
記住我
With the advancement of technology, especially the rapid development of artificial intelligence, significant changes have occurred in the field of music production. Artificial intelligence algorithms and other digital tools not only accelerate the process of music creation, but also open up new means of creation and expression for musicians. Traditional composition involves composers using music theory and personal creativity to create melodies, harmonies, and rhythms (Liu, 2023a). Electronic music production utilizes computer software such as electronic instruments and digital audio workstations (DAW) to create and edit music using virtual instruments, samples, and synthesizers. Algorithm music involves automatically generating music through specific algorithms or mathematical models, which can generate melodies and harmonies based on preset rules or randomness (Zeng and Zhou, 2021). Artificial intelligence music generation uses technologies such as machine learning and deep learning to extensively analyze music data, learn music styles and structures, and create new works (Bitaraes et al., 2022). The introduction of AI is not intended to replace traditional music creation methods or musicians, but to enhance their creative abilities and stimulate new ideas.
Previous studies have typically used techniques such as Long Short Term Memory (LSTM) and Recurrent Neural Networks (RNN) to achieve music generation. For example, Zhao et al. (2019) utilized biLSTM (bidirectional LSTM) to generate polyphonic music and designed a controllable parameter system based on Russell's two-dimensional emotional space (pleasure arousal). The system introduced the concept of LookBack to improve long-term structure, aiming to generate music that expresses four basic emotions. Dua et al. (2020) used Recurrent Neural Networks (RNNs), Gated Recursive Units (GRUs), and Long Short Term Memory Units (LSTMs) to improve the source separation and chord estimation modules, thereby enhancing the accuracy of score generation. Minu et al. (2022) regards music generation as a sequence to sequence modeling task, utilizing recursive neural networks to capture long-term time structures and patterns present in music data. Neural networks analyze a large amount of music data to learn and simulate the characteristics of specific music styles, thereby generating new music works. However, these algorithms still face challenges in understanding and generating complex music structures and their emotional expressions, especially in capturing subtle changes in music structures and deep emotions.
The application of emotion recognition and expression technology in music creation. This is mainly achieved through two optimization methods: first, creating a dataset with different emotional annotations, allowing the model to learn and imitate rich emotional expressions during the training process. Secondly, through interdisciplinary cooperation, integrating knowledge and technology from different fields, we can more effectively address the challenges of emotional expression in music. Hung et al. (2021) developed a shared multimodal database called EMOPIA, focusing on perceptual emotions in popular piano music, including audio and MIDI formats. Zheng et al. (2022) introduced an emotionBox method driven by music elements based on music psychology. The method extracts pitch histograms and note densities to represent pitch and rhythm, respectively, to control the emotional expression of music. Ma et al. (2022) proposed a new method for synthesizing music based on specific emotions, embedding emotional labels and music structure features as conditional inputs, and applying GRU networks to generate emotional music. However, accurately conveying human emotions to models remains a major challenge, especially in ensuring that the complexity and multidimensional nature of emotions are fully understood and expressed.
With the rapid development of Transformer technology, researchers have begun to effectively utilize data from large music libraries to analyze and learn the rhythm and melody of music through methods such as self supervised learning and transfer learning. Liu et al. (2022) developed a model of music motion synchronous generative adversarial network (M2S-GAN) to automatically learn music representations and generate command actions. This model can simulate the key functions of human conductors in understanding, interpreting, accurately, and elegantly performing music. Zhang and Tian (2022) developed a dual Seq2Seq framework based on reinforcement learning, which establishes a reward mechanism for emotional consistency and content fidelity to ensure that the generated melody is consistent with the emotional content of the input lyrics. Latif et al. (2023) proposed an Adversarial Dual Discriminator (ADDi) network, which uses a three person adversarial game to learn generalized representations and self supervised pre training using unlabeled data. Abudukelimu et al. (2024) developed a symbol music generation model called SymforNet based on self supervised learning, which utilizes attention mechanisms to achieve excellent ability to recognize different contextual elements. At present, these technologies mainly rely on methods that generate similar content based on specific text or music segments, and the generated music may not meet user expectations in terms of emotional expression.
An increasing number of studies are using auxiliary information to generate emotional music rather than relying on random generation. For example, techniques like Riffusion (Forsgren and Martiros, 2022) and Mubert (Mubert-Inc, 2022) use text information. Riffusion (Forsgren and Martiros, 2022) converts text-to-audio generation into spectrogram images and uses diffusion methods to maintain the stability of the music style. Mubert (Mubert-Inc, 2022) encodes text prompts and labels into latent vectors and selects the most matching labels to generate music. EEG signals are objective records of how people experience music, reflecting the impact of music on the brain. There is a general correlation between EEG signals triggered by music video stimuli and the content of the music video, and this information can effectively guide music generation. Therefore, utilizing EEG signal data to drive the generation of emotional music is of significant importance. Due to the lack of unified standards and classification methods, the mapping relationship between EEG signals and musical elements (such as rhythm, melody, and emotion) has become blurred and complex (Matsuda and Yamaguchi, 2022). EEG typically contains high levels of noise and is influenced by individual physiological and psychological states, while music data needs to address the complexity of polyphonic structures, volume changes, and different styles and genres (Bellisario et al., 2017). There are two main issues, one is the lack of a clear and fixed vocabulary between EEG and music data to standardize information. The other, the challenges posed by their respective data problems make it difficult to map between modalities.
To address these challenges, this study proposes a new approach that utilizes clustering to construct discrete representations and effectively utilizes complex and continuous EEG data to generate music for emotional expression through a Transformer model reverse mapping relationship. To address the mismatch between local and global information in emotion driven music generation, we introduce audio masking prediction loss learning technology to learn the global features of audio data. The model can more effectively understand and integrate the direct and overall emotional context, making music works more emotionally coherent and bridging the gap between short-term music elements and the overall emotional curve.
This study conducted extensive experiments on the EEG emotion dataset and demonstrated the following points:
1. Our model effectively integrates EEG and music data, and applies positional encoding to create robust discrete representations. Through the Transformer reverse mapping relationship, it significantly enhances the potential connection between EEG signals and audio data, and improves the emotional correlation of generated music.
2. The use of audio masking prediction loss forces the model to learn long sequence contextual information, enhancing its ability and accuracy in processing global information in music, ensuring that the generated music reflects a coherent and comprehensive emotional narrative, closely integrated with EEG driven emotional cues.
3. Our method performed well on multiple evaluation metrics and achieved the best results. This indicates that the generated music not only resonates well with the expected emotional state, but also maintains a high level of music quality.
2 Related work 2.1 The definition of beautiful musicMusic is often regarded as beautiful because it has the ability to evoke emotions, aesthetic appreciation, or pleasure among listeners. Beautiful music typically possesses qualities such as harmony, melody, rhythm, creativity, and emotional expression. Through the harmonious combination of various musical notes, it generates pleasing harmonies and clear melodic lines, as well as a strong sense of rhythm, effectively conveying emotions and eliciting resonance among listeners (Bruns et al., 2023).
Emotional music generation can be divided into three main approaches: style transfer (Liu, 2023b), symbolic-level generation (Zhou et al., 2023b), and music snippet generation (Wang and Yang, 2019). Style transfer involves transforming existing music pieces into new ones with specific styles or emotional characteristics. This process involves analyzing the style features of the original piece and incorporating these features into the new piece, such as transforming a classical music piece into a jazz style. Symbolic-level generation uses symbolic data (such as MIDI files) instead of directly processing audio waveforms to create music. By applying models like LSTM to capture the temporal characteristics of music, melodies and chords can be generated. Additionally, by adding emotional labels to the input symbolic music data, the model can learn and generate music with corresponding emotions. Music snippet generation involves creating short, clearly emotional or stylistic music snippets, which may form part of a complete composition or stand alone as independent musical phrases. This process often employs deep learning algorithms, including Recurrent Neural Networks (RNNs), Variational Autoencoders (VAEs), and Generative Adversarial Networks (GANs). These algorithms adjust rhythm and pitch by directly processing audio samples, thereby generating music snippets with specific emotions. Particularly, GANs and VAEs can learn complex data distributions and create both natural and expressive new music snippets. The understanding of the beauty of music is highly subjective and varies with cultural and individual differences. Nevertheless, it is generally believed that music capable of eliciting deep emotional resonance has universal aesthetic value.
2.2 Characteristic representation of brain electricityEEG is a method for recording electrical activity in the brain, widely used in studies of brain function and conditions. By analyzing EEG data, researchers can obtain characteristics of brain electrical activity and interpret rich information therein (Sánchez-Reyes et al., 2024). This non-invasive technique can be employed to study brain function, cognitive processes, sleep states, and neurological disorders, among others (Özdenizci et al., 2020). By analyzing the spectrum, coherence, and temporal parameters of EEG signals, interactions between brain regions can be revealed, and the functioning of the brain under specific tasks or states can be explored. Additionally, EEG data analysis aids in a deeper understanding of brain activity patterns underlying cognitive processes. Focusing on changes in specific frequency bands and features of event-related potentials helps in understanding the brain's response to different cognitive tasks, such as attention, memory, and language processing. Moreover, EEG is also used to monitor changes in brain activity during the treatment of neurological disorders or disease progression. By combining different EEG features with advanced data analysis techniques and machine learning algorithms, researchers can delve deeper into EEG signals, providing comprehensive insights into understanding brain activity mechanisms, brain functional disorders, and research on brain-computer interfaces, thus driving advancements in neuroscience and clinical diagnosis and treatment of neurological diseases.
2.3 Clustering to build dictionary tableClustering methods, dictionary construction, and high-dimensional data embedding are crucial tools in the fields of data analysis and machine learning, playing pivotal roles in handling vast datasets. In natural language processing (NLP) tasks, word embedding techniques offer rich text representations by capturing similarities and contextual relationships among words (Krishnan and Jawahar, 2020). Simultaneously, dictionary construction ensures consistency in text processing, which is vital for applications such as text classification and sentiment analysis. For instance, Gozuacik et al. (2023) utilized word embedding techniques to generate word vectors and employed LSTM networks to simulate the temporal evolution of word associations, establishing a model for predicting word embedding matrices. High-dimensional data embedding techniques encode raw data into feature vectors, effectively preserving key information and structure. After undergoing intermediate layer network mapping and decoding processes, they can accurately extract the desired information features. Clustering, as an unsupervised learning technique, groups data into clusters or clusters based on the similarity between data points (Cai et al., 2023). The K-means clustering method groups data by minimizing the sum of intra-cluster distances, while hierarchical clustering methods build hierarchical structures by progressively merging or splitting data points. Additionally, the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) method identifies clusters of various shapes through density estimation and can effectively handle outliers. To achieve synchronized representations of music and EEG signals, we adopted a feature clustering approach to construct a discrete feature dictionary and established a model to map the relationships between these features.
2.4 Pre-trained modelMore and more researchers are adopting pre-trained models to learn features from different modalities and apply them to downstream tasks, such as generating content for the target modality. In terms of task design, the Vision Transformer (ViT) directly applies the transformer architecture to sequences of image patches. Al-Quraishi et al. (2022) utilized Continuous Wavelet Transform (CWT) to generate time-frequency representations for each EEG signal and used the extracted images as inputs to deep learning models for classification. HuBERT is a model specifically designed for self-supervised learning of speech representations, which builds upon the architecture of BERT and trains by iteratively refining hidden representations. Seq2Seq, on the other hand, is a model architecture used for transforming one sequence into another, such as translating text from one language to another. Zhang et al. (2022) introduced self-supervised contrastive pre-training for time series data, including EEG signals, aiming to improve the performance of various downstream tasks. Panchavati et al. (2023) developed a transformer-based model pre-trained on annotated EEG data for seizure detection. Meanwhile, Zhou et al. (2023a) utilized pre-trained speech features to enhance EEG signal recognition, demonstrating the versatility of pre-trained models in various signal processing tasks. Using a transformer-based architecture to generate music based on EEG inputs is an innovative approach. Transformers are particularly effective in handling sequence data with long-range dependencies, making them suitable for modeling complex EEG signal patterns related to music.
3 MethodsEEG data and music audio data represent different dimensions of information, and thus we processed each type separately. In handling the EEG data, we first performed downsampling and filtering, followed by data alignment and slicing, eventually obtaining multi-channel aligned feature vectors FEEG0∈ℝN×M, known as the raw EEG data. Here, N represents the number of channels, while M represents the sample length. As for the music audio data, we extracted the music feature FM0∈ℝ1×M through appropriate audio processing techniques, referred to as emotional music data, where M also indicates the sample length. This processing approach ensures the consistency and comparability of the two different types of data. As shown in Figure 1, we present the detailed steps of the entire processing workflow. In this study, both EEG data and emotional music data are simultaneously input into our training model. The purpose of this is to develop a new model that utilizes both types of data, thereby achieving the task of generating emotional music expressed through brainwave signals.
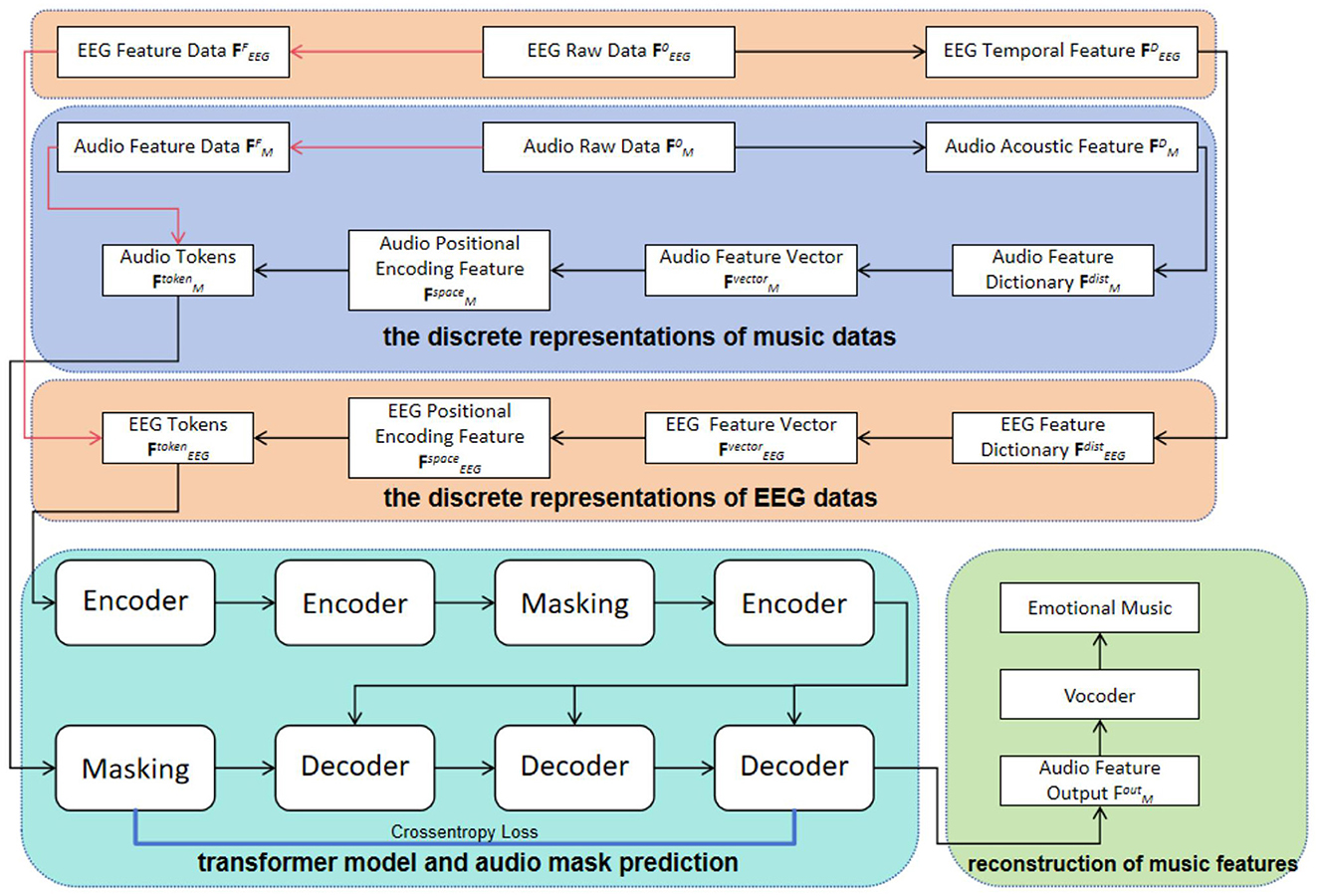
Figure 1. The overall framework consists of four steps: discrete representations of music datas, discrete representations of EEG datas, transformer model and audio mask prediction, and reconstruction of music features. Initially, convolutional feature extraction is applied to the filtered and aligned EEG raw data, denoted as FEEG0, and the raw audio data, denoted as FM0 (indicated by the red arrows). Subsequently, a series of feature transformation operations are performed on FEEG0 and FM0 to construct spatial encoding features, FEEGspace and FMspace, and generate EEG tokens, FEEGtoken, and audio tokens, FMtoken. These tokens are then inputted into a Transformer architecture for inter-token feature mapping, ultimately resulting in the audio feature, FMout, which is utilized for reconstructing emotional music.
When processing the FEEG0 data, we first extracted the differential entropy features and applied the DBSCAN density clustering algorithm for adaptive learning to obtain a cluster set, which further refined the EEG's temporal feature FEEGD. Based on these temporal features, we constructed an EEG feature dictionary FEEGdist, from which the EEG feature vector FEEGvector were derived. Additionally, we acquired FEEGspace through a positional encoding function, providing richer spatiotemporal information for model training. In handling the emotional music data, we used a method similar to the EEG signal processing. First, we utilized the DBSCAN density clustering algorithm for adaptive learning to obtain a cluster set of emotional music, and then sequentially extracted the features FMD, FMdist, FMvector, and FMspace. For the EEG signals, FEEGF was obtained by applying a Convolutional Neural Network (CNN) to the raw EEG data FEEG0 for feature mapping. Subsequently, we combined FEEGF and FEEGspace to construct EEG tokens FEEGtoken. Similarly, the audio feature data FMF was obtained by mapping the audio raw data FM0 through a CNN network. Afterwards, FMF was combined with FMspace to construct audio tokens FMtoken.
The EEG tokens FEEGtoken and audio tokens FMtoken are input into a model based on the Transformer architecture for deep feature interaction, thereby realizing the potential feature expression and mapping relationship between them. The self-attention mechanism of the Transformer model can effectively capture the complex dependencies between tokens, thereby extracting high-quality features that reflect the interaction between brainwave signals and musical emotions.
3.1 Clustering to build discretized representationsIn this section, we elaborate on how clustering methods are utilized to construct discretized representations for generating tokens from EEG and audio data. Initially, we extract differential entropy features from the original continuous feature data and apply the DBSCAN clustering algorithm to effectively group these continuous features into meaningful categories. Subsequently, we assign a unique identifier to each category and construct a feature dictionary. Through this process, we transform the original continuous features into a series of discrete feature vectors, thereby achieving a mapping from continuous features to discrete feature sequences. Following these steps, we effectively transform the original continuous features into discretized representations and, based on these representations and the original features, construct tokens. These tokens can then be input into the Transformer model for deep learning and interaction between features.
3.1.1 DBSCAN clustering methodDensity-Based Spatial Clustering of Applications with Noise (DBSCAN) is a density-based spatial clustering algorithm capable of identifying clusters of arbitrary shapes and effectively handling noise data. The core idea of the algorithm is to cluster based on the density of the area where objects are located. In the DBSCAN algorithm, there are two key parameters: radius ϵ and minimum number of points MinPts. These parameters determine whether an area is dense enough to form a cluster. The operation of DBSCAN can be summarized in the following steps: First, the algorithm starts with any unprocessed point as the starting point and explores its ϵ-neighborhood; if the number of points in this neighborhood reaches MinPts, the point is marked as a core point, otherwise, it is marked as a boundary point or noise point. Then, starting from a core point, the algorithm adds all points in the neighborhood to the cluster and recursively expands the neighborhood of all newly added core points.
We define the sequence FD0, represented as FD0=, where each element fi represents a feature in the data. Using these features, the DBSCAN algorithm groups data points into clusters such that the distance between any two points within a cluster is less than the set radius ϵ, and each cluster contains at least MinPts points. The ϵ-neighborhood of a point is defined as the collection of all points within a circular area centered at the point with radius ϵ. For any point fi in the sequence FD0, its ϵ-neighborhood can be represented by the following mathematical Equation 1 formula:
Here, dist(fi, q) denotes the distance between the point fi and point q. If the ϵ-neighborhood of the point fi contains at least MinPts points (including fi itself), then fi is labeled as a core point. This condition can be represented by the following Equation 2 formula:
|FDBSCAN(fi)|≥MinPts (2)where, |FDBSCAN(fi)| represents the number of points in the set FDBSCAN(fi).
If a point is not a core point, and the number of points in its ϵ-neighborhood is less than MinPts, but it includes at least one core point within its ϵ-neighborhood, then that point is marked as a boundary point. Points that are neither core points nor boundary points are considered noise points. During the clustering process, if a point fi is a core point, then any point q within its ϵ-neighborhood is considered to be directly density-reachable from fi. This relationship can be defined by the following Equation 3 condition:
q∈FDBSCAN(fi) and |FDBSCAN(fi)|≥MinPts (3)where the point q is part of the same cluster as fi, driven by the density connection that fi establishes through its sufficient ϵ-neighborhood size. In this way, DBSCAN can effectively identify and distinguish clusters of various shapes and sizes in time series and handle noise points in the data.
3.1.2 EEG signals build EEG tokensIn the process of constructing EEG tokens, we first perform feature extraction on the processed dataset FEEG0. We extract differential entropy features, which are defined by the function FDe. Then, using the density clustering algorithm DBSCAN, we perform adaptive learning on these differential entropy features to obtain the clustered EEG temporal features FEEGD. This process can be precisely described by the following Equation 4 formula:
FEEGD=FDBSCANEEG(FDe(FEEG0)) (4)In the process of constructing the EEG feature dictionary FEEGdist, we first use the feature clusters obtained through the DBSCAN algorithm as the elements of the dictionary. Each cluster's centroid and its representative features together form an entry in the dictionary. This EEG feature dictionary FEEGdist is used to represent and encode the features of EEG data. The EEG feature vector FEEGvector is generated based on the similarity between the features of a new signal and the most matching entry in the dictionary. This process can be represented by the following Equation 5 formula:
FEEGvector=FdictEEG(FEEGD) (5)Here, FdictEEG is a function that maps the clustered features FEEGD, obtained through clustering, to the EEG feature dictionary FEEGdist. This mapping facilitates the generation of the EEG feature vector FEEGvector for EEG signals. Constructing the feature dictionary FEEGdist=c1:(centroid1,features1),c2:(centroid2,features2),…,ck:(centroidk, featuresk), ci represents the ith cluster, centroidi is the centroid of the ith cluster, and featuresi are the representative features of the ith cluster.
To fully leverage the spatiotemporal information in EEG signals, this study inputs the FEEGvector signals into a positional encoding function to generate richer positional encoding feature FEEGspace. This process can be described by the following Equation 6 formula:
FEEGspace=FspaceEEG(FEEGvector) (6)where, FspaceEEG is a function specifically designed to add spatial and temporal context to the feature vectors derived from the EEG signals. The Sinusoidal Position Encoding method uses sine and cosine functions to generate encodings for each position in the sequence. The purpose of this method is to provide the model with information about the positions in the sequence, helping the model to better understand the order characteristics of the sequence data. The position encoding function FPE is specifically defined as follows Equation 7:
FPE(pos,k)={sin(pos10,0002i/dmodel),k=2icos(pos10,0002i/dmodel),k=2i+1 (7)In this, pos represents the position index in the sequence, k is the dimension index of the positional vector, 2i and 2i+1 to distinguish the parity of k, and dmodel is the total dimension of the model. This encoding method assigns a sinusoid to each dimension, with wavelengths varying geometrically from 2π to 10, 000 × 2π.
This method is used to generate a unique encoding for each position in the EEG data. These encodings not only contain positional information but also reflect the similarities between similar positions. We construct the EEG positional encoding feature FEEGspace and the EEG feature data FEEGF into EEG tokens FEEGtoken, where each token includes a comprehensive representation of both EEG features and positional information.
3.1.3 Emotional music build audio tokensFor emotional music data, although audio data is typically single-channel, differing in dimension from multi-channel EEG signal data, a similar process can be used to construct audio tokens. This method transforms the time series data of music into tokens rich in information, making them suitable for deep learning models.
The audio raw data FM0 undergoes feature extraction, where features such as differential entropy could be extracted. These features are then adaptively learned using the DBSCAN algorithm to form clusters of audio acoustic feature FMD. This process can be represented as Equation 8:
FMD=FDBSCANM(FDe(FM0)) (8)This step transforms continuous audio feature into discrete representations, similar to the method used for processing EEG signals.
Encode the clustering results from FMD using the audio feature dictionary FMdist to form the audio feature vector FMvector. Transform the clustering results into specific feature vectors through a mapping function Equation 9:
FMvector=FdictM(FMD) (9)Similar to EEG signals, perform positional encoding on the audio feature vector FMvector using fixed formulas of sine and cosine functions to generate encodings for each position, which are the audio positional encoding feature FMspace. This helps the model understand the temporal information of the audio data. This step can be represented as Equation 10:
FMspace=FspaceM(FMvector) (10)The construction of audio tokens FMtoken involves combining the position-encoded audio positional encoding feature FMspace with audio feature data FMF. These tokens include both the feature information of the audio and its temporal encoding, making them suitable for input into models for
留言 (0)