During recent years, TIRADSs have gained worldwide acceptance because of their proven reliability and high utility in clinical practice. Thyroid and thyroid-focused international societies are making major efforts to build a unique joint TIRADS. Since current TIRADSs [2,3,4] include different terminologies to define the same descriptors, the goal of the International TIRADS project is to develop a generalizable lexicon [7]. Furthermore, numerous attempts at computerized analysis of both images and written texts are underway. It is therefore foreseeable that artificial intelligence (AI) may soon enter the management of thyroid US examination. Therefore, the performance of non-medical professionals, specifically CSs, is of enormous relevance for the era of AI-assisted thyroid US analysis.
The present study was undertaken to evaluate the accuracy of a CS using physicians as a gold standard. The results of this study can be summarized as follows. First, the CS performance for ACR-TIRADS was optimal, showing complete agreement with the physicians. However, significant inter-observer disagreement was found when the CS used EU- and, especially, K-TIRADS. Second, there were US scenarios that the CS could not assess according to EU- or K-TIRADS. Almost all US descriptors included in EU- and K-TIRADS were retrieved in the non-concordant cases.
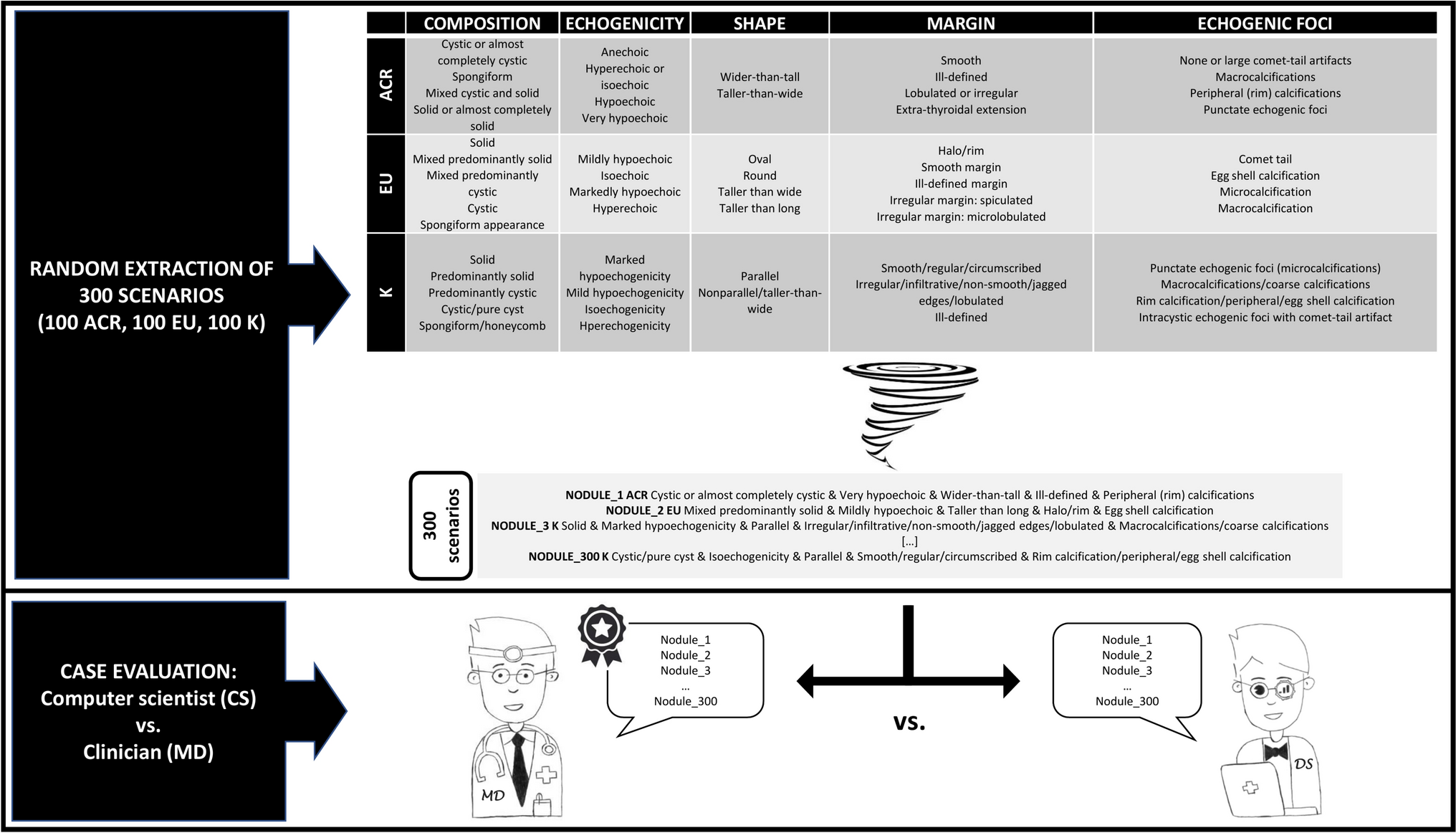
To the best of our knowledge, this is the first study analyzing the performance of non-medical personnel in assessing the RoM of TNs according to US TIRADS categories and descriptors. In addition, previous studies investigating inter-observer variability between medical operators included cases with frozen US images and not their written descriptions [8,9,10]. Solymosi et al. evaluated the inter-observer variability between expert investigators in the judgment of ultrasound characteristics on video recording, and found a Cohen κ ranging between 0.26 and 0.71 [8]. Persichetti et al. analyzed the inter-observer variability between raters in assessing TNs according to TIRADS and found Cohen κ 0.42 for ACR-TIRADS and 0.39 for EU-TIRADS [9]. Grani et al. evaluated the inter-observer variability in indicating FNAC according to ACR-TIRADS, EU-TIRADS, and K-TIRADS and found Cohen κ 0.61, 0.68, and 0.82, respectively [10]. Here, we aimed to explore the confidence of a CS in TIRADS terminology. Since the TIRADS lexicon is a crucial issue in the development of I-TIRADS, and considering that online sites and applications have been diffused to furnish US operators (and patients) with tools to stratify the RoMs of TNs, the present findings are of interest for clinical thyroidologists and computer operators/AI specialists. Accordingly, the findings we observed merit careful discussion.
The CS’s performance was optimal when using ACR-TIRADS, which is certainly correlated with the fact that this is a point-based system. The descriptors of the categories of ACR-TIRADS are attributed a score ranging from 0 to 3; and summing the scores of the descriptors gives a final classification of the nodule across the risk categories from TR1 (benign) to TR5 (highly suspicious). This system structure facilitates risk assessment, including that by the CS, and this may be in some part due to the “mathematical” structure of the terminology.
However, the CS showed lower performance using the EU- and K-TIRADS. Both the EU- and K-TIRADS are pattern-based systems. The European system was basically conceived to discriminate high-risk cases; the presence of at least one high-risk feature classifies a TN as 5 (high risk) in EU-TIRADS. Since the US category “shape” was the most prevalent (10/19 non-concordant cases were oval and the remaining 9/19 were round), we should consider that this terminology may be confounding for non-medical figures.
The Korean system allows stratification the RoMs of TNs by a combination of descriptors. As with EU-TIRADS, the category “shape” was the most frequent between the non-concordant cases (29 parallel and 28 nonparallel/taller-than-wide).
Considering the moderate inter-observer agreement between physicians generally found in previous studies including thyroid US frozen images or clips [8,9,10], the present results obtained on terminology-based assessment are surprising. The agreement found between CSs and physicians in assessing TNs according to TIRADS terminology, especially ACR-TIRADS, should furnish a good base to develop further projects of AI. Basically, AI reads and learns after understanding data contained in online documents. Initially, researchers developed algorithms that imitated reasoning that humans use to solve problems. Algorithms are based on written language (informatic, clinical, popular, etc.) constantly changing according to human progress. Then, the role of humans remains essential to keep AI as much as possible autonomous in learning and developing further decisional processes. From this point of view, physicians should share their advancements with CSs and professionals involved in AI development. The present study elucidates that, currently, CSs can be aware of classification systems when the latter are conceived with a “mathematical” structure.
The prevalence of US descriptors in discordant cases between CS and physician can also be discussed on the basis of studies evaluating the inter-observer agreement between clinicians. At first glance (see Table 2), in the present study shape was the most frequent issue recorded in non-concordant cases for both EU- and K-TIRADS; and other issues such as composition, margin, and echogenic foci were often recorded in these cases. This finding seems comparable to that recorded in studies evaluating the inter-observer agreement between clinicians in assessing the single US features [11, 12, 13]. Considering that the TIRADSs were introduced just on the basis of those results with the aim to reduce the inter-observer variability between operators, the present study intrinsically confirms the need for classification systems as TIRADS. When more raters classify TNs according to their single characteristics, their variability can be higher. This should be true also for non-medical professionals depending on the terminology used to report the descriptors.
To summarize the present results, CSs can correctly interpret the lexicon of ACR-TIRADS, while this is not the case for EU- and K-TIRADS. This new data corroborates the clinical results for the three TIRADSs, which were conceived in different cultural contexts, that show different assessments of TNs [14]. In any case, it must be underlined that non-medical personnel may attempt to assess the RoMs of TNs using their written descriptions only if the descriptions are complete for all categories. Partial description of TNs including only some categories cannot supply adequate information to apply TIRADS.
The present study has potential limitations. First, the TIRADS risk classes were differently represented in the 300 cases. However, the scenarios were deliberately randomly selected to avoid the bias of predictable series. Second, the US categories for ACR-TIRADS are clearly defined as composition, echogenicity, shape, margin, and echogenic foci; while EU- and K-TIRADS do not define them as such. However, the US descriptors for the European and Korean systems allow them to be categorized comparably to ACR-TIRADS.
In conclusion, the present study shows that CSs are confident with the ACR-TIRADS lexicon and structure, and they can correctly classify TNs based on their description. This is not the case for EU- and K-TIRADS, probably because they are pattern-based systems requiring medical training.



留言 (0)