
記住我
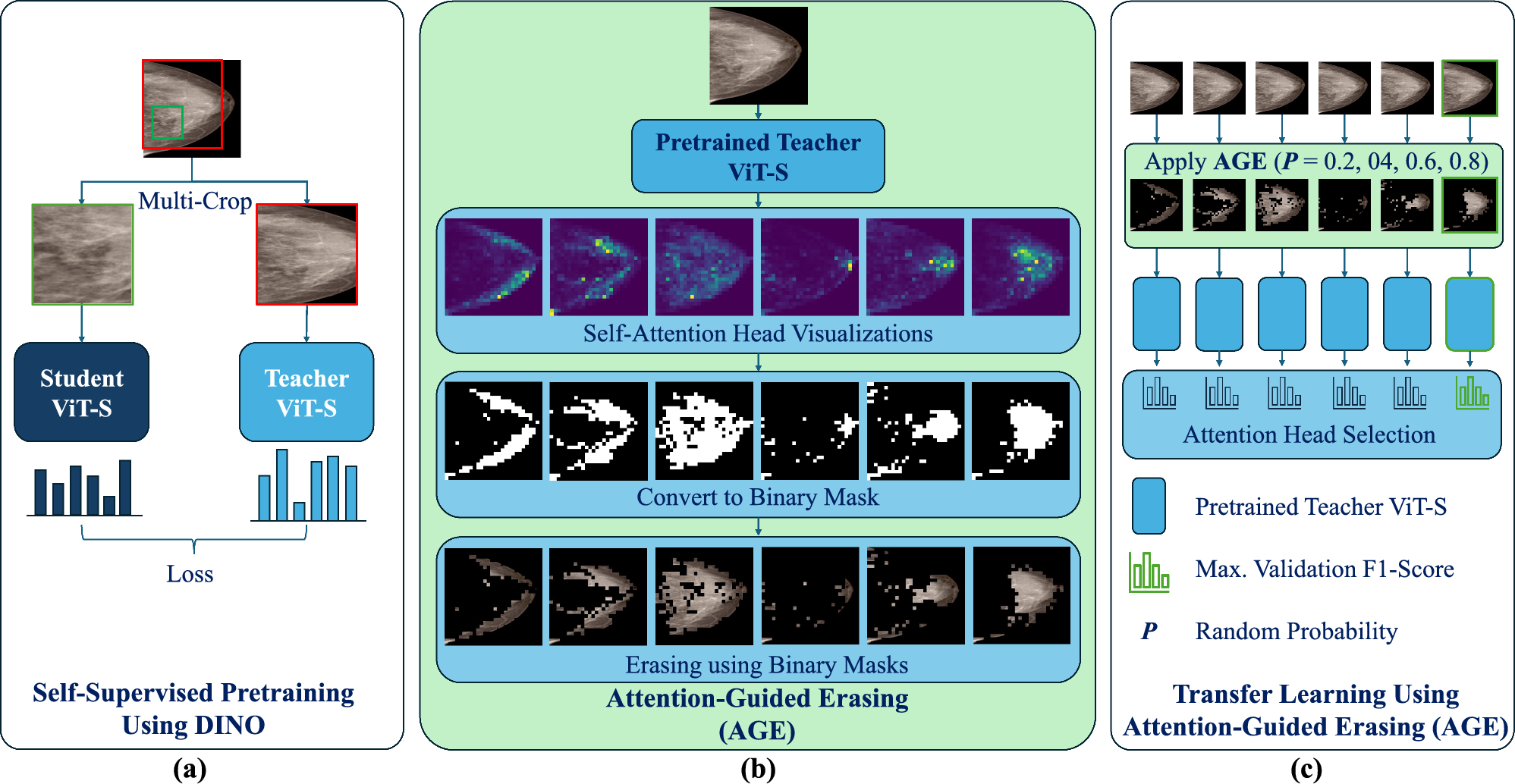

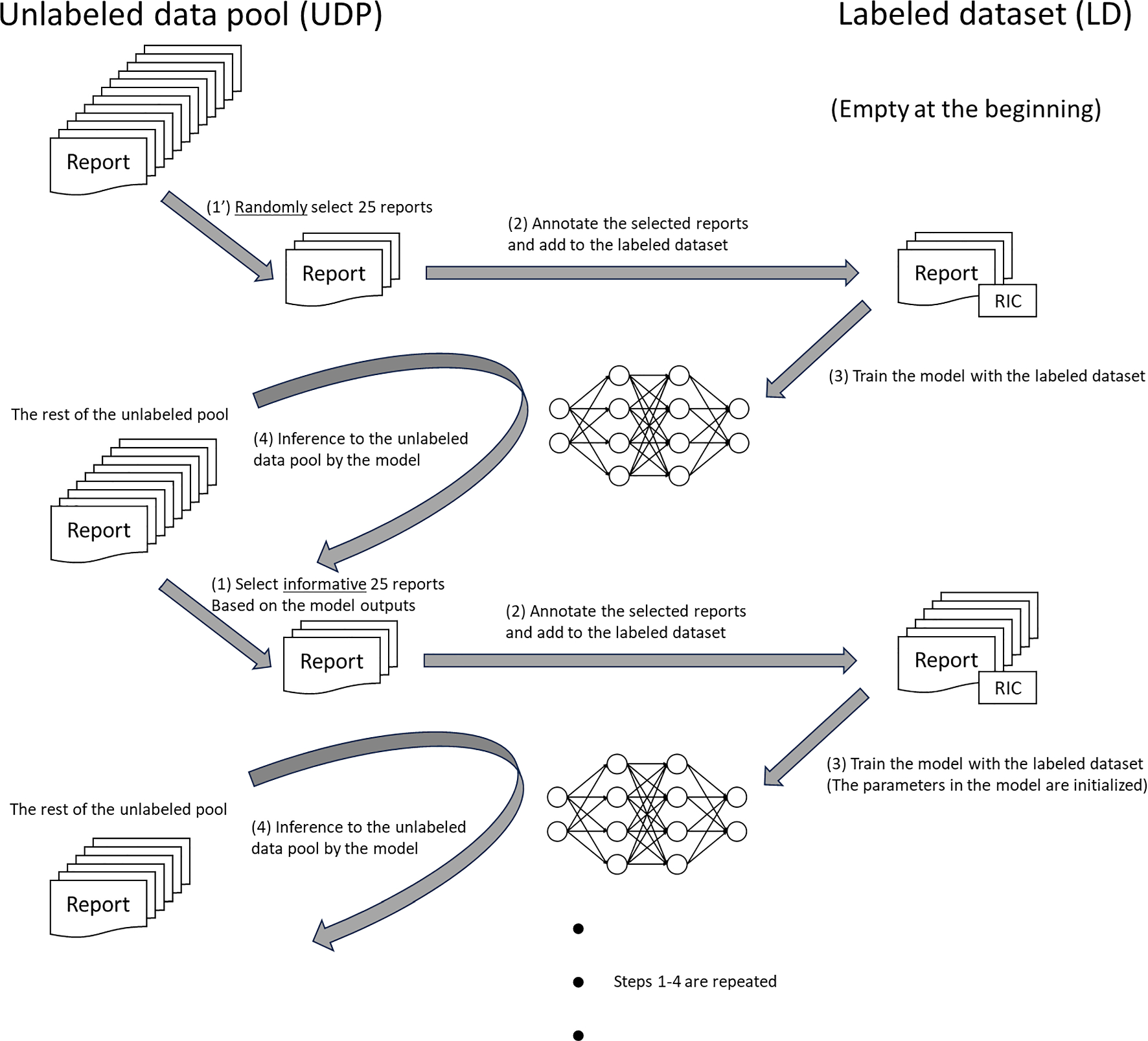


Overview of the Attention-Guided Erasing (AGE) Methodology. a Self-Supervised Pretraining using DINO [11]: A teacher student ViT framework, leveraging a teacher-student ViT-S self-distillation framework. b AGE [13]: Attention head visualizations from the SSL pretrained teacher ViT-S are converted into binary masks to isolate key ROIs and then used to erase background regions. c Transfer Learning with AGE: AGE is used on the input images using each of the attention heads with a random probability during training. The attention head yielding the highest validation performance is selected for final AGE-based transfer learning
Figure 1 outlines our proposed AGE data augmentation pipeline, involving SSL pretraining using DINO [11], a step-by-step illustration of obtaining masks for AGE, and transfer learning using AGE [13]. A single mammogram image is used in this figure for illustrative purposes, while the methodology is applied across multiple datasets as detailed in this work. The details of each stage are provided in this section.
Self-Supervised pretraining using DINOFigure 1(a) shows the overview of the DINO SSL pretraining. DINO’s approach involves a self-knowledge distillation paradigm where the student network learns to replicate the output of a teacher network through cross-entropy loss, aligning their output probabilities [11]. The output probabilities are derived by applying a softmax function to the feature representations learned independently by the student and teacher networks. Two differently transformed versions of the same image acts as the input to the student and teacher networks, which have distinct parameters. Here, we adopt the original implementation of DINO [11], to apply a multi-crop strategy, utilizing two global crops of the mammograms along with multiple lower-resolution local crops that focus on smaller patches within the images. The exposure to varied transformations drives the SSL learning process [11]. To maintain the quality of the model, the teacher network’s parameters are gradually updated to reflect the student network’s parameters, using an exponential moving average [11]. The ViT architecture is employed for both student and teacher networks, where the input image is split into patches, embedded, and an additional learnable class token (CLS) without labels is included to aggregate information [11]. These embeddings are processed through self-attention layers to capture relationships between patches.
Attention-guided erasingFigure 1(b) shows the step-by-step illustration of the AGE data augmentation. After the SSL pretraining, the self-attention mechanisms are carefully analyzed in the final layer’s six attention heads, each focusing on the CLS token [11]. As seen in Fig. 1(b), the attention maps generated by these heads are converted into binary masks through thresholding. These binary masks are used to erase non-attention regions in the image, retaining only the regions of interest to perform AGE [13].
Transfer learning using AGEExamining the activation patterns that most accurately represent the feature of interest across the datasets is crucial. In the AGE method for breast density classification [13], we manually analyzed the activation patterns of each of the six attention heads to understand their relevance to breast tissue characteristics. We then hypothesized that an attention head focusing on fewer than 50 pixels could be identifying regions of dense breast tissue. To test this hypothesis, we analyzed these activation patterns in 10% of our training data set and found that the sixth attention head consistently concentrated on dense areas, suggesting its potential association with breast density [13]. However, for tasks requiring expert domain knowledge, such as abnormality or malignancy classification explored in this work, selecting the optimal attention head that accurately localizes the ROI presents a challenge. Figure 1(c) shows the depiction of the attention head selection during transfer learning using AGE. We treat each attention head as a hyperparameter and evaluate the performance of AGE across six separate runs, using binary masks generated from each of the six attention heads with a random probability during training. The attention head achieving the highest validation F1-score across these runs is selected as the optimal head and used for the final application of AGE. We adopt this selection approach because the imaging presentation of malignancy, such as calcifications or masses, is inherently more complex and less distinct compared to breast density. Additionally, acquiring domain-specific knowledge in the form of pixel-level annotations is generally time-consuming and costly, further complicating the process.
DatasetIn our research, we utilize four distinct datasets consisting of different dataset sizes to efficiently evaluate the AGE augmentation technique: VinDr-Mammo [14], CDD-CESM [15], and two subsets derived from the CBIS-DDSM dataset [16]. These datasets are selected based on the diversity of mammographic modalities they represent. This ensures a broad variety in how the input images manifest the features essential for the image-level and patch-level classification tasks. The aim is to validate the generalizability of our technique by thoroughly assessing the applicability and performance across different image classification tasks.
Breast density classificationThe VinDr-Mammo dataset, which originates from Hospital 108 and Hanoi Medical University Hospital in Hanoi, Vietnam, comprising 20,000 full-field DM from 5,000 patients was utilized for the image-level breast density (A, B, C, D) classification task [14]. The ROI, i.e., dense tissue, appears in varying proportions within the DM image and serves as the input to the DL system. We use this dataset to discuss the results originally published in [13]. It includes both craniocaudal and mediolateral oblique views, thoroughly annotated by expert radiologists for BI-RADS breast density. The dataset was divided into training (72 A, 1,308 B, 10,366 C, 1,854 D), validation (8 A, 220 B, 1,866 C, 306 D), and testing (20 A, 380 B, 3,060 C, 540 D) portions.
Malignancy classificationThe subtracted CEM images from the CDD-CESM dataset are utilized for both image-level and patch-level classification tasks [15]. Various abnormalities appear throughout the image in varying size proportions and lesions are visually enhanced due to the contrast agents used while acquiring the images. The dataset comprises 1,003 CEM images from Cairo University, Egypt, stratified at the patient level into training (75%: 309 normal, 193 benign, 243 malignant), validation (13%: 61 normal, 34 benign, 35 malignant), and testing (12%: 46 normal, 23 benign, 47 malignant) sets [15].
Calcification classificationThe calcification subset of CBIS-DDSM containing ROIs in digitized scanned film mammography (SFM) is then used as the distributions, morphology, and intensities of the calcifications in the dataset vary in proportion to the input ROI image [17]. For the calcification abnormality subset of CBIS-DDSM, the distribution is as follows: training (389 benign without callback, 438 benign, 446 malignant), validation (85 benign without callback, 90 benign, 98 malignant), and testing (67 benign without callback, 130 benign, 129 malignant) [16, 17].
Mass classificationThe CBIS-DDSM data subset consisting of mass abnormality is utilized here, where the shape and presence of masses encompass the entire input ROI patch [16]. The mass abnormality subset is similarly divided, for training (91 benign without a callback, 468 benign, 525 malignant), validation (13 benign without a callback, 109 benign, 112 malignant), and testing (37 benign without a callback, 194 benign, 147 malignant).
Experimental setupFor the SSL pretraining, the original DINO implementation [11] is used for each task, where the ImageNet pretrained ViT-S architecture is used as the backbone for both the student and teacher networks [11].The standard data augmentation techniques reported in the original work such as flipping, color adjustments, blurring, and solarization are reused [11]. The input images are subjected to random resizing and cropping to match the model’s input specifications, with a patch size of 16 for the 224 \(\times \) 224 resolution images. Pretraining is performed with a batch size of 32, suitable for the memory capacity of a single GPU over 300 epochs, and the models are saved at the lowest loss points. We compare our AGE augmentation with a standard random erasing (RE) [18] augmentation during the downstream transfer learning task at various probability values (P) of 0.2, 0.4, 0.6, and 0.8. The probability value indicates the chance that an image will undergo augmentation during training. A classification layer on top of the pretrained teacher ViT-S model for all classification tasks is added and the entire network is finetuned during the transfer learning. All experiments are conducted five times over 100 epochs with a batch size of 8, incorporating early stopping to prevent overfitting. Optimization was performed using a binary cross-entropy loss and a standard Adam optimizer, with a learning rate of \(5e^\) and a weight decay of \(1e^\). A standard set of data augmentations is utilized, as reported in [19].
Table 1 Classification performance for image-level tasks on the test datasets with their respective sizes in brackets. The best results are in bold. Asterisks indicate the statistical significance of AGE over the NE and RE, \(p < 0.0001\)Table 2 Classification performance for patch-level tasks on the test datasets with their respective sizes in brackets. The best results are in bold. Asterisks indicate the statistical significance of AGE over the NE and RE, \(p < 0.0001\), and the plus sign indicates significance with \(p<0.05\)
留言 (0)