Participants
Four children, Dave, Elliot, Isaac, and Eva, participated in the study. The participants were between 3 and 4 years of age, and they had all been diagnosed with autism or pervasive developmental disorder based on the ICD-10 criteria (World Health Organization, 2007). All of the participants were diagnosed using the Autism Diagnostic Observation Schedule-Second Edition (ADOS-2; Lord et al., 2012), and the Autism Diagnostic Interview-Revised (ADI-R; Rutter et al., 2003). They were enrolled in early intensive behavioral intervention (EIBI) programs in local day care centers. None of the participants had received direct training in BiN skills prior to this study. At the time of the study, all of the participants were assessed using the Assessment of Basic Learning and Language Skills-Revised (ABLLS-R; Partington, 2006). See Table 1 for a more detailed description of the participants’ mastery of each skill area.
Table 1 Participant characteristicsTo be eligible for the study, the participants had to vocally imitate (echo) sentences of up to 3 to 4 words. Participants’ ABLLS-R scores were used to determine whether they had the minimum skills required to be included in the study. They had to respond as a listener to at least 50 words, and also tact at least 50 words. Listener responding was defined as the participants touching or pointing to the correct stimulus (picture) from an array of stimuli when asked. Tacting was defined as the participants emitting the correct name of the stimulus when asked. The participants also could not engage in BiN to qualify for the study. BiN for a particular stimulus was defined as the participants showing correct listener and speaker behavior after observing another person naming a stimulus twice. If the participants demonstrated BiN for more than two out of the five probes, they were excluded from the study.
Setting
The study was conducted in the participants’ local day care centers, where they received their daytime EIBI-programming. Probing and intervention sessions were conducted in separate teaching rooms. These were the same rooms that were used for most of their other intervention programs. The participant and the experimenter were seated facing each other at a table. The sessions lasted around 15 to 30 minutes. The first author trained and supervised the day care center teachers who, together with the first author, implemented the intervention. Generalization was assessed in two ways. The first was to evaluate generalization across activities not related to training sessions (e.g., meals, free play, and during transitions), and across settings (e.g., play areas, bathrooms, locker rooms, etc.). The second was to assess generalization across people who were not involved in the project (e.g., staff, parents, or children attending the day care centers). These second generalization assessments were conducted in the participants’ teaching room.
Materials
We recorded data using data sheets tailored for the project. They were the same for every participant. Written descriptions of the probe and intervention procedures were available for the teachers, both in the teaching rooms and in the generalization settings. Potential reinforcers, stimuli such as toys, food, or games, were provided through a token economy system, tailored to each participant. The token system was the same one used during their EIBI sessions. Stimuli that were used as backup reinforcers were chosen based on teacher and parent reports. The reinforcement schedule for the token economy was a continuous reinforcement schedule (CFR) during initial training trials of newly introduced stimuli. After the mastery criterion was met, the schedule was thinned to a variable ratio 3 schedule (VR3).
Pictures cards were prepared to assess and teach BiN. They were 9 cm by 9 cm color photos of stimuli against a transparent/white background. For each participant, we chose stimuli from one of the following categories: wild animals, fruit and vegetables, or children’s characters from TV/movies, etc. The participants had some knowledge of some members of these categories; more uncommon members of the category were therefore selected. Dave’s cards included children’s characters from TV-series such as Bart from The Simpsons and Dizzy from Bob the Builder, from children’s movies such as Dumbo, Simba, and Pinocchio, or game characters like Mario. Elliot’s cards included fruit, berries, and vegetables (e. g., ginger, chili, artichoke, parsnips, raspberry, and grapefruit). Isaac and Eva’s cards were wild animals (e.g., a gorilla, wasp, scorpion, llama, hedgehog, or pelican). Stimuli used for generalization probes were conducted using objects found in the daycare centers that the participants typically did not interact with, such as knife steel, screw bit, file, egg slicer, wrench, and corkscrew. For Dave’s generalization probes, pictures of children’s characters were used.
Dependent variable and data collection
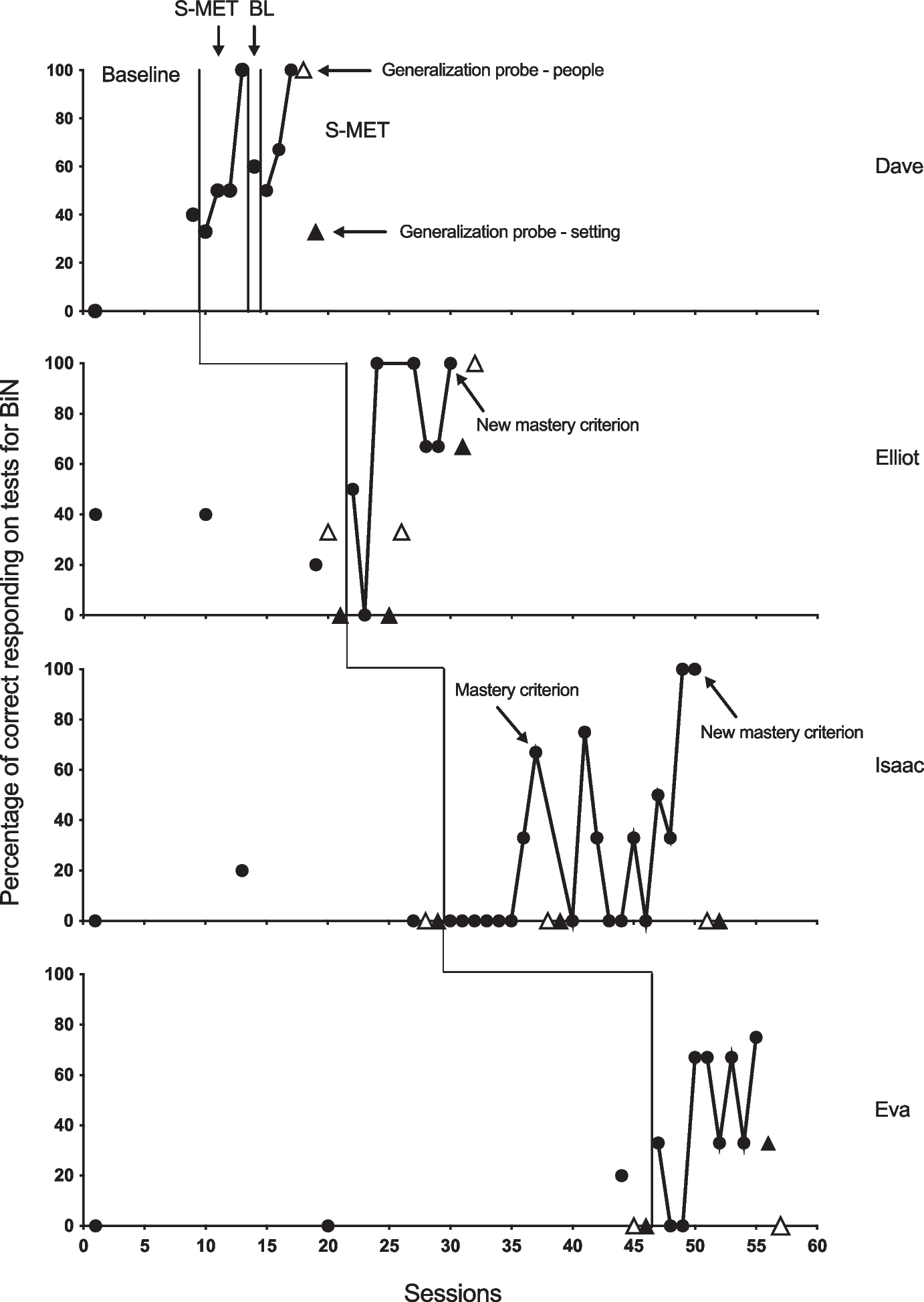
The primary dependent variable was the percentage of correct responding on probes for BiN. A probe for BiN for one stimulus consisted of eight listener trials and five speaker trials. All listener and speaker trials had to be correct for the BiN probe to be scored as correct. When probing for listener responding there was a possibility that the participant could respond correctly by chance. This was not the case when probing for speaker responding, which is the reason that there were more listener (8) trials compared to the speaker trials (5). The BiN probe data were calculated as a percentage of correct responses. A correct listener response was defined as touching/showing/selecting the correct stimulus from an array of five stimuli after being given the instruction, “Touch (stimulus).” A correct response was recorded if the participant correctly touched/showed/selected the stimulus within five seconds of the instruction. An incorrect response was recorded if the participant did not respond within five seconds, or selected an incorrect stimulus. A correct speaker response was defined as a correct tact of the stimulus presented when asked, “What is it?”. A correct speaker response was recorded if the participants correctly labeled the stimulus within five seconds of the instruction. An incorrect response was recorded if the participant did not respond within five seconds, or labeled the stimulus incorrectly. We recorded data as correct or incorrect on a trial-by-trial basis. During generalization probes, the dependent variable was the percentage of correct speaker responses. A response was recorded as correct if the participant labeled the stimulus within five seconds when asked, “What is it?”. A response was recorded as incorrect if the target response was not emitted within five seconds of the question, or it was labeled incorrectly. Probing only the speaker part of BiN was done for practical reasons. The reasoning was that it would be easier to probe speaker responses during ongoing activities during the course of a typical day at school or during sessions. Whereas probing listener responses would require an interruption in the activity and involve special arrangements of the stimuli.
Design
We used a non-concurrent multiple baseline design (Watson & Workman, 1981) across participants to evaluate the effects of the S-MET procedure. The experimental sequence was initiated at different times for each participant, and we randomly assigned the participants to different baseline lengths. Dave was assigned to a one-week baseline length, Elliot to a three-week baseline, Isaac to a four-week baseline, and Eva to a five-week baseline. For the one-week condition, there were two baseline probes, on day 1 and day 7. For the three-week condition, there were three probes, on day 1, day 10, and day 21. The four-week condition had three baseline probes, on day 1, day 13, and day 28. Lastly, for the five-week condition, there were three baseline probes, on day 1, day 20, and day 35.
Procedure
During pre-experimental procedures and BiN probes, participants only received reinforcement for general effort and attention. We provided praise (e.g., “You are working so hard!”) and a token when the participant was looking at the experimenter or sitting nicely. During S-MET, we provided reinforcement (token and praise; e.g., “Baboon, that is correct”) contingent on correct responding to the target stimulus. The consequence for prompted correct responses was praise, only. Reinforcement was not provided for incorrect or no responding. The order of the experimental procedure is displayed in Table 2.
Table 2 The order of the experimental conditionsPre-experimental assessments
Pre-experimental assessments included an echoic, tact, and listener assessment for every stimulus and they were conducted before the baseline condition. The stimuli were probed in random order for each of the three assessments. The participants were given two opportunities to respond per stimulus. The participants had to respond correctly within five seconds of the instruction. An echoic assessment was administered to see whether the participants were able to echo the name of the stimulus. We presented the instruction “say (stimulus).” Stimuli that the participants were unable to echo were excluded from the study. A tact assessment was administered to determine whether the participants could respond as a speaker. We showed the participants one stimulus at a time and asked, “What is it?”. If the participants could tact the stimulus (responded correctly during one of two opportunities), the stimulus was excluded from the study. A listener assessment involved presenting the target stimulus along with two stimuli that were known and two stimuli that were unknown in a line in front of the participant, for a total of five stimuli. We instructed the participants to touch the target stimulus (e. g., “touch garlic”). Trials with the target stimulus were randomly interspersed with trials with the two known stimuli. If the participants responded correctly during both trials of the target stimulus, the stimulus was excluded from the study. Stimuli that were not excluded in the pre-experimental assessment were randomly assigned to either the baseline or the S-MET condition. Praise (e.g., “I like how hard you are working”) and tokens were provided contingent on looking at the experimenter, on good sitting, and on responding, and distributed equally between correct and incorrect responses. We provided praise on a CRF schedule, and tokens on a VR3 schedule. One to three assessment sessions were conducted per day. Sessions were conducted two to five days each week.
Baseline probes
Each baseline session consisted of five probes with five unknown stimuli. The BiN probes for each stimulus were conducted in three steps:
Step 1 was modeling of the tact
We showed a picture of the target stimulus while the participants observed, and then said the name of the stimulus twice, with five seconds in between each presentation of the stimulus name. In step 1, the only requirements for the participants were to look at the experimenter and the stimulus presented. This step could be considered to be an approximation of how children with BiN skills learn the names of novel stimuli in natural settings.
Step 2 was the listener probe
We placed five stimuli in a line on the table in front of the participants. These included the target stimulus, two known, and two unknown stimuli. We instructed the participants to touch a stimulus (e.g., “touch elephant”). A total of eight trials were conducted; asking for the target stimulus in three trials, and the two known stimuli in five trials. In order to pass the listener probe, the participants were required to respond correctly during all eight trials. The order of the stimuli was randomized across trials, while the positions on the table were also rotated. The participants were not instructed to touch the two unknown stimuli. The unknown stimuli were later probed and trained using S-MET.
Step 3 was the speaker probe
We showed the target stimulus to the participants and asked, “What is it?” A total of five trials were conducted and it involved asking the participants to tact the target stimulus in three trials and two known stimuli in two trials. In order to pass the speaker probe, the participants were required to respond correctly during all five trials.
To pass the BiN probe, the participants’ responding needed to meet the above criteria during both the listener and speaker probes. Hence, a total of 13 (eight + five) consecutive correct trials of listener and speaker responses for each stimulus probed were required. A total of 65 trials were conducted per baseline session. We only presented the tact during step 1 and not during steps 2 and 3.
Pre-training generalization probes
Pre-training generalization probes were conducted on the same day as or the day after the last baseline probe session. Two types of generalization probes were conducted. During the settings probe, we assessed responding to three stimuli in other settings and using different activities, but with the experimenters. During the people probe, the assessment was conducted in the participants’ regular teaching room but by people other than the experimenters (e.g., children attending the day care center, staff, or the participant’s mother or father visiting the day care center). Staff who were part of the project were present during these generalization probes, but did they not conduct the probe trials. The novel person (e.g., the father) showed the participant the stimulus while saying the name of it once (e.g., held up the wrench and said “wrench”). After 30 seconds, the novel person showed the participant the stimulus again and asked, “What is it?”. The participants had one opportunity to answer correctly. Praise was provided for responding to the instruction, whether or not the responses were correct. No stimuli were probed twice. The generalization probes differed from the BiN probes used in baseline and S-MET in three ways: (1) unknown objects found in the participant’s environment were utilized, and not stimuli from the categories used in baseline and S-MET, (2) the name of each stimulus was only presented once, and (3) only the speaker behavior was assessed. We conducted generalization probes in this manner because this more closely approximates how children learn language in the natural environment. For Dave, generalization probes were not conducted prior to the intervention since he was the first participant in this study to complete the procedures. We introduced pre-training probes for the remaining participants in order to more effectively evaluate the results of the post-training probes.
Serial Multiple Exemplar Training (S-MET)
S-MET was conducted on the same day as or the day after the pre-training generalization probes. Stimuli for S-MET were randomly selected from stimuli not excluded during the pre-experimental assessment. We introduced training for one stimulus at a time. The intervention started with a BiN probe for the first stimulus. The probe was procedurally identical to baseline probes. If the participants mastered the BiN probe for the particular stimulus (e.g., baboon), the next stimulus on the list was probed for BiN (e.g., otter). If the participants failed the BiN probe of the stimulus (e.g., baboon), only the response forms of the target behavior the participant failed (listener response, speaker response, or both) were trained (e.g., if they failed the listener portion but passed the speaker portion, only the listener response was targeted). After we trained the target response to mastery, the next untrained stimulus (e.g., otter) became the target stimulus and was probed for BiN. Following this procedure, the remaining stimuli on the list were probed one at a time. We used the results of this probing procedure as one measure of evidence of BiN. After the participants engaged in BiN to mastery for three consecutive stimuli (e.g., otter, antelope, and condor), the training was concluded. For two of the participants, Elliot and Isaac, we established a higher criterion of five consecutive BiN probes to see whether this higher criterion would improve stimulus generalization.
If the participant’s responding did not meet mastery during the listener probe, we trained listener responding for that particular stimulus. Since listener training included echoic training, it will be described as listener and echoic response training, hereafter. During listener and echoic response training, we placed the target stimulus in a line on the table together with two known and two unknown stimuli. We presented the instruction “touch (stimulus).” We used a prompting procedure on the following trials if the participants responded incorrectly or did not respond to the instruction. The choice of prompts depended on which type of error the participants made. If the participants did not echo the instruction, an echoic prompt was used. We used a constant time delay of four seconds to fade the echoic prompt. For some participants, we modeled both the sequence of the echoic response and the pointing response if they did not select the stimulus. If needed, we physically blocked the participants’ hands by gently holding the them back so that they echoed the name before touching it. Another prompt involved positioning the correct stimulus closer to the participants to teach them to respond correctly as a listener. Position prompts were faded using a most-to-least procedure, fading the position prompt from full position, to half position, then to no position. An example of a prompt fade is “touch (stimulus),” and immediately providing the prompt “say (stimulus),” while blocking and then releasing the participants hands so that they could point to the target stimulus while the target stimulus was in full position. The echoic prompt was faded first, then the blocking prompt, and lastly the position prompt. During listener probing and training trials, the two unknown stimuli on the table were the next two stimuli on the list to be probed. For example, if the list of stimuli to be probed and trained consisted of baboon, bison, and octopus, the first to be probed was baboon, while the two unknowns would be bison and octopus. The known stimuli on the table were the last two mastered stimuli from probing and training. If no stimuli had been mastered at the start of the intervention or in baseline probes, stimuli were used that were mastered from the pre-experimental assessment or stimuli that we knew the participant was familiar with. If the participants responded incorrectly in a trial with previously mastered stimuli (distractors), they were trained using the same prompting and prompt fading procedures.
If the participant failed the speaker probe, we trained speaker responding. We held up the card, asked the question, “What is it?”, and prompted responding by modeling the correct response, “say (stimulus).” After a prompted trial, we repeated the instruction and then faded the prompt using a constant time delay of four seconds between the instruction and the echoic prompt. This was done until the participants responded independently to the instruction. The known stimuli we used in speaker training were the two previously mastered stimuli from probing and training. Previously mastered stimuli that the participants did not respond to correctly during training trials were trained, as was done during listener training. We used differential reinforcement during both listener and echoic response training, and speaker training. Correct prompted responses produced praise. Correct independent responses produced praise using a CRF schedule, and a token was delivered according to the reinforcement schedule that was in place (CRF or VR3). Incorrect responses did not produce praise or a token, and the participants only received corrective feedback (e.g., “No, it is not falcon. It is bluebird”).
The mastery criterion in listener and echoic training was eight consecutive correct trials in a random mix with mastered stimuli, provided that the target stimulus was asked for three times in this mix. We rotated the positions of the stimuli for each trial. In the speaker training, the criterion was five consecutive correct trials in a random mix with mastered stimuli, provided that the target stimulus was asked for three times in the mix. We conducted training between three to five days a week, for one to three sessions per day. Training was stopped for a few days if the participants or experimenters were ill. Each training session consisted of the probing and/or training of two to four stimuli. A varying number of training trials were targeted per session. An estimate based on the available data suggests that between 20 to 60 trials were conducted for each stimulus if both listener/echoic and speaker behavior were trained for the stimulus, fewer if only one response form was trained, and no trials if the participants demonstrated responding to mastery during the probe trials. We provided the participants short breaks during training sessions. Breaks in S-MET were not provided during BiN probes (steps 1–3), only during listener and echoic, and/or speaker training. An outline of the intervention procedure is displayed in Table 3.
Table 3 The procedure for serial multiple exemplar training. After assessing for BiN, different responses were trained depending on the resultsPost-training generalization probes
For Dave, generalization probes were conducted as regular BiN probes similar to those conducted in the baseline and treatment conditions, which involved probing both listener and speaker responding. Full BiN probes were extensive and involved an abundance of probing material. Therefore, we simplified the generalization probes for the remaining participants. For Elliot, Isaac, and Eva, the generalization probes were procedurally identical to the pre-training generalization probes. Post-training generalization probes were conducted on the same day as the mastery criterion for BiN was reached for Dave, Elliot, and Eva, and on the following day for Isaac.
Interobserver agreement
A subset of sessions had an independent observer present to collect data for the purpose of measuring interobserver agreement. Both observers independently scored the participant’s responses as either incorrect or correct. We calculated interobserver agreement by dividing the number of agreements by the number of disagreements plus agreements and multiplying by 100. IOA was assessed during 73.4% of Dave’s trials, 27.5% of Elliot’s trials, 31.7% of Isaac's trials, and 34.7% of Eva’s trials. The mean agreement was 98.7% for Dave (range 97.3–100%), 99.3% for Elliot (range 97.4–100%), 97.1% for Isaac (range 96.8–100%), and 95.3% for Eva (range 90.7–100%).



留言 (0)