorized [15]. Analogously, in the present task, single note symbols were presented for later serial recall. In between the presentation of each of these to-be-remembered notes, participants had to perform a short, unknown, notated melody on an electric piano. Hobby musicians and music students completed this task and its procedure was slightly adapted to match the skill level of the two sub-samples.
To manipulate the possibility for chunking, we varied the meaningfulness of the tonal structure of the sequences of to-be-remembered notes. In meaningful sequences, the to-be-remembered notes formed major triads, which can be considered meaningful units in tonal music. In stimuli that were not meaningful, to-be-remembered notes formed arbitrary trichords, i.e., tonal structures that were at odds with the common rules of tonal music. We generally expected that more musically experienced participants would gain an additional benefit in recalling sequences of major triads.
In addition to identifying the interplay of expertise groups and tonal structure conditions, our goal was to uncover the underlying cognitive mechanisms. One method to pursue this goal was to design a computational model that can perform the same experiment as the participants by expressing the involved cognitive processes within a computational framework. This framework was the TBRS*C computational model [16], which is a model of WM supplemented with a chunking mechanism. The TBRS*C model performed the experimental task and it was analyzed which parameter estimates best reflected expertise differences in the human data. This provided insights how WM processes and chunking might change with expertise.
The TBRS*C Computational ModelTBRS*C [16] uses the same functional core as TBRS*, which was developed by Oberauer and Lewandowsky [17] as a computational implementation of the TBRS verbal theory. TBRS* simulates serial recall in complex span tasks. Because recall is serial in such tasks, associations between items and their position in the sequence have to be built and maintained. For instance, if participants are presented with the items A, B, and C, it is supposed that they have to create associations between item A and position 1, item B and position 2, etc. This is described in TBRS* by a Hebbian learning mechanism which has both a cognitive and a computational modeling basis. The Hebbian learning rule [18] describes the modification of neural network connections as a result of the firing of output neurons [19]. More specifically, if cell assemblies, i.e., networks of interconnected neurons that form a functional unit [20], are activated simultaneously, they become associated. The unsupervised learning in neural networks has been described based on this rule [21, 22].
The specific decay/refresh mechanisms in TBRS also have a neural equivalent. Although WM is generally assumed to be biologically implemented by persistent spiking activity, another line of research considers that WM can be explained by short-term synaptic plasticity mediated by increased residual calcium levels [23]. In this kind of model, memory maintenance is directly achieved through short-term synaptic facilitation. However, this facilitation decays over time [24].
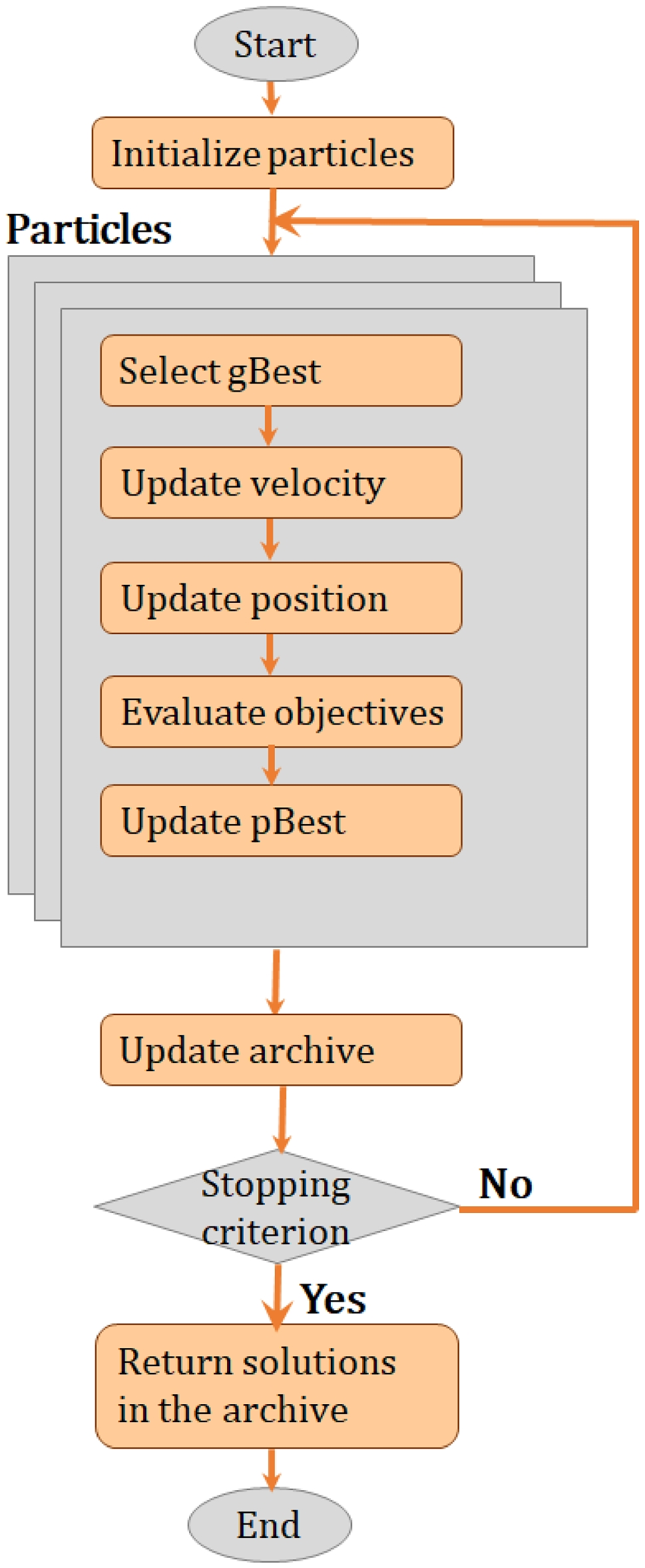
In line with these explanations, TBRS* stores associations between items and positions in a network with two fully interconnected layers, i.e., a position layer and an item layer. Each item is represented by a node in the item layer that is connected with a set of position markers in the position layer. Adjacent positions share a certain proportion P (30% by default) of these markers in order to represent the fact that people are more likely to confound a position with the previous or the next one, but less likely with others. TBRS* reproduces the basic operations of a complex span task, namely encoding, refreshing, distractor processing, and recall. Following the assumptions of the underlying TBRS model, only one of these processes can be performed at a time and all items that are not in the focus of attention suffer from time-based decay. Figure 1 presents the architecture that is the basis of TBRS*.
Fig. 1
Model architecture of TBRS*. Upper panel: Simulated time course of a complex span task in which items J, N, H, and F are encoded (light gray areas). Two distractors are processed in between each encoded item (dark gray areas). Free time (white areas) is used to refresh items. Curves represent the total activation value of each item with respect to its position. Lower panel: Connections between position and item units. Each item is represented by a single unit. Each position is represented by several units. Black and white squares represent position coding. For instance, position 1 is coded by units 3, 6, 8, 12, and 13. Positions 1 and 2 share units 3 and 8. Examples of specific processes: (i) item J is encoded and associated with all units of position 1; (ii) item N is encoded and associated with all units of position 2; (iii) all activation values decay during distracting tasks; (iv) during free time, items are retrieved and refreshed for each position in turn; (v) during free time following the second distractor after item H was presented, item H was erroneously retrieved at position 2, instead of N. Then, H was associated with all units of position 2. Figure reproduced from Lemaire and Portrat [25]
Table 1 provides an overview of the parameters of the computational model. These parameters will now be explained in detail. Encoding of items is performed by a Hebbian mechanism that strengthens the association between the item node and the markers representing its position. Basically, each connection weight wip between an item i and a position unit p is increased by ∆wip = η.(L-wip) where L is an asymptotic value set to 1/9 because there are 9 position markers coding each position. This way, the total strength of the item-position association that can be reached during encoding is bound to 1. The rate of increase of the association strength is defined as η = 1—e−Rt, i.e., it follows an exponential curve. It is influenced by the time during which the association is strengthened (t) and the parameter R. With increasing R, the association strength increases faster and hence, the maximum is reached more rapidly. So, R affects the time that is needed to encode a memorandum. For example, with the default value R = 6 and a duration of t = 0.5 s, the strength of the association between an item being encoded and its position is η = 0.95 which represents 95% of the maximum value. Actually, to model some variability, it is not the value R which is used but rather the outcome of a random draw from a normal distribution centered at R, with a standard deviation of s (1 by default).
Table 1 Parameters of the TBRS*C computational modelRefreshing in TBRS* occurs during any free time, usually right after encoding items or processing distractors. During refreshing, previous positions are considered in turn and for each one, an item is retrieved and the association with its position markers is strengthened, using the same mechanism as during the initial encoding of an item, presented previously, except that the duration is much shorter. As the duration of refreshing Tr is fixed (80 ms by default), though, a larger R does not result in more rapid refreshing, but in a larger activation reached during refreshing.
Retrieval at a given position is performed by selecting the item whose sum of association strengths to the respective position markers is maximal. To mimic retrieval errors, zero-centered Gaussian noise with standard deviation σ (0.02 by default) is added to each sum of activation strengths. More precisely, the selected item is defined by argmaxi(∑p wip + noise) where noise ~ N(0, σ) and wip is the association weight between item i and position p. However, if that best value is lower than a retrieval threshold ϴ (0.05 by default), no item is recalled as if it was forgotten.
Distractor processing is not simulated per se, but its effect is reproduced by applying a decay function to the item-position associations during processing of distractors. The Ta parameter indicates the time used for the attentional capture of a distractor. During that time, all association weights w decay and become wnew = w.e−D.Ta, where D is a decay parameter usually set to 0.5.
Recall in the model involves the retrieval and output of the most activated item associated with the markers representing a given position, following the mechanism presented previously. Once an item i is recalled, its associations with the current position p are suppressed by Hebbian anti-learning (∆wip = − ηL) in order to minimize repetition of the same item at a subsequent position. Further details of TBRS* mechanisms and parameters are described in the seminal article [17] or in derived models [26].
TBRS*C [16] extended TBRS* with a chunking mechanism which accounts for the fact that humans may recode known sequences of items as single units to increase recall performance. TBRS*C assumes that there is a period right after encoding an item during which long-term memory is searched for the previous sequence of items. If a chunk is successfully recognized, the items are chained and the known group is associated with the position of the first item in the sequence. This is advantageous, as fewer elements need to be refreshed. So, chunking in TBRS*C denotes a process of searching LTM for sequences of encoded items and recoding them; a chunk denotes a known sequence of items in LTM.
For instance, if the letter sequence X-P-D would be presented, the model would search for XPD in LTM and would not recognize a chunk. However, if the next letter would be F, the model would recognize the chunk PDF and would associate it with the position of the first letter of the acronym. Consequently, only one unit (PDF) would have to be refreshed in position two instead of three letters in positions two, three, and four. To search a known sequence in LTM, all its constitutive elements need to be simultaneously present within the focus of attention. Thus, as opposed to TBRS*, TBRS*C has an attentional focus size of up to four elements [27] meaning that up to four items are refreshed in parallel during each refreshing period. The duration Tr is not modified, but the strength is divided by the number of items N that is considered: ∆wip = η.(L-wip)/N. Items are thus refreshed in groups of 4 instead of individually, but the strength of refreshing is 4 times weaker. Actually, N is not always 4 because at the beginning of the task, there are less than 4 items to be refreshed.
Chunking is implemented in the model by two parameters, namely the time invested in searching for known sequences (chunk search duration, cSD) and the likelihood of recognizing an item as a chunk, given it exists in LTM (probability of chunk retrieval, PCR). Both parameters are separate and independent. With reference to the architecture presented previously, cSD represents an additional amount of time right after encoding an item, during which there is no refresh and all association weights decay, exactly like during the attentional capture of a distractor. PCR, however, does not change the time course of processes in the model as it only controls the probability of recognizing the previous sequence of encoded items as a chunk.
In the initial study on TBRS*C, Portrat and colleagues [16] employed a complex span task in which seven letters were presented as memoranda. Between the presentation of memoranda, participants had to complete spatial judgment tasks. Known letter sequences, namely French three-letter acronyms, were either absent or present, starting at the first, third, or fifth serial position. Participants’ recall data was simulated with TBRS*C leading to the conclusion that chunking is “an attentional time-based mechanism that certainly enhances WM performance but also competes with other processes at hand in WM” [16, p. 430].
Expertise Differences in Working Memory FunctioningIn the present work, we assumed two expert advantages in WM functioning, namely chunking and rapid access to LTM. These advantages are assumed by other theories of WM, such as LT-WM [5] and template theory [4]. In addition, they are biologically founded on long-term neural plasticity. When someone practices to become an expert, Hebbian learning takes place [20]. As a consequence, functional units of neurons (so-called cell assemblies) form new associations, thereby creating chunks. For example, if the notes C-E-G are repeatedly activated together with the verbal label “C major,” the notes and the label form a functional unit through Hebbian learning. Rapid access to LTM, however, is based on another mechanism: nerve myelination. Myelin is found in the brain’s white matter. It is a white, fatty tissue that encloses axons and increases the speed of the passing nerve impulses [28]. Myelination is a process that persists for the first three decades of human development and is affected by experience [29]. Specifically, piano practice in certain critical developmental periods was found to be associated with plasticity in myelinating tracts [30]. As a consequence of musical training, myelin cells around nerve fibers have been found to increase in size, contributing to the velocity of electrical impulses [13].
Based on these biological mechanisms, the present study sought to unravel expertise differences in WM functioning in greater detail. To this end, we collected data from a complex span task with musical notation. To ensure variation in musical expertise, the task was completed by two sub-samples, namely music students and hobby musicians. The complex span task required the performance of notated melodies at first sight, which is highly demanding for hobby musicians. Thus, the task procedure was slightly adapted to match hobby musicians’ skill level. Using a median split on the general musical sophistication scale of the Gold Musical Sophistication Index [31], both sub-samples were split up in a higher-expertise and a lower-expertise group (threshold for hobby musicians: 69.5; threshold for music students: 85.5).
The complex span task was additionally performed by the TBRS*C computational model. Separately for both sub-samples, we analyzed which parameter values best reflected the differences in task performance between the higher-expertise and the lower-expertise group. The parameters for this analysis were chosen based on the expected expertise differences in WM: the parameters cSD and R were chosen to investigate experts’ rapid access to LTM; the parameter PCR was chosen to investigate experts’ chunking processes. In addition, we were interested if changes in WM and chunking processes would be associated with changes in the way resources were shared between the two task components. We wondered if the same amount of time would be used for the processing of distractors despite changes in the timing of encoding and chunking. Thus, we explored expertise differences in the parameter that represents the time used for the processing of distractors (Ta). In the analysis, we checked which combination of values for these four parameters (cSD, R, PCR, Ta) would provide the best fit to expertise differences in the human data. Due to the difference in the experimental procedure, music students and hobby musicians were not directly contrasted, but higher-expertise hobby musicians were compared to lower-expertise hobby musicians and higher-expertise music students were compared to lower-expertise music students.
留言 (0)