
記住我
With the development of the Internet, sequential recommendation has been widely used in business scenarios (e.g., e-commerce recommendation, media recommendation, and ad click prediction). In such scenarios, the user's historical behaviors can be organized as a chronological sequence of activities. Moreover, sequential recommendation aims to recommend the next item that the user is likely to interact with in the near future based on the user's historical behaviors.
A large number of methods have been proposed for sequential recommendation. Traditional sequential models are usually based on Markov Chain (MC) (Chen et al., 2015; He and McAuley, 2016). A classic model, Factorizing Personalized Markov Chain (FPMC) (Rendle et al., 2010), has been introduced to factorize user-specific transition matrices over Markov Chain, which assumes that the next action is only related to the previous one. However, with the Markov assumption, an independent combination of the past interactions may limit the performance of recommendation (Xu et al., 2019). Recently, with the success of deep learning, many methods based on Recurrent Neural Network (RNN) have emerged (Hidasi et al., 2016; Zhu et al., 2017). These RNN-based methods usually employ the last hidden state of RNN as the user representation, which is used to predict the next action. Despite the success, RNN models are hard to preserve users' long-term dependencies, even using well-designed cell structures such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU). Khandelwal et al. (2018) demonstrate that language models using LSTM can apply approximately 200 context tokens on average. However, only 50 nearby tokens can be sharply distinguished, which reveals that even LSTM has trouble in capturing long-range dependencies. In addition, RNN-based methods need to propagate relevant information step by step, which makes it hard to parallelize (Zhang et al., 2019).
More recently, the self-attention mechanism has achieved great success in natural language processing (Vaswani et al., 2017), which also makes outstanding contributions to sequential recommendation. Compared with RNN, self-attention is more suitable for grasping and preserving the long-term dependencies as it allows the model to interact with any step regardless of distance. Kang and McAuley (2018) proposed the Self-Attentive Sequential Recommendation model (SASRec) that applies a self-attention mechanism to replace traditional RNNs for sequential recommendation and achieves remarkable performance. However, SASRec only considers the sequential patterns between items, ignoring the sequential patterns between features, which is incomplete. In actual scenarios, users' behaviors usually also have transition patterns at the item feature level. A very promising idea to solve the problem is to introduce feature-wise into the model to reduce the prediction space to improve recommendation accuracy. Zhang et al. (2019) and its enhanced version Hao et al. (2023) proposed the FDSA model to capture the full sequential patterns from the item-wise and the feature-wise, where a simple vanilla attention operation is used to obtain the integrated feature representation. Though FDSA captures the feature-wise transition patterns and achieves state-of-the-art performance, it generates the feature combinations using the vanilla attention, which assumes that features are independent of each other. This assumption is obviously not realistic (Yun et al., 2019). For instance, women like skirts, while men prefer pants, indicating there are certain dependencies between gender and category. The vanilla attention applied in FDSA(Zhang et al., 2019) and its enhanced version (Hao et al., 2023) is not carefully designed for learning integration features, and it cannot learn effective integrated features. Capturing the dependencies between the features of an item can help learn meaningful and integrated feature representations, and higher-order feature combinations are crucial for good performance (Lian et al., 2018).
In this study, we propose a novel Feature Interaction Dual Self-Attention Network (FIDS) model for sequential recommendation, which utilizes dual self-attention to capture feature interactions and sequential transition patterns. Specifically, we first utilize self-attention to model feature interactions for each item in the sequence, in which each feature is allowed to interact with all other features and is able to automatically identify relevant features to form meaningful higher-order features using a multi-head attention mechanism. Then, we adopt two independent self-attention networks to capture the transition patterns of the item sequence and the integrated feature sequence, respectively. Moreover, we stack multiple self-attention blocks and add residual connections at each block. For self-attention capturing feature interactions, multiple blocks can model interactions at different orders, and residual connections can combine interactions of different orders. For self-attention capturing sequential patterns, stacking multiple blocks can learn more complex item transitions, and residual connections help propagate the visited items' embedding (or integrated features' embedding) to the final layer. Finally, we conduct extensive experiments on two real-world datasets. Our experimental results demonstrate that considering feature interaction can significantly improve the accuracy of the recommendation.
The main contributions of this study are summarized as follows:
• To the best of our knowledge, this is the first study to learn feature interactions and capture sequential patterns all in the unified self-attention mechanism.
• We propose a novel Feature Interaction Dual Self-attention network (FIDS) model for sequential recommendation, which adopts dual self-attention to model the dependencies between items and the dependencies between features, respectively. Specifically, we first utilize self-attention to model the feature interactions for each item to form meaningful higher-order features. Then, we adopt two independent self-attention networks to capture the transition patterns of the item sequence and the integrated feature sequence. Finally, we combine the feature-wise and item-wise sequential patterns to a fully connected layer for the next item recommendation.
• We conduct extensive experiments on two real-world datasets and demonstrate that our proposed method outperforms the state-of-the-art methods.
2 Related workIn this section, we discuss related work from two aspects, which are sequential recommendation and attention mechanism.
2.1 Sequential recommendationMost of the existing sequential recommendation methods are concentrated on Markov Chain-based models and neural network-based models. In essence, the first-order Markov Chain captures the transition relationship between the current action and the previous action, while the higher-order Markov Chain assumes that the next action is related to several previous actions. In general, the users' former behavior has a more significant impact on the following action, so the first-order MC-based models can still achieve excellent performance. He et al. (2017) proposed TransRec model, considering the first-order Markov Chain. Rendle et al. (2010) combined Matrix Factorization and Markov Chain to model sequential patterns. He and McAuley (2016) dedicated modeling sequential relationships using higher-order Markov Chains and can make meaningful recommendations even in sparse environments. However, models based on Markov Chains rely on strong assumptions, which may limit the recommendation performance. Recently, with the advancement of deep learning, many neural network-based sequential recommendation methods have emerged. Hidasi et al. (2016) adopted GRU to model transitions between items. Despite its success, RNN-based methods still have problems in maintaining long-term user preferences and parallel processing. Moreover, Lv et al. (2021), Manotumruksa and Yilmaz (2020), and Ren et al. (2020) utilize the generative adversarial network to assist sequential recommendation and improve the model performance by enhancing the generalization of the model. Tolstikhin et al. (2021) hope to capture sequence information using a simple MLP structure which may facilitate the simplification of computation. Recently, numerous studies (Chen et al., 2022; Li et al., 2023; Qin et al., 2023) have suggested employing contrastive learning in sequential recommendation (SR) to enhance user representation. However, these sequential recommenders focus only on item sequences and fail to utilize valuable auxiliary information.
2.2 Attention mechanismIn recent years, attention mechanism has been widely used in various tasks, including machine translation (Huang et al., 2016; Miculicich et al., 2018; Zhang J. et al., 2018), computer vision (Jaderberg et al., 2015; Wang et al., 2017; Hu et al., 2018), and recommendation system (Zhang S. et al., 2018). The success of the Transformer (Vaswani et al., 2017) and BERT (Devlin et al., 2019), which can model syntactic and semantic patterns between words in a sentence very efficiently, stimulates the development of the self-attention mechanism in sequential recommendation. Kang and McAuley (2018) and Sun et al. (2019) employed the self-attention mechanism to model sequential patterns and proved that the self-attention network is superior to RNN/CNN-based models. Zhou et al. (2018) proposed an attention-based user behavior modeling framework, which projects heterogeneous user behaviors into multiple potential semantic spaces, where the influence between behaviors is captured by self-attention. Huang et al. (2018) also captured the polymorphism of user behaviors through a feature-wise self-attention network and dynamically modeled the contextual dependency via the forward and backward position encoding matrices. Lately, Zhang et al. (2019) focused on conducting the feature sequence via vanilla attention and modeling sequence transition patterns from the feature-wise and item-wise.
2.2.1 DifferenceThe methods mentioned above either only model sequential patterns from a single level (i.e., item-wise) or coarsely integrate feature representations with vanilla attention, which cannot model accurate integrated features and may limit the accuracy of recommendations. Inspired by Song et al. (2019), who adopted a multi-head self-attention to capture feature interactions automatically for Click-Through Rate (CTR) prediction. In this study, we learn feature interactions and capture item-wise and feature-wise sequential patterns under a unified self-attention framework.
3 Proposed modelIn this section, we introduce the Feature Interaction Dual Self-attention network (FIDS) model. We first formulate the problem definition and then present the architecture and the details of our proposed model.
3.1 Problem statementSequential recommendation aims to predict the next item that the user interacts with, based on his/her historical interaction sequence. We formulate the sequential recommendation before introducing our proposed model details. We let U= denote the set of users and I= represent the set of items, where |U| and |I| represent the number of users and items, respectively. We use S= to represent the sequence of items that the user has interacted with in a chronological order, where si∈I. In addition, item si∈S corresponds to a set of features Ai=, where m represents the number of features of each item in the dataset. The goal is to recommend the next item i∈I that user u∈U might interact with. For clarity, Table 1 lists the symbols involved and their definitions.
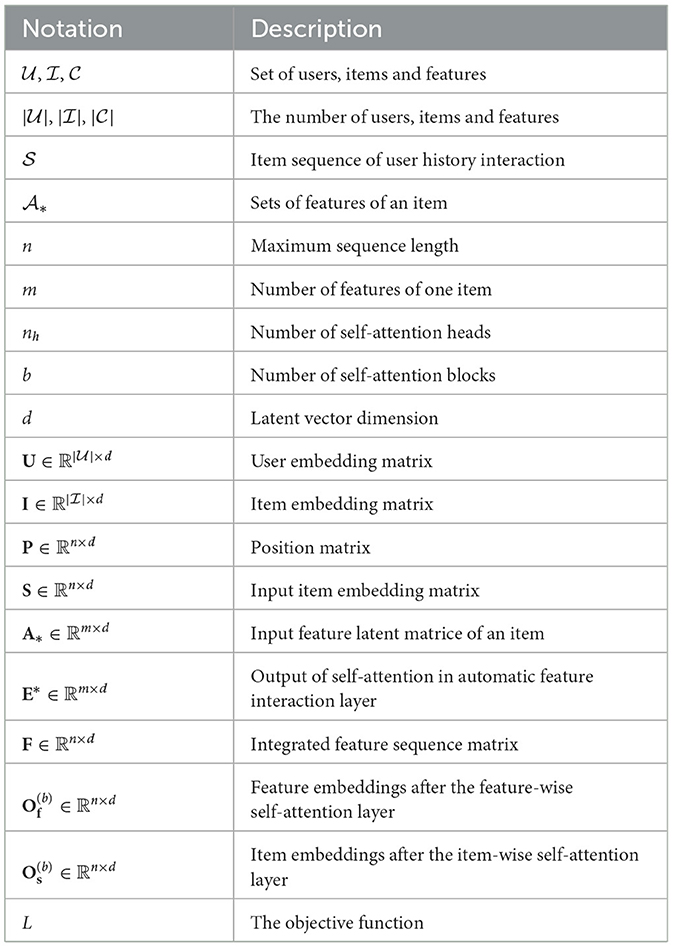
Table 1. Table of notations.
3.2 The architecture of FIDSWe propose a novel Feature Interaction Dual Self-Attention Network, the basic idea of adopting a dual self-attention network to generate an accurate feature sequence by considering feature interactions and capturing the full sequential patterns from item-wise and feature-wise. We mainly consider the following characteristics of users' sequential behaviors.
1) The users' sequential behavior is not only related to the item sequence but also closely related to the feature-wise sequential pattern.
2) For each item, feature interaction can capture a more comprehensive integrated feature, thereby enhancing the expressive ability of feature-wise modeling sequential dependencies.
3.2.1 Automatic feature interactionModeling feature interactions with the self-attention mechanism has proven effective in click-through rate (CTR) prediction tasks (Song et al., 2019; Yun et al., 2019). Inspired by them, we use n self-attention modules to model the interaction between the features corresponding to n items automatically in the automatic feature interaction layer, where n represents the historical interaction number of the input sequence. Each self-attention module acts on one item's features and generates integrated higher-level features. Then, we use the vanilla attention to select and merge its output into a d-dimensional feature vector for each item. In this way, meaningful feature representations have been generated. The second problem mentioned above has been solved.
3.2.2 Capturing transition patternsZhang et al. (2019) proved that only the item level is not enough to model the entire sequence pattern. Here, we model the feature-wise transition patterns and the item-wise transition patterns in the feature-wise self-attention layer and the item-wise self-attention layer, respectively. More specifically, we use two self-attention networks with independent parameters to model item-wise and feature-wise transition patterns.
As shown in Figure 1, FIDS consists of five parts, namely, an embedding layer, an automatic feature interaction layer, an item-wise self-attention layer, a feature-wise self-attention layer, and a prediction layer. Specifically, we first project the items and relevant features into dense vector representations. Then, the automatic feature interaction layer adopts multi-head self-attention networks to learn higher-order interactions between features automatically and generate the feature sequence. Subsequently, the feature-wise sequential patterns and the item-wise sequential patterns are learned in the feature-wise self-attention layer and the item-wise self-attention layer, respectively. Finally, we combine the two sequential patterns and recommend the next item in the prediction layer. Following, we elaborate on the details of our proposed model FIDS.
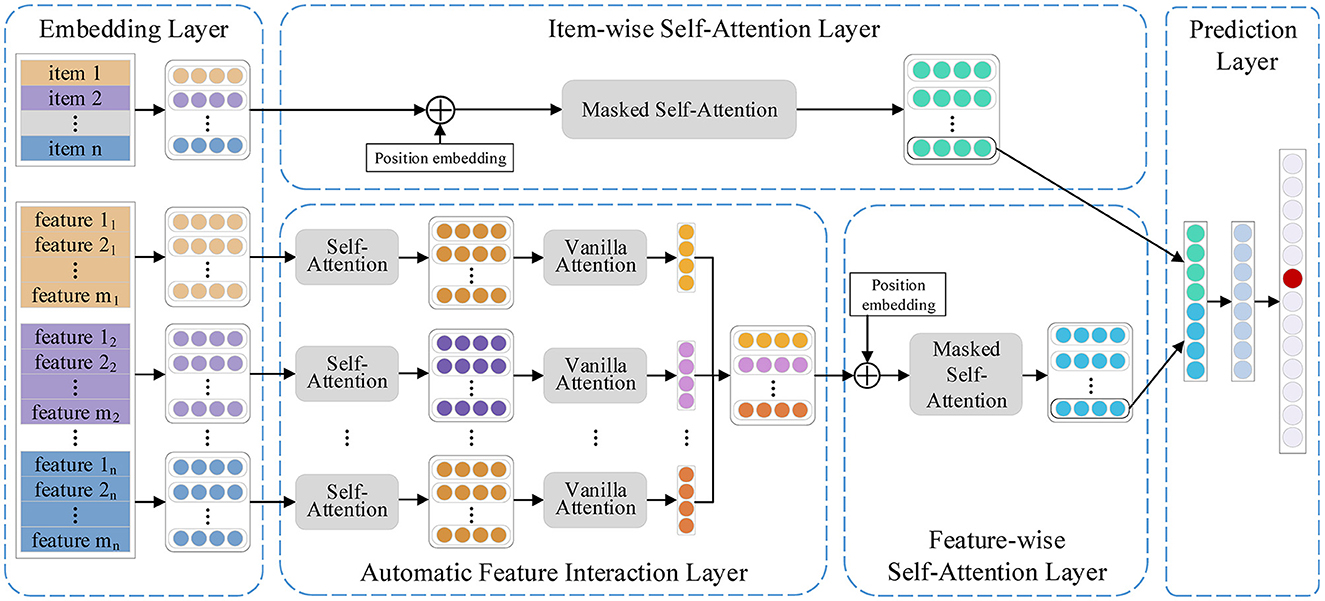
Figure 1. Framework of feature interaction dual self-attention network.
3.3 Embedding layerWe convert the user historical interaction sequence into a fixed-length sequence s = (s1, s2, ..., sn), where n represents the maximum length that the model can accommodate. If the sequence length is longer than n, we intercept the n items that the user has recently interacted with. For the length of sequences less than n, we adopt a zero-padding strategy. We first map the item sequence into a dense latent matrix V∈ℝn×d, where d represents the latent dimension. Since the self-attention mechanism does not have position awareness, we generate a learnable position matrix P∈ℝn×d to model the position relationship (Kang and McAuley, 2018). Each item in the sequence corresponds to a set of features, and we generate a feature matrix Ai∈ℝm×d for item si, where m is the number of features of each item. Then, the original feature sequence can be expressed as a matrix sequence f = (A1, A2, ..., An).
In short, the embedding layer generates three sequences: item sequence, position sequence, and feature sequence. We use S∈ℝn×d and P∈ℝn×d to represent the item and position sequence embedding matrix respectively. A*∈ℝm×d is used to represent an element of the feature sequence.
3.4 Automatic feature interaction layerThe critical task at the automatic feature interaction layer is to learn meaningful higher-order combined features. Song et al. (2019) proved that self-attention network can effectively construct higher-order feature interactions in CTR prediction tasks. Inspired by it, once the feature matrix Ai about the i-th item is obtained, we use a self-attention mechanism to learn higher-order interactions between features. We adopt the widely used scaled dot-product attention (Vaswani et al., 2017), which is defined as follows:
Attention(Q,K,V)=softmax(QKTd)V (1)where Q, K, and V represent queries, keys, and values, respectively. The term 1d constrains the scale of the dot products, where d is the latent dimension. For the task of learning the higher-order interactions between features, Q, K, and V are all generated by Ai. We first transform the feature matrix Ai into three matrices via linear transformation and feed them into Attention to learn higher-order interaction features.
HAi=Attention(AiWQ,AiWK,AiWV), (2)where WQ, WK, WV∈ℝd×d are learnable weights. By doing this, each feature vector is obtained by summing all feature vectors with all attention scores.
3.4.1 Multi-head self-attentionWe adopt a multi-head self-attention to map different feature interactions to multiple subspaces and concatenate the outputs of different subspaces:
MAi=[h1;h2;...;hnh]WAi,hj=Attention(AiWjQ,AiWjK,AiWjV), (3)where nh denotes the number of heads in the automatic feature interaction layer. And WjQ, WjK, WjV, and WAi are weight matrixes.
3.4.2 Residual connectionTo a certain extent, the deeper the network is, the stronger the expression ability and the better the performance will be. However, the increase of network depth also brings many problems, such as gradient disappearance and gradient explosion. Therefore, simply adding more layers does not directly correspond to better performance. He et al. (2016) proposed residual networks which help propagate lower features to higher features. To preserve the combined features learned previously, we apply residual connections to combine different order features:
MAi′=LayerNorm(MAi+Ai), (4)where LayerNorm is Layer Normalization (Ba et al., 2016), which is used to constrain the parameter range in order to alleviate overfitting, and what we adopt is the same as Kang and McAuley (2018):
LayerNorm(x)=α⊙x-μσ2+ϵ+β, (5)where x is the assumed input and μ, σ2 are mean and variance. ⊙ is the Hadamard product. And α, β are learnable parameters.
3.4.3 Feed-forward networkAlthough the self-attention network has strong learning capabilities, it still cannot get rid of the fact that it is a linear model. To endow the model with non-linear capabilities and consider the interaction at the dimensional level at the same time, we then add two fully connected layers:
OAi=ReLU((MAi'W1+b1)W2+b2), (6)where W1, W2∈ℝd×d, b1, b1∈ℝd are weight matrixes and bias, respectively. In essence, each feature of OAi has merged the two-order influence of other features on itself.
3.4.4 Multiple self-attention blocksTo capture higher-order combined features, we stack multiple self-attention blocks. We use SAttB (Self-Attention Block) to represent the above self-attention process for simplifying; then, the entire process of stacking multiple self-attention blocks can be expressed as
OAi(1)=SAttB(Ai), OAi(2)=SAttB(OAi(1)), ......Ei=OAi(b)=SAttB(OAi(b−1)), (7)where OAi(b)∈ℝm×d is the output after stacking b self-attention blocks about item i, and b (b> = 1) is the number of self-attention blocks.
3.4.5 Vanilla attentionNext, we use vanilla attention to merge mixed feature matrix to a feature vector and select which features determine the user's choice:
fi=∑jmαjeji,αj=exp(eji)∑kmexp(eki), (8)where eji is the j-th row of Ei. The term fi∈ℝd is higher-order integrated feature of item i. Then, the feature-wise sequence can be translated to F = (f1, f2, ...fn), where fi represents the fused high-order feature corresponding to item i. And we let F∈ℝn×d denote the integrated feature sequence matrix.
3.5 Feature-wise self-attention layerOnce the feature sequence F = (f1, f2, ...fn) is obtained, we continue to use a same self-attention network to preserve the contextual information and learn the dependencies between features, and then, we try to generate a transition sequence F′=(f2,f3,...fn+1). The last row of the output matrix in this layer corresponds to the fusion feature of the next item that the user may be interested in.
3.5.1 Position-codingSince the self-attention network ignores the positional relationship, we add position-coding P∈ℝn×d to the feature sequence matrix F to preserve the order of user interactions:
F=[f1+p1f2+p2···fn+pn]. (9)Then, we send the sum matrix to the self-attention blocks to capture the user's sequential patterns from the feature-wise, which is shown as follows:
Of(1)=SAttB(F),Of(2)=SAttB(Of(1)), ......Of(b)=SAttB(Of(b−1)), (10)where Of(b)∈ℝn×d is the learned feature transition matrix, the last row of which can be interpreted as the next fusion feature that the user might be interested in.
3.5.2 MaskUnlike learning high-level feature interactions, when modeling sequential transition patterns, we must limit the influence of items purchased in future on items purchased in the past due to the inherent sequence of sequences. More specifically, we adjust the attention weights to 0 to eliminate the influence of fi on fj, where i>j.
3.5.3 DifferenceThe automatic feature interaction layer and the feature-wise self-attention layer (or the item-wise self-attention layer, which will be introduced in detail later) are different when using self-attention, although both utilize the attention mechanism. 1) We do not need to consider position-coding when automatically capturing feature interactions as there is no positional relationship between features of an item. However, modeling sequential patterns requires position-coding to learn the location contact. 2) When modeling feature-wise sequential patterns (or item-wise sequential patterns), the impact of future features (or items) on past features (or items) needs to be masked, but no mask is required when capturing feature interactions as there is no order between features. In addition, they have diverse interpretations when using self-attention. Multiple block stacking is used to model different order interactions and learn more complex sequential patterns in the modeling feature interaction task and capturing sequence mode, respectively. Residual connections can combine interactions of different orders in the feature interaction task. When modeling the transition patterns, it helps propagate integrated features' embedding (or the visited items' embedding) to the following layer.
3.6 Item-wise self-attention layerThe item-wise self-attention layer aims to learn the dependencies between items. Similar to feature-wise, for a given item sequence S = (s1, s2, ..., sn), this layer try to learn a transition sequence S = (s2, s3, ..., sn+1). In detail, we first attach a position-coding to the item sequence S. Then, put it into stacked self-attention blocks, as shown follows:
S=[s1+p1s2+p2···sn+pn
留言 (0)