
記住我
Plant breeding has been done by humans for centuries and has only grown in importance in recent history due to increasing global demand for food. Nowadays, it is possible to incorporate genetic information in breeding programs to improve decisions on artificial selection (Hickey et al., 2017). Researchers have investigated different statistical modeling methods for data analysis in this field. However, there are still a number of open questions w.r.t. model-oriented experimental design for phenotypic data collection in plant breeding programs. This problem is well-known in the field as optimization of the training set for model fit in genomic selection. Particularly, the search for optimum experimental designs under the genomic best linear unbiased prediction (gBLUP) model has not been studied extensively.
This article provides insights into the optimal design problem in the gBLUP model that is frequently applied in genomic selection. Section 2 is concerned with some preliminary information about the gBLUP model and a review of the generalized coefficient of determination, which is necessary for the introduction of the CDMin-criterion, an established criterion in breeding experiments. The optimal design problem is specified in Section 3 with emphasis on the particularities and differences to optimal design of experiments in classical linear models. Subsequently, different algorithms for the heuristic search of exact optimal designs are outlined in Section 4. A related discussion in a similar context is provided in Butler et al. (2021). The algorithms mentioned in Section 4 are applied to data and compared to algorithms provided in the TrainSel R package by Akdemir et al. (2021). The setup for this comparison is described in Section 5 and results are stated w.r.t. criterion values achieved as well as runtime in Section 6. A discussion on extensions of this work is given in Section 7. We provide conclusions in the final Section 8.
2 The gBLUP modelThe gBLUP model is a special case of a linear mixed model with individual-specific random effects. Consider the following linear mixed model
where y is a n×1-vector of observed values, X is an n×p matrix, with corresponding p×1-vector β of fixed effects, and Z=In being the identity matrix of dimension n×n with corresponding n×1-vector γ of individual-specific random effects. The n×1-vector ε denotes the random errors. The vectors γ and ε are independent of each other and follow a normal distribution with
γε∼N00,σg2G00σe2In.It is assumed that the genomic relationship matrix (GRM) G and the ratio λ=σe2σg2 are known. Further, it is assumed that G is nonsingular. For convenience, define V = σg2ZGZ′ + σe2In for subsequent formulas.
The GRM quantifies the degree of relatedness between plant lines in a breeding scheme. There are several ways to obtain such a matrix from genetic marker data (e.g., single-nucleotide polymorphism marker data). The calculation of the GRM is not the subject of this article, thus, for further information on this, the reader may want to refer to Clark and van der Werf (2013). For a detailed introduction to the gBLUP model and its relationship to other models in plant breeding, it is useful to refer to Habier et al. (2007) and VanRaden (2008).
The fixed and random effects in model (1) can be estimated/predicted via Henderson’s mixed model equations, see, e.g., Henderson (1975) and Robinson (1991). The estimators/predictors can be written as
β̂γ̂=D′σe−2In−1D+σg−2B−1D′σe−2In−1y=σe−2D′D+σg−2B−1σe−2D′y,with
The covariance matrix of the estimators/predictors is
Eβ̂−βγ̂−γβ̂−βγ̂−γ′=σe−2D′D+σg−2B−1∝D′D+λB−1=H11H12H21H22,(2)where H11 is of dimension p×p and it is the (proportional) covariance matrix of the fixed effects and correspondingly for the other submatrices.
The prediction variance of observed units is therefore
Varŷ∝diagDD′D+λB−1D′.Let the covariance between random effects of units xi and xj be denoted by σg2G(xi,xj)=Cov(γi,γj) and G(xi,xi)=G(xi) with the appropriate extension to a covariance matrix of several individuals.
The prediction variance of an unobserved individual is
Varŷ0∝d0D′D+λB−1d0′where d0=x0z0 is a row-vector of dimension n+p with z0=G(x0,X)G(X)−1.
After model-fitting, breeders are mainly interested in the predicted random effects of all individuals potentially available for breeding. The predicted effects are called estimated genomic breeding values (GEBVs) and serve as a selection criterion, where the ranking of the breeding values is important (Jannink et al., 2010). The GEBVs of the individuals used for model fitting provide the predicted random effects γ̂. For individuals not included in the fitted model, the random effects must be rescaled to account for relationships between individuals. Let z0=G(x0,X)G(X)−1, where x0 denotes the vector of fixed effects for an unobserved individual. Then the GEBV of this individual is given by z0γ̂ (Clark and van der Werf, 2013).
Since breeders are mainly interested in the predictions of random effects, the goodness of a model shall be evaluated on the precision of the GEBVs in the sense that the ordering is most accurate. Arbitrary rescaling of the predicted random effects does not influence breeders’ selection decisions, hence, it is not important. To utilize a measure that is most useful in this respect, Laloë (1993) has introduced the generalized coefficient of determination with the purpose of quantifying the precision of the prediction.
Let the coefficient of determination (CD) of the random effect of unit i be defined by
CDxi|X=Varγ̂iVarγi=1−Varγi|γ̂iVarγi,(3)where the design matrix in the model fit to predict γ̂ is X.
As can be seen in Equation 3, the CD of an individual effect is a function of the variance ratio before and after the experiment. Consequently, CD is in the range of [0,1]. As described in Laloë (1993), the CD measures the squared correlation between the predicted and the realized random effect for an individual and thus measures the amount of information supplied by the data to obtain a prediction.
A matrix of CD values can easily be computed by
CDX0|X=diagGX0,XZ′PZGX,X0⊘GX0,X0,where ⊘ is the element-wise (Hadamard) division and P = V−1 − V−1X(X′V−1X)−1X′V−1 (Akdemir et al., 2021; Isidro y Sanchéz and Akdemir, 2021). Notice that X is the matrix of fixed effects for model fitting and X0 is a design matrix of individuals. The concept of CD can be extended by introducing contrasts between individuals. For a given contrast c with appropriate dimension and |c|=0, the respective CD values are given by
diagc′GX0,XZ′PZGX,X0c⊘c′GX0,X0c.3 Optimal design problemThe design problem in the gBLUP model can be viewed as a selection of n experimental units out of N candidate units without replicates. Denote the design space as X=, i.e., it is the set of all units that can potentially be included in the design. Note that the design matrix Z is not included in this definition, since it is the same regardless of the design for a given size n of the experiment, and replication of units is not considered. However, it is the case that the covariance of units xi in the model, with i=1,…,n, is different w.r.t. the design.
The exact design of size n<N is then written as ξn and fulfills ξn⊂X, |ξn|=n. Define the remaining set as ζ= and notice that ξ∪ζ=X and ξ∩ζ=∅.
Let the inverse of the (proportional) covariance matrix in Equation 2 be called the information matrix and denote it relative to a design ξn by
M(ξn)=D′ξnDξn+λBξn.Due to the dependence of the GRM G on the exact design ξn, the information matrix is not additive w.r.t. single experimental units. This makes the application of well-known experimental design theory on the classical linear model infeasible.
An optimal exact design ξn* of size n is typically defined as
for some optimal design criterion given by a function Φ:Rq×q↦R on the information matrix, where q=n+p.
Since breeders are mainly interested in the prediction of random effects in the gBLUP model, we restrict ourselves to criteria on the part of the covariance matrix that corresponds to random effects, i.e., to H22. In accordance with the literature on optimal design of experiments (cf. Atkinson et al., 2007), let the D-criterion on the covariance of random effects be defined by
Φ1M(ξn)=−ln|H22ξn|.(4)The D-criterion is a standard criterion, which minimizes the generalized variance of the parameter estimates (i.e., predictions in this application). Hence, it measures the precision of the predictors. For a geometrical interpretation of the D-criterion, see, e.g., Atkinson et al. (2007), Fedorov and Leonov (2013).
Additionally, consider the so-called CDMin-criterion, defined as
Φ2M(ξn)=minCDX|ξn=mindiagGX,ξnZ′PZG′X,ξn⊘GX.(5)The CDMin criterion is the default criterion in the R package TrainSel (see Akdemir et al., 2021). As previously mentioned in Section 2, the CD of an individual measures the amount of information supplied by an experiment to predict the random effect of an individual. The CDMin-criterion maximizes the minimum CD value over all individuals. Hence, it is driven by the intuition of controlling for the worst case. The generalization of the CD was initially proposed by Laloë (1993) and has since gained popularity in the field, see e.g., Rincent et al. (2012). There are other criteria related to the CD, e.g., the CDMean criterion, which instead optimizes for the average CD. Refer to Akdemir et al. (2021) for a discussion on the CDMin-criterion versus other criteria. The literature on optimization criteria for this task is very rich and current, see e.g., also Fernández-González et al. (2023), where the authors compare different criteria w.r.t. accuracy of the predicted traits. However, the main focus of this manuscript is not on the selection of a suitable criterion, but rather on the efficient optimization once a criterion has been chosen.
In the following, we will concentrate on the two criteria stated above for clarity, but our methodology and discussion may extend well beyond those.
4 Heuristic search for an exact optimal designExperimental design optimization in the gBLUP model is challenging in the sense that the covariance matrix of the random effects is directly dependent on the design. In particular, the information matrix is not a weighted sum of unit-specific matrices, which does not allow for standard convex design theory from the classical linear model to be applied directly. Due to this fact, it seems most reasonable to consider only optimization methods for exact designs rather than approximate designs (cf. Prus and Filová, 2024).
Even though the information matrix in the gBLUP model is quite different from the standard case, it may be sensible to adopt some ideas on algorithms from the classical linear model. This section reviews and alters algorithms for the application at hand. Furthermore, a comparison to the algorithm and R package TrainSel by Akdemir et al. (2021) will be made in the subsequent section.
The optimization strategy proposed by Akdemir et al. (2021) (implemented in TrainSel) combines a genetic algorithm with simulated annealing to identify local maxima in a given design region. It does so in a brute-force way without relying on theoretical considerations w.r.t. the design of experiments. The TrainSel algorithm provides flexibility by allowing for user-specified criteria, which comes at the cost of perhaps more efficient optimization strategies for specific criteria. The implemented function TrainSel offers several parameters that can be modified for a given situation; most relevant to this article are the maximum number of iterations for the algorithm, as well as the number of iterations without (significant) improvement until the algorithm is considered to have converged.
The published article Akdemir et al. (2021) refers to the author’s publicly available R package on Github. Since then, the authors have made a major update to the repository in May 2024 (see Javier, 2024). The full functionality of the package is now under license, with the possibility of obtaining a free license for public bodies. A substantial part of the computations in this paper have been performed on TrainSel v2.0, the previously publicly available version on Github. To the best of our knowledge, this version is no longer available for download. We have made comparisons with the licensed version Trainsel v3.0, and have observed some changes, which will be discussed in subsequent sections. Most notably, the newest version permits the manipulation of even more hyperparameters in the optimization algorithms and provides more user-friendliness in the specification of these parameters by introducing settings related to the size and complexity of the optimization problem. The optimization algorithm itself seems to have improved as well.
In contrast to this approach, the literature on experimental design typically proposes exchange-type algorithms in the search for exact designs (cf. Atkinson et al., 2007). Exchange-type algorithms start with an initial design ξn of size n (e.g., randomly sampled) and iteratively improve the design by exchanging units from the support and candidate set. In this case, the support and candidate set are mutually exclusive, and their union is the whole design space X. The units are exchanged either according to the best improvement in the criterion (Fedorov exchange, see Fedorov, 1972) or according to a greedy strategy (modified Fedorov exchange, see Cook and Nachtsheim, 1980). In the classical Fedorov exchange algorithm, the criterion value for all possible exchanges between the candidate and the support set is calculated at each iteration. This guarantees that the most beneficial exchange is made in each step, which leads to quick ascension. The disadvantage is that the number of computations in each iteration can be large depending on the size of the support and candidate set. In the modified Fedorov exchange, the exchange is performed as soon as an improvement is identified, hence, the ordering of the support and candidate set has an impact on the search. The advantage of the modified Fedorov exchange over the classical one is the reduced computational effort in each iteration if a beneficial exchange can be found quickly. The final exact designs are dependent on the initial design, i.e., for randomly sampled starting designs, the final designs are also subject to randomness.
Exchange algorithms have been applied in the field of plant breeding, e.g., in Rincent et al. (2012) and Berro et al. (2019). However, these articles have not included any guidance on selecting potential instances for exchange. Rather, they have randomly performed an exchange and recalculated the criterion value. If an improvement could be observed, the exchange was kept. We believe that exchange algorithms can be improved in two ways, either the known best exchange can be made at each step, or the chance of making a good exchange can be increased by ordering the support and candidate set by some heuristic. These two approaches will be discussed below.
Unfortunately, none of the algorithms can guarantee convergence to the global optimum. Thus, it is reasonable to restart the algorithms at different random seeds to obtain multiple solutions, as is typically advised in the literature (see, e.g., Atkinson et al., 2007). The design with the highest criterion value over all random restarts should ultimately be chosen.
In the classical linear model, the most beneficial exchanges under the D-criterion are performed by exchanging the unit with minimum prediction variance in the support set with the unit with maximum prediction variance from the candidate set (cf. Atkinson et al., 2007). The reasoning is not as clear-cut in the gBLUP model as will be argued below. A modified Fedorov exchange can be performed with different orderings of the candidate and support set, which may lead to different resulting designs as well as different runtimes.
As stated, the candidate set in the modified Fedorov exchange is usually ordered w.r.t. decreasing prediction variance for the D-criterion, i.e., candidates with a high prediction variance are considered first for inclusion in the support set. Since the gBLUP model relies on individual-specific random effects, the removal of a unit from the support set has non-trivial consequences on the variance of other units. This makes it relatively difficult to specify a sensible ordering of the support set for exchanges. Since the D-criterion minimizes the generalized variance of the predicted random effects in this application, it seems reasonable to remove units (and thereby also random effects in the model) that have a high prediction variance. As this is completely converse to the reasoning in the classical linear (or mixed effect) model, we will here vary the ordering of the support set to increasing, decreasing, and random for the subsequent examples.
For the CDMin-criterion, following a similar thought process, it seems reasonable to add units with a small CD from the candidate set in the modified Fedorov exchange. In turn, units with a high CD could be sensible candidates for removal from the support set. In an effort to compare the ordering strategies, the ordering of the support set is also performed in increasing, decreasing, and random order as for the D-criterion in our examples.
The Fedorov exchange algorithm has a natural ending, i.e., when no further improvement can be found for any exchange of a unit from the candidate set with a unit from the support set, the best solution obtained is returned. For the modified Fedorov exchange, the same stopping rule is given, but the path and solution obtained are not necessarily the same. On the other hand the TrainSel algorithm does not have such a natural ending. Instead, the user must specify a maximum number of iterations for the algorithm and a number of iterations without a (significant) improvement on the criterion value, which will terminate the algorithm. The threshold for minimum improvement must also be specified by the user. Termination of this algorithm is defined as early stopping when no significant improvement on the criterion value was attained for a specified number of iterations.
5 Comparison of different algorithmsIn the previous section, three algorithms have been introduced: TrainSel, Fedorov exchange and modified Fedorov exchange, where in the modified Fedorov exchange the support set can be ordered in different ways.
A comparison between these algorithms is performed on a dataset of N=200 wheat lines given in the TrainSel R package (see Akdemir et al., 2021). The data consists of genotypes at 4,670 markers or as a precalculated relationship matrix of the 200 available individuals. Akdemir et al. (2021) name https://triticeaetoolbox.org as the original source of the data, which has undergone some additional preprocessing by the authors. We proceed with the GRM G over the 200 individuals as it is provided since the calculation is not the subject of this article. In this simulated design problem, we set the ratio of variances λ=1 and R=In for a given sample size n. We further include an intercept in the model, i.e., X=1.
The comparison is performed over ten restarts with different random seeds over the D-criterion in Equation 4 and the CDMin-criterion in Equation 5. Overall, the algorithms are run at sample sizes of n∈. We eventually compare five different search strategies w.r.t. the criterion value obtained and the runtime of the algorithms.
Since there is no natural convergence of TrainSel, some arbitrary parameters must be selected for comparison to the other algorithms. There are conflicting goals in comparing criterion values and runtimes between algorithms, so the parameters were chosen such that TrainSel was not run unnecessarily long, but would converge to an appropriate solution. In particular, the maximum number of iterations was chosen to be 30⋅n, and the number of iterations without (sufficiently large) improvement before convergence was set to 100. All other parameters were set to the default values.
The results in the subsequent section refer to Trainsel v2.0, which is the algorithm described in the article Akdemir et al. (2021). Since the corresponding R package has since undergone major updates to version 3.0, we reproduce the plots in this section for the newer version as well. The set of hyperparameters in the newest version has increased in comparison to v2.0. First, we have strived to set parameters as similarly to version v2.0 as possible. Second, we have reproduced the design problems with the suggested hyperparameters in TrainSel v3.0 for large high-complexity designs. Only the maximum number of iterations and the number of iterations without improvement before convergence have been adjusted as in the computations with TrainSel v2.0. Since results were better in the second configuration, we only discuss this case in Section 6.1.
6 ResultsFirstly, the criterion values of different algorithms are compared to one another, secondly, runtimes are investigated and lastly, some convergence plots are examined. We start with comparisons for the D-criterion. The final criterion values and runtime per random restart can be seen in Figure 1. It is most notable that the Fedorov exchange algorithm does not perform well in terms of criterion value in small sample sizes, while it does obtain a slightly larger criterion value at n=80 than the other algorithms. In general, for sample sizes n≥30, the criterion values for the TrainSel and (modified) Fedorov exchange algorithms are similar, while the runtime for the TrainSel algorithm as well as the Fedorov exchange exhibits rapid growth over increasing sample size as opposed to the modified Fedorov exchange.
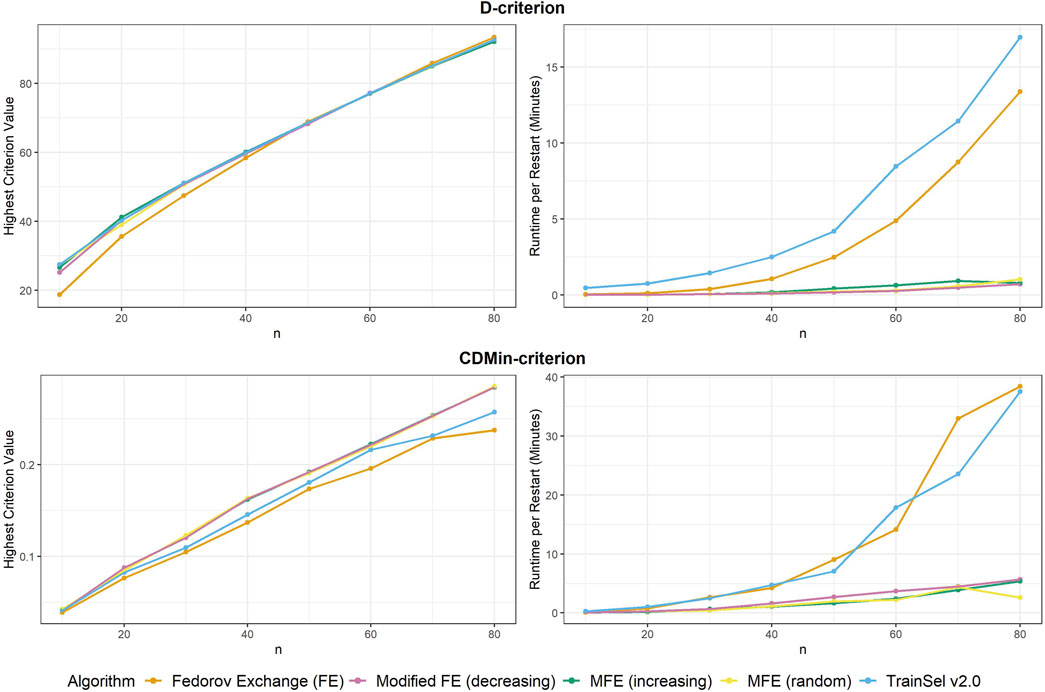
Figure 1. Highest criterion value and runtime per restart of different algorithms.
Convergence was attained for all algorithms at all random restarts and sample sizes.
Although the convergence plots of different algorithms do not directly imply anything related to runtime, it is still interesting to compare the ascension to criterion values, especially w.r.t. the different orderings of the support set in the modified Fedorov exchange algorithm. Therefore, Figure 2 displays criterion values per iteration for the different algorithms.
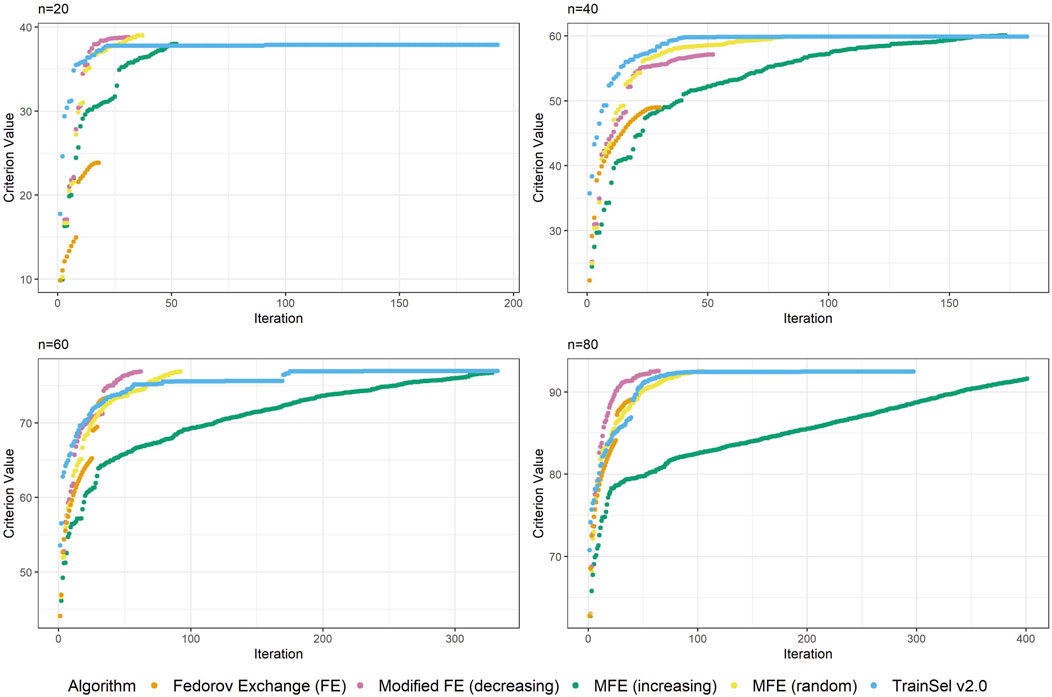
Figure 2. Convergence of algorithms over different sample size at one random seed (D-criterion).
Figure 2 depicts the criterion values over iterations for sample sizes of n ∈ at one random seed. The reader should be made aware that these graphs can look different at other random seeds, in particular for small sample sizes, but we deem this plot representative for showing some general properties. For a more comprehensive understanding, some more convergence plots at all random seeds are provided in the accompanying Supplementary material for this article.
One thing that is particular about the graphs is that the modified Fedorov exchange with ordering according to increasing variance (as is traditionally used in the classical linear model) displays a very slow ascension of the criterion value. Ultimately, the resulting criterion value at convergence is similar to the other algorithms, but if the algorithm were to be stopped early, even just a random ordering of the support set might result in higher criterion values. This may seem counterintuitive, but as has been mentioned in Section 5, by removing a unit from the support set, the whole individual-specific effect of this individual disappears from the model, hence units with high variance will be interesting candidates for removal. Obviously, there is a trade-off w.r.t. relationships (i.e., covariances) to other individuals, thereby making this reasoning non-trivial.
Another interesting fact is that at this random seed, TrainSel ascends rather quickly, but a plateau on the criterion value is retained for several iterations before convergence. This is due to the specified settings. Other settings would have resulted in different behavior (e.g., earlier stopping). It is not straightforward to choose settings a priori that will result in reasonable convergence behavior.
Now moving on to the CDMin-criterion, similar plots of criterion values and runtime are provided in Figure 1.
The results in the CDMin-criterion are different compared to the D-criterion in a number of ways. Firstly, it is very clear from Figure 1 that the Fedorov exchange is not well-suited for this problem, since it results in criterion values below the ones of all other algorithms and it has bad runtime properties. The same applies to the TrainSel algorithm, although it is still better than Fedorov exchange w.r.t. criterion values. One may observe that the modified Fedorov exchange yields similar criterion values regardless of the ordering of the support set, but a decreasing ordering of the support set w.r.t. CD results in a longer runtime. In general, the modified Fedorov exchange requires a longer runtime for the CDMin-criterion than for the D-criterion.
Convergence occurred for all algorithms at all random seeds and sample sizes, except for TrainSel, where 3 out of 10 random restarts did not converge for a sample size of n=10, otherwise, convergence was always attained.
Again, Figure 3 looks quite different from Figure 2, i.e, the case of the D-criterion. In particular, the TrainSel algorithm does not ascend as quickly and there are still large jumps in the criterion value after a considerable number of iterations. It can also be seen from the second graph in this figure that TrainSel can be stuck in a local minimum that is not optimal and converges too early. Interestingly, the modified Fedorov exchange with the random ordering of the support set seems to have good ascension properties. As for the D-criterion, refer to the Supplementary Material to find convergence graphs for all random seeds at different sample sizes.
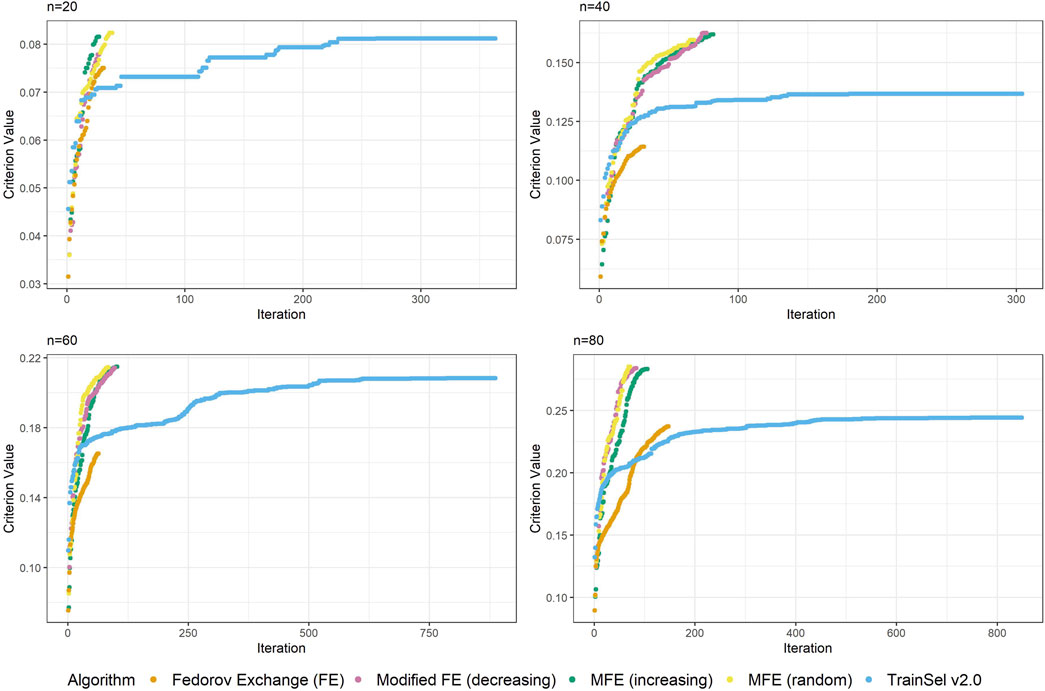
Figure 3. Convergence of algorithms over different sample size at one random seed (CDMin-criterion).
6.1 Comparison to TrainSel v3.0We have observed improvements of the optimization algorithm in TrainSel in the last major update. Particularly, the optimization over the D-criterion is considerably improved. We reproduce Figures 1–3 subsequently to showcase the improvements.
We have included further computations for samples sizes n∈ for all algorithms except for the classical Fedorov exchange since this algorithm is not competitive with the other algorithms for large sample sizes.
From Figure 4 it seems that the runtime has improved substantially, while the criterion value is still equally high as in TrainSel v2.0 for the D-criterion. Looking at Figure 5, it is clear that TrainSel v3.0’s best solution is attained very quickly and the subsequent iterations are not necessary. While it is typically not possible to know this before optimization of a design problem, we can see a posteriori that the number of iterations until termination of the algorithm could have been chosen much smaller, which would improve runtime even further.
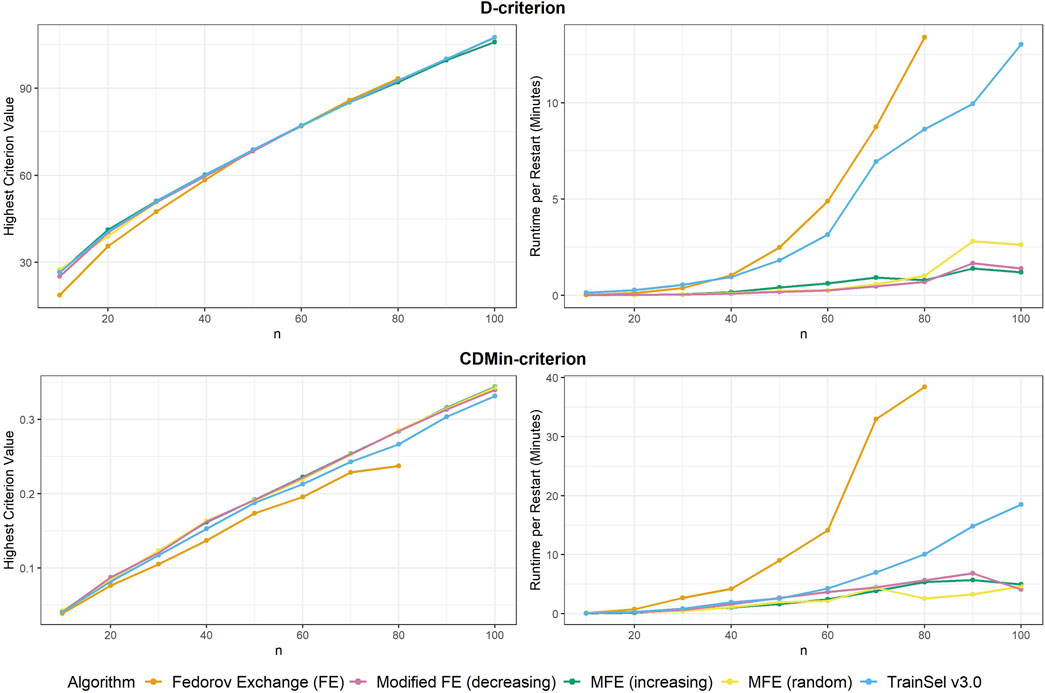
Figure 4. Highest criterion value and runtime per restart of different algorithms including TrainSel v3.0
留言 (0)