
記住我



This retrospective study received approval from the institutional review board (IRB number: 2021060), and all methods were performed in accordance with the relevant guidelines. The statement granted a waiver for written patient informed consent. The data were collected retrospectively from four distinct hospitals. The study included patients who underwent prostate bpMRI followed by RP between November 2017 and December 2022. This encompassed gathering bpMRI images and pertinent clinical information, such as age, PSA levels, bpMRI results, biopsy pathology, and RP pathology reports. The exclusion criteria were as follows: (1) prior endocrine therapy, (2) benign prostate hyperplasia according to RP pathology, (3) missing PSA data, (4) incomplete biopsy pathology records, (5) incomplete MR images, and (6) evident image artifacts. The process of data enrollment is depicted in Fig. 1.
Fig. 1
Data enrollment process. Flowchart depicting the process of data inclusion. The training dataset comprises data from Hospital_1, while the external validation dataset includes data from Hospital_2, Hospital_3, and Hospital_4. All the data adhered to the same inclusion and exclusion criteria. In total, the training dataset consisted of 345 included patients, and the external validation dataset included 533 patients: 18 from Hospital_2, 231 from Hospital_3, and 284 from Hospital_4
Reference standardAll patients underwent both biopsy and RP, and pathology samples were available for all patients. Pathology was assessed by experienced pathologists following the guidelines of the International Society of Urological Pathology (ISUP) group. The reference standard was established using the RP pathology results, categorizing the patients into three groups: ISUP_1, ISUP_2, and ISUP_3–5.
MR scanning protocolsThe bpMRI images in this study were acquired with 13 MR scanners from five different vendors. Detailed information regarding the MR scanners and image acquisition protocols can be found in Table 1.
Table 1 MR scanning protocols used in different hospitalsImage features extracted by AI algorithmsFollowing anonymization, the DICOM files were converted to NIFTI format using dicom2nii.py (Python 3.5) and then input into pre-trained AI software. For detailed technical information about the AI software, please refer to the supplementary material.
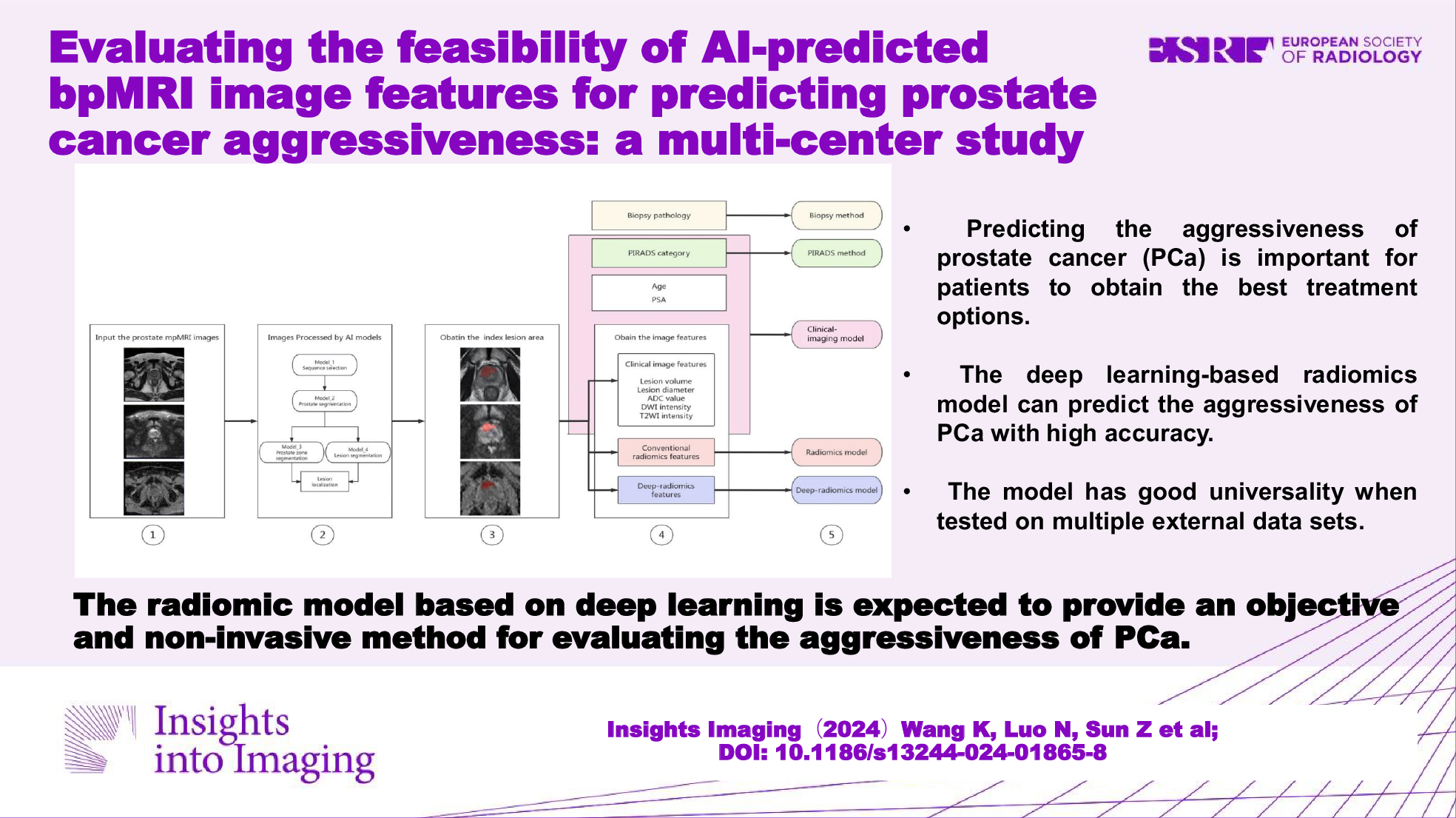
For each enrolled patient, the largest lesion predicted by the AI algorithms on the bpMRI images was designated the index lesion for analysis. The lesion’s location was classified as solely in the peripheral zone (PZ), solely in the transitional zone (TZ), or in both the PZ and TZ (PZ + TZ). The following image features were computed and utilized in the prediction model: (1) lesion volume, (2) diameter of the lesion, signifying the largest diameter of the lesion, (3) mean ADC value of the lesion (ADClesion), (4) mean signal intensity of the lesion on DWI (DWIlesion), and 5) mean signal intensity of the lesion on T2WI (T2WIlesion) (as illustrated in Fig. 2).
Fig. 2
Extraction of image features and construction of prediction methods. Step 1 involves selecting and inputting anonymized mpMRI images, which encompass T2WI, DWI, and ADC maps. In Step 2, the pre-trained AI models are employed to identify suspicious areas indicative of PCa. For a detailed process, see the supplementary materials. Step 3 entails identifying the index lesion by selecting the largest lesion from the predicted labels. The index lesion was annotated as the red areas on the images. Step 4 encompasses extracting image features from the index lesion, encompassing (1) clinical image features such as lesion volume, lesion diameter, ADC value, DWI signal intensity, and T2WI intensity, (2) conventional radiomic features, and (3) deep-radiomic features. In Step 5, various prediction methods are developed, including (a) biopsy prediction, which forecasts ISUP grouping based on biopsy pathology; (b) PIRADS prediction, which anticipates ISUP grouping based on the PIRADS category; (c) a clinical-imaging model, which incorporates age, PSA, PIRADS category, and clinical image features to predict ISUP grouping; (d) radiomics model, which forecasts ISUP grouping using conventional radiomic features obtained from the index lesion; and (e) deep-radiomics model, which forecasts ISUP grouping using deep-radiomic features extracted from the index lesion
Prediction methodsTo predict the ISUP_1, ISUP_2, and ISUP_3–5 classes, five prediction methods were developed, namely, the PIRADS category, biopsy pathology, a clinical-imaging model, a radiomics model, and a deep-radiomics model. The steps involved in developing the prediction methods are illustrated in Fig. 2. The training dataset utilized was sourced from Hospital_1, while the external validation dataset included data from Hospital_2, Hospital_3, and Hospital_4.
Both the PIRADS and biopsy methods use their results to fit an ordinal logistic regression model to predict the final PR pathology grading. Specifically, the PIRADS method uses the PIRADS categories (1 to 5) to predict the probability of the final PR pathology being classified as ISUP_1, ISUP_2, or ISUP_3–5. The biopsy method uses biopsy results (negative or ISUP 1 to 5) to predict the probability of the final PR pathology being classified into the same ISUP categories.
For the construction of the clinical-imaging model, clinical variables were employed as covariates. These included age, PSA levels, PIRADS score, and image features of the suspected clinically significant prostate cancer (csPCa) lesion, which included position, volume, diameter, ADC value, signal intensity on DWI, and signal intensity on T2WI.
To construct the radiomics model, image features were derived from regions of interest (ROIs) on the ADC maps using the PyRadiomics package in Python (https://pyradiomics.readthedocs.io/en/latest/changes.html). Z-score normalization was applied to standardize the extracted features, and Pearson correlation coefficients (PCCs) were computed to identify highly correlated features. Features with a PCC value exceeding 0.99 were eliminated to mitigate multicollinearity. The Kruskal‒Wallis test was then employed to select the features for the final radiomics model. For the classifier, the least absolute shrinkage and selection operator (LASSO) algorithm was utilized.
To construct the deep-radiomics model, image features were extracted using a deep-learning algorithm. The construction process involved several key steps: (1) Preprocessing ADC maps: Initial preprocessing included normalizing the intensities of the ADC maps. (2) ROI resampling: ROIs were resampled to ensure a consistent voxel size. (3) Deep feature extraction: A pre-trained deep-learning model was used to extract features from the segmented ROIs. (4) Feature dimension reduction: The resulting channel feature maps underwent dimension reduction by filtering with the maximum value, resulting in a set of 512 one-dimensional features. (5) Model construction: After extracting the deep features, the construction of the deep-radiomics model followed a procedure similar to that of the radiomics model, as previously described.
For model tuning, 5-fold cross-validation was employed to select the optimal value of the hyperparameter α, which controls the strength of the L1 penalty. A grid search was performed over a range of α values, and the one yielding the highest cross-validated accuracy was chosen. This process identified a subset of significant predictors associated with ISUP classes.
Prediction efficacy evaluationThe external dataset was used to assess the prediction effectiveness of the methods via receiver operating characteristic (ROC) analysis. This evaluation was conducted by computing the area under the ROC curve (AUC).
Statistical analysisThe statistical analysis was conducted using R 4.1.3 software. Quantitative variables with a normal distribution are presented as the mean ± standard deviation, while those with a nonnormal distribution are presented as the median (Q1, Q3). Categorical variables are presented as frequencies. The normality of the variables was assessed using the Kolmogorov‒Smirnov test, associations between categorical variables were examined using the chi-square test, and differences between multiple groups were compared using the Kruskal‒Wallis test. Multiclass ROC analysis was performed using the multiclass.roc() function from the pROC package. The calculation of classification metrics was performed using the reportROC() function from the reportROC package (supplementary material). The DeLong test was used to compare differences in the area under the curve (AUC) among the five types of prediction methods. A p-value less than 0.05 was considered to indicate statistical significance.
留言 (0)