
記住我

To optimize patient outcomes in chronic obstructive pulmonary disease (COPD), it is important that decisions on funding and reimbursement made by health technology assessment (HTA) bodies and payers are based on a thorough appraisal of the evidence for efficacy of treatments [1, 2]. It is also important that decisions made by healthcare professionals (HCPs) and management recommendations in national and international guidelines are based on the most up-to-date and highest-quality evidence available [3,4,5,6,7].
Randomized controlled trials (RCTs) demonstrate the efficacy of therapies, but often these studies do not compare all available treatments or provide information on how individual treatments fit into treatment algorithms [8]. RCTs usually compare the intervention of interest to an established treatment and/or placebo and are seldom replicated. RCTs examining the same treatments can also sometimes result in contradictory conclusions—this can be due to different trial designs or populations, but also as a result of random variation [9, 10]. Synthesizing evidence from multiple RCTs provides a balanced and comprehensive assessment of all available evidence on a given topic, as well as a “global summary” of findings. This is a fundamental way in which HTA bodies, payers, providers, and those developing clinical management guidelines make informed decisions [1, 3, 4, 11].
Various methods of evidence synthesis can be used in the development of management recommendations and HTA appraisals/reimbursement decisions, and HTAs and payers often have set preferred approaches. For example, the National Institute for Health and Care Excellence (NICE) Technical Support Documents (TSDs) on evidence synthesis make recommendations for preparing, reviewing, and appraising submissions to NICE [12]. However, the TSDs do not attempt to recommend the form that the analysis must take or the methods to be used. Any methods fulfilling the required properties are valid; the appropriateness of the approaches often depends upon the data available [13]. However, methodological problems can hinder interpretation of findings or lead to invalid summary estimates [14,15,16,17]. Such problems include inappropriate searching and selection of relevant trials for inclusion in analyses [18, 19], lack of publication bias assessment or evidence appraisal [20, 21], poor reporting of methodology [14], and drawing inappropriate or unsupported conclusions [22, 23].
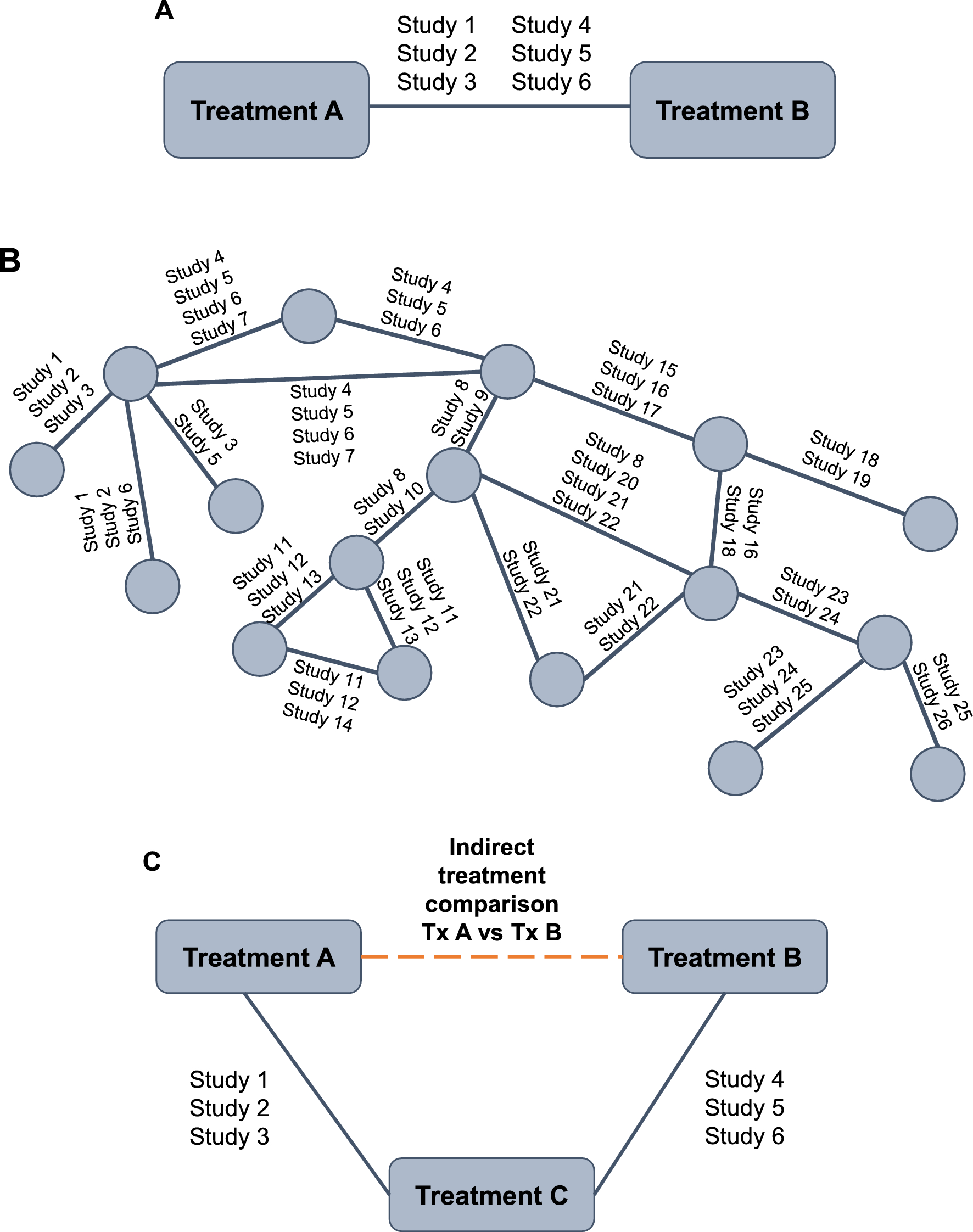
Meta-analysis of RCTs is now widely used to provide a summary measure of effect for an individual treatment as part of evidence synthesis [13]. Pairwise meta-analysis compares the efficacy or safety of two treatments that have been directly compared in head-to-head clinical trials, assuming the population and outcomes are comparable across trials [13, 24, 25] (Fig. 1A). A “network” diagram is constructed, which consists of “nodes” representing interventions and “lines” representing available direct comparisons between interventions (Fig. 1B) [26]. The methodology for performing pairwise meta-analysis is well established and HCPs are familiar with the outputs seen in publications such as Cochrane reviews [27]. All evidence comparing the two treatments is combined and statistical methods are used to calculate a “pooled treatment effect”, which can help inform comparative efficacy and/or safety of interventions. Common measures generated via meta-analysis include odds ratio (OR; odds of an event in the treatment group vs odds of the event in the control group); relative risk (absolute risk in the treatment group vs absolute risk in the control group); and risk difference (difference between the observed risks [proportions of individuals with the outcome of interest] in the treatment group and the control group).
Fig. 1
A Pairwise meta-analysis; B Network meta-analysis; C Indirect treatment comparison. Tx treatment
In our example, a range of molecules in different therapeutic classes and different inhaler devices are available for the treatment of COPD [28] and new therapies based on combinations of these molecules have been developed and approved over recent years. Assessing the relative efficacy and effectiveness of these treatments within and between classes of monotherapy, dual, and triple therapy is challenging but important.
Sometimes, RCTs are not available to inform clinically important comparisons, such as the comparative efficacy of single-inhaler triple therapies for the treatment of COPD, and it is highly unlikely any will be undertaken. To address this problem, meta-analysis methods have been developed, which allow indirect comparisons of treatments by assessing their relative efficacy versus a common comparator using data from multiple studies [24, 29, 30] (Fig. 1C). In effect, this methodology allows researchers and decision makers to ask additional research questions beyond those originally studied. These indirect treatment comparisons (ITCs) are increasingly used by HTA bodies that are interested in the costs and benefits of the entire algorithm of treatments available (e.g., Pharmaceutical Benefits Advisory Committee in Australia, Canadian Agency for Drugs and Technologies in Health, NICE in the United Kingdom) [13, 31,32,33]. ITCs are able to inform decision makers of the relative effects of different medicines on individual outcomes, and provide a hierarchy of competing treatments, without compromising the rigor of the original RCT.
A pairwise meta-analysis of all relevant RCTs may be judged as being the highest level of evidence (if the analysis is of sufficient design quality) [5, 34]. Network meta-analysis (NMA) allows the simultaneous analysis of direct (head-to-head) and indirect (through a common comparator) data and is less prone to confounding bias than cohort or observational studies [24, 35].
With an increasing use of ITCs to inform clinical decisions, it is important that HCPs are able to critically appraise published analyses. Therefore, the purpose of this tutorial is to fill an important gap in the literature surrounding this topic, by providing an overview of NMA as an evidence synthesis method with a worked example of COPD pharmacotherapy. This tutorial will outline key considerations when planning, conducting, and interpreting NMAs. The tutorial will end with a simple illustrative example of different NMA methodologies using simulated data to illustrate their impact on the conclusions.
The basics of evidence synthesisStep 1: a systematic literature reviewPrior to conducting a meta-analysis, all relevant RCTs in the research area must be identified through a systematic literature review (SLR). This ensures that all relevant studies are systematically identified for inclusion or exclusion in the analysis.
The SLR should follow best practice methodology, including a priori registration with the International Prospective Register of Systematic Reviews (PROSPERO) [36], and should be communicated using the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines [37]. Cochrane, the gold standard, recommends that the search should be based on a pre-defined search string (specific for each database) and all records identified from the searches must be evaluated for their eligibility for inclusion, usually defined by the research question of interest [38]. Research questions are defined using the population, intervention, comparator, outcome, setting (PICOS) framework (Table 1). Other criteria, such as time horizon and language of studies, should also be pre-specified before the SLR is carried out.
A non-systematic review introduces a high risk of bias, even before an ITC is completed. For example, exclusion of studies based on their design (e.g., those with placebo or no treatment arms) or restricting the inclusion of trials to those undertaken in a particular location or time period can have a significant effect on the conclusions of the analysis [39]. Theoretically, if the excluded trials are similar to those included, their omission will not have any systematic impact on the estimates, although it will lead to wider confidence intervals. However, if the excluded trials are different from those included, their omission may cause an over- or under-estimation of treatment effect. As such, the research question must be closely related to the inclusion and exclusion criteria, and all of these elements impact the application of study conclusions.
Step 2: data extraction and meta-analysisOnce all relevant studies have been identified, data should be extracted, and a quality assessment/risk of bias completed. A gold standard framework for assessing risk of bias is the Revised Cochrane risk-of-bias tool for randomized trials (RoB 2) [40]. Bias can occur when there are flaws in the design, conduct, analysis, and reporting of randomized trials, causing the study findings to be underestimated or overestimated. This is important for transparency of results; if a large number of included studies are deemed as having a high risk of bias, then overall findings of any combination of these studies should be interpreted with caution [41]. It is recommended that quality assessment and data extraction should be completed independently by at least two reviewers [42].
An overview of the different approaches to network meta-analysisNMA/multiple treatment comparison (MTC) allows the simultaneous evaluation of direct and indirect evidence across multiple treatments and studies (example in Fig. 1B). Using NMA, the identity of each treatment can be preserved (i.e., different doses and/or co-treatments), with no requirement to combine (pool) different treatment doses or combinations [43]. Other treatments that are not necessarily of interest to the research question can be included in the network of comparisons to provide additional evidence (e.g., to ‘connect’ other treatments into the network that otherwise would not be connected by providing a common comparator) [43]. All treatments in an NMA can be compared, providing they are linked (either directly or indirectly) in the final network. In some cases, the researcher may wish to compare treatments that are not linked either directly or indirectly within the study network. In this case, other methods such as matching-adjusted indirect comparisons (MAIC) can be used to make indirect comparisons [11].
Key assumptions of NMAFour assumptions are fundamental to NMA: similarity, transitivity, consistency, and homogeneity [4, 11, 26]. An overview of these assumptions is shown in Table 2.
Table 2 Key assumptions of NMASimilarityStudies included in an NMA must be similar. Similarity includes both clinical and methodological similarity and is based on clinical judgement and knowledge rather than statistical methods. Visualizing relevant patient characteristics (e.g., age, sex, and disease severity) across all trials included in the NMA using a summary table or showing covariate distribution via a scatter plot can help identify dissimilarity between studies (i.e., with outlying data points potentially indicating a violation of the similarity assumption) [4, 44]. Studies brought together in a network must have a similar research question (PICOS) to be pooled together without affecting effect estimations (i.e., the estimated impact of a treatment on the outcome of interest or on the association between variables). If two studies are adequately similar (e.g., mean age ranging between 45 and 60 years), the relative effect of one treatment versus placebo should remain unchanged if tested under the conditions of the other treatment versus placebo.
TransitivityTransitivity implies that there are no systematic differences between the included comparisons other than the interventions being compared [26]. For example, intervention A must be similar when it appears in A versus B studies and A versus C studies with respect to all patient and study characteristics that may affect the two relative effects. Although clinical and methodological differences between studies are inevitable, prior to conducting NMA, it should be assessed whether such imbalances are considered large enough to potentially violate the transitivity assumption (e.g., the degree of lung function impairment can heavily impact results in COPD—if some studies contain mostly patients with mild lung function impairment and others include patients with more severe lung function impairment, the transitivity assumption may be violated) [26].
ConsistencyNetworks should be consistent, i.e., there should be agreement between direct (RCT) and indirect (based on a common comparator) evidence within a network [44]. Combining inconsistent evidence is inappropriate and may lead to a biased result—either an under- or overestimation of treatment effect. For closed loops within an NMA (i.e., both direct and indirect comparisons are possible; Fig. 2), inconsistency assessment can be conducted. If both direct and indirect estimations are aligned, the network can be considered consistent.
Fig. 2
A closed loop with three treatments. RCT randomized controlled trial
HomogeneityStudies collated in an SLR will inevitably have some level of variability between them, in terms of patient population, interventions/outcomes of interest, or study design/methodological differences. Even when selected using systematic criteria, significant differences in effect modifiers can still be present. Studies may also differ in the way in which the outcomes were measured or defined, the concomitant medications allowed, the length of follow-up, or the timeframe during which the studies were conducted. As in pairwise analyses, homogeneity between studies included in an NMA must be considered. Homogeneity can be assessed in cases where identical treatment comparisons are made and multiple data sources are available. Imbalances in population, interventions, outcomes, and study design across direct and indirect comparisons in an NMA can lead to biased indirect estimations [45, 46].
Overview of NMA methodsThere are two common frameworks of NMA: frequentist (including Bucher ITC) and Bayesian. The most frequently used method in the literature is Bayesian NMA, followed by frequentist NMA, and then Bucher ITC. Bucher ITC is based on simple equations whilst frequentist and Bayesian NMA are based on more complex methods (generalized linear models).
Bucher ITCThe method described by Bucher and colleagues in 1997 is an ITC-based approach using simple equations (no statistical model is required) [47]. The indirect comparison of treatment A versus treatment B is estimated by comparing the treatment effects of treatment A and treatment B relative to a common comparator (treatment C; example Fig. 1C) [47]. This allows the comparison of treatments with no head-to-head evidence, whilst preserving the randomization of the original RCTs. This is often the method of choice if evidence is limited (e.g., comparison of just two interventions [48,49,50]). For example, in the case of three treatments (treatment A, B, and C), the indirect treatment effect of treatment A versus treatment B could be estimated as the treatment effect of A versus a common comparator (treatment C) minus the treatment effect of B versus treatment C [47]. No pooled standard error or standard deviation can be calculated (see Additional file 1, section 1.1). This method may also be the most appropriate if potential effect modifiers vary between studies, and risk introducing bias into the analysis [51]. In larger networks of evidence, indirect comparisons of interventions connected through longer paths can be conducted through multiple steps. However, adding many steps between treatments increases the uncertainty of the estimation.
The advantage of the Bucher ITC is that it is based on simple equations and relatively straightforward to conduct. A key limitation is its unsuitability for performing ITC with more complex networks of treatments with multi-arm studies. The Bucher ITC method is recommended by multiple HTA organizations as a preferred approach for conducting cross-trial ITCs [52]. See Additional file 1, section 1.1 for further information. Recent examples of studies conducted using a Bucher ITC approach in a non-COPD context include Akkoç 2023 [51], Cruz 2023 [50], Merkel 2023 [52], and Pinter 2022 [49].
Frequentist NMAFrequentist NMA uses the approach most familiar to clinicians, in which measures are thought to have a fixed, unvarying (but unknown) value, without a probability distribution. Frequentist methodologies calculate confidence intervals for the value, or significance tests of hypotheses concerning it. Frequentist NMA is based on generalized linear models and uses weighted least squares regression (LSR; see Additional file 1, section 1.2 for further details).
Frequentist analysis is based solely on observed data. Hypothesis testing is conducted, with the null hypothesis being ‘no statistically significant difference between treatments’. Results are presented as estimated relative effects (mean difference, OR, etc., and a 95% confidence interval [CI; i.e., if the experiment was repeated 100 times, the true value would be covered by the interval 95 times]). P-scores can be calculated to rank treatments and results are interpreted as showing a statistically significant difference or absence thereof. Frequentist analysis is considered more conservative than a standard Bayesian NMA and corresponding 95% intervals are usually narrower.
A frequentist analysis can be implemented relatively straightforwardly using R, Stata, or Python, and there are several packages available, which make the analysis easier. The simplicity of the model can be a deciding factor in choosing frequentist over a Bayesian approach [53]. Advantages of the frequentist method are its suitability for sparse networks of evidence and the fact that the interpretation of classical statistics is more familiar to clinicians. Providing heterogeneity is moderate or low, the estimation bias is considered lower using a frequentist model than with other methods [54]. The main limitation is the inability to incorporate any additional information that may already be known about the parameter of interest (e.g., previously observed evidence from pilot or observational studies obtained through expert clinician opinion) into the analysis. Recent examples of studies conducted using a frequentist approach in a non-COPD context include: Karam [55], Lampl [53], Recchia [56], Shen [57], and Zhang [54].
Bayesian NMABayesian methods are based on the idea that unknown quantities, such as forced expiratory volume in one second (FEV1) differences between treatments, have probability distributions. Bayesian NMA is also based on generalized linear models; however, the Bayesian approach is deemed more flexible than the frequentist approach as it also allows the incorporation of additional information into the model, in the form of prior distributions or ‘priors’. A prior is any external information that is already known or believed about the parameter of interest (for example, additional observational study data on the distribution of change from baseline in FEV1), and it represents the uncertainty about the parameter of interest before the current data are examined. The prior distribution is then updated to produce the posterior distribution by ‘learni
留言 (0)