
記住我
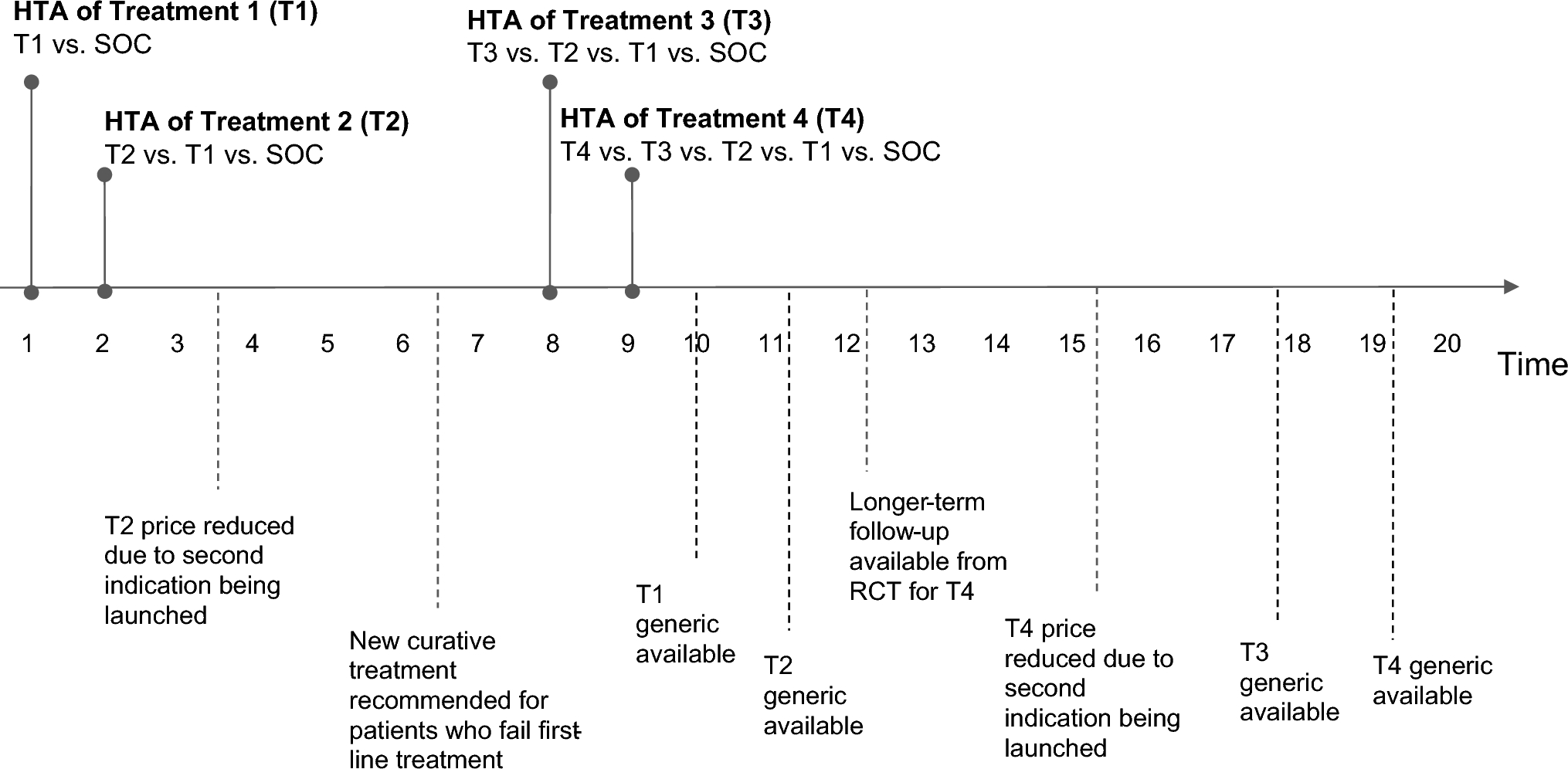

We begin by illustrating the illness–death model (Fig. 1). An illness–death model is one special type of multistate model for describing disease progression [29]. Typically, the model consists of three states: progression free, progression, and death. For disease onset, the states would represent disease free, illness, and death, respectively. The progression-free state is the initial state where the disease is present but without any progression (illness). The progression state corresponds to the advancement of the disease. The death state represents an absorbing state where no further transitions are possible. We applied a semi-Markov (clock-reset) approach; hence, the choice of time scale for the progression state to the death state is time since progression \((t-u).\) A Markov (clock-forward) approach is also available if the choice of time scale is \(t\), time since study entry. Patients may recover from the progression state back to the progression-free state, which is also referred as a "reversible" illness–death model [30]. For illustrative purposes, we hereby only consider an irreversible model.
Fig. 1
An irreversible illness–death model with three transitions: \(_(\text)\), progression free → progression; \(_(\text)\), progression free → death, and \(_(t-u)\), progression → death, with a semi-Markov approach
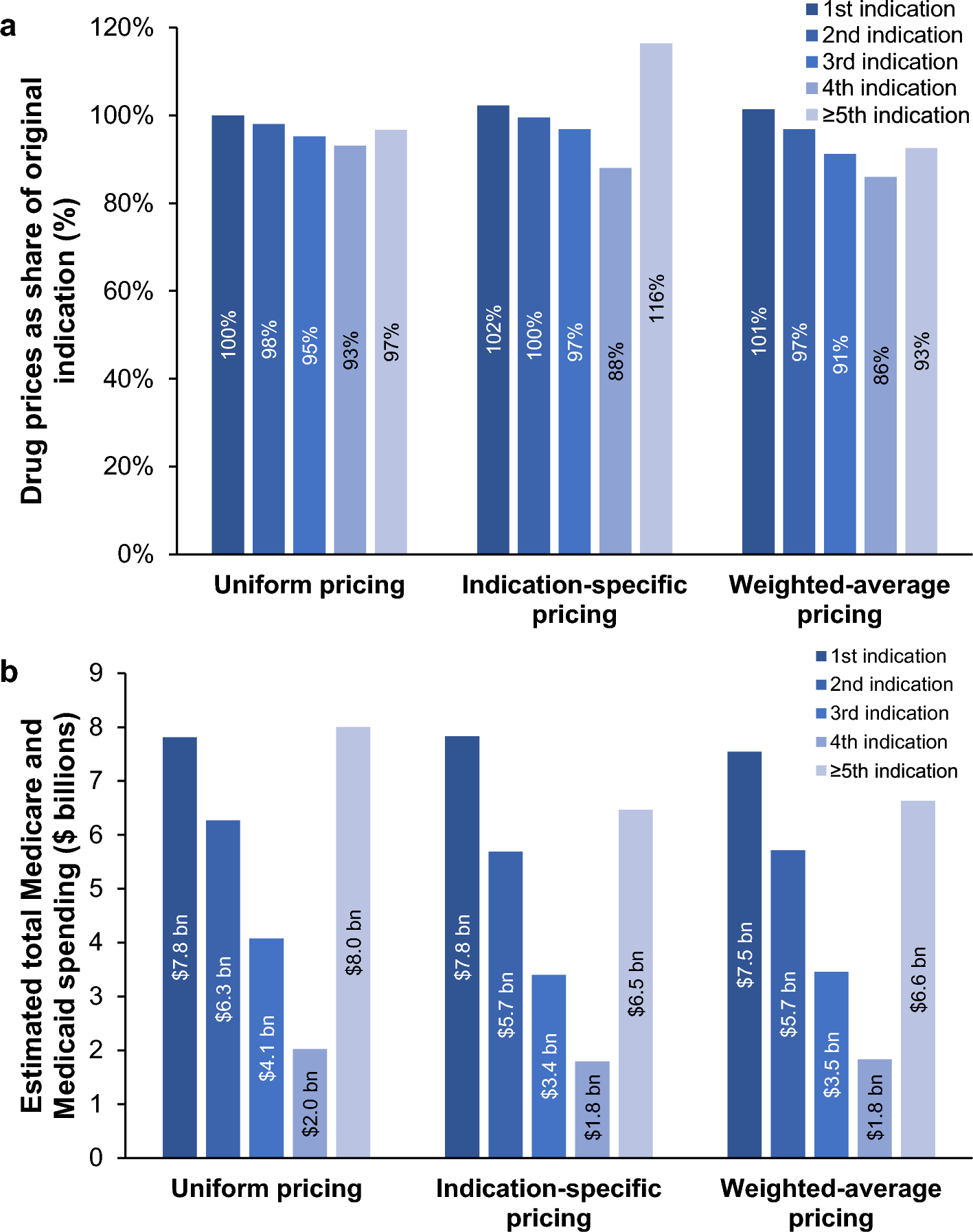
Figure 2 shows our suggested extension to the illness–death model. We partition the death state into two states: excess death and expected death. That is, when transitioning to the death state, patients may experience mortality related either to the disease itself (excess death) or to other causes (expected death). Hence, for our modeling application, we have four states (progression free, progression, excess death, and expected death), with five transitions in total. All patients start from the progression-free state and may transition to the progression state or the death state. We also applied a semi-Markov approach for the transitions from the progression state to the excess or expected death state. Below, we describe each transition and its statistical properties individually.
Fig. 2
An irreversible illness–death model incorporating a relative survival framework, with five transitions: \(_(t)\), progression free → progression; \(_(t)\), progression free → excess death; \(_^(t+a, t+c)\), progression free → expected death; \(_(t-u)\), progression → excess death; and \(_^(t+a, t+c)\), progression → expected death, with a semi-Markov approach
2.1.1 Transition 1: Modeling the Incidence Rate of Progression Free to ProgressionAll patients start from the progression-free state and thus are at risk for transitioning to the progression state and the excess or expected death states. We use the trial data for the transition from the progression-free state to the progression state to model the transition rate of progression free \(\to\) progression, \(_\left(t\right)\), with an FPM on a log cumulative hazard scale:
$$\text_\left(t|}_\right)=\text_\left(t\right)+}}_}_.$$
(1)
The log cumulative baseline hazard, \(\text_\left(t\right)\), is modeled with restricted cubic splines [31, 32], and we have the covariate vector \(}_\), variables of patient characteristics, with the corresponding coefficients \(}}_\).
2.1.2 Transition 2: Modeling the Mortality Rate of Progression-Free to DeathIn an RSF, the all-cause mortality of progression free \(\to\) death, \(_\left(t, t+a, t+c\right)\), can be written as the sum of the expected mortality, \(_^\left(t+a, t+c\right)\), and the excess mortality, \(_\left(t\right)\):
$$_\left(t, t+a, t+c|}_\right)=_^\left(t+a, t+c|}_}^\right)+_\left(t|}_\right),$$
(2)
where \(}_\) is a covariate vector that includes patient characteristics such as treatment, age, sex, and calendar year at diagnosis. The expected mortality is obtained from general population mortality rates, which can vary across stratification factors such as age, sex, and calendar year, denoted by \(}_}^\), which is a subset of \(}_\). Here, we use attained age (\(t+a)\) and attained calendar year \((t+c)\) as time scales. The extrapolation of the expected mortality for a given birth cohort can be based on projected general population mortality rates, typically published by national vital statistics offices, or by assuming that the rates remain the same as in the last follow-up year [17].
Using the trial data in conjunction with the general population mortality rates, any parametric relative survival model can be applied to model the excess mortality of progression free \(\to\) death, \(_\left(t\right)\). We chose to model this with a flexible parametric relative survival model [33] on a log cumulative excess hazard scale, \(\text_\left(t|}_\right)\), with time since study entry, \(t\), as the time scale:
$$\text_\left(t|}_\right)=\text_\left(t\right)+}}_}_,$$
(3)
where \(\text_\left(t\right)\) is the log cumulative baseline hazard, \(}_\) is the covariate vector, and \(}}_\) denotes the coefficients.
The all-cause cumulative mortality, \(_\left(t, t+a, t+c\right)\), can be shown as the sum of the cumulative expected mortality, \(_^\left(t+a, t+c\right)\), and the cumulative excess mortality, \(_\left(t\right)\), as follows:
$$_\left(t, t+a, t+c|}_\right)=_^\left(t+a, t+c|}_}^\right)+_\left(t|}_\right).$$
(4)
Note that model fitting for \(_\left(t, t+a, t+c\right)\) uses the all-cause mortality rates \(_^(t+a, t+c)\) for the event times and does not require all-cause cumulative mortality rates \(_^(t+a, t+c)\), as minus \(_^(t+a, t+c)\) is a constant term in the log-likelihood.
2.1.3 Transition 3: Modeling the Mortality Rate of Progression to DeathOnce patients enter the progression state, they are only at risk of transitioning to the death state. We apply a semi-Markov model here, that is, the clock-reset approach [7]; thus, the choice of time scale here is time since progression \((t-u\)) where \(u\) is time at progression. The all-cause mortality of progression \(\to\) death, \(_\left(t-u, t+a, t+c\right)\), can be expressed as the sum of the expected mortality, \(_^\left(t+a, t+c\right)\), and the excess mortality, \(_\left(t-u\right)\):
$$_\left(t-u, t+a, t+c|}_\right)=_^\left(t+a,t+c|}_}^\right)+_\left(t-u|}_\right),$$
(5)
where \(}_\) is a covariate vector containing patient characteristics, and \(}_}^\), a subset of \(}_\), is stratification factors for general population mortality rates. Like transition 2, the expected mortality \(_^(t+a, t+c)\) is estimated and extrapolated using attained age \((t+a)\) and attained calendar year \((t+c)\) as time scales, based on data from the general population mortality rates. For the excess mortality, using the trial data for the transition from the progression state to the death state, we chose to model this transition on a log cumulative excess hazard scale, \(\text_\left(t-u|}_\right)\), with a flexible parametric relative survival model [33]:
$$\text_\left(t-u|}_\right)=\text_\left(t-u\right)+}}_}_,$$
(6)
where \(\text_\left(t-u\right)\) is the log cumulative baseline hazard, \(}_\) is the covariate vector with corresponding coefficients \(}}_\), and (\(t-u)\) denotes time since progression as the time scale.
2.1.4 Simulation AlgorithmWe focus on using simulation approaches to obtain point estimates of interest in a given multistate model, applying the inversion method [34] to generate random survival times from fitted parametric time-to-event models. Bender et al. [34] proposed this method for a range of parametric distributions, such as exponential, Weibull, and Gompertz. Crowther and Lambert [35] extended this method by incorporating more complex hazard functions, for example, FPMs. In this study, to perform relative survival extrapolation, we use the inversion method to simulate survival times from a piecewise-constant exponential distribution [36], which has been implemented in msm::rpexp R function [37] and the Rpexp C++ class in the microsimulation package [38], within a multistate framework.
We simulate individual trajectories through the transition models until all individuals either reach an absorbing state or are right censored at a specified time, such as the study endpoint. This process treats the multistate model as a series of competing risks [39].
Following Crowther and Lambert [10], the simulation of an individual’s trajectory through a multistate model is conducted as follows:
Let \(a\) be the initial state entered at time \(_\), \(_\) be the number of allowed transitions from state \(a\), and \(S\) be the set of states that can be reached from state \(a\). The study endpoint is denoted as \(_}\).
1.For each state \(s\in S\), let \(_\left(t\right)\) represent the cumulative hazard function for the transition from state \(a\) to state \(s\), where \(s\) can be \(1, \dots , _\). If \(S=\varnothing\), meaning the individual reaches an absorbing state, then the simulation stops.
2.Simulated survival times \(=\left\_, _, \dots , __}, _}\right\}\) are generated using the inversion method [34] for each allowed transition.
3.The transition with the minimum time from \(,\) denoted \(_\), is selected, and the individual moves to state \(u\) at time \(_\). If \(_=\) \(_}\), the simulation stops.
4.Set \(a=u\) and \(_=_\), and repeat steps 1 to 3 until reaching an absorbing state or \(_=\) \(_}\).
This simulation algorithm enables relative survival extrapolation within the multistate model by simulating survival times in a competing risks framework with mixed time scales. For instance, in transition 2 (Sect. 2.1.2), we can derive transition probabilities from the cumulative expected hazard function, \(_^\left(t+a, t+c|}_}^\right)\), and the cumulative excess hazard function, \(_\left(t|}_\right)\).
We repeat this algorithm for a sufficiently large number \((n)\) of individuals through the multistate model [27]. Point estimates of interest—such as mean sojourn times, life-years, quality-adjusted life-years (QALYs), and costs—are calculated by averaging across all simulated individuals. Confidence intervals are computed from repeated simulations for \(m\) times using a multivariate normal distribution, with the estimated parameter vector as the mean and the associated variance–covariance matrix as the variance [10, 39].
2.2 Illustrative Example2.2.1 DataThe illustrative example is based on a randomized clinical trial comparing the use of rituximab in combination with fludarabine and cyclophosphamide (RFC) versus fludarabine and cyclophosphamide alone (FC) for the first-line treatment of chronic lymphocytic leukemia, also referred to as the CLL-8 trial [40]. This study formed the main source of clinical evidence used to inform National Institute for Health and Care Excellence Technology Appraisal TA174 [41, 42]. Our analysis was motivated by the study by Williams et al. [28], who analyzed this trial using semi-Markov multistate modeling in R, considering a competing-risks setting. The data were formatted for multistate modeling from the original wide format (each individual has one row with records on all transitions) into long format (each individual has a separate row for each transition where an individual is at risk). In total, 810 individuals were enrolled in this trial during 2003 to 2006. The RFC arm included 403 patients, and the FC arm 407 patients. Among both arms, the median age was 61 years, and the proportion of men was 74%. [40] Among the RFC arm, there were 106 progressions, 23 deaths after progression, and 21 deaths without progression. The FC arm had 148 progressions, 27 deaths after progression, and 26 deaths without progression. When the results of the CLL-8 trial were first reported [40], the maximum follow-up was approximately 4 years. To evaluate survival extrapolation, we predicted survival from 4 to 50 years using all multistate models (see Sect. 2.2.4) and compared these projections with the updated 8-year follow-up data [43].
2.2.2 Population Mortality DataTo integrate relative survival extrapolation into a multistate model, we require population mortality rates of the study population in the CLL-8 trial. The trial was conducted in 190 centers in 11 countries. We used the general population mortality rates of these countries from the Human Mortality Database [44] to construct the population mortality data for this trial. The data were stratified by calendar year, and age, with average mortality rates calculated considering the varying proportions of males and females across these 11 countries. For extrapolation of the population mortality data beyond 2006 (the last year of enrollment in the CLL-8 trial) [40] and for ages beyond 100 years, we applied the mortality rates from 2006 and age 100 years, respectively.
2.2.3 Hazard FunctionsWe used the multistate-structured data of the CLL-8 trial [40] provided in the study by Williams et al. [28]. The data were obtained by digitizing the overall survival (OS) and progression-free survival curves that were published in conjunction with the CLL-8 trial [40] using the algorithm proposed by Guyot et al. [45]. The survival curves do not contain sensitive personal information; consequently, the reconstructed data derived from the published figure are also devoid of such information.
We compared the fitted parametric models with the observed hazards by transition. For the observed hazard functions, we applied kernel smoothing methods to plot non-parametric observed hazard functions of 4 years. All parametric models were fitted with the observed data (maximum follow-up of 4 years) and extrapolated to 50 years. Transition 3 (progression to death) used a clock-reset approach with time since progression as the time scale. This approach was recommended by Williams et al. [28], who tested and concluded that the Markov property did not hold, making the semi-Markov model more suitable. We fitted all the parametric models with a treatment covariate, a binary variable indicating RFC or FC. SPMs in this article were referred to as the Gompertz, generalized gamma, and Gompertz distributions for transition 1 to 3, respectively, aligned with the base-case analysis of Williams et al. [28]. For FPMs, each transition had six candidate models: two to four degrees of freedom for main effects with or without two to three degrees of freedom for the covariate to allow for non-proportional hazards [46]. We selected the model with the lowest Akaike information criterion (AIC) [47].
We included three alternative formulations of the multistate model, detailed in Sect. 2.2.4. We applied extrapolation within an ASF for both SPMs and FPMs by fitting the models on a log cumulative hazard scale, and we used extrapolation within an RSF only for FPMs, detailed in Sect. 2.1. Below, we illustrate the characteristics of the parametric models by transition.
(A)Transition 1: progression free to progression
For SPMs, we fitted the Gompertz model. For FPMs, the selected model included treatment as a covariate with two degrees of freedom for the main effect without time-dependent effect.
(B)Transition 2: progression free to death
For SPMs, we employed the generalized gamma model. In the case of FPMs, our chosen model included treatment as a covariate with two degrees of freedom for the main effect without time-dependent effect. To extrapolate within an ASF, the model was fitted on a log cumulative hazard scale, \(\text_\left(t|}_\right)\), whereas within an RSF, the model was fitted on a log cumulative excess hazard scale, \(\text_\left(t|}_\right)\). Subsequently, we obtained the all-cause hazard function using the interrelationship provided in Eq. (2).
(C)Transition 3: progression to death
For SPMs, we implemented the Gompertz model. For FPMs, our selected model included treatment as a covariate with three degrees of freedom for the main effect without time-dependent effect. For extrapolation within an ASF, the model was fitted on a log cumulative hazard scale, \(\text_\left(t|}_\right)\), whereas within an RSF, the model was fitted on a log cumulative excess hazard scale, \(\text_\left(t|}_\right)\), provided in Eq. (6). Hence, we derived the all-cause hazard function using the interrelationship in Eq. (5). For this transition from progression to death, we employed a semi-Markov model (clock-reset) with (\(t-u)\), time since progression, as the time scale.
2.2.4 Multistate ModelsWe summarize the characteristics of all three multistate models in Table 1. Our proposed method was a multistate model that incorporates relative survival extrapolation with mixed time scales using FPMs (FPMs, RSF), whereas the model of Williams et al. [28] used SPMs within an ASF (SPMs, ASF). For comparison purposes, we also present results from FPMs within an ASF (FPMs, ASF). Note that the generalized gamma model did not converge for fitting an excess hazard function for transition 2 (progression free to death), so we did not investigate SPMs in an RSF.
Table 1 Characteristics of each multistate model include parametric model, survival framework, and time scale by transitionPoint estimates of the state occupation probabilities were derived from simulating \(\text=\text000000}\) individuals. Life-years of each state were estimated from the probabilities of being in the non-death states: progression free and progression. Furthermore, we presented the extrapolated survival curves from the six multistate models described above (Table 1) along with mean sojourn time/restricted mean survival time (RMST) and survival proportions at 4, 8, 15, and 50 years or lifetime.
2.2.5 Cost-Effectiveness AnalysisTo be consistent with Williams et al. [28], the time horizon of the cost-effectiveness analysis was set at 15 years. We presented the base-case analysis and one-way sensitivity analysis of our proposed model using FPMs within an RSF. The discounting rate for both costs and effectiveness was 3.5%, aligned with Williams et al. [28] To compare the PSA between our model and that by Williams et al. [28], we presented the cost-effectiveness plane and the acceptability curve. PSA involved Monte Carlo simulations [27], Beta Pert distributions [48] for costs, and other distribution parameters used by the manufacturer [42]. We simulated \(n=100, 000\) individuals for \(m=1000\) Monte Carlo iterations by refitting the FPMs.
2.3 Statistical SoftwareWe conducted all statistical analyses using R version 4.4.1. We plotted the observed hazard functions using the muhaz package [49] and the bshazard package [50]. All SPMs and FPMs were fitted and post-estimated by the flexsurv package [51] and the rstpm2 package [52]. Multistate models were computed using the simulation algorithm described in Sect. 2.1.4 using the microsimulation package [38]. For the model using SPMs in an ASF, we additionally employed the mstate package [7], following the approach used by Williams et al. For our proposed approach using mixed time scales with FPMs using an RSF, we also updated the hesim package [5] by adding an option of simulating event times from models with mixed time scales and included the analysis using the hesim package [5] to verify the results. Example code for all analyses in R can be found on the webpage: https://github.com/enochytchen/ChenEYT_microsim.
留言 (0)