
記住我
Swimming action recognition holds significant research value and application prospects in the fields of sports science and health monitoring (Santos et al., 2021). Firstly, it can help swimming athletes optimize their training, improve their technical skills, and enhance their competitive performance. It can also effectively monitor posture and movements during sports activities, thereby preventing sports injuries (Cabrera-Arellano et al., 2022). Secondly, swimming action recognition technology plays a crucial role in water rescue and rehabilitation training. It can provide real-time monitoring and analysis of patients' movement status, offer precise rehabilitation recommendations, and quickly identify abnormal behaviors of drowning individuals in emergency situations, facilitating timely rescue measures (Hamidi Rad et al., 2022). Furthermore, with the rapid development of artificial intelligence and computer vision technology, research on swimming action recognition not only promotes the advancement of related technologies but also finds applications in other fields such as virtual reality and smart homes, expanding its scope of application. Therefore, conducting research on swimming action recognition is not only of theoretical significance but also possesses extensive practical value.
Traditional methods for swimming action recognition mainly rely on symbolic AI and knowledge representation. Firstly, manual feature extraction is widely adopted in early research on swimming action recognition, as it depends on the researcher's experience and expertise to select and extract action features. For example, Wang et al. (2019) proposed a swimming action recognition method based on manual feature extraction. Additionally, Kon et al. (2015) demonstrated the application and effectiveness of manual feature extraction in swimming action analysis. Secondly, rule-based methods utilize a series of predefined rules for action recognition. These methods exhibit high determinism and reliability, performing well even in the face of complex or highly variable actions. Chen et al. (2011) proposed a rule-based system for automated swimming action analysis, while Omae et al. (2017) provided a rule-based system framework for analyzing swimming performance. Furthermore, logistic regression, as a statistical method, learns features from training data to make classification decisions. It not only has important applications in action recognition but also significantly improves classification accuracy. Style (2014) demonstrated the application of logistic regression in swimming action recognition. These methods have advantages such as strong interpretability and transparency in the decision-making process. However, they suffer from limitations in handling complex and highly variable actions, as well as limited capability for processing large-scale data.
To address the limitations of traditional algorithms, data-driven and machine learning-based approaches have been applied to swimming action recognition, mainly using methods such as Support Vector Machines (SVM), Random Forests, and Multilayer Perceptron (MLP). These methods offer higher accuracy and robustness. For example, Jiang (2009) demonstrated the application of SVM in image recognition, significantly improving recognition accuracy through efficient feature extraction and classification. Yi-Bo et al. (2010) showed the efficient application of SVM in SAR automatic target recognition, greatly enhancing recognition efficiency. Additionally, Omae et al. (2017) improved swimming action classification using the Random Forest algorithm, reducing classification errors by integrating multiple feature values. Similarly, Liu (1996) demonstrated the application of Multilayer Perceptron in speech recognition, significantly improving classification accuracy through feature extraction and model training integration. While these methods have shown significant improvements in accuracy and robustness, they still face challenges such as high computational complexity and limited capability to handle large-scale data.
To address the limitations of statistical and machine learning algorithms, deep learning-based approaches have been applied to swimming action recognition, primarily using Convolutional Neural Networks (CNN), Transformers, and attention mechanisms. These methods offer higher recognition accuracy and robustness. For example, Victor et al. (2017) demonstrated the detection of swimming actions from continuous videos by training CNN and achieved significant results. Ahmed et al. (2022) proposed a lightweight CNN and GRU network for real-time action recognition, showing high accuracy and low computational cost. Additionally, Ali et al. (2023) showed that CNN can achieve comparable results to Graph Neural Networks in skeleton action recognition. In the case of Transformers, Ming et al. (2023) proposed the FSConformer model that utilizes frequency-domain and spatial-domain Transformer networks, significantly improving the accuracy of compressed video action recognition. The powerful capabilities of Transformers were also validated in the research by Li and Sun (2021), where they developed a Transformer-based model for 3D skeleton-based human action recognition, achieving excellent results. Regarding attention mechanisms, Dhiman et al. (2021) demonstrated the recognition of 3D human actions using a CNN driven by spatiotemporal attention mechanisms, effectively overcoming intra-class variations and inter-class similarities. Banerjee et al. (2020) achieved high-precision recognition of 3D skeletal actions by combining fuzzy integral with a CNN classifier. While these methods have shown significant improvements in accuracy and robustness, they still face challenges such as high computational complexity and limited capability to handle large-scale data.
To address the issues of high computational complexity and limited capability in processing large-scale data, we propose a new method called RL-CWtrans Net: Multimodal swimming coaching driven via robot vision. This system utilizes cutting-edge deep learning techniques and integrates multimodal data to provide precise and efficient swimming training guidance. Firstly, the system employs Swin-Transformer as the core computer vision model. This advanced visual model effectively extracts the motion and pose features of swimmers from video data. With its hierarchical architecture and powerful feature extraction capabilities, the Swin-Transformer can handle complex dynamic scenes and capture subtle motion variations. This endows the system with higher accuracy and robustness in recognizing and analyzing swimmer actions. Secondly, the system integrates the CLIP model, which combines visual and textual data. Through the CLIP model, the system can comprehend natural language instructions and descriptions relevant to swimming. For example, when a coach gives instructions like “maintain a straight body” or “pay attention to arm movements,” the system can translate these textual cues into specific visual features and compare them with actual swimming actions for analysis. To further enhance the intelligence and practicality of the system, we employ Reinforcement Learning (RL) to train the intelligent agent. RL enables the intelligent agent to learn and optimize its behavioral strategies through continuous interaction using a reward mechanism. In RL-CWtrans Net, the intelligent agent can dynamically adjust and optimize swimming coaching strategies based on multimodal inputs (visual features and textual instructions). For instance, if incorrect posture is detected, the intelligent agent can provide personalized corrective suggestions and feedback based on previous learning experiences and the current multimodal data. Through this approach, RL-CWtrans Net not only improves the accuracy and robustness of action recognition but also handles large-scale data and provides personalized swimming training guidance. As the intelligent agent undergoes continuous training and optimization, it gradually improves its decision-making ability, enabling the system to identify issues more precisely and offer corresponding guidance to help swimmers enhance their skill levels. This multimodal and multi-level intelligent swimming coaching system holds broad application prospects in areas such as sports training and health monitoring.
The contributions of this paper are as follows:
• RL-CWtrans Net combines Swin-Transformer and CLIP models, innovatively handling multimodal visual and textual data to achieve a more comprehensive and accurate information representation.
• The system possesses multi-scenario applicability, efficient processing, and wide generality, making it suitable for swimming action recognition and other multimodal data processing domains.
• The experiments demonstrate that RL-CWtrans Net exhibits significantly higher accuracy and efficiency in swimming action recognition and posture correction compared to traditional methods, showcasing outstanding performance.
2 Related work 2.1 Action recognitionThe development of action recognition, as an important research direction in the field of computer vision, has undergone a significant transformation from traditional methods to deep learning. Traditional approaches relied on manually designed feature extractors and machine learning-based classifiers, such as using Histogram of Oriented Gradients (HOG) and Support Vector Machine (SVM) for action recognition. These methods performed well in some simple scenarios but struggled with complex variations in actions and background interference (Qiu et al., 2022). With the rise of deep learning techniques, especially the widespread adoption of Convolutional Neural Networks (CNNs), action recognition has made significant progress. CNNs can automatically learn feature representations suitable for action recognition from data, leading to breakthroughs in visual recognition tasks. For example, by performing convolutional feature extraction and classification at the frame level of videos, CNNs can effectively identify key features in actions, such as human poses and motion patterns (Jin et al., 2023). Subsequently, with increasing demands for processing time-series data, models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) were introduced into action recognition. These models can capture the temporal dependencies in action sequences, enabling more accurate and efficient modeling of actions (Wang and Liang, 2023). More recently, spatio-temporal attention models like ST-GCN (Spatial-Temporal Graph Convolutional Network) have pushed the frontier of action recognition even further. ST-GCN leverages the idea of graph convolutional networks to effectively capture the spatio-temporal relationships in action sequences, significantly improving the accuracy and robustness of action recognition in complex environments (Wang and Liang, 2023).
2.2 Transformer modelThe Transformer model, as a deep learning architecture based on self-attention mechanisms, has demonstrated its powerful application potential in various fields. In natural language processing (NLP), a representative application of the Transformer model is BERT (Bidirectional Encoder Representations from Transformers). BERT learns deep semantic representations of text through large-scale unsupervised pre-training, significantly improving the performance of various NLP tasks such as text classification, named entity recognition, and question-answering systems (Lin et al., 2024b). In the field of computer vision, the application of Transformer models is also expanding. While traditional Convolutional Neural Networks (CNNs) excel in image processing, they may have limitations when dealing with large-scale images and long-range dependencies. Swin-Transformer introduces a hierarchical attention mechanism by dividing the image into local patches and establishing attention connections between local and global levels. This effectively enhances image understanding, especially in large-scale and complex scenes (Wang et al., 2023). Furthermore, Transformer models have demonstrated unique advantages in multimodal learning. The CLIP (Contrastive Language-Image Pre-training) model is a typical example. By jointly training on image and text data, CLIP enables the model to understand and reason about the content of images while possessing language description capabilities. CLIP does not rely on any category labels but instead learns through contrastive learning on pairs of images and texts, resulting in outstanding performance on multiple visual and language tasks (Stolarz et al., 2024).
2.3 Robot visionRobot vision technology has made significant progress in recent years, driving the application and development of intelligent robots in various domains. These advancements mainly focus on sensor technology, visual SLAM, and the application of deep learning in robot vision (Geisen and Klatt, 2022). Firstly, the development of sensor technology provides robots with more precise and rich visual information. For example, RGB-D cameras can simultaneously capture color images and depth information, providing more accurate data support for robot navigation and object detection in complex environments. Panoramic cameras extend the robot's field of view, enabling a wider-angle perception of the environment (Lin et al., 2024a). Secondly, advancements in visual SLAM (Simultaneous Localization and Mapping) enable robots to achieve real-time localization and map construction in unknown environments. Visual SLAM combines visual sensors and robot motion models to infer the robot's position and environment map through processing visual information. It provides essential support for autonomous navigation and task execution. Lastly, the widespread application of deep learning enhances the visual capabilities of robots. Deep learning models such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are widely used in robot vision tasks, including object detection, object tracking, and scene understanding. These technologies improve not only the visual performance of robots in static scenes but also enable robots to handle visual challenges in dynamic and complex environments, opening up broader possibilities and application prospects for intelligent robots (Modungwa et al., 2021).
3 Methodology 3.1 Overview of our networkThe proposed RL-CWtrans Net: Multimodal swimming coaching driven via robot vision integrates Swin-Transformer, CLIP, and reinforcement learning to deliver real-time guidance and feedback to swimmers. This innovative system harnesses computer vision techniques, natural language processing, and intelligent agent training to significantly elevate the efficacy of swimming instruction. Figure 1 is the overall framework diagram of the proposed method.
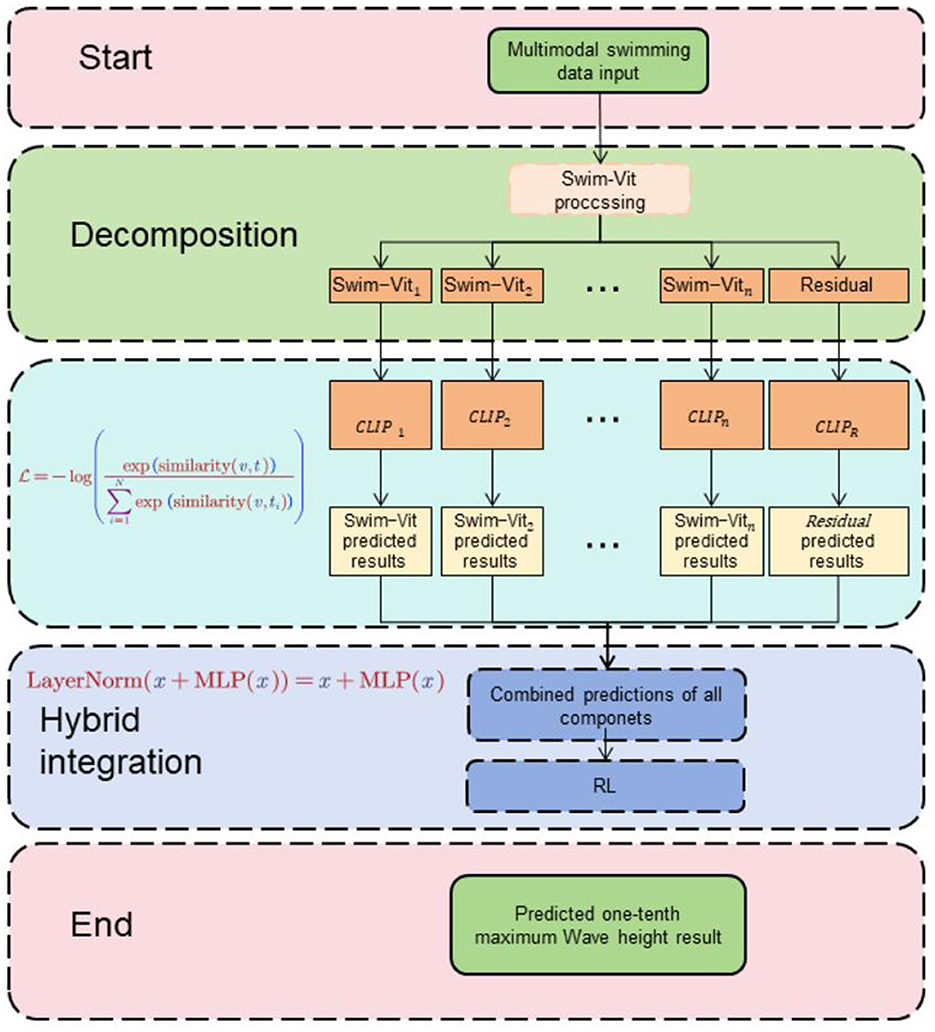
Figure 1. First, the video input is passed through Swin-Transformer to extract the swimmer's action and posture features. Then, the CLIP model parses the natural language instructions and descriptions and converts them into text features. Next, the visual and text features are fused to form a comprehensive information representation. Finally, the intelligent agent trained by reinforcement learning provides personalized guidance and feedback based on the multimodal input, completing the data stream processing and action optimization.
Swin-Transformer: The Swin-Transformer model is employed as a computer vision model to extract features from swimmers' movements and postures. It captures spatial relationships and temporal dependencies among video frames, enabling a comprehensive understanding of swimming techniques. CLIP integration: The CLIP model is integrated into the system to understand swimming-related natural language instructions and descriptions. By combining visual and textual features, the system achieves a more accurate representation of information and enhances the coach's ability to comprehend and respond to swimmers' needs. Reinforcement learning: The system employs reinforcement learning to train an intelligent agent that provides personalized coaching and feedback. The agent learns from multimodal inputs, such as visual observations and textual instructions, and optimizes its behavior based on a predefined reward function. This enables the system to adapt its coaching strategies to individual swimmers' needs and goals. Method implementation: Data Collection: Gather a diverse dataset of swimming videos, covering different styles, techniques, and skill levels. Include various camera angles and perspectives to capture the necessary modalities for analysis. Preprocessing: Preprocess the swimming videos to extract relevant features, such as body keypoints, joint angles, and stroke patterns. Use computer vision techniques, including pose estimation algorithms, to extract these features from video frames. Swin-Transformer: Apply the Swin-Transformer model to process the video frames and capture spatial and temporal dependencies. This enables the system to understand the swimmers' movements and gestures accurately. CLIP integration: Integrate the CLIP model into the system to understand natural language instructions and descriptions related to swimming. This allows the coach to comprehend textual inputs and bridge the gap between visual observations and human-readable instructions. Reinforcement learning training: Train an intelligent agent using reinforcement learning techniques. Define a reward function that evaluates the swimmer's performance based on predefined criteria. The agent learns to optimize its behavior by receiving feedback through the reward signal, allowing it to provide personalized coaching and feedback. Interaction and feedback: Develop an interface for swimmers to interact with the robotic coach. Swimmers can ask questions, seek advice, or request specific feedback. The coach provides real-time feedback through a combination of visual cues, natural language instructions, and reinforcement signals. Progress tracking: Implement a system to track the swimmer's progress over time. This includes performance metrics, skill development, and personalized training plans. The coach adapts its guidance based on the swimmer's progress and goals. Deployment and evaluation: Deploy the multimodal robotic swimming coach system in a controlled environment, such as a swimming pool, and gather feedback from swimmers. Continuously evaluate and improve the system based on user feedback, incorporating new techniques and research advancements.
To effectively implement domain adaptation techniques in our swimming coach system, we focus on enhancing the robustness of our computer vision and pose estimation models to the varying conditions encountered in different swimming pool environments. Here's a detailed breakdown of how we apply domain adaptation to address challenges such as lighting variations, water clarity, and background noise: Data Collection Across Environments: We begin by gathering a comprehensive dataset from a variety of swimming pools, including indoor and outdoor settings, under diverse lighting conditions and water qualities. This dataset includes video recordings that capture a wide range of environmental factors and swimmer interactions within these varying conditions. Data augmentation techniques: To extend the diversity of our training data, we employ data augmentation techniques that simulate additional environmental variables. This includes adjusting brightness and contrast to mimic different lighting conditions, adding artificial noise to represent different water clarity, and digitally altering background elements to create various scenarios of background noise. These augmentations help our models learn to function accurately across a spectrum of real-world conditions. Fine-tuning on target domain data: Once the models are pre-trained on the augmented dataset, we perform fine-tuning using data specifically collected from the target environments where the system will be deployed. This step adjusts the model's weights to better reflect the characteristics of specific swimming pool settings, enhancing its predictive accuracy and reliability in those particular conditions. Adversarial training: We incorporate adversarial training methods to align feature representations from different domains. By introducing adversarial examples during training, the models learn to generalize better by minimizing the domain discrepancy. This method forces the model to focus on the most relevant features that are invariant across different environments, thereby improving its robustness. Continuous monitoring and feedback loop: After deployment, the system continuously monitors its performance across different environments and collects feedback. This feedback is used to iteratively update the training process, allowing the models to adapt to any new conditions or changes in existing environments over time. Collaboration with domain experts: Throughout this process, we collaborate closely with swimming coaches and technical experts in aquatic sports to validate the relevance and accuracy of the models under various conditions. Their insights ensure that the models not only handle environmental variations but also align with the practical needs of competitive swimming training. By integrating these domain adaptation strategies, we equip our pose estimation models to handle the inherent variability in swimming pool environments effectively. This approach ensures that our robotic swimming coach system delivers consistent, accurate, and reliable performance, enhancing its utility as a training tool in diverse swimming settings. The overall implementation of the proposed system combines computer vision, natural language processing, deep learning, and robotics expertise. By integrating Swin-Transformer, CLIP, and reinforcement learning, the system aims to provide swimmers with effective and personalized coaching, leading to enhanced swimming techniques and performance.
3.2 Swin-TransformerSwin-Transformer is a computer vision model based on the Transformer architecture that has shown excellent performance in image processing tasks (Wang et al., 2024). The following will detail the basic principles of the Swin-Transformer model and its role in this context (Ahmadabadi et al., 2023). Figure 2 is a schematic diagram of the principle of Swin-Transformer.
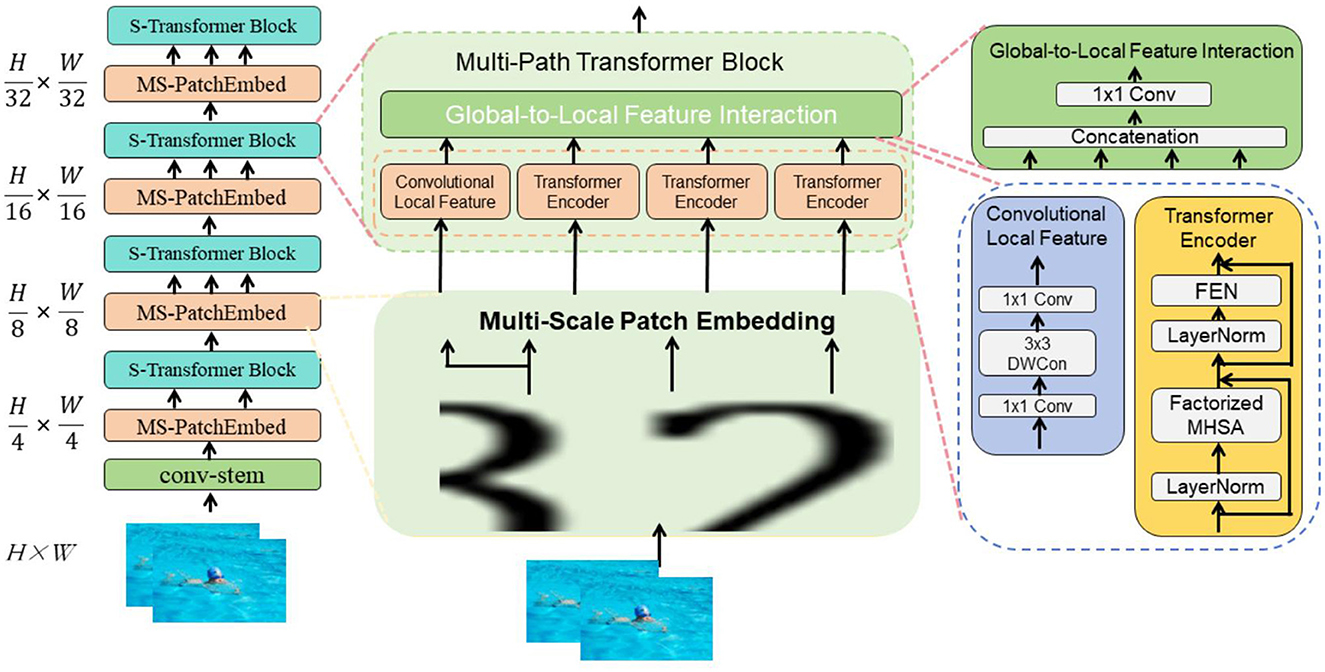
Figure 2. A schematic diagram of the principle of Swin-Transformer.
Hierarchical transformer structure: Swin-Transformer features a hierarchical Transformer architecture with multiple layers. Each layer is designed to capture different scales of information within the image, where lower levels focus on finer, local details and higher levels on broader, global features. This hierarchical approach is instrumental in processing multi-scale visual information, enhancing the model's ability to discern varied visual cues within complex images. Shifted window mechanism: To better capture long-range dependencies in images, Swin-Transformer incorporates a shifted window mechanism. This technique shifts the windows of local attention periodically, allowing each processing unit to integrate information from a broader context. This is critical for understanding the deeper, contextual relationships and long-range dependencies within images, aiding in more comprehensive feature extraction. Integration with temporal processing: To adapt Swin-Transformer for video analysis, where temporal dynamics play a crucial role, we have integrated it with a 3D convolutional network layer. This adaptation allows the model to process sequential data across video frames, enabling it to capture not only the spatial relationships but also the temporal dynamics of the swimmers' movements. Application in robotic swimming coach system: Feature extraction: Leveraging its enhanced spatial processing capabilities, Swin-Transformer extracts critical features from the motion and posture of swimmers from frame sequences. This forms the foundation for subsequent analysis and deeper understanding of dynamic postures and motion patterns. Spatial relationship modeling: By capturing both local and global features, Swin-Transformer effectively models the spatial relationships among various elements within the frame. This capability is vital for deciphering the complex postures, poses, and movement styles of swimmers, providing a nuanced understanding that is essential for precise coaching feedback. Context and dynamics modeling: With the shifted window mechanism and temporal integration, Swin-Transformer extends its reach to capture the overarching dynamics and context of swimmers' movements. This ensures that the coaching system can offer precise, context-aware instructional guidance and feedback, reflecting both spatial and temporal aspects of swimming techniques.
The formula of the Swin-Transformer model is as follows:
Attention(Q,K,V)=softmax(QK⊤dk)V (1)Multi-head Self-Attention:
MultiHead(Q,K,V)=Concat(head1,…,headh)WO headi=Attention(QWiQ,KWiK,VWiV) LayerNorm(x+MultiHead(x))=x+MHSA(x) (2)Transformer Block:
LayerNorm(x+MLP(x))=x+MLP(x)Among them, the explanation of variables is as follows:
In Formula 1 Q: Query vector, used to calculate attention weight. K: Key vector, used to calculate attention weight. V: Value vector, used to calculate the weighted sum. dk: The dimension of the attention head. Attention(Q, K, V): Attention mechanism, calculates the similarity between the query vector and the key vector, and performs a weighted sum of the value vectors based on the similarity. In Formula 2 MultiHead(Q, K, V): Multi-head attention mechanism, splicing the results of multiple attention heads. headi: The output of the ith attention head. softmax(·): softmax function, used to calculate attention weight. Concat(·): Splicing operation, splicing the results of multiple attention heads. WQ, WK, WV, WO: weight matrix, used for linear transformation. MLP(·): Multi-layer perceptron, used for nonlinear transformation of input. LayerNorm(·): Layer normalization operation, used to normalize input tensors.
Through the combination of multi-head self-attention and Transformer blocks, the Swin-Transformer model can effectively capture spatial and contextual information in images and extract useful feature representations. This provides a multi-modal robotic swimming coaching system with powerful computer vision capabilities.
3.3 CLIPCLIP (Contrastive Language-Image Pretraining) is a multimodal model based on contrastive learning, designed to link images and text together (Ma, 2021). Below is a detailed introduction to the basic principles of the CLIP model and its role in this context. Figure 3 is a schematic diagram of the principle of CLIP.
1. Position and velocity loops: The outer loop controls position, while the inner loop regulates velocity. The position loop receives a command Qc(s), which is the desired position, and compares it with the actual position feedback. The velocity loop takes the error from the position loop, processes it through velocity control Kvp+Kvis, and then feeds it into the torque control Kt to drive the motor.
2. Feedforward control: A feedforward control SKvff is added to the position loop to enhance the response speed and accuracy by anticipating the required control efforts based on the desired velocity.
3. Mechanical system: The motor and load are represented as inertia (Imotor and Iload), coupled by a stiffness k. This setup shows how mechanical elements like torque (Td(s)) and displacement (Qa(s)) interact within the system.
4. Dynamic interaction: The torque generated by the motor is transmitted through a coupling stiffness to the load, with the entire system's dynamics being influenced by these interactions. The feedback loops help to correct any discrepancy between the desired and actual outputs, ensuring precise control of the mechanical system.
Figure 3. A schematic diagram of the principle of CLIP.
The objective of the CLIP model is to learn a shared representational space where images and text can correspond to each other. The CLIP model consists of two main components: a visual encoder and a text encoder. Visual encoder: The visual encoder transforms input images into vector representations. It utilizes a Convolutional Neural Network (CNN) to extract features from images and maps them into the representational space. The goal of the visual encoder is to capture the semantic and visual characteristics of the image. Text encoder: The text encoder converts input text descriptions into vector representations. It employs natural language processing technologies, such as Recurrent Neural Networks (RNNs) or Transformers, to encode the semantic and contextual information of the text. The objective of the text encoder is to map text descriptions into the same representational space as the visual encoder. The CLIP model is trained using a contrastive learning approach. It learns the correspondence between images and text by maximizing the similarity of positive sample pairs while minimizing the similarity of negative sample pairs. This ensures that related image-text pairs are closer together in the shared representational space, while unrelated pairs are further apart.
The CLIP model plays a significant role in the multimodal robotic swimming coach system, specifically in the following aspects: Cross-modal understanding: The CLIP model can link images and text, allowing for comparisons and matches within a shared representational space. This enables the robotic swimming coach system to understand swimming-related natural language instructions and descriptions and associate them with the swimmers' image features. This enhances the system's ability to understand and analyze swimming movements and postures. Multimodal matching: Through the CLIP model, the system can compare and match the image features of swimmers with related textual instructions. This allows the system to identify specific movements performed by swimmers and associate them with corresponding swimming techniques and guidance. Multimodal matching enables the robotic swimming coach system to provide more accurate and personalized swimming instruction. Understanding contextual information: The CLIP model can encode the semantic and contextual information of texts, enabling the system to understand issues, requests, or feedback from swimmers. This allows the robotic swimming coach system to interact more effectively with swimmers and provide appropriate responses and feedback based on context.
The formula of the CLIP model is as follows:
CLIP Loss:L=-log(exp(similarity(v,t))∑i=1Nexp(similarity(v,ti))) (3)In Formula 3 among them, the explanation of variables is as follows:
v: vector representation of the input image. t: vector representation of the input text description. ti: vector representation of negative sample text descriptions (text descriptions that are not related to the input image). similarity(v, t): Calculate the similarity between the image vector and the text vector. exp(·): exponential function. ∑i=1N: summation symbol, which means summing all negative samples. L: The loss function of the CLIP model.
The CLIP model is trained using a contrastive learning method, in which the loss function shortens the distance between relevant images and text by maximizing the similarity of positive sample pairs, while minimizing the similarity of negative sample pairs to increase the distance between irrelevant images and text. distance. In this way, the model is able to learn a shared representation space such that related image and text pairs are closer in this space, while unrelated image and text pairs are further apart. By minimizing the CLIP loss function, the model is able to learn a shared representation space that is semantically and visually consistent so that images and text can be compared and matched in this space. This provides the multi-modal robot swimming coaching system with powerful capabilities, enabling it to understand the swimmer's image features and related text instructions, and provide personalized swimming teaching guidance and feedback. The CLIP model, by linking images and text, provides capabilities for multimodal matching and cross-modal understanding. In the multimodal robotic swimming coach system, it helps the system understand the image features of swimmers and related textual instructions, thereby offering personalized swimming instruction and feedback.
3.4 Reinforcement learningReinforcement learning is a machine learning method used to solve the problem of agents learning optimal decision-making strategies during interaction with the environment (Dong et al., 2020). The basic principles of the reinforcement learning model and its role in this method will be introduced in detail below (Liu et al., 2022). Figure 4 is a schematic diagram of the principle of Reinforcement Learning.
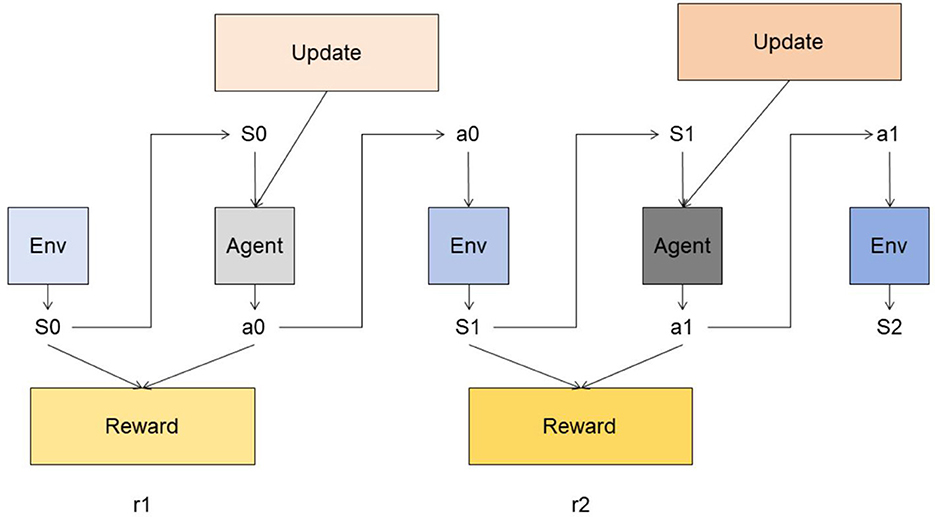
Figure 4. A schematic diagram of the principle of Reinforcement Learning.
The reinforcement learning model is modeled based on the framework of Markov Decision Process (MDP). MDP consists of five-tuple < S, A, P, R, γ>, where:
S: State space, representing the set of states that the agent may be in. A: Action space, which represents the set of actions that the agent can perform. P: State transition probability, which represents the probability distribution of an agent transitioning from one state to another under a given state and action. R: Reward function, which represents the immediate reward obtained by the agent under a given state and action. γ: discount factor, used to measure the importance of future rewards. The goal of the reinforcement learning model is to learn an optimal policy π* through interaction with the environment, so that the agent can choose the optimal action in each state, thereby maximizing the cumulative reward. The training process of the model can be divided into two stages: learning stage and execution stage.
Learning phase: In the learning phase, the reinforcement learning model learns the policy through interaction with the environment. The model selects an action based on the current state and interacts with the environment. The environment returns the next state and immediate reward based on the action chosen by the agent. The model updates the strategy based on the obtained rewards and state transition information, so that the agent chooses a better action in each state. Execution phase: In the execution phase, the trained strategy is used in the actual decision-making process. The model selects actions based on the current state and learned policies and interacts with the environment. The model adjusts the strategy in real time based on the rewards and state transition information returned by the environment to adapt to changes in the environment.
The formula for reinforcement learning is as follows:
Q(s,a)=(1-α)·Q(s,a)+α·(r+γ·maxa′Q(s′,a′)) (4)In Formula 4 among them, the explanation of variables is as follows:
Q(s, a): State-action value function (Q function), which represents the estimated value of the cumulative reward obtained by executing action a in state s. s: current status. a: current action. α: learning rate, used to control the weight of new and old estimates, between 0 and 1. r: immediate reward (immediate reward), the reward obtained from the environment after executing action a. γ: Discount factor, used to measure the importance of future rewards, between 0 and 1. s′: The next state, which is the new state observed from the environment after executing action a. a′: The action selected in the next state s′. maxa′Q(s′,a′): The maximum value of the state-action value function of all possible actions in the next state s′.
Reinforcement learning models play an important role in multi-modal robot swimming coaching systems, including the following aspects: Learning the optimal strategy: The reinforcement learning model can learn the strategy to select the optimal action in each state through interaction with the environment. In the swimming coaching system, the model can learn to select the best teaching guidance and feedback strategies under different swimming postures and action states to help swimmers improve their techniques and swimming performance. Personalized teaching: The reinforcement learning model can learn adaptive teaching strategies based on the individual characteristics and performance of swimmers. By interacting with swimmers, the model can adjust strategies based on the swimmer's status and feedback, providing personalized swimming teaching guidance and feedback to meet the needs and goals of different swimmers. Real-time decision-making: The reinforcement learning model enables the robotic swimming coaching system to make decisions in real-time scenarios. The model can be based on the current state and learned policies. Reinforcement learning (Reinforcement Learning) is a machine learning method used to solve the problem of agents learning optimal decision-making strategies during interaction with the environment. The basic principles of the reinforcement learning model and its role in this method will be introduced in detail below.
4 Experiment 4.1 DatasetsThis paper uses four data sets: Swimming Technique Datasets, ImageNet Datasets, Kinetics Datasets and Sports-1M Dataset. Swimming technique datasets (Brunner et al., 2019): This dataset is specifically designed for the study and analysis of swimming techniques. It may contain videos, images, or other relevant data, such as demonstrations of different swimming strokes, recordings of swimming competitions, etc. The Swimming Technique Dataset is useful for training and evaluating computer vision or machine learning models related to swimming. ImageNet datasets (Deng et al., 2009): ImageNet is a widely used large-scale image database for image recognition and visual object classification tasks. It contains millions of high-resolution images labeled across thousands of different categories, including animals, objects, scenes, etc. The ImageNet dataset is commonly used for training and evaluating deep learning models, especially in the field of computer vision. Kinetics datasets (Carreira and Zisserman, 2017): Kinetics is a video dataset for action recognition and classification research. It includes a large number of video clips covering a variety of everyday actions and sports activities, such as running, dancing, basketball, etc. The Kinetics dataset is typically used to train and evaluate deep learning models related to action recognition, helping computers understand and analyze actions in videos. Sports-1M dataset (Li et al., 2021): Sports-1M is a large-scale dataset used for video action recognition and analysis of sports activities. It contains over one million YouTube video clips, covering various sports such as soccer, basketball, tennis, etc. The Sports-1M dataset is used to train and evaluate deep learning models related to sports activities, enabling automated sports action recognition and analysis.
In evaluating our model for the multimodal robotic swimming coach, we employed a range of metrics including Accuracy, Area Under the Curve (AUC), Recall, F1 Score, and inference time recording. Each metric serves a specific purpose in assessing different aspects of the model's performance relative to the characteristics of our datasets. Accuracy is a fundamental metric that measures the overall correctness of predictions compared to the ground truth. It provides a general sense of how well the model performs across all classes or categories within the dataset. In our context, accuracy helps gauge the model's ability to correctly classify different swimming techniques or performance levels. AUC (Area Under the Curve) is particularly relevant when evaluating models trained for binary or multi-class classification tasks. It assesses the trade-off between true positive rate (sensitivity) and false positive rate (1-specificity), which is crucial for understanding how well the model distinguishes between different classes or categories in our diverse dataset of swimming styles and skill levels. Recall (also known as sensitivity) measures the model's ability to correctly identify positive instances (e.g., correct swimming techniques) out of all actual positive instances in the dataset. It is especially important in scenarios where identifying certain classes or conditions accurately is critical, such as detecting specific stroke patterns or movements in swimming. F1 Score combines precision and recall into a single metric, providing a balanced assessment of the model's performance. It is particularly useful in scenarios where there is an uneven class distribution or when both false positives and false negatives have significant consequences. For our robotic coach, achieving a high F1 Score ensures that it provides reliable feedback on swimming technique and performance. Additionally, inference time recording is essential for assessing the model's efficiency in real-time applications. It measures how quickly the model can process input data and generate outputs, which is crucial for ensuring timely feedback and guidance during training sessions.
4.2 Experimental detailsWe focus on researching a model called RL-CWtrans Net, aiming to develop a robot vision-driven multimodal swimming coach system. We have designed a detailed experimental procedure to evaluate the performance of this model on multiple datasets and conducted metric comparisons and ablation experiments to analyze its strengths and applicability in depth. Firstly, we selected four representative datasets: a swimming technique dataset, ImageNet dataset, Kinetics dataset, and Sports-1M dataset. Each dataset was divided into training, validation, and testing sets to ensure the scientific rigor and reliability of the experimental results. Specifically, each dataset was systematically partitioned with approximately 70% allocated to the training set, 15% to the validation set for hyperparameter tuning and model selection, and the remaining 15% to the testing set for final performance evaluation. This consistent division across all datasets ensured our model evaluations were conducted under rigorous and controlled conditions. Secondly, the RL-CWtrans Net model incorporates advanced techniques such as Swin-Transformer and CLIP and is trained using reinforcement learning methods. During the model implementation, we conducted detailed implementation and adjustments based on the characteristics of each dataset to fully utilize the information from different datasets and improve the model's generalization ability and effectiveness. During the model training phase, we set appropriate hyperparameters such as learning rate, batch size, and optimizer type. We also implemented effective data augmentation strategies such as random cropping and flipping to enhance the model's robustness. We accurately recorded key metrics such as training time, number of model parameters, computational complexity (FLOPs), and inference time, as these metrics directly impact the model's practicality and efficiency. Through metric comparison experiments, we created performance comparison charts for various models on different datasets and conducted in-depth analysis of their performance differences across multiple metrics such as accuracy, AUC, recall, and F1 score. Additionally, the ablation experiments helped us explore the impact of key factors such as network architecture and data augmentation methods on performance, providing theoretical support and experimental evidence for further model optim
留言 (0)