
記住我


Approval for this study was obtained from the internal Ethics Review Board of Osaka University Hospital (Suita, Japan). The need for informed consent was waived because of the retrospective nature of this study.
DatasetIn this study, the dataset used in [1] was appropriated. This is composed of 3728 reports for plain head CT conducted at Osaka University Hospital. All of these reports were written in Japanese. These were categorized (Report Importance Category: RIC) into five categories by the agreement of neuroradiologists, according to the importance of the content: Category 0: no findings (15.0%), category 1: minor findings (26.7%), category 2: routine follow-up (44.2%), category 3: careful follow-up (7.7%), and category 4: examination or therapy (6.4%). Two thousand three hundred eighty-five reports (64%) were used as the train dataset, 597 reports (16%) were used as the validation dataset, whereas 746 reports (20%) were used as the test dataset. Since the division into these datasets was performed randomly, the proportions of each category in these datasets are imbalanced, as is the original whole dataset.
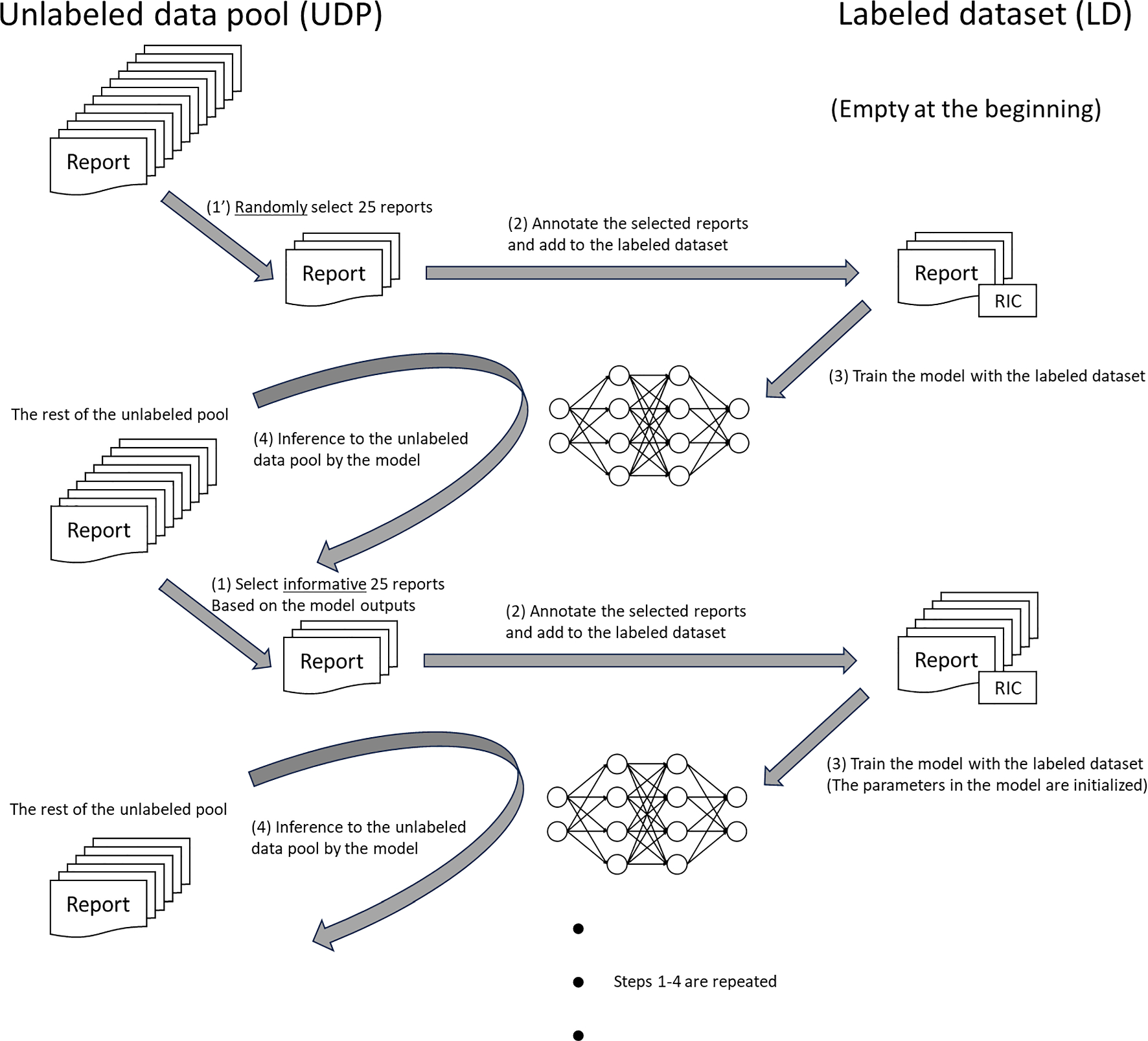
Scenario of active learningThe flowchart of the AL scenario is shown in Fig. 1. Initially, all reports in the train dataset were put into the “unlabeled data pool (UDP)”, whereas the “labeled dataset (LD)” was empty, to assume the unannotated state for all data. (1’) A fixed number (granularity, N: fixed to 25 in this research) of reports were randomly selected from the UDP and (2) added to the LD with the RIC annotation. (3) An NLP model was trained using the LD at that point. Then, (4) the rest data in the UDP were input to the trained model, creating the temporary inference. After that, (1) based on the inference, the informative score (\(\varphi \)) was calculated for each report using AL algorithms (described later), and the most informative N reports were selected from the unlabeled pool. Thus, steps (1)–(4) were repeated until the UDP became empty.
Fig. 1
Workflow of active learning
In this study, UTH-BERT [13] was adopted as the NLP model. This BERT model was pre-trained with medical reports written in Japanese at Tokyo University Hospital and could be regarded as a domain-specific BERT model for Japanese medical texts. A fully connected layer was used to convert the 768-dimensional UTH-BERT output (corresponding to the CLS token) into probabilities for each of the five categories. The learning rate and batch size were fixed to 2e-5 and 4, respectively, according to those used in another study [1]. The model was trained through 10 epochs and the model weights with the least loss for the validation dataset was saved.
Comparison of active learning algorithmsSeven algorithms were used to compare the effectiveness of AL. These algorithms output IS for each report based on the inference by the model.
(a)Random sampling (RS)
This is a control method. In this method, \(\varphi \) are randomly selected.
Uncertainty sampling (US) methods.
The following four methods quantify the model’s lack of confidence in each report. In the following formulae, x represents each report used as input, and \(_|x)\) the i-th highest output of the model (probability of each category) for x.
(b)Least confidence (LC)
Reports with low probability for the highest category are selected.
$$ \varphi \left( x \right) = 1 - P(y_ |x) $$
(c)Marginal sampling (MS)
This method selects reports based on the difference between probabilities for the first and second categories.
$$ \varphi \left( x \right) = P(y_ |x) - P(y_ |x) $$
(d)Ratio of confidence (RC)
This method selects reports based on the ratio of probabilities for the first and second categories.
$$ \varphi \left( x \right) = P(y_ |x)/P(y_ |x) $$
(e)Entropy sampling (ES)
This method calculates entropy based on probabilities for each category. Originally, the higher this value is, the higher the confidence in the model’s classification can be considered; however, the minus sign has been removed from the original definition for the entropy in the following formula to give preference to those with lower values for selection.
$$ \varphi \left( x \right) = \Sigma_^ P(y_ |x) \times \log P(y_ |x) $$
Distance-based sampling (DS)
These methods use not only the data in the UDP but also those in the LD. For each report, UTH-BERT outputs a 768-dimensional vector and those vectors for the labeled data are used to calculate the category center vector (\(_\)) by averaging vectors for each category. For one report (\(x\)) in the UDP, the distance between the corresponding 768-dimensional vector (\(_\)) and each of the category center vectors is calculated and the report that gives the vector furthest from all category center vectors is selected.
Two different methods of measuring distance were employed in this study.
(f)Euclidean distance (ED)
This method calculates the distance between \(_\) and \(_\) using the Euclidean distance.
$$ \varphi \left( x \right) = }_ \left\| - v_ } \right\| $$
(g)Cosine distance (CD)
This method calculates the distance between \(_\) and \(_\) using the cosine similarity.
$$ \varphi \left( x \right) = 1 - }_ \left( \cdot v_ /\left| } \right|} \right| \cdot \left| } \right|} \right|} \right) $$
For each AL method, the trial explained in the “Scenario of active learning” section was repeated ten times changing the initial LD.
Examination of the effects of postponed case introductionEspecially in phases of AL, where the LD is small, the model may not be well trained, and truly informative data may not always be selected by the AL algorithms. In this experiment, we introduced a parameter called postponed case (PC), and, using the AL methods, the highest priority of PC reports was forcibly lowered, preventing those reports from being selected from the UDP.
In this experiment, due to the undesirable results of the DS methods (described in the Results section), only the four US methods were adopted, and PC was changed to 0 (original US methods), 25, 50, 75, 100, 125, and 150. The transition of performance of the models is examined.
Statistical analysisComparison of efficacy of labeled data reduction.To examine the AL efficacy of labeled data reduction, the minimum number of cases required to achieve certain thresholds (accuracy = 0.80, 0.81, 0.82, and 0.83) were compared. (Since seven AL methods were compared, and 10 trials were repeated for each AL method, training with all 2385 reports was conducted 70 times. As described later, since the minimum accuracy was 0.839 among the 70 trials, the maximum threshold was set to 0.83.)
Comparison of accuracy of NLP models with AL methodsIn this research, since 2385 reports existed in the UDP initially, a model corresponding to each of the 96 steps (in the last 96th step, the remaining 10, instead of 25, cases were added to the LD) appeared. For each step, the performance of the model was evaluated using the accuracy for the test dataset and the transition of the accuracy was regarded as the result of the AL method. As described above, we performed the same trial ten times changing the combination of the initial 25 cases in the LD. For each step, the accuracies between two methods were compared using the Mann–Whitney U test, where p value < 0.05 was regarded as significant.
When comparing two AL methods, since there are as many as 96 steps, some of them may have significant differences while others may not, making it difficult to tabulate the overall trend, this study introduces quartiles. The learning process is divided into four groups of 24 steps, and whether each step was significant or not is examined. When comparing two methods A and B in one of the quartiles, the superiority of A over B is assessed by the difference between the number of steps in which A performed significantly better and the number of steps in which B performed significantly better. In this research, we call this value “Superiority Score (SS)”. When focusing on a single step, the probability of the occurrence of a significant difference by chance is at most 0.05, thus by solving the equation below, it can be said that A is significantly superior to B in that quartile when SS is greater than or equal to + 4. On the other hand, when SS is lower than − 4, A is regarded as significantly inferior to B.
$$ \mathop \sum \limits_^ _C_ \times 0.05^ \times 0.95^ < 0.05 $$
The effect of PC introduction was evaluated similarly. AL methods with nonzero PCs introduced were compared to the original (PC = 0) method.
留言 (0)