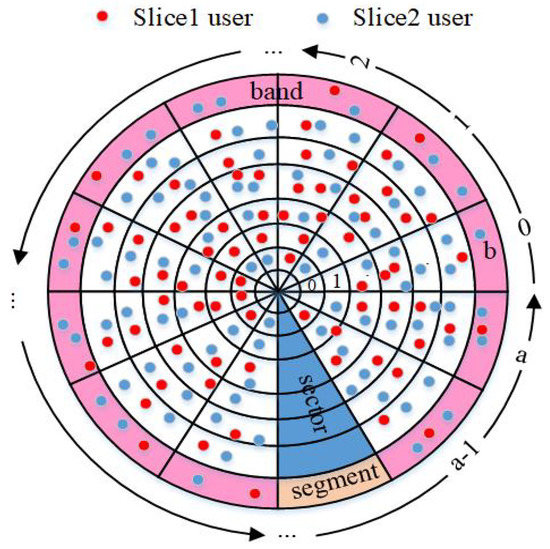
1. IntroductionNetwork slicing, in which the network infrastructure is separated into several virtual sub-networks, is a critical technology for 5G networks. Each slice can provide a specific slice service such as end-to-end low latency, high bandwidth, and massive device access [
1]. The spectrum resource can be adjusted and optimized based on different service requirements by separating it into several slices in RAN. However, there are some challenges to allocate resource efficiently for limited spectrum resources. Among them, one important issue is the lack of real-time intelligence agents to effectively deal with unstable resource supply and demand and lack of real-time technologies to accurately track and analyze resource allocation and usage. Once slice users cannot obtain the minimum resources they need due to unreasonable resource allocation, they will not be able to realize the corresponding services. This is made even more difficult in fifth-generation (5G) cellular networks because end-users want larger data rates and lower end-to-end latency [
2]. In this paper, we research the inter-slice bandwidth allocation in RAN to maximize the qualified user ratio (QUR), which obtained enough to meet its quality of service (QoS).Luis Guijarro et al. [
3] allocated a weight to each cell to enable operators to share resources. The weight denoted the proportion of resources that each network slice user can obtain in each cell to maximize the number of subscribers. It provided accurate approximation when the cells were heterogeneous and exact values for the Nash equilibrium. Liu et al. [
4] proposed a two-level allocation to maximize a no close-form utility. They first learned how many resources were needed by users in each slice to fulfill their QoS requirements and then optimize the resource allocations. They take inter-slice resource allocation as the master optimal problem and suggested a convex optimization approach for it. The deep deterministic policy gradient method (DDPG) for learning the allocation policy intra-slice as the slave optimal problem. Deep reinforcement learning (DRL) was introduced by Wang et al. [
5] to dynamically allocate resources between several slices. The goal is to maximize resource usage while maintaining a high quality of service. It outperforms heuristics, best efforts, and random methods. Sun et al. [
6] reserve a portion of the radio resource in the BS, and then utilize DRL to change the resources in each slice autonomously in terms of resource consumption and satisfaction of the slices. Akgul et al. [
7] proposed a negotiated spectrum resource sharing agreement between operators and infrastructure providers to improve spectral efficiency. To allocate resources across eMBB and URLLC slices, Feng et al. [
8] proposed a two-timescale technique based on the Lyapunov optimization. It performed similarly to the exhaustive searching algorithm (the optimal solution). To achieve a trade-off between slice performances, Sun et al. [
9] employed the Stackelberg game to distribute subchannels for local radio resource managers (LRRMs) within slices. They analyzed the service performance of power consumption and user satisfaction. The low-complexity methods perform similarly to exhaustive search and greatly outperform other benchmarks. Yang et al. [
10] proposed using a game theoretic approach to allocate resource. Yang et al. [
11] proposed using a genetic algorithm (GA) to determine the most suitable slice boundary to achieve the optimal inter-slice resource management. To deal with co-channel interference, Yang et al. [
12] proposed a connection admission control (CAC) mechanism to achieve effective isolation for network slicing.
In conclusion, most optimization algorithms have not maximized the QUR in the case of a limited spectrum, and only obtained a performance similar to an exhaustive search. We research the slice bandwidth ratio prediction based on a case library, which stores a massive number of cases by an exhaustive search method that can find the optimal solution to maximize the QUR. It can realize very low prediction errors and run costs.
In summary, the key contributions of this paper are summarized as follows:
To reduce the computational complexity and determine the optimal slice ratio (the proportion of bandwidth occupied by slices), we built a case library to store the user distribution scenario and the optimal slice ratio produced by exhaustive searching.
We have considered the QUR, which is to optimize the slice service.
The CBR framework is proposed to form a complete system. The predicted error is reduced by revising and retaining consistancy.
The KNN algorithm is proposed to determine the optimal slice bandwidth ratio for the new case based on the database. To reduce the prediction error and run cost, the sparsity reduction method, which joined the least square, spare learning, and locality-preserving projection, is utilized to optimize the k value. We defined it as optimizing KNN (O-KNN).
The rest of the paper is structured as follows.
Section 2 presents the system model and details the related components of the system architecture.
Section 3 presents related intelligent techniques required to build the proposed approach.
Section 4 presents and analyzes the results of the O-KNN in predicting the slice ratio for resource allocation.
Section 5 presents the conclusion and scope for future work. 3. Problem FormulationO-KNN is used to predict the slice ratio. The similarity between the query case and the library cases is first calculated, and then a search is made of the nearest k neighbors. The k value is determined by the reconstruct process between the test sample and training sample. We use the training sample to reconstruct each test sample by least squares, spare learning, and locality preserving projections. Finally, the solutions are predicted by weighting the distance of the k-nearest neighbors. The flowchart of the O-KNN method is shown in
Figure 3.To test the CBR approach, we used query cases from the test data where we had already used an exhaustive search to determine the optimum slice ratios. We compared the test case with the attributes in the case library using Euclidean distance. To speed up the retrieval, brute force [
16] was applied. Investigating a faster search structure would form part of future work using the approach here as a benchmark.Each case in the library is an d-dimensional space and the Euclidean distance between the query case (q) and each library case (ci) represents the similarity and can be expressed as:By calculating this, we can find the set of k nearest neighbors, i.e., those with the smallest value of di. Each of those k neighbors has a value for the slice ratio and the KNN approach [
17] takes these k values of distance and output (slice ratio) to predict the value of w for the query case, which we denote as wq. This prediction is generally conducted by using a weighted combination [
18] of the outputs with the weighting depending on distance. The α(•) is the weight function and is shown in
Table 2.
ωq=∑i=1kαdi×ωi∑i=1kαdi
(4)
The k value metrics and distance metrics used in KNN algorithms have an impact on their performance. Using a set k value for all query cases is not feasible [
19] as is using the time-consuming cross-validation approach [
13] to obtain the k value for each query case. The k value should be different and should be learned from the data. The selection of an optimal k value for each query case as the nearest neighbor to conduct KNN by sparse learning, and locality preserving projections have shown to be highly effective [
20,
21].The case library is denoted as a matrix X∈Rn×d, where n and d, respectively, denote the quantity of practice samples and attributes. X=[xij], its i-th row and j-th column are denoted as xi and xj, respectively. Y∈Rd×m denotes the transpose matrix of the query cases, where m denotes the number of query case. In this paper, we propose to reconstructed query case Y using case library X, with the purpose of minimizing the distance between XTwi and yi. The reconstruction coefficient or correlation between the case library and query cases is denoted by W∈Rn×m. To get the smallest reconstruction error, we use a least square loss function [
22] as follows:
minW∑i=1m||XTwi−yi||22=minW||XTW−Y||F2
(5)
||X||F2=∑ixi221/2 is the Frobenius norms of X. In this paper, we employ the following sparse objective function:
minW||XTW−Y||F2+ρ1||W||1W≽0
(6)
where ||W||1 is an l1–norm regularization term [
23] to generate the sparse reconstruction coefficient, and W≽0 means that each element of W is nonnegative. The larger the value of ρ1, the more sparse is W.To make sure that the k-closest neighbors of the original data are kept in the new space after dimensional reduction, we impose the locality preserving projections (LPP) regularization term between the case library and themselves [
24]. The case library X∈Rn×d is mapped to Y∈Rd×m, a projection matrix is W∈Rn×m, and yj=XTwj. As a result, LPP’s objective function is as follows:
minY=XTW12∑i,jdsij||yi−yj||22=minWtrWTXLXTW
(7)
Let sij denote the attribute similarity matrix. S=[sij]∈Rd×d, which encodes the relationships between attributes. Let G denote a graph with d attributes. If nodes i and j are connected, we put sij=e−||xi−xj||22σ, (σ is a tuning parameter constant). We use an adjacency matrix S to denote the attribute correlations graph. D is a diagonal matrix whose entries are column (or row, since S is symmetric) sums of S, Dii=∑j=1dsij. L∈Rd×d, L=D−S is the Laplacian matrix [
25]. The proof is shown in
Appendix A.Finally, the objective function for the reconstruction process can be defined as follows:
fW=minW(||XTW−Y||F2+ρ1||W||1+ρ2trWTXLXTW,W≽0
(8)
tr(•) is the trace operator. We let Equation (
8) take the first derivative with respect to Wk, and then make it equal to 0 using the accelerated proximal gradient approach. The minf(W)=s(W)+r(W). s(W) is convex and differentiable as follows:
sW=minW(||XTW−Y||F2+ρ2trWTXLXTW
(9)
rW=ρ1||W||1 is an l1-norm regularization term [
26]. Further let S(W)=s(W)1+ρ2s(W)2.
s(W)1=‖XTW−Y‖F2=(XTW−Y)T(XTW−Y)=WTXXTW−WTXY−YTXTW+YTY
(10)
According to the Derivative properties of matrices ∂XTAX∂X=A+ATX, ∂ATX∂X=∂XTA∂X=A, we set A=XXT, and X=W. So we can obtained the following:
∂(WTXXTW)∂W=(XXT+XXT)W=2XXTW
(11)
set A=XY and X=W
∂(WTXY)∂W=∂(YTXTW)∂W=XY
(12)
So
∂s(W)1∂W=2XXTW−2XY
(13)
As s(W)2=minWtr(WTXLXTW), according to the derivative formula of matrix trace ∂trWTAW∂W=A+ATW let A=XLXT. Therefore,
∂sW2∂W=XLXT+XLTXTW=2XLXTW
(14)
wherein, L is a symmetric matrix, so L=LT.
∂s(W)∂W=2XXTW−2XY+2ρ2XLXTW=2XXT+ρ2XLXTW−2XY
(15)
Gradient descent is performed on the smooth term to obtain an intermediate result.
Wk+12=Wk−α∗∇s(Wk)
(16)
where α is the learning rate. So
Wk+12=Wk−2αXTX+p2XLXTWk+2αXY
(17)
Then the intermediate result is substituted into the non-smooth term to obtain the projection of its adjacent points, that is, to complete an iteration.
Let
vW=p1W1+12αW−Wk+122
(19)
∂vW∂W=1αW−Wk+12+p1sgnW
(20)
For the derivatives of the ρ1||W||1, soft thresholding [
27] is used. Then, we update the W as follows:
Wk+1=softWk+12,αp1=signWk+12maxWk+12−αp1,0
(21)
Wk+1=
Table 2.
Weight functions.
Table 2.
Weight functions.
Weight FunctionsFormulainverse distanceαd=1/dquadratic kernelαd=1−d2,ifd<10,otherwisetricube kernelαd=1−d33,ifd<10,otherwisevariant of the triangular kernelαd=1−dd,ifd<10,otherwise
Table 3.
Simulation configuration.
Table 3.
Simulation configuration.
ParameterValueCell radius1 kmCell number7Modulation formatOFDMNumber of slices2Cell bandwidth10 MHZNumber of users200Antenna height75 mCarrier frequency2 GHzSubcarrier spacing15 kHzTransmit power23 dBmShadow fadinglog-normalPath lossCOST231-HataRequired bitrate of S1 users1 MbpsRequired bitrate of S2 users2 MbpsUser distributionUniformNo. of cases in libraryUp to 10,000No. of test (query) cases300
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (
https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yan, D.; Yang, X.; Cuthbert, L. Resource Allocation for Network Slicing in RAN Using Case-Based Reasoning. Appl. Sci. 2023, 13, 448.
https://doi.org/10.3390/app13010448
AMA Style
Yan D, Yang X, Cuthbert L. Resource Allocation for Network Slicing in RAN Using Case-Based Reasoning. Applied Sciences. 2023; 13(1):448.
https://doi.org/10.3390/app13010448
Chicago/Turabian Style
Yan, Dandan, Xu Yang, and Laurie Cuthbert. 2023. "Resource Allocation for Network Slicing in RAN Using Case-Based Reasoning" Applied Sciences 13, no. 1: 448.
https://doi.org/10.3390/app13010448
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details
here.
Article Metrics
Article metric data becomes available approximately 24 hours after publication online.


留言 (0)