
記住我




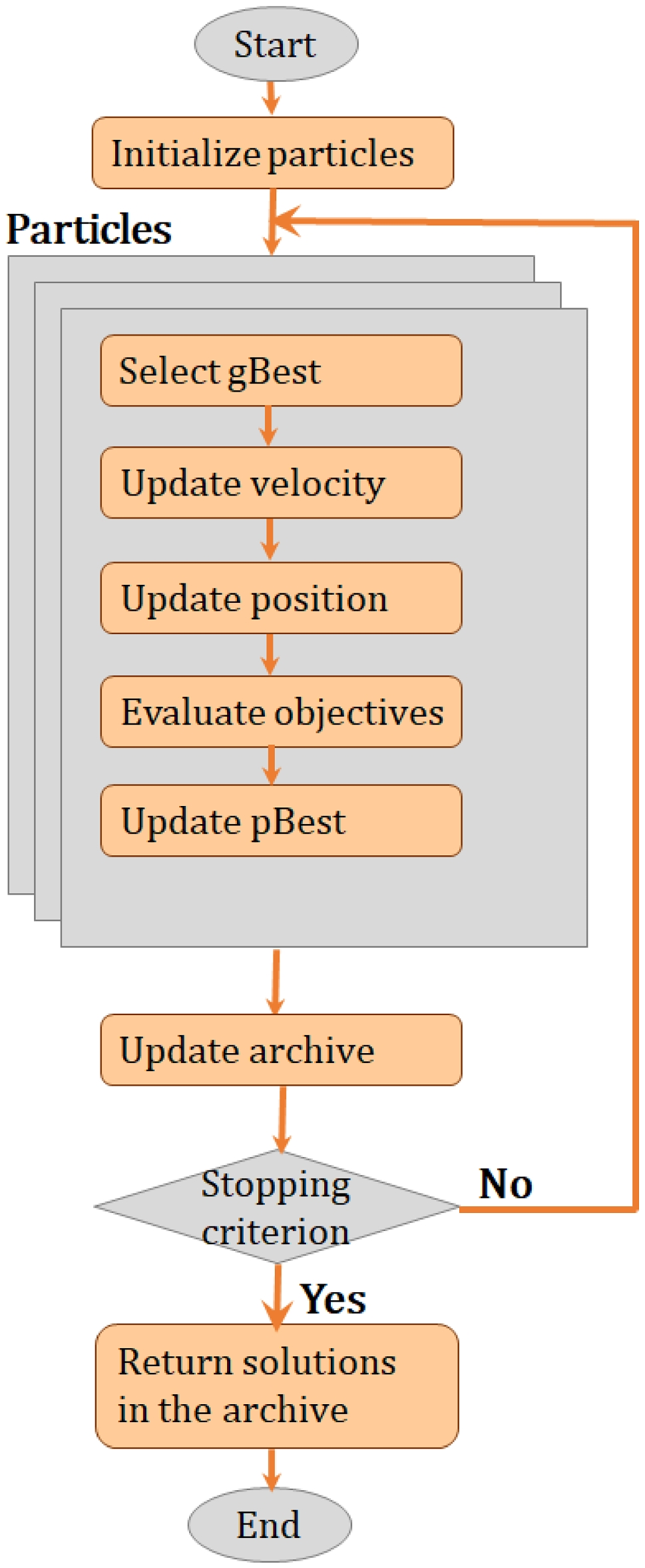
This section presents the quantitative and qualitative evaluation results for each step of our approach in this study. We analyze the performance of the above-mentioned models and ensemble techniques on the DFUC2020 dataset. After that, we validate the results by inferencing on the IEEE DataPort Diabetic Foot Dataset. A discussion of the performance of each model is given in the first subsection, followed by an analysis of how they perform after ensembling. In the “Overlapping bounding box reduction” section, the proposed overlapping bounding box reduction technique is demonstrated to improve the results.
Individual Model PerformanceWe investigated different variations of YOLOv5, YOLOv7, and YOLOv8 models, and the Faster R-CNN ResNet101 and EfficientDet-D1. Pretrained weights from the MS COCO dataset were used to develop the models on the training set and the hyperparameters were tuned on the validation set. The loss and mAP curves are provided in the supplementary materials and the models’ quantitative performances are presented in Table 1.
Table 1 Single model performance on test setTable 1 shows that YOLOv8x, which is the extra-large version of YOLOv8, gave both the highest mAP@0.5 score of 0.856 and the highest F1 score of 0.811. The YOLOv8x model outperforms all other YOLO models, as well as FRCNN-ResNet101 and EfficientDet-D1. Among the non-YOLO models, FRCNN-ResNet101 performed better than EfficientDet-D1 in terms of both F1 score and mAP. YOLOv8m’s optimal trade-off between inference time and mAP demonstrates the most practical applicability in terms of medical context, where timely and efficient diagnosis is pivotal for taking faster decision-making and enhancing healthcare. It also had a significantly lower total parameter count compared to the other similar performing models making it resource-efficient without compromising on robustness. As shown in Fig. 7, predictions and ground truth are provided for a sample test image so that qualitative results can be visualized. From the figure, it can be observed that while FRCNN-ResNet101 and other YOLO variants accurately detected the two regions identified in the ground truth, YOLOv5x identified an additional third region causing a false-positive prediction. Regarding the bounding box area, models such as YOLOv7x, YOLOv8m, and YOLOv8x demonstrated high precision, aligning most closely with the ground truth. However, FRCNN-Resnet101 predicted the top left ulcer point with a much larger bounding box. These types of predictions may be attributed to the model’s lower mAP score, as the lower IoU overlap threshold of less than 0.5 leads to the exclusion of such predictions, despite the model’s ability to accurately detect the affected area.
Fig. 7
Sample test image using best individual models. a Ground truth, b YOLOv5x, c YOLOv7x, d F-RCNN Resnet101, e YOLOv8m, and f YOLOv8x
In the context of healthcare, especially when diagnosing conditions such as ulcers using deep learning models like YOLOv8m, explainability is crucial. Saliency maps generated for the model using Gradient-weighted Class Activation Mapping (GradCAM) are shown in Fig. 8. The reddish hues on the map indicate regions that positively contribute to the model’s detection of the ulcer point in the image, while bluish tones suggest areas that are less influential to the detection outcome. The saliency maps in Fig. 8 reveal the model’s highly centered attention in the ulcerated region, which is indicative of its ability to precisely pinpoint ulcer locations. Despite the presence of highlighted regions beyond the ulcer area, their effect on the model’s results is minimal and does not detract from the overall accuracy of ulcer identification.
Fig. 8
YOLOv8 GradCAM saliency map visualization
Model Ensemble PerformanceApart from the YOLO models, FRCNN-ResNet101 achieved higher accuracy in DFU detection compared to EfficientDet-D1. To develop an ensemble model for DFU prediction, we combined the FRCNN-ResNet101 model with the top three performing YOLO models (YOLOv7x, YOLOv8m, and YOLOv8x) to investigate the performance of DFU prediction. The predictions were combined using three different ensemble techniques (NMS, Soft-NMS, and WBF). The IoU threshold of 0.5 was chosen to determine detections for all the methods. Bounding boxes with less than 0.001 confidence score were eliminated. A low Sigma value of 0.1 was chosen for Soft-NMS. According to Eq. 8, a lower sigma value highly suppresses the confidence scores of the overlapping bounding boxes without completely eliminating them. Before applying Soft-NMS and WBF, weight values of 1.5 and 1 were used for the YOLO-based models and FRCNN-ResNet101, respectively. This bias was implemented as the YOLO-based models surpass FRCNN ResNet101 in individual performance in most cases, which is evident from Table 1 and Supplementary Fig. 1. The quantitative performance after ensemble is presented in Table 2.
Table 2 Different ensemble method performances on test setAs a result of using the NMS ensemble technique to combine predictions, in most cases, mAP is modestly higher than in the individual models. However, YOLO8x is slightly lower. Meanwhile, Soft-NMS performs poorly across all models, since it significantly lowers both mAP and F1 scores, with the exception of YOLOv7 and YOLOv7x, where it increases the mAP score from 0.824 to 0.829 and from 0.823 to 0.826, respectively. Other than the YOLOv8x model, where a slight decrease in mAP score can be observed, WBF provided the most excellent results, significantly improving mAP while minimally impacting the F1 score. Combining predictions from YOLOv8m and FRCNN-Resnet101, this technique achieves the highest mAP score of 0.864, which represents a significant improvement over both of their individual performances and surpasses the current leaderboard of the DFUC2020 challenge by 12.4% [52]. For the remaining experiments, only predictions based on the WBF approach have been considered for YOLOv8m and FRCNN-ResNet101 (Table 3).
Table 3 Individual model performance on the test setFigure 9 shows a qualitative comparison between the ensemble outputs and the two fundamental models. Comparing the individual model performances to the results obtained through ensemble, it is evident that the ensembled results are significantly better. It can, for example, compensate for the fact that one of the models misses an ulcer point, as depicted in the figure. Even though all the ensembling techniques provide comparable qualitative results in detecting the DFU-affected areas in the ground truth almost perfectly, the WBF method is the most confident in detecting the regions.
Fig. 9
Sample test image prediction with ensemble techniques. a Ground truth, b YOLOv8m, c F-RCNN Resnet101, d NMS, e Soft-NMS, and f WBF
Overlapping Bounding Box ReductionThe most reliable results obtained using the WBF ensemble on YOLOv8m and FRCNN ResNet101 are shown in Table 2. However, the ensemble method introduces multiple detections or overlapping detections for some images. To address this problem, we employed an overlapping bounding box reduction technique prioritizing the larger detection area. We removed any smaller bounding boxes that have an area-to-overlap with other bounding boxes with an intersection ratio greater than 0.8. The results are depicted side-by-side in Fig. 10. The figure shows how smaller bounding boxes can appear inside larger bounding boxes detecting the same DFU-affected area and how overlapping bounding box reduction can be applied to this problem.
Fig. 10
Qualitative result improvement after overlap reduction
External ValidationWe validated our proposed DFU detection system using IEEE DataPort Diabetic Foot datasets to predict foot ulcers. The visual clarity of the DFUC2020 dataset surpassed that of the IEEE DataPort dataset, where many ulcer points were either out of focus or positioned at the edge of the foot. Sometimes the view of the foot is obstructed by the L-shaped scale. So, the model failed to predict some true positives from the suboptimal images within the IEEE DataPort’s dataset. In addition, there were different background objects on the IEEE Dataport’s dataset which led the model to make some false prediction. To tackle this issue, we cropped some overly prevalent background elements from the images of foot ulcers in the IEEE DataPort database to reduce the false positive detections owing to the presence of irrelevant objects in the image. The above proposition was effective for most of the images in the validation dataset. The prediction results for the dataset are shown in Fig. 11 in which we can see that for the first four images, our method predicts ulcer areas almost accurately, but for the last two images (Fig. 11e, f), it failed to identify the ulcer area. In these last two images, the ulcer points are not clearly visible because they are out of focus. As the original dataset used in this study did not have such poor-quality images, where the DFU-affected areas were blurry, this kind of result is to be expected.
Fig. 11
Prediction on the external dataset
Ablation StudyThis section presents the ablation study for evaluating the performance of various deep learning models on the validation set, with a focus on understanding the nuances of their architectures and the effectiveness of ensemble techniques in diabetic foot ulcer (DFU) detection.
Individual Network PerformanceOur study categorized the evaluated models into two groups based on their network architectures: YOLO-based models and other models. Table 3 reveals that the newer architectures like YOLOv8 performed better than earlier versions like YOLOv5. One of the key reasons was that the output heads in YOLOv8, which serve as the last layers of the neural network, have been simplified in comparison to earlier iterations such as YOLOv5. YOLOv8 employs a solitary output head, in contrast to the three heads present in YOLOv5, and utilizes an anchor-free detection technique, unlike YOLOv5, which relies on an anchor-based strategy. This approach directly predicts the center of the object, reducing the number of bounding boxes and thereby increasing the efficiency of the post-processing stage. Additionally, YOLOv8 integrates Feature Pyramid Network (FPN) and Path Aggregation Network (PAN) modules, aiding in producing multi-scale feature maps and combining features from different levels of the network, respectively. These modifications in YOLOv8’s backbone architecture streamline information flow within the network and enhance the efficiency and effectiveness of object detection tasks [53].
YOLO-Based Model EnsembleSince the YOLO-based models performed better than the other architectures, we have presented the combination of different YOLO models using the WBF module. Analysis with the other modules is discussed at a later section. Our results in Table 4 indicate that the ensemble performance did not significantly exceed the performance of individual models. This finding suggests that while YOLO models are individually robust, their similarities in architectural design and detection approach lead to a convergence in their detection capabilities. As a result, the ensemble models tend to reinforce the same strengths and weaknesses, rather than complementing and compensating for each other’s limitations.
Table 4 Ensemble of YOLO-based models performanceEnsemble of Different Architecture ModelsContrasting with the YOLO-based model ensemble, combining YOLO models with different architectures yielded more promising results. This approach leverages the complementary strengths of different detection algorithms, potentially addressing the limitations of a single-model approach. From Table 5, we see that the combination of YOLO models with FRCNN-ResNet101 mostly resulted in improved performance, with the combination of YOLOv8m and FRCNN-ResNet101 emerging as the most successful ensemble, yielding the best result in terms of mAP. This can be due to FRCNN’s approach to object detection, which includes selective search and the use of a Region Proposal Network (RPN). This enhances its ability to detect objects more accurately compared to other models, which when combined, compliments YOLO’s efficient architecture improving overall performance in different scenarios [54]. FRCNN-ResNet101’s two-stage approach comprising of first feature extraction and then doing region proposal enhances the accuracy of detection on some complex scenarios compared to YOLO’s single-stage approach [55]. However, the combination with EfficientDet-D1, which had the lowest performance among the individual models, did not yield significant improvements. This could be due to EfficientDet-D1’s limitations not being effectively addressed by the YOLO models’ capabilities as both are single-stage detectors.
Table 5 Ensemble of different architecture model performancePrecision Recall TradeoffThe study also examined different confidence score thresholds to determine the optimal balance between precision and recall and select the best ensemble technique. As thresholds increased, the number of detections decreased, leading to a reduction in false positives but an increase in false negatives. Consequently, recall diminished as precision improved. Figure 12 illustrates this precision-recall tradeoff for various ensemble techniques at various confidence thresholds. The NMS and Soft-NMS showed a drastic drop in recall after the 0.55 threshold, while the WBF method demonstrated a more proportional trade-off. This is mostly because NMS removes the additional bounding boxes with lower confidence values that cross the IoU threshold for each detection. As a result, it showed higher precision in the first half compared to the Soft-NMS approach. Soft-NMS reduces the confidence scores of additional bounding boxes rather than fully eliminating them, resulting in increased recall in the first half. However, recall dropped drastically in the second half for both methods. WBF method on the other hand does not eliminate or reduce additional bounding boxes, but instead computes a weighted average based on the confidence scores. This resulted in a more gradual decline in recall maintaining a smoother trade-off across the whole confidence range, making WBF a robust option compared to NMS and Soft-NMS techniques. Based on the precision-recall trade-off graph, we chose 0.1 confidence threshold in this study as the optimal confidence score maximizing both precision and recall for the ensemble technique.
Fig. 12
Precision recall trade-off for different ensembling methods
Overall, this ablation study reveals that the best YOLO models ensembled with FRCNN-ResNet101 using the WBF technique provide the best results for DFU detection. It also highlights the importance of considering architectural differences of combining models to enhance diagnostic accuracy.
留言 (0)