
記住我








The CHARLS is a long-term follow-up survey targeting Chinese adults aged 45 years and above. Its primary goal is to collect high-quality micro-data related to the aging status of China’s population. Organized and conducted by the Chinese Academy of Social Sciences, Peking University, and other institutions [18]. CHARLS began as a national baseline survey in 2011. Since then, participants have been followed up every two years, resulting in five rounds of data collection to date (2011, 2013, 2015, 2018, and 2020). The dataset includes demographic information, results from 13 medical examinations, and analyses of blood samples [19]. The study adhered to the principles of the Declaration of Helsinki and received approval from the Biomedical Ethics Review Board of Peking University (IRB 000010052–11, 015). All field workers underwent systematic professional training and conducted face-to-face interviews using standardized questionnaires [19]. Written informed consent was obtained from all participants prior to their inclusion in the study. Further details about CHARLS are available on its official website (http://charls.pku.edu.cn/en).
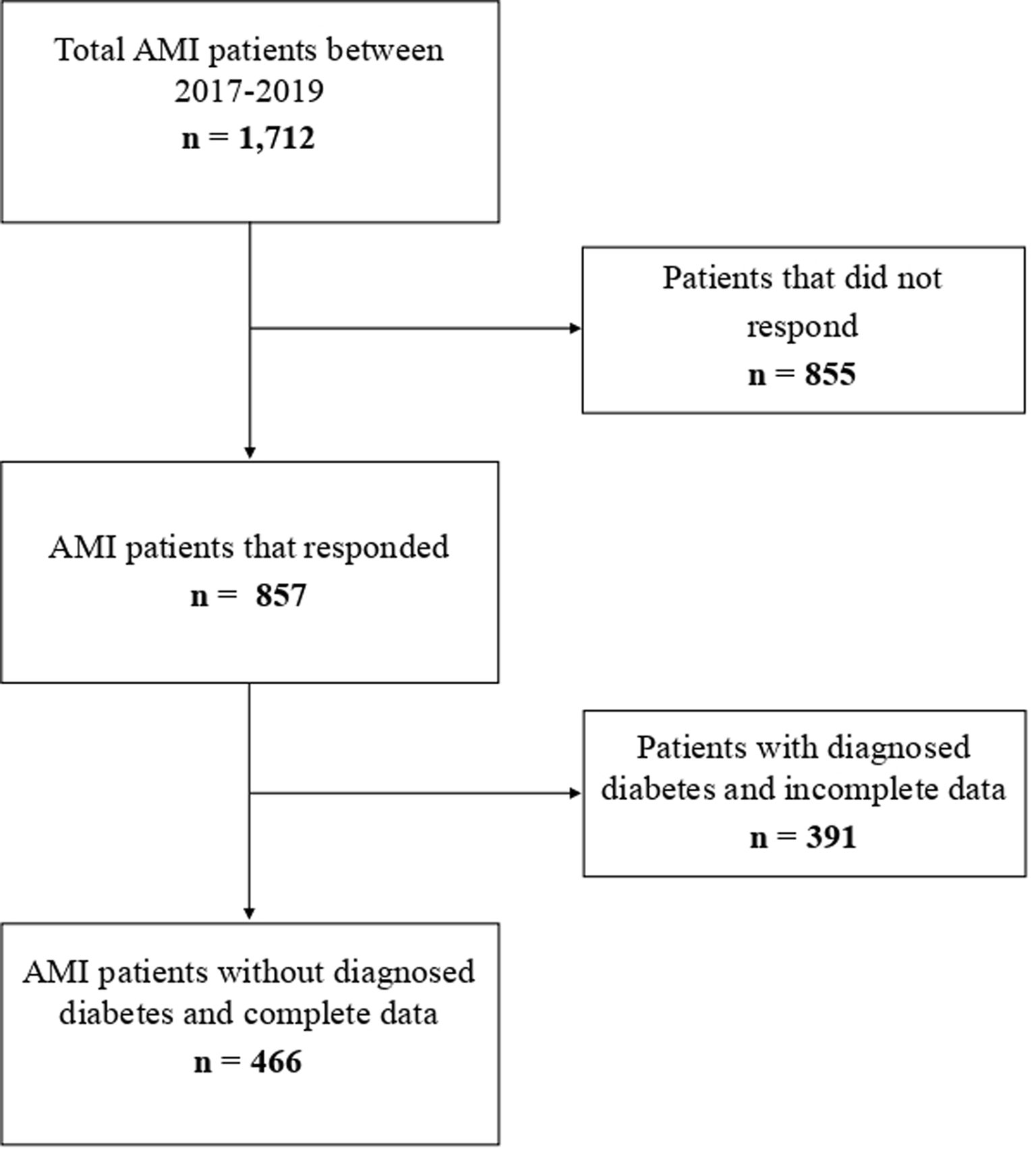
In this study, wave 3 (2015) was set as the baseline. We used data from the baseline survey and wave 1 (2011) to evaluate dynamic changes in AIP, while subsequent follow-up surveys were utilized to track outcomes up to wave 5 (2020). Figure S1 presents the study population selection process. Of the 19,719 participants aged 45 years and above, we excluded 12,806 participants for the following reasons: (1) lack of blood test data in both 2011 and 2015, (2) inability to calculate AIP, and (3) inability to define CKM syndrome stage. Additionally, 2,385 participants with CVD at baseline or who were lost to follow-up and 1,099 participants with missing baseline characteristic data were excluded. Finally, 3,429 eligible participants were included in the analysis.
Data assessmentDetermination of CVD and calculation of AIPIn this study, we calculated the AIP by taking the logarithm of the ratio of TG to HDL-c obtained from blood samples collected at waves 1 and 3. Using these AIP values, we performed K-means cluster analysis to identify distinct patterns of AIP variation over time among the participants.
The exposure factor in this study was the changes in AIP from 2012 to 2015, and the cumulative AIP(cumAIP) was calculated as (AIP2012 + AIP2015)/ 2 * (2015 − 2012) for assessing the impact of AIP changes on CVD incidence [17].
The outcome in this study was the incidence of CVD. In according to previous studies [20,21,22], incident CVD events were assessed by the following standardized questions: “Have you been told by a doctor that you have been diagnosed with a heart attack, coronary heart disease, angina, congestive heart failure, or other heart problems?” or “Have you been told by a doctor that you have been diagnosed with a stroke?” Participants who reported heart disease or stroke during the follow-up period were defined as having incident CVD. Additionally, if a participant indicated a heart attack or stroke at a previous round of follow-up, they were required to verify the presence of CVD at a later round of follow-up. If participants denied a previous self-reported diagnosis of heart disease or stroke, these inconsistencies were corrected retrospectively. Our diagnoses of CVD were consistent with previous studies using CHARLS [20,21,22].
Definition of CKM syndrome stages 0 to 4According to the American Heart Association Presidential Advisory Statement [1], CKM syndrome stages 0–4 are specified as follows: stage 0: no CKM health risk factors; stage 1: abdominal obesity and/or prediabetes; stage 2: metabolic disorders (type 2 diabetes mellitus, hypertension, and high triglycerides) or renal disorders; stage 3: subclinical CVD in the context of the CKM syndrome; stage 4: clinical CVD (coronary heart disease, heart failure, stroke, peripheral artery disease, atrial fibrillation) in CKM.
Data collectionThe baseline survey collected demographic information such as age, gender, place of residence, education and marital status. Anthropometric measurements including body mass index (BMI), waist circumference(WC), diastolic blood pressure(DBP) and systolic blood pressure(SBP) were also taken. Related diseases and treatment factors included diabetes, antidiabetic treatment, dyslipidemia, antihyperlipidemic treatment, cancer, liver disease, CVD and CKM stage. Data on current alcohol consumption and smoking were also recorded. As part of the laboratory assessment, a number of blood chemistries were also collected, including total cholesterol (TC), TG, blood urea nitrogen (BUN), uric acid (UA), C-reactive protein (CRP), HDL-c, serum creatinine(Scr), fasting blood glucose (FBG) and glycated haemoglobin (HbA1c) AIP and cumAIP was assessed by further calculations.
Subjects were classified as hypertensive if they had a documented history of hypertension, had a SBP of 130 mmHg or greater, a DBP of 80 mmHg or greater, or were taking antihypertensive medication at the time of the baseline assessment [23].
Participants were diagnosed with diabetes if they had an FBG of 7.0 mmol/L (126 mg/dL) or greater, an HbA1c of 6.5% or greater, or had a history of diabetes or were being treated for diabetes [24].
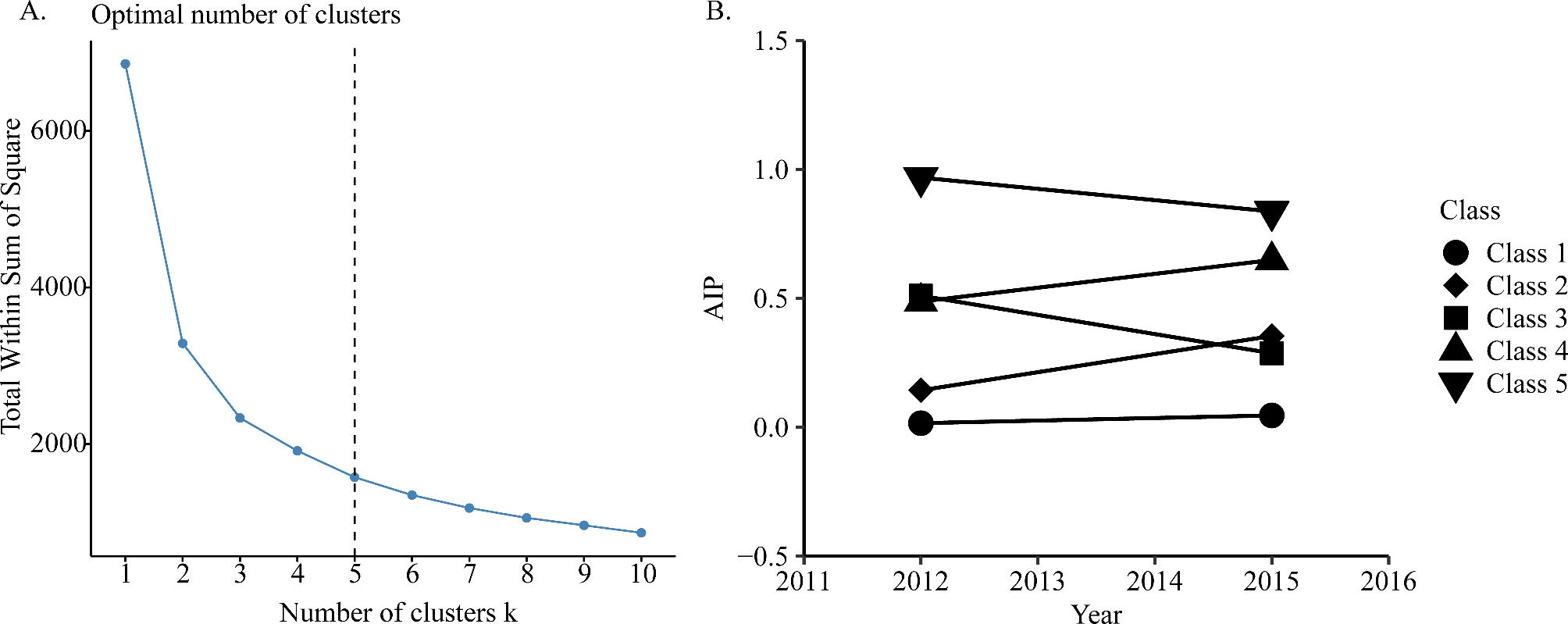
Statistical analysisK-means clustering is a rule-based method for determining the distance between data items (Fig. 1A). The advantage of this method is that it is simple and scalable. In our study, K-means clustering performed best when the number of clusters is equal to 5 [25, 26]. The specific groupings are as follows: Class 1: AIP increased slightly from 0.02 in 2012 to 0.05 in 2015, with a cumAIP of 0.09 ± 0.33, indicating that the AIP level has always remained in a low range with the best control; Class 2: AIP increased from 0.14 in 2012 to 0.35 in 2015, with a cumAIP of 0.75 ± 0.24, indicating that the AIP level was within the medium range with a slow upward trend, and the control was better; Class 3: AIP decreased from 0.51 in 2012 to 0.29 in 2015, with a cumAIP of 1.20 ± 0.31. Even though the AIP level had decreased from high to low, due to the higher AIP level in the early period, its cumAIP was higher than class 2, indicating a medium control effect; Class 4: AIP slightly increased from 0.49 in 2012 to 0.65 in 2015, with a cumAIP of 1.70 ± 0.28, indicating that the AIP level has been in the higher range for a long time, and the control is poor; Class 5: AIP decreased from 0.97 in 2012 to 0.84 in 2015, with a cumAIP of 2.71 ± 0.46, indicating that the AIP levels were always in the highest range and the control was the worst (Fig. 1B).
Fig. 1
A K-means clustering method for clustering the atherosclerosis index of plasma; B The AIP clustering by k-means clustering
Descriptive statistics (mean and standard deviation SD for continuous data, percentages for categorical data) were used to report the basic characteristics of the data. The normality of continuous variables was tested by Kolmogorov-Smirnov test, and the skewed distribution variable CRP was expressed as median and interquartile range. One-way analysis of variance, Kruskal-Wallis H test (skewed distribution variables), and chi-square test were used for comparison between groups.
We analyzed the association between cumulative and AIP changes and the risk of CVD using univariate and multivariate logistic regression models. To explore the potential nonlinear relationship between cumulative AIP and CVD risk in the CKM syndrome stages 0–3 population, as well as in the CKM stages 0–2 (early) and CKM stage 3 (late) populations [27, 28], we used the restricted cubic spline (RCS) regression model to analyze the odds ratio (OR). At the same time, to explore the relationship between cumulative and AIP changes and CVD risk in different demographics, subgroup and interaction analyses were performed in different age groups (< 60 years and ≥ 60 years), sex, place of residence, marital status, smoking status, drinking status, and different CKM syndrome stages. In the multicollinearity test (Table S1), the results showed that the variance inflation factor of each covariate was less than 5, indicating that there was no significant multicollinearity between the covariates.
In addition, the AIP was derived using a mathematical formula for the TG and HDL-c variables. In order to fully explain the formula, we employed a weighted quantile sum (WQS) regression model with 1000 iterations using the bootstrap resampling method. The WQS model helps to determine the weights assigned to TG and HDL-c, quantifying their respective contributions to the overall effect. These weights were restricted to a range of 0 to 1, with a cumulative sum of 1. Higher weights indicate greater importance of the corresponding metrics in the prediction of the CVD.
All analyses were performed using R statistical software version 4.2.2 (R Foundation), and a two-sided P < 0.05 was considered statistically significant.
留言 (0)