
記住我
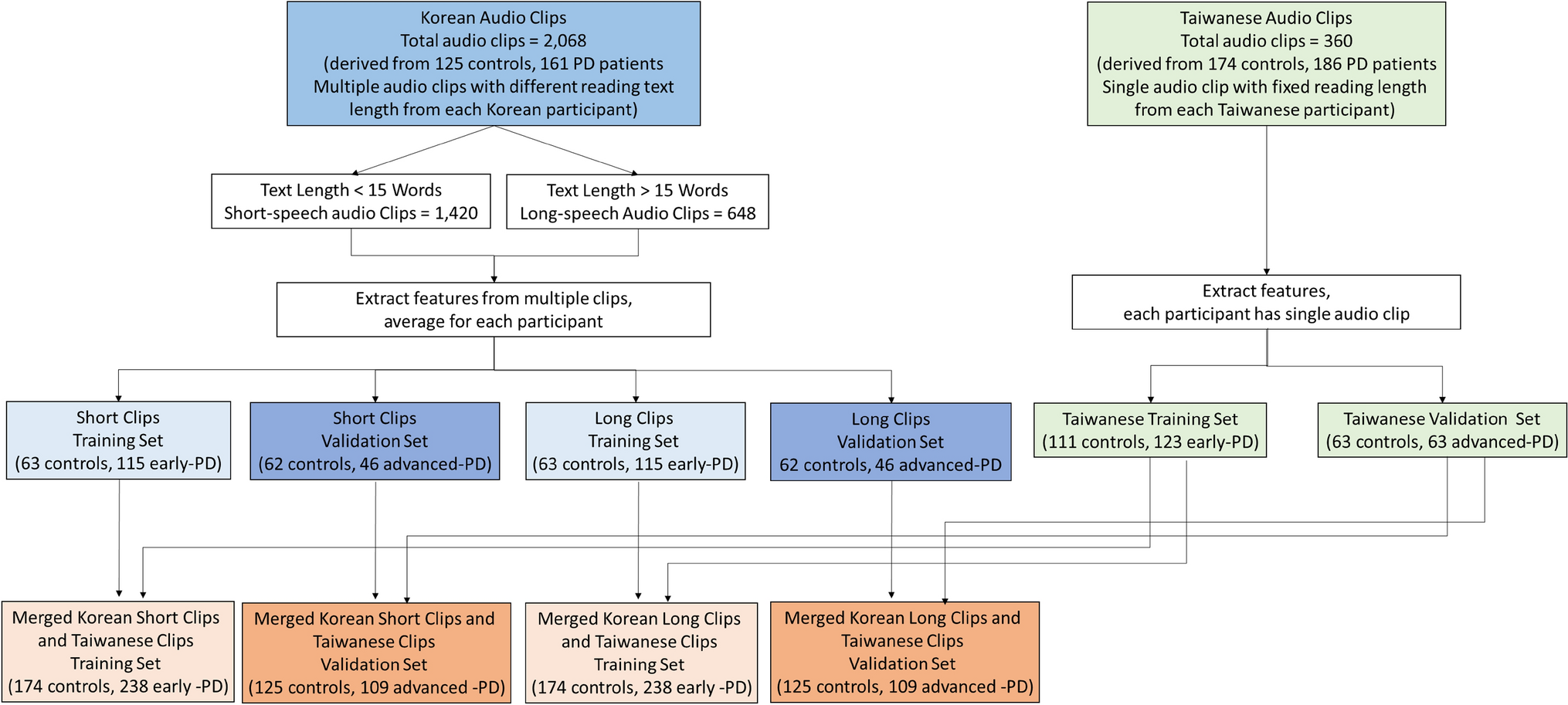
A total of 646 participants, including 299 healthy controls and 347 patients with PD, were recruited from movement disorder clinics of Seoul National University Hospital (125 controls and 161 patients with PD) and National Taiwan University Hospital (174 controls and 186 patients with PD). PD was diagnosed according to the United Kingdom PD Society Brain Bank Clinical Diagnostic Criteria (Hughes et al. 1992). The controls were neurologically unaffected participants who were spouses or friends accompanying the patients with PD. We excluded participants who were illiterate, as well as those with hearing impairments or other non-neurological disorders that could affect the vocal cords. All participants underwent otolaryngologic evaluations. All Korean and Taiwanese participants had received at least 9 years of education, which is the compulsory education requirement in these regions. Among PD patients, early-stage PD was defined as Hoehn–Yahr stage < 2.5 and advanced-stage PD was defined as a Hoehn–Yahr stage ≥ 2.5. All participants provided written informed consent, and the institutional ethics boards of Seoul National University Hospital and National Taiwan University Hospital approved the study.
Speech datasetsMultidisciplinary approach to dataset and task selectionThe selection of speech datasets and tasks was guided by a multidisciplinary team comprising movement disorder specialists, machine learning specialists, and a speech analysis expert. This collaborative approach ensured that the tasks were linguistically and clinically appropriate for identifying PD-related speech changes. Task selection, such as reading speech in Korean and Mandarin, was informed by language-specific methodologies, ensuring the inclusion of tailored tasks critical for capturing distinct linguistic features relevant to PD and the respective languages. Different stimuli were used for Korean and Taiwanese datasets because the two languages belong to different language families (Altaic and Sino-Tibetan, respectively) and exhibit distinct phonetic and linguistic characteristics. Using stimuli that align with each language's natural phonetic structure ensures robust analysis of PD-related speech changes while maintaining linguistic validity.
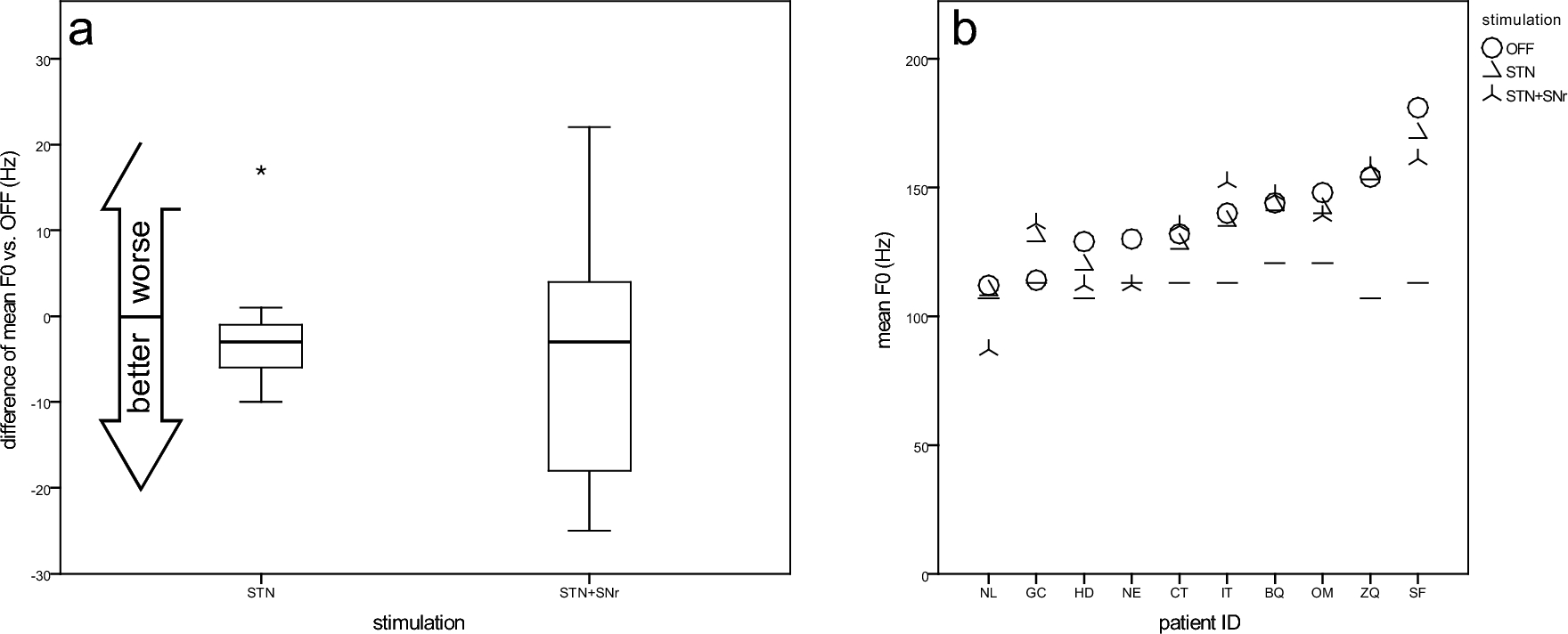
Korean datasetThe Korean dataset included both short and long sentences designed to capture a wide range of phonetic and linguistic contexts. These stimuli were carefully selected to incorporate variations in vowels, consonants, and sentence structures reflective of the Korean language. Additionally, the sentences were chosen to capture natural prosody and syntactic diversity. The Korean speech recordings were gathered from 291 Korean participants, including 125 control individuals and 161 patients with PD. Each participant was asked to perform 12 distinct Korean speech texts (detailed description were shown in Supplementary Data) or speech tasks, including sustained vowel phonation (Naranjo et al. 2017), syllable repetition tasks (Skodda et al. 2013), sentence repetition tasks (Bandini et al. 2016), and reading tasks (Galaz et al. 2016), on the same day during the “on” phase of medication, resulting in a total of 2,068 Korean audio clips. Among the 2,068 Korean audio clips, 1420 clips contained reading text lengths of less than 40 characters (short-speech recordings) and 648 clips contained reading text length exceeding 40 characters (long-speech recordings) (Fig. 1 and Supplementary Table 1). Audio features were extracted from multiple clips, and the average values were calculated for each participant.
Fig. 1
Study design flowchart with two cohorts. In the Korean cohort, participants performed various speech texts, while the Taiwanese participant read a standardized, fixed-length article. Korean short-speech (≦15 syllables) and long-speech (> 15 syllables) recordings were combined with the Taiwanese speech dataset. The merged dataset was then divided into a training set (controls vs. early-stage PD) and a validation set (controls vs. advanced-stage PD) to evaluate the effectiveness of a speech length-based model in distinguishing PD patients from unaffected controls across languages
Taiwanese datasetThe Taiwanese dataset consisted of a single, standardized passage that represents key linguistic features of Taiwanese Mandarin, such as tonal variations and frequent phonemes characteristic of the language. This passage was selected for its linguistic richness, incorporating all major tones and a diverse set of vowels and consonants. It facilitates the analysis of tonal dynamics, which are particularly relevant to Taiwanese Mandarin and are influenced by PD. Taiwanese speech recordings were derived from a published speech dataset of 360 Taiwanese participants, including 174 controls and 186 patients with PD, who were requested to read a standardized article with a fixed-length text consisting of 500 characters (Lim et al. 2022). The 360 Taiwanese audio clips contained standardized long text readings derived from each participant. Among the Taiwanese speech dataset of patients with PD, only speech files recorded during the “on” medication phase were used in the current study.
Recording processAll recordings were conducted in a quiet indoor clinic environment to minimize background noise. While the environment was not a professional soundproof studio, care was taken to minimize external disturbances, with the recording setup kept consistent across participants. Participants were instructed to speak naturally and maintain a steady tone and volume during the tasks. Trained research assistants supervised all recordings, and the same model of smartphone was used for consistency in each dataset. The smartphone microphone was positioned at a consistent distance of 5–35 cm from the participant’s mouth, and this setup was verified before each recording session. Speech data were initially captured in linear PCM format (.wav) with a sampling rate of 44.1 kHz and a 24-bit sample size, then down sampled to 44.1 kHz and 16-bit for uniform processing. These recordings were categorized according to the length of their speech content. Long-speech recordings were characterized by a lack of repetitive words and a minimum of 40 Hangul characters, whereas short-speech recordings were defined by a length of fewer than 40 characters. In Korean, as in Taiwanese, one character represents one syllable.
Dataset merging and model trainingTo evaluate the sensitivity of a cross-lingual speech model in distinguishing patients with Parkinson’s disease (PD) from healthy controls, we combined the Korean and Taiwanese speech datasets. Considering the uneven number of speech datasets derived from each participant in the two cohorts, they were merged in two distinct ways First, the Korean long-speech recordings (≥ 40 Hangul characters) were combined with the Taiwanese dataset (500 characters). Second, the Korean short-speech recordings (< 40 Hangul characters) were merged with the same Taiwanese dataset. Furthermore, the merged datasets were then split into training and testing (validation) sets based on disease stage. The training set included early-stage PD patients (Hoehn–Yahr stage ≤ 2) and healthy controls, while the testing/validation set comprised advanced-stage PD patients (Hoehn–Yahr stage > 2) and an independent group of controls (Fig. 1). The testing data included participants from both cohorts to assess the model's cross-lingual generalizability. This approach provided a unique opportunity to evaluate the model’s effectiveness in distinguishing PD patients from controls across varying speech lengths and linguistic contexts (Fig. 1). By dividing the speech recordings into training (early-stage PD patients and controls) and validation (advanced-stage PD patients and another control group) datasets for each merged configuration, we ensured robust testing of the model’s performance.
All PD patients were receiving levodopa therapy, and the speech was recorded during the “on” phase, such that the motor function and speech of patients with early-stage PD would be similar to those observed in healthy older individuals. Therefore, patients with early-stage PD should be more difficult to differentiate from controls than patients with advanced-stage PD. For this reason, we trained the model with speech features derived from patients with early-stage PD to differentiate them from healthy controls. We reasoned that a model that could discriminate patients with early-stage PD from healthy controls might show optimal diagnostic performance for identifying drug-naïve patients with PD or advanced-stage PD among healthy older individuals.
Speech feature selectionSeveral speech features were used to distinguish patients with PD from healthy controls. Because patients with PD present with hypovolemic and monotonous speech (Lim et al. 2022), speech volume and fundamental frequency (pitch) features were adopted as features that could discriminate patients with PD from controls. Volume represents the vocal intensity of an audio signal, which correlates with the amplitude of the signal. Therefore, we adopted volume variance, pause percentage, fundamental frequency variability, and average fundamental frequency as speech features in our model. Vocal intensity variance was calculated by analyzing variations in the volume of audio frames across the speech sample, while fundamental frequency variance was extracted frame-by-frame using Python’s pysptk library. Pause percentage was derived as the proportion of silent frames to total recording length, with silent frames identified based on a dynamically set threshold. Average fundamental frequency was computed as the mean F0 across voiced frames after pitch tracking. All stimuli were fully analyzed for consistency, using Python-based signal processing tools. While other vocal parameters (e.g., jitter, shimmer, and HNR) are affected by PD, cross-lingual applicability challenges led to their exclusion. The inclusion of speech-related measures aimed to complement acoustic features by capturing linguistic and articulatory characteristics of PD.
In addition to volume and fundamental frequency, intonation, pronunciation, and syllable length vary between the two languages; therefore, we used the ground-truth speech text provided to the participants at recording and the Google Speech-to-Text API, which is versatile and can be applied to all supported languages (Google 2023a, b). We utilized the Google Speech-to-Text API for transcribing the Korean speech dataset into Korean text and Taiwanese Mandarin speech to traditional Mandarin text. After transcription, we measured the following features. (1) Speech Rate: Calculated as the ratio of reading duration to text character length, this measure assesses spoken language efficiency by focusing on the pace of speech, not the overall clip length. A lower ratio indicates faster speech, allowing for accurate comparison across both short and long audio clips. (2) Speech-to-Text Google API Confidence Score: This score reflects the API’s confidence in the accuracy of its transcription. A higher confidence score suggests that the transcribed text is a more accurate representation of the original speech, which is crucial for assessing transcription reliability. (3) Speech-to-Text Word Error Rate (WER): The WER is a standard metric for evaluating speech recognition accuracy. This involves comparing the API-generated transcription with a ground-truth text to quantify discrepancies. A lower WER signifies higher accuracy, indicating the system's effectiveness in converting spoken language into written form. This metric is particularly valuable for evaluating the effects of factors such as background noise, accents, and linguistic variations on transcription accuracy.
Machine learning algorithms and analysesWe used sequential forward feature selection with base classifiers such as Random Forest (Breiman 2001), Support Vector Machine (SVM) (Pisner and Schnyer 2020), and AdaBoost (Freund and Schapire 1997) to train our model. The source code for all classifiers is available in the python science-kit learning library (Buitinck et al. 2013). We implemented the leave-one-out cross-validation (LOOCV) method to reduce both bias and variance in the machine learning models by providing an objective estimate of the model's performance on new data. In LOOCV, the model is trained on all data points except one, and this process is repeated for each data point, ensuring that every observation is used for both training and validation. We compared the performances of these training classifiers based on several key performance metrics. These metrics included the accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUROC) for binary classification. This comprehensive evaluation approach allowed us to assess the effectiveness of each classifier in the context of our study, ensuring a robust and reliable machine learning model.
Statistical analysisContinuous variables are expressed as mean ± standard deviation. For variables where appropriate, we have also included the median and interquartile range in addition to the mean. Categorical variables are expressed as number and percentage. We tested the homogeneity of variances using Levene’s tests. Variables were compared using two-tailed t tests or analysis of variance (ANOVA) when normally distributed, or with the non-parametric t-test when assumptions of normality or homoscedasticity were violated. The diagnostic performance of the models is expressed as the AUROC and 95% confidence interval (95% CI). All statistical analyses were performed using SAS (version 9.4; Cary, NC, USA) and GraphPad Prism (version 9.0.0; San Diego, California, USA). P values < 0 0.05 were considered statistically significant.
留言 (0)