
記住我
With the rapid development of modern robot research and development technology, manipulators have permeated various aspects of human life, such as space explorations (Ma et al., 2023a) and smart factories (Abate et al., 2022). Its fundamental functionality lies in trajectory tracking, where specific tasks are accomplished by executing predefined end-effector trajectories (Jin et al., 2024b). This involves the control of robot kinematics and dynamics (Liao et al., 2022; Lian et al., 2024; Sun et al., 2024). To exert control over the robot, desired joint attributes should be obtained according to the task trajectory and converted into the corresponding joint torques (Müller et al., 2023). Numerous algorithms, such as pseudoinverse methods (Guo et al., 2018; Sun et al., 2023a) and model predictive control method (Jin et al., 2023), have been designed to achieve precise control of the manipulator. However, these algorithms rely on accurate robot models and struggle to control the robot effectively when its parameters change. In practical applications, it is common for robot model parameters to vary, especially when robots are modified to perform different tasks in diverse application scenarios (Xiao et al., 2022; Xie and Jin, 2024). Reliable model-free control methods need to be designed to enable effective control of robots after the parameter changes.
In recent decades, there are many emerging algorithms to address the control issues of manipulators (Liao et al., 2024; Yan et al., 2024), which are considered from the velocity level (Zhang et al., 2019; Sun et al., 2022), acceleration level (Wen and Xie, 2024), or torque level (Hua et al., 2023). For instance, to eliminate the joint-angle drift and prevent excessive joint velocity, a velocity-level bi-criteria optimization scheme is provided for coordinated path tracking of manipulators, focusing on the velocity aspect (Xiao et al., 2017). Additionally, a data-driven acceleration-level scheme is introduced to address control continuity and stability issues for manipulator (Wen and Xie, 2024). However, most of these studies focus solely on kinematics, neglecting dynamic factors (Tang and Zhang, 2022). Robot kinematics and dynamics are two fundamental domains within the field of robotics. Robot kinematics focuses on the study of the motion capabilities of robots in space, encompassing aspects such as joint angles, positions, velocities, and accelerations, without considering the effects of forces (Xie et al., 2023). In addition, robot dynamics is concerned with the impact of forces and torques on the motion of the manipulator, including the interactions between the robot and its environment. In the control of robotic manipulators, considering dynamic factors can help precisely predict the actual motion trajectory of the manipulator under various load and motion conditions, thereby improving the overall motion accuracy (Sun et al., 2023b; Xiao et al., 2023). It can also compensate for the oscillation and coupling effects in joint motion, making the movement of the manipulator smooth and stable. Furthermore, the dynamics-based studies aid in selecting the optimal drive scheme, reducing energy consumption, and enhancing energy utilization efficiency. However, manipulators frequently encounter issues with dynamic uncertainties due to the diversity of robotic grippers and uncertainties in load (Bruder et al., 2021; Liu et al., 2024b). Specifically, surgical manipulators may be equipped with different end-effectors to meet various task requirements, implying changes in dynamic parameters (Liu et al., 2024b). Moreover, in robotic-grasping tasks, unknown loads also lead to variations in robot dynamic parameters (Bruder et al., 2021). Dynamic uncertainties significantly impede the accurate control of manipulators, highlighting its research significance.
Recurrent neural networks (RNNs) have emerged as effective robot control algorithms in recent years (Liao et al., 2023; Ma et al., 2023b; Jin et al., 2024a). RNN is utilized to establish a scheme for addressing the coordination problem for multirobot systems (Cao et al., 2023; Liu et al., 2024a). In addition, RNN can mitigate uncertainties in the robot systems by enabling online learning of robot parameters (Xie et al., 2022). However, further research is needed to explore the integration of synchronous dynamic parameter learning with the kinematic model to achieve accurate trajectory tracking (Tang et al., 2024). To this aim, this study assumes the presence of deviations in the robot dynamic model and proposes an RNN for the model-free control of manipulators. Specifically, relevant control algorithms are designed at both the kinematic and dynamic levels, and an estimator of the mass matrix is proposed to compensate for the uncertainty of the dynamic model. Further verifications are carried out on a Franka Emika Panda manipulator to perform a trajectory-tracking task, taking into account dynamic uncertainties. In addition, compared with the existing methods, the superiorities of the proposed RNN lie in the following two aspects:
• Compared with kinematics-based methods (Guo et al., 2018; Jin et al., 2023, 2024b), the proposed RNN bridges the robot kinematics and robot dynamics models through joint acceleration signals, considering the motion feature and the dynamic behavior of manipulators.
• Compared with dynamics-based methods (Shojaei et al., 2021; Zong and Emami, 2021), the proposed RNN addresses the dynamic uncertainty problem by estimating the mass matrix online and realizes synchronous trajectory tracking.
Through the introduction of the above basic content, the specific research of this study is organized as follows. Section 2 explains the kinematic relationship between the joint angle of the manipulator and the end-effector. In Section 3, a corresponding RNN is designed. Subsequently, the learning and control ability of the proposed RNN are analyzed theoretically in Section 4. Finally, simulations and comparisons are carried out in Section 5.
2 Kinematic controllerThe forward kinematics of the manipulator describes the mapping relationship between the joint angle and the end-effector position, described as f(q) = r, where q ∈ ℝa is the joint angle, r ∈ ℝb denotes the position of the end-effector, and f(·) stands for the non-linear mapping. Furthermore, the time derivative of the forward kinematics is derived as
where L = ∂f(q)/∂q ∈ ℝb×a is the Jacobian matrix, q· denotes the joint velocity, and r· is the velocity of the end-effector. Concerning the joint acceleration level, taking the time derivative of Equation 1 leads to
L·q·+Lq¨=r¨, (2)where L· is the time derivative of L, q¨ represents the joint acceleration, and r¨ denotes the acceleration of the end-effector. Building upon Equation 2, the desired joint acceleration can be obtained by the following kinematic controller:
q¨=L†(r¨d-L·q·-v), (3)where v=β(r·-r·d)+ζ(r-rd) denotes the error feedback term; rd, r·d, and r¨d are the desired position, velocity, and acceleration of the trajectory tracking task; superscript † denotes the pseudoinverse operation of a matrix with L† = LT(LLT)−1; and β>0 and α>0 are convergence coefficients. On the one hand, kinematic controller (Equation 3) utilizes the minimization function of the pseudoinverse operation to obtain the desired joint acceleration (Wen and Xie, 2024). On the other hand, it takes the desired trajectory tracking task as input and incorporates feedback of the tracking error, leading to improved trajectory tracking performance. In addition, kinematic controller (Equation 3) can apply traditional methods to avoid the singularity issues, such as the damped least squares method (Xie et al., 2024). Specifically, a damped term can be added in the computation of the pseudoinverse. The specific calculation formula is LT(LLT + μI)−1, where μ>0 denotes a tiny parameter and I denotes the identity matrix. By doing so, the infinite values caused by zero eigenvalues in the pseudoinverse operation can be avoided.
3 Recurrent neural network designRobot dynamics refers to the mathematical description of the relationship between joint torques, dynamic parameters, and joint motions in a robotic system. Specifically, the dynamic model of a manipulator can be written as
τ=M(q)q¨+c(q,q·)+g(q), (4)where τ ∈ ℝa represents the joint torque, M(q) ∈ ℝa×a is the mass matrix, c(q,q·)∈ℝa is the Coriolis and centrifugal vector, and g(q) ∈ ℝa denotes the gravity vector. Generally, traditional methods, such as Guo et al. (2018), are capable of performing accurate dynamic control by relying on precise dynamic models (Equation 4). However, in real-world applications, it is common for manipulators to undergo modifications to perform various tasks, resulting in changes in their dynamic parameters. Given the assumption that the change occurs in the inertia matrix, we design an estimated inertia matrix M¯∈ℝa×a to effectively mitigate dynamic uncertainties. As a result, the following state equation is established:
τ¯=M¯(q)q¨+c(q,q·)+g(q), (5)where τ¯∈ℝa is the corresponding joint torque. When the estimated inertia matrix converges to the actual one, it indicates that the dynamic uncertainty issue is solved. To this aim, an estimation equation is presented as follows:
M¯·=α(τ-τ¯)q¨†, (6)where M¯· determines the evolution direction of M¯, and α > 0 stands for the convergence coefficient. In Equation 6, τ is measured in real time. Combining Equations 3, 5, 6, an RNN is designed as follows:
M¯·=α(τ-M¯(q)q¨+h(q,q·))q¨†, (7a) τout=M¯(q)(L†(r¨d-L·q·)-v)+h(q,q·), (7b)where τout is the output signal and h(q,q·)=c(q,q·)+g(q). In addition, a control flow chart of RNN (Equation 7) is shown in Figure 1. Notably, the joint acceleration generated by Equation 3 in a kinematic manner serves as the input for Equation 7b. Furthermore, Equation 7a utilizes measurement data τ to estimate the mass matrix, which, in turn, facilitates the precise control of Equation 7b. In this context, RNN (Equation 7) demonstrates its capability to learn the mass matrix and achieve synchronous trajectory tracking via the joint torque. The parameters in RNN (Equation 7) include α, β, and ζ, which are determined through trial and error methods.
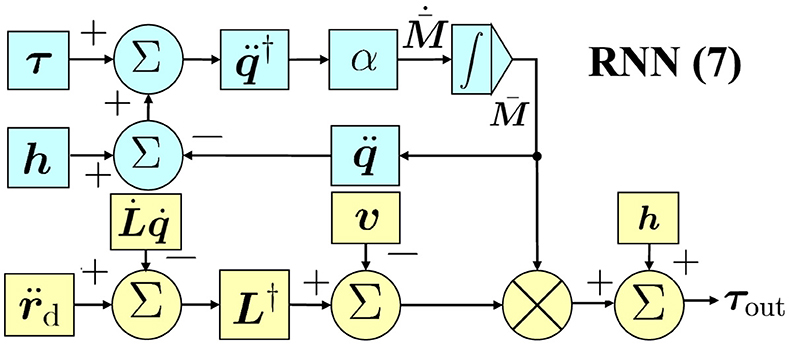
Figure 1. A control flow chart of RNN (Equation 7).
In RNN (Equation 7), we first apply kinematic controller (Equation 3) to output the joint acceleration corresponding to the trajectory task. This process belongs to the inverse kinematics solution. Subsequently, we further obtain the joint torque by calculating the obtained joint acceleration. This process belongs to the inverse dynamics of solution. Finally, the output joint torque can directly control the manipulator to perform the given task. In this control mode, robot kinematics and dynamics are combined together with joint acceleration to form a bridge.
4 Theoretical analysisThe following theorem provides a verification of the learning and control capabilities of the proposed RNN (Equation 7).
Theorems: Assuming a sufficiently large value of α, the estimated error M-M¯ generated by Equation 7a is global convergent to a zero matrix. Based on the estimated mass matrix, Equation 7b enables accurate trajectory-tracking control of the manipulator with an unknown mass matrix.
Proof: By incorporating Equations 2, 3, we can rewrite Equation 7b as M¯·=α(M-M¯)q¨q¨†. Multiplying both sides of the equation by q¨ yields M¯·q¨=α(M-M¯)q¨. Then, it follows that M¯·=α(M-M¯). Define an estimated error as e=(Mi-M¯i) with Mi and M¯i being the i-th column of M and M¯ (i = 1, ⋯ , a), respectively. Set a Lyapunov function as V=(Mi-M¯i)T(Mi-M¯i), and then, its time derivative is calculated as follows:
V·=(Mi-M¯i)TM·i-α(Mi-M¯i)T(Mi-M¯i) =eTM·i-αeTe ≤||e||2||M·i||2-α||e||22 =||e||2(||M·i||2-α||e||2), (8)with ||·||2 being the Euclidean norm of a vector. The above equation leads to three different situations as follows:
• Situation i: ||e||2>||M·i||2/α. This situation contributes to V·<0 and V>0, which implies that ||e||2 is convergent until ||e||2=||M·i||2.
• Situation ii: ||e||2=||M·i||2/α. It leads to V·≤0. This suggests that ||e||2 converges to zero or maintains at ||e||2=||M·i||2.
• Situation iii: ||e||2<||M·i||2/α. We deduce that V·>0 or V·≤0. Subsequently, it can be inferred that ||e||2 continues to increase until it reaches Situation ii or it remains unchanged or convergent.
Considering the above three situations, it can be obtained that ||e||2≤||M·i||2/α when t → ∞. Provided a sufficiently large value of α, we have that ||e||2 reaches zero when t → ∞. In conclusion, the estimated error M-M¯ generated by Equation 7b globally converges to a zero matrix. Hence, applying LaSalle's invariance principle (K.Khalil, 2001), we replace M¯ with M in Equation 7b and deduce
τout=M(q)(L†(r¨d-L·q·)-v)+h(q,q·). (9)Therefore, Equation 7b enables dynamic control of the manipulator depending on the desired joint acceleration in kinematic controller (Equation 3).
The desired joint acceleration allows the manipulator to precisely follow a given trajectory, which is proven through the following proof. Primarily, (Equation 3) can be equivalently converted into
Lq¨+L·q·-r¨d=r¨-r¨d=-β(r·-r·d)-ζ(r-rd). (10)Assuming the position error as u = r − rd, the above equation is reorganized as u¨+βu·+ζu=0, which belongs to a second-order differential equation system. The roots of the corresponding characteristic equation are s1=(-β+β2-4ζ)/2 and s2=(-β-β2-4ζ)/2. Furthermore, According to Equations 8–10, we can analyze that the convergence of this system can be categorized into the three cases (Jin et al., 2017).
• Case i: When β2 − 4ζ > 0, we obtain that s1 < 0 and s2 < 0 are real numbers with s1 ≠ s2. Then, the solution satisfies u(t) = c1exp(s1t) + c2exp(s2t) with c1∈ℝb and c1∈ℝb being coefficient vectors determined by the initial state of the system.
• Case ii: When β2 − 4ζ = 0, the system has two equivalent characteristic roots with s1 = s2 < 0. Therefore, the solution can be deduced as u(t) = (c1 + c2)exp(s1t).
• Case iii: When β2 − 4ζ < 0, s1 = z + iy and s2 = z − iy are conjugate complex numbers with z < 0. As a result, the solution can be deduced as u(t) = exp(zt)(c1cosyt+c2sinyt).
These cases demonstrate that the position error u generated by Equation 3 exponentially converges to a zero vector from any initial states. In other words, it is concluded that Equation 7b enables trajectory tracking control of the manipulator with the unknown mass matrix. The proof is thus completed.
5 Simulative results and comparisonsThis section provides simulation experiments to demonstrate the learning and control performance of RNN (Equation 7). Specifically, we test it on a 7-degree-of-freedom manipulator called Franka Emika Panda (Liu and Shang, 2024) to task a four-leaf clover path with α = 104, β = 1, and ζ = 5. In addition, we assume that the mass matrix is unknown and design a random noise matrix with elements < 0.5 to represent its uncertainties. The related results are shown in Figures 2, 3. Figure 2A demonstrates the effectiveness of the proposed method in enabling the manipulator to accomplish trajectory-tracking tasks, even in the presence of an unknown mass matrix. In addition, the initial joint acceleration in Figure 2B is relatively large due to the initial mass matrix error and becomes smooth and normal. Furthermore, the position error keeps the order of 10−5 m in Figure 2C. Similarly, in Figure 2D, it can be observed that the joint torque exhibits reasonable variations. However, when the estimation Equation 7b is not considered, achieving the trajectory tracking task based on Equation 7b becomes challenging due to the presence of the unknown mass matrix. As shown in Figure 3A, the manipulator driven by Equation 7a cannot complete the tracking task. Evidently, the joint acceleration became uncontrollable at ~4.5 s, as shown in Figure 3B, and the manipulator system is no longer operational. Furthermore, the position error exhibits divergence in Figure 3C. Similarly, the joint torque in Figure 3D is out of control at 4.5 s. Through the above results, the learning and control ability of the proposed method are verified.
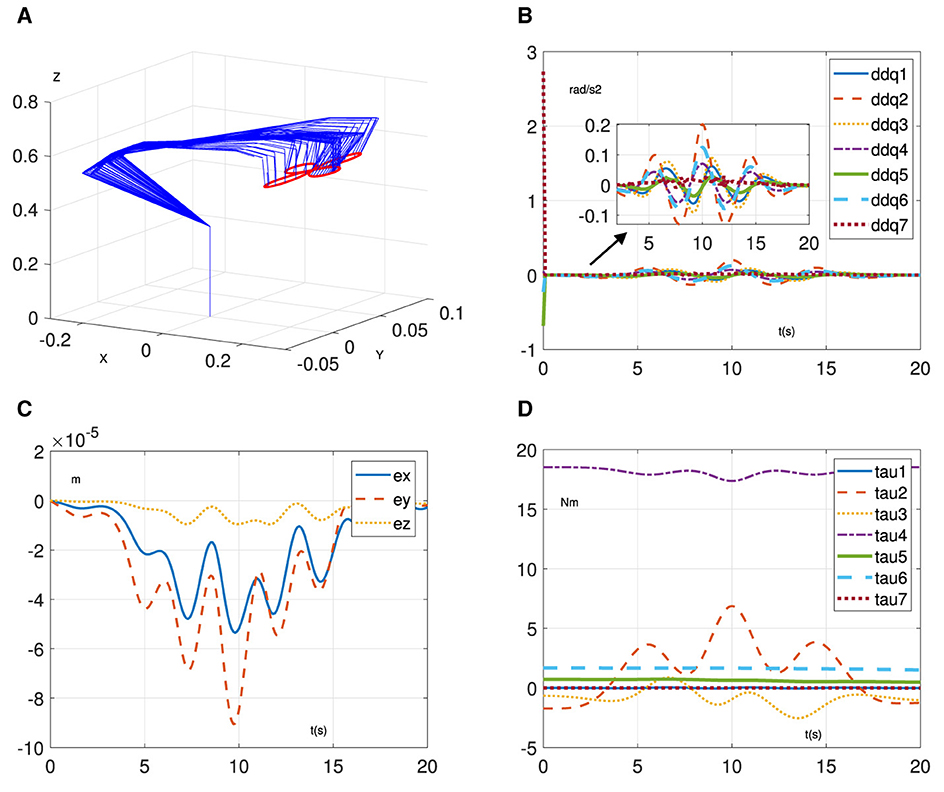
Figure 2. Simulative results of RNN (Equation 7) for trajectory-tracking task on Franka Emika Panda manipulator. (A) Motion process. (B) Joint acceleration. (C) Position error. (D) Joint torque.
留言 (0)