Data splitting
Recommendations: The dataset should be split into training, validation and testing sets, and the ratio of the division clearly reported (obligatory).
* A common practice is to allocate 70% of the data for training, 15% for validation, and 15% for testing [21]. If alternative ratios are chosen, an explanation should be provided. Proper data splitting is crucial for developing a robust model (training set), fine-tuning model parameters (validation set), and getting an unbiased estimate of model performance (testing set). Furthermore, the use of stratified shuffle split is advised to ensure a proportional representation of categories within each subset of data; afterward, such a dataset could be evaluated using K-fold cross-validation.
Model selection
Recommendations: The criteria used for model selection should be clearly described. This might include the data characteristics, problem domain, and prior performance metrics (preferably).
Model finetuning
Recommendations: Model fine-tuning entails adjusting the model parameters to enhance its performance, often through hyperparameter selection. If hyperparameter tuning is implemented, the methodology should be clearly described (preferably).
* Initial boundaries for hyperparameters should be established through a trial-and-error approach. Subsequently, metaheuristic (e.g., genetic algorithms) or Bayesian methods may be employed to identify optimal hyperparameter values [22]. It should be noted that, according to the no free lunch theorem, a universal ML approach applicable to all datasets does not exist, therefore hyper-parameters’ optimization is necessary and metaheuristics proved to be very efficient in solving this non-deterministic polynomial hard task.
Overfitting
Recommendations: Methods used to control overfitting should be clearly described, such as regularization techniques and model simplification strategies (preferably).
* Overfitting is a common challenge in machine learning where a model learns noise instead of underlying patterns, leading to poor performance on unseen data [23]. To mitigate overfitting, it is recommended to use regularization techniques such as L1 and L2, which add penalties to the model’s complexity, and to implement early stopping, which halts training when validation performance declines. Adopting simpler models, utilizing data augmentation to increase training data diversity, and employing cross-validation methods like K-fold are also beneficial strategies. Continuous monitoring and evaluation of model performance on external datasets further help assess generalizability and reduce overfitting risks. By combining these approaches, more robust and reliable machine learning models can be developed. In case some of the mentioned techniques were used, it is necessary to state and explain the implementation procedure.
Model performance evaluation
Recommendations: Reporting accuracy and confusion matrices for all the datasets (training, validation and test) (obligatory); Reporting the area under the curve (AUC) of the Receiver Operating Characteristic (ROC) curve, F1 score, sensitivity, and specificity (preferably).
* Authors should clearly articulate the accuracy of the model and contextualize this value within the specific clinical or research setting [24]. A discussion should include how accuracy relates to the overall effectiveness of the model and the potential implications of its limitations, especially in scenarios involving imbalanced datasets. The confusion matrix should be leveraged to provide insights into the model’s performance across different classes. Authors are encouraged to analyze the values within the confusion matrix, focusing on true positives, false positives, true negatives, and false negatives. By interpreting these results, authors can identify specific strengths and weaknesses of the model, particularly how it may impact clinical decision-making. In discussing the F1-score, authors should focus on the balance between precision and recall, exploring how the obtained value reflects the model’s reliability. Insights into what the F1-score indicates about the model’s performance should be provided, helping readers understand its relevance in practical applications. Precision and recall should also be highlighted, with authors discussing the values obtained for these metrics and their implications for identifying positive cases. An exploration of the trade-offs between these two metrics can enhance understanding of the model’s performance, particularly in critical scenarios where both false positives and false negatives are significant concerns. The AUC is another vital aspect that should be discussed in terms of its implications for model discrimination. Authors should examine the AUC value and its relevance in assessing how well the model can differentiate between classes, emphasizing its role as a complementary metric to accuracy. Lastly, the discussion of the ROC curve and its AUC should emphasize the insights these tools provide regarding the model’s sensitivity and specificity. Authors should interpret the ROC curve concerning the obtained values, discussing what these results suggest about the model’s practical utility.
External validation
Recommendations: In ML investigations, model validation across new clinical settings is crucial. Many of ML’s biggest issues involve ‘overfitting’, where a model properly explains a training data set but fails to generalize. Showing that a model works in another patient cohort in the same healthcare system is important, but showing it works in a different setting is preferable. Replication is just the start of a protracted validation and dissemination process that depends on decades of diagnostics development experience [25,26,27] (preferably).
Feature importance
Recommendations: It is recommended that feature importance metrics be clearly presented and interpreted to enhance the transparency and interpretability of the model (preferably).
* Common methods for assessing feature importance include permutation importance, Gini importance, or Mean Decrease Impurity [28]. Understanding feature importance is crucial for identifying key predictors, guiding feature selection, and uncovering potential biomarkers or insights that can inform clinical decision-making. Additionally, presenting visualizations of feature importance, such as bar plots, can facilitate better understanding and aid in the interpretation of model predictions. Finally, ML models need to produce transparent explanations to effectively manage the benefits of ML methodology and allow the discovery of biomarkers and new predictors.

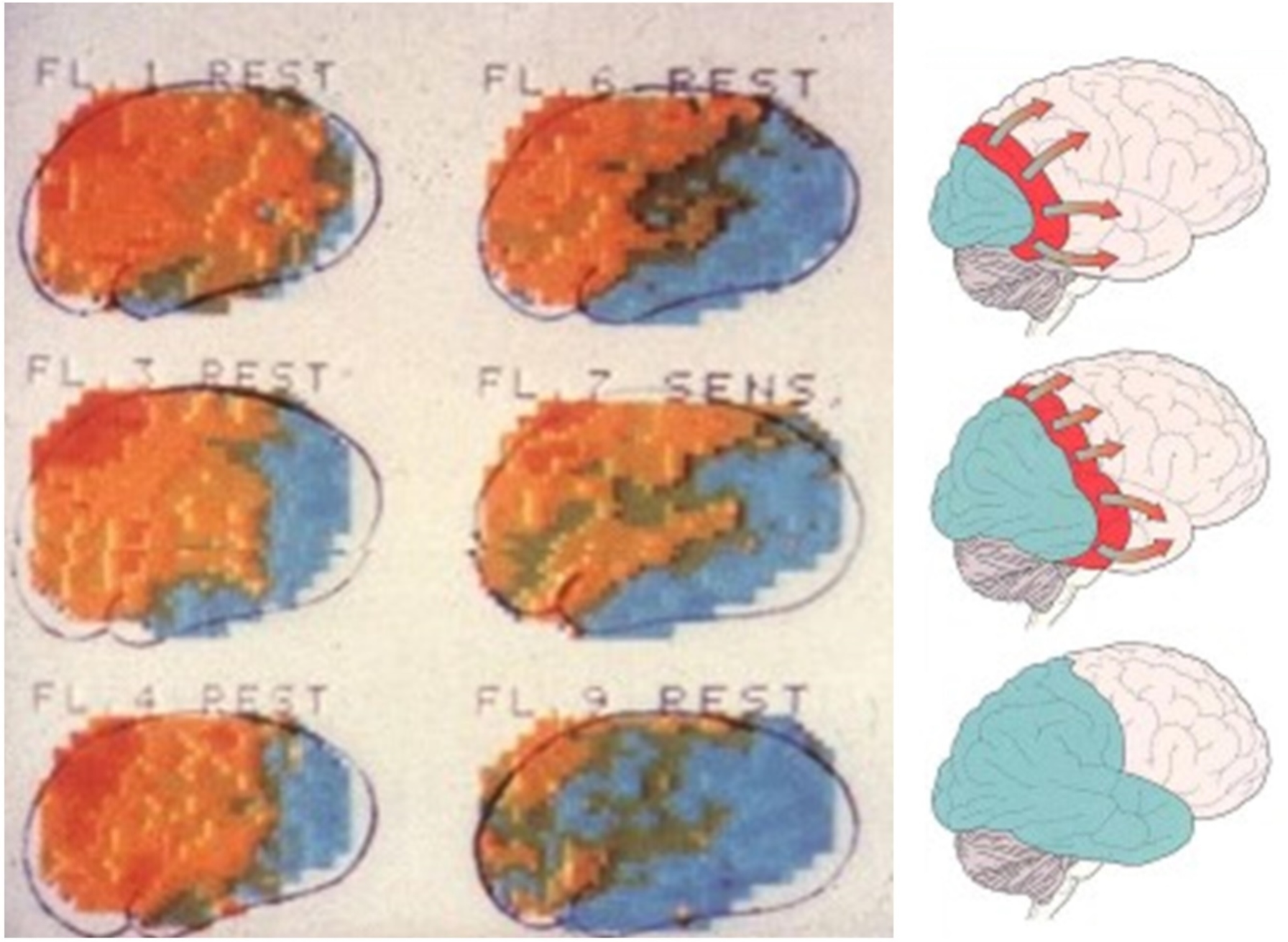
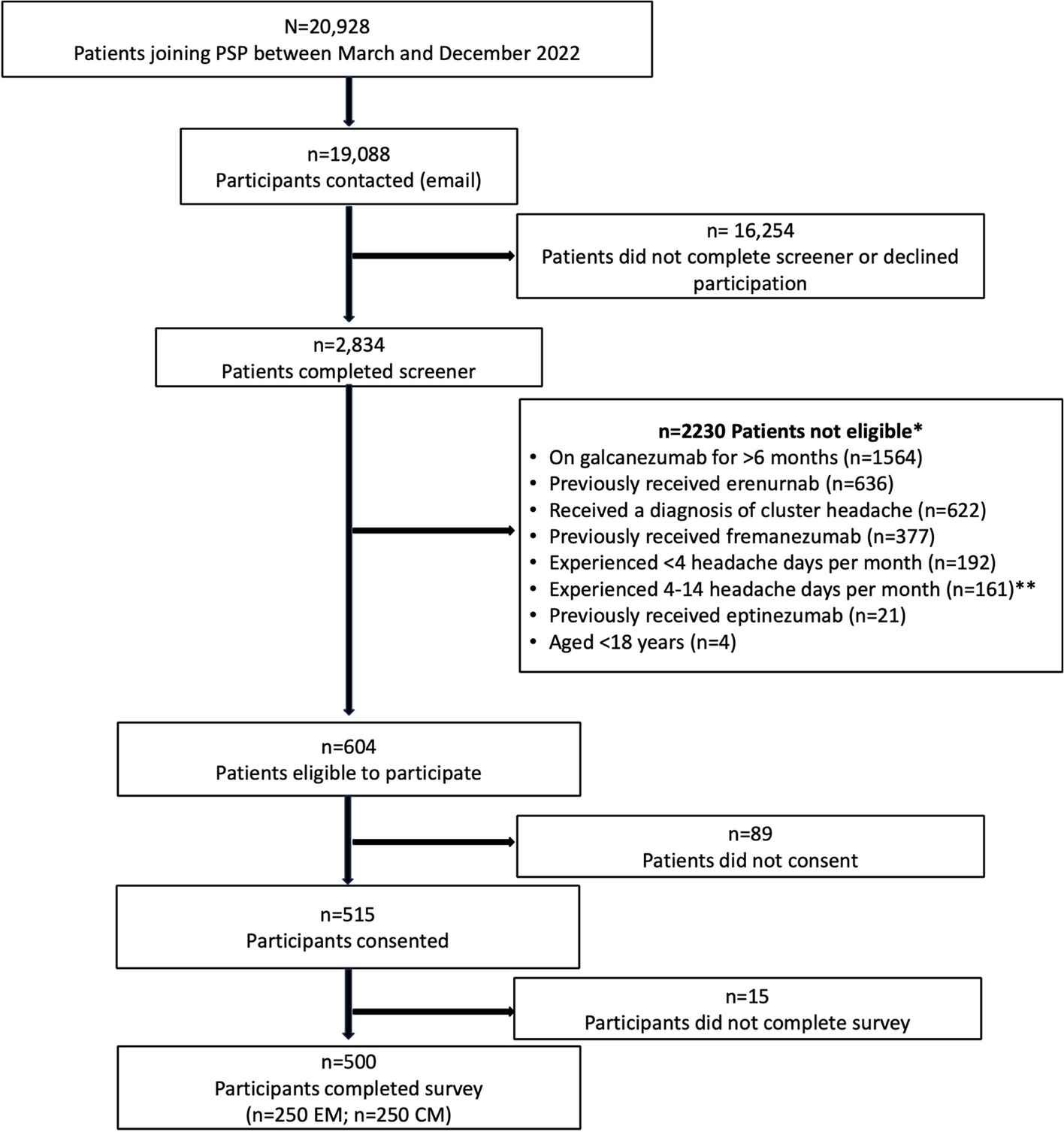
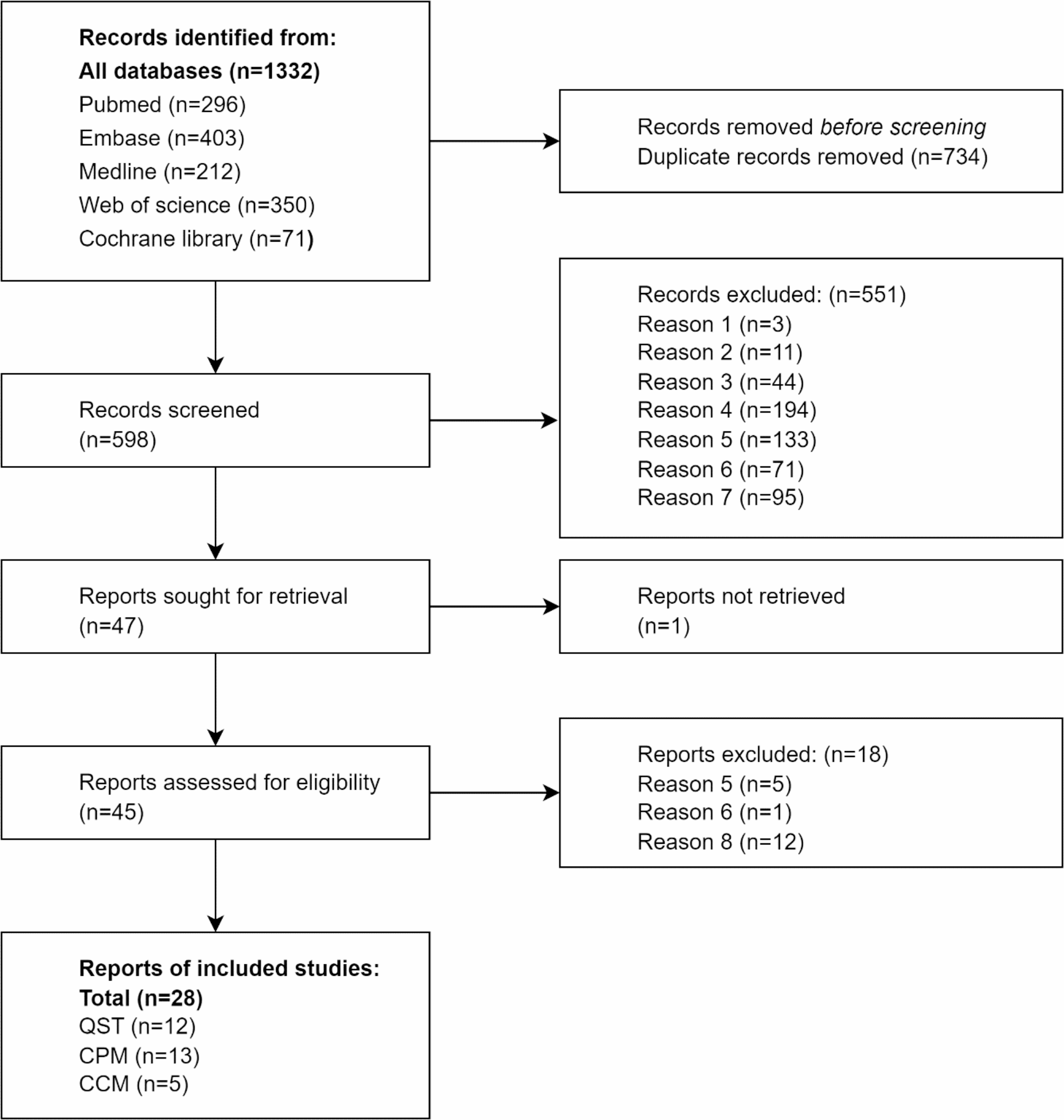
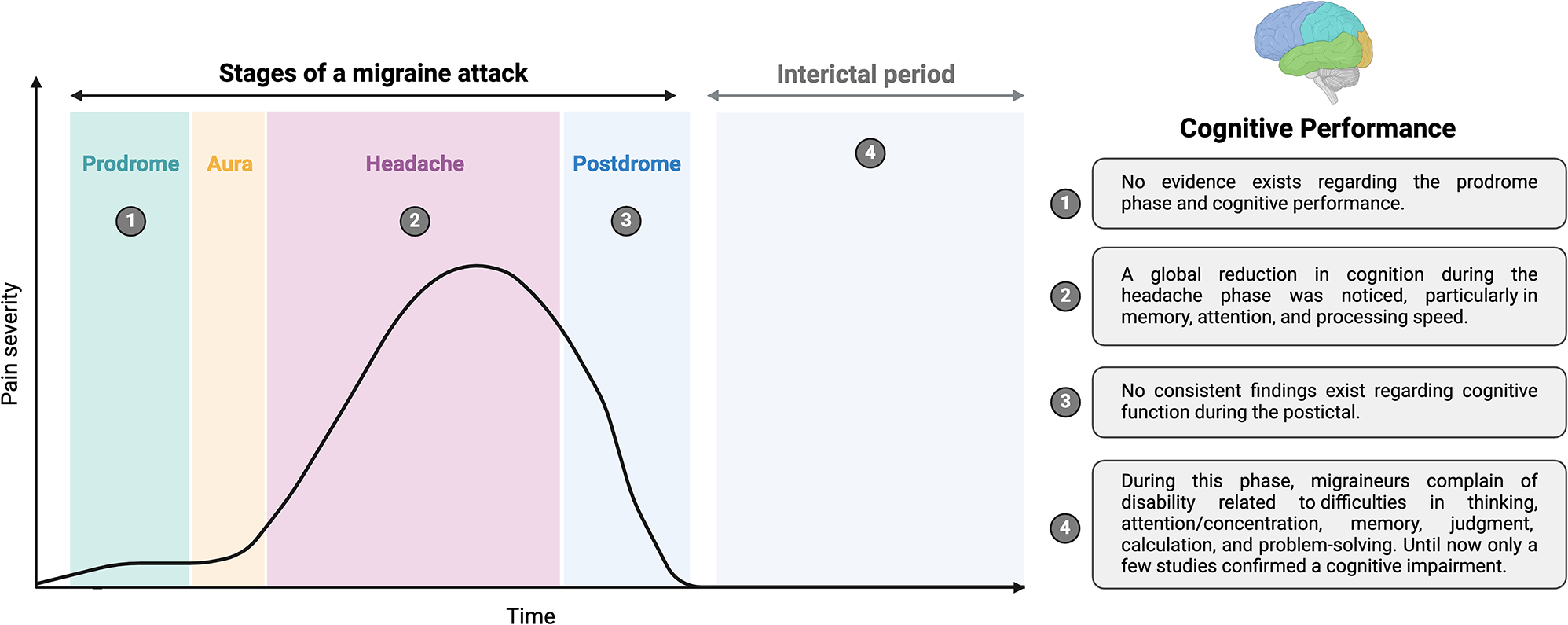
留言 (0)