The scoping review will be conducted following the guidance of JBI [17] and reported in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews (the PRISMA-ScR) [18].
Inclusion and exclusion criteria
Following the JBI guidance [17], the inclusion and exclusion criteria for the proposed review are categorised in terms of participants, concept, context, and sources (Table 1).
Table 1 Inclusion and exclusion criteriaSearch strategy
We have worked with an experienced information specialist at the Karolinska Institute Library and developed a search strategy that was informed by the strategy used by Cranley et al. [11]. Time span for searches in MEDLINE (Ovid), Embase (embase.com), Web of Science Core Collection, and CINAHL (Ebsco) is from inception to September 2020. The initial search strategy for MEDLINE (Ovid) is displayed in Table 2. In addition, we will review the reference lists of included articles. A secondary search to identify recently published articles will be performed prior to the completion of this review.
Table 2 Search strategy for MEDLINE (Ovid) and initial hitsStudy selection
Following the searches, duplicates will be excluded in EndNote using an automatic function. References will be transferred to Rayyan (https://rayyan.qcri.org/welcome) where the screening of titles and abstracts will be performed. The reviewers will ensure consistency in screening through conducting the following steps: (1) joint screening until all reviewers (n = 10) feel confident to start independent screening, (2) independent blinded screening of 25 titles/abstracts followed by a meeting and discussion to clarify inclusion/exclusion decisions, and (3) repetition of step 2 until an acceptable agreement is reached. For the subsequent process, the reviewers will be divided into five pairs. Each pair will screen a fifth of the titles/abstracts, independently and blinded from each other’s decisions. If consensus is not reached, the title/abstract will still be included not risking excluding an article that might fall within the inclusion criteria when the full text is reviewed.
To ensure consistency in reviewing full texts for inclusion/exclusion, a two-step process will be followed. In the first step, the full team will undertake joint screening of 20 full texts with discussion and clarification of inclusion criteria as appropriate. If needed, this will be repeated. Thereafter, four of the co-authors will assess full-text articles in two pairs, independently and blinded from each other’s decisions. For this process, we will use Covidence (https://www.covidence.org/). In the review of full-text articles, disagreements will be resolved by consensus in the pairs.
Throughout screening abstracts, full texts, and extracting data, the reviewers will have regular meetings to discuss and solve emerging issues.
Data extraction
A preliminary data extraction form that is in line with the aims of this scoping review has been developed. Information extracted from the included full-text articles will comprise publication data, study details, details about facilitation and the facilitator(s), details on training and support and facilitator(s)’ perception of the training. The preliminary data extraction template is presented in Table 3. However, the extraction template may need to be refined as the review process progresses.
Table 3 Preliminary table for data extractionSix of the co-authors, divided into three pairs, will conduct the data extraction. Each pair of co-authors will, independently and blinded from each other’s decisions, extract data from a third of the included full texts. The co-authors will start by extracting data in five articles. Thereafter, the extraction form will be evaluated based on knowledge from this initial work. If needed, the data extraction form will be revised. Modifications will be described in the complete scoping review paper. The tool Data Extraction 2.0 (https://www.covidence.org/) will be used for the data extraction process. Each pair of co-authors will meet and discuss differences in data extraction until they reach consensus. Throughout extraction of data, the reviewers will have regular meetings to discuss and solve emerging issues.
Analysis
The extracted data on the details of training and support/supervision (see Table 3) and facilitator(s)’ perception of the training and support/supervision will be analysed to provide a comprehensive picture of how facilitator training and support is reported in the literature. The number and proportion of studies that report learning outcomes/goals of training (and/or support), content of training (and/or support), dose of training (and/or support), mode of delivery of training (and/or support), pedagogical approach of training (and/or support), characteristics/qualifications of the trainer (and/or supervisor), method(s) used for evaluation of training (and/or support), and facilitator(s)’ perception of training (and/or support) will be presented.
Qualitative data relating to learning outcomes/goals of training (and/or support), content of training (and/or support) pedagogical approach of training (and/or support), characteristics/qualifications of the trainer (and/or supervisor), mode of delivery of training (and/or support), and facilitator(s)’ perception of training (and/or support) will be analysed using an approach of inductive qualitative content analysis [19]. The extracted data for each item will be analysed in a process following three main phases: preparation, organising, and reporting. After reading through the data, open coding of the manifest content will be conducted, and the codes grouped into categories. Categories for each item will be created on a level that is meaningful in relation to the research question and the extracted data. Frequencies for the inductive categories will be reported. Furthermore, we plan to create categories of time intervals that reflect the extracted data on dose of training (and/or support). In addition, median, mean, minimum, and maximum dose (hours) will be calculated. Throughout the process of analysis, we will have a flexible approach and adapt the analyses to the extracted data.
Presentation of the results
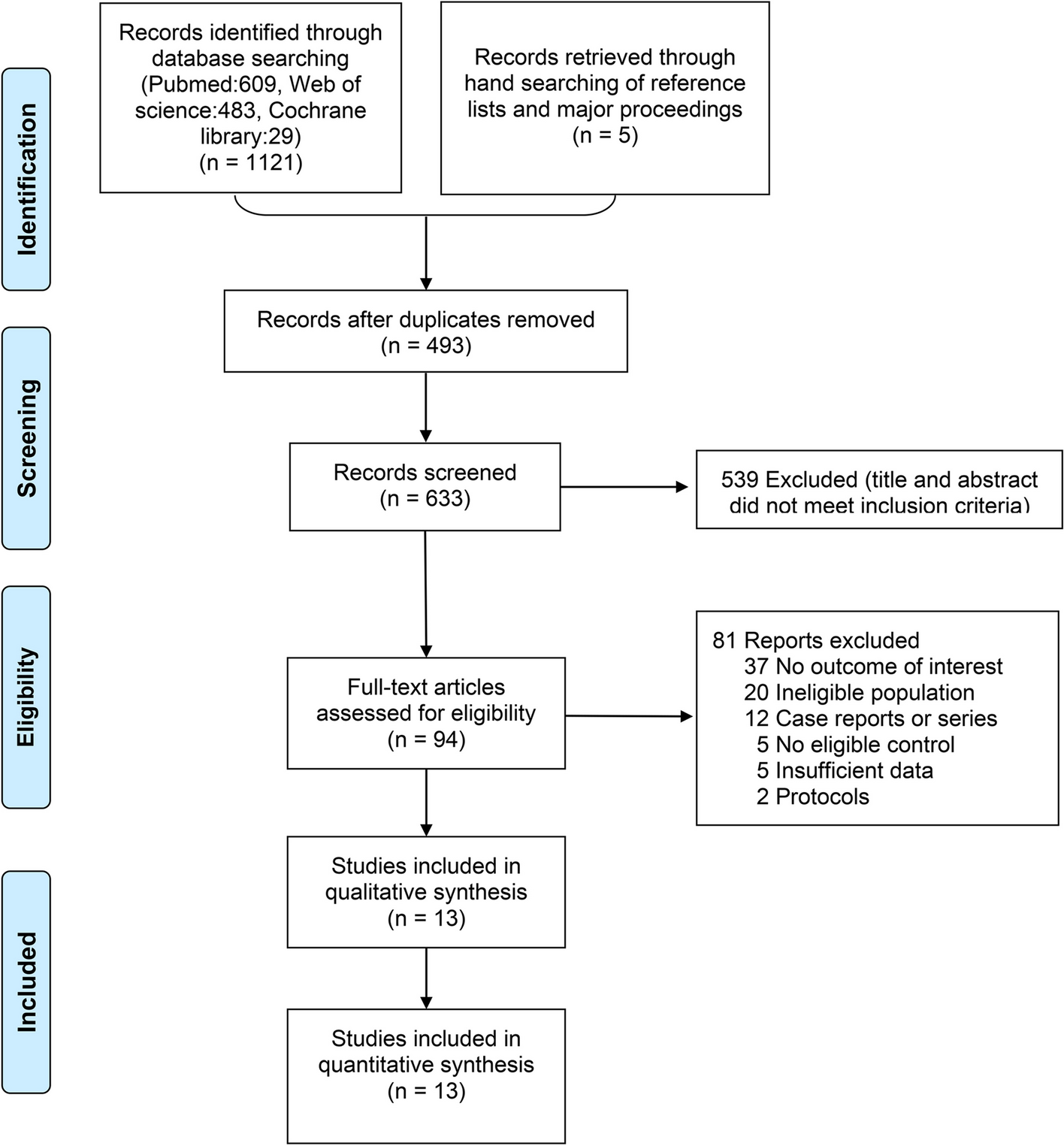
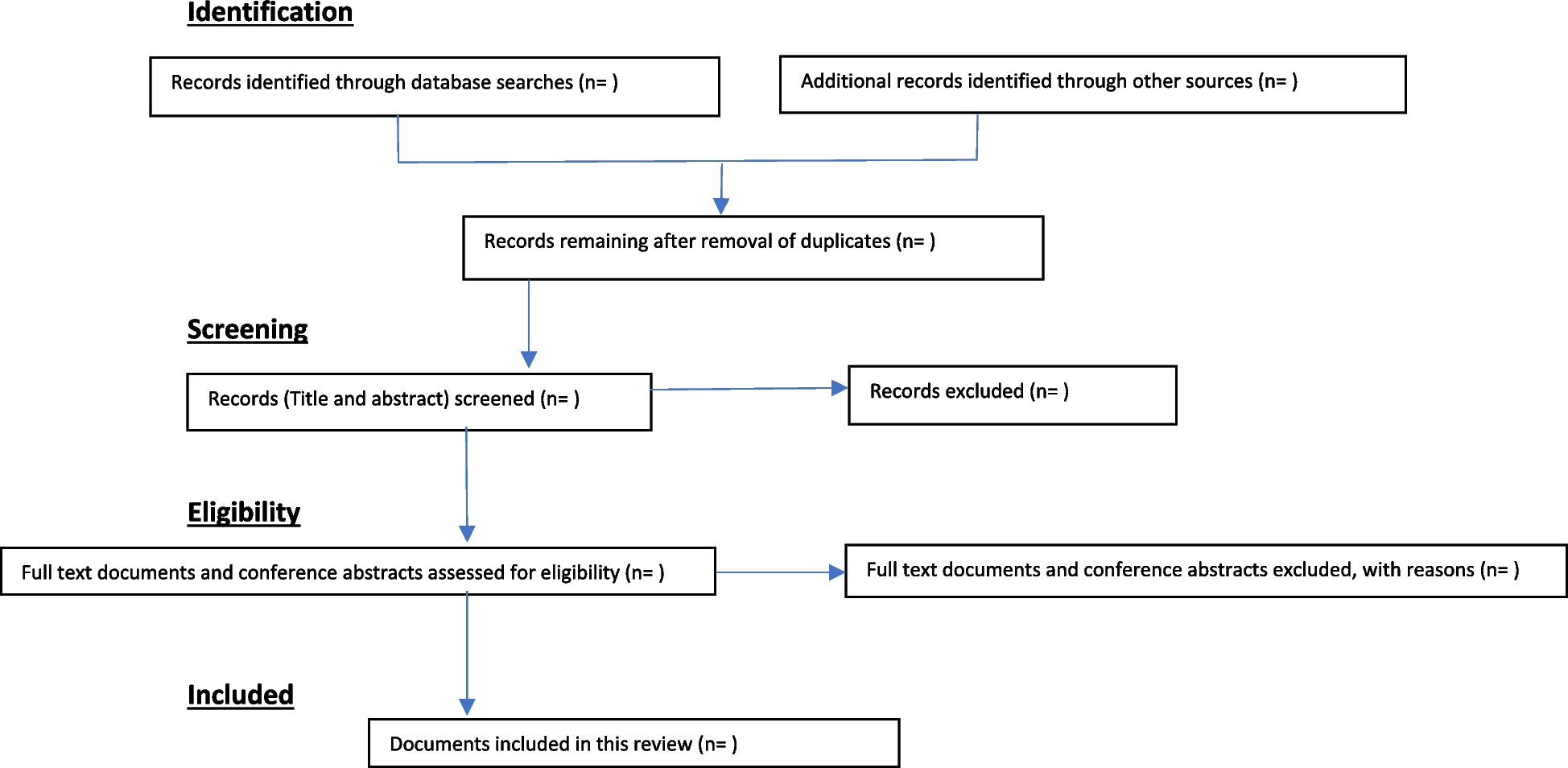
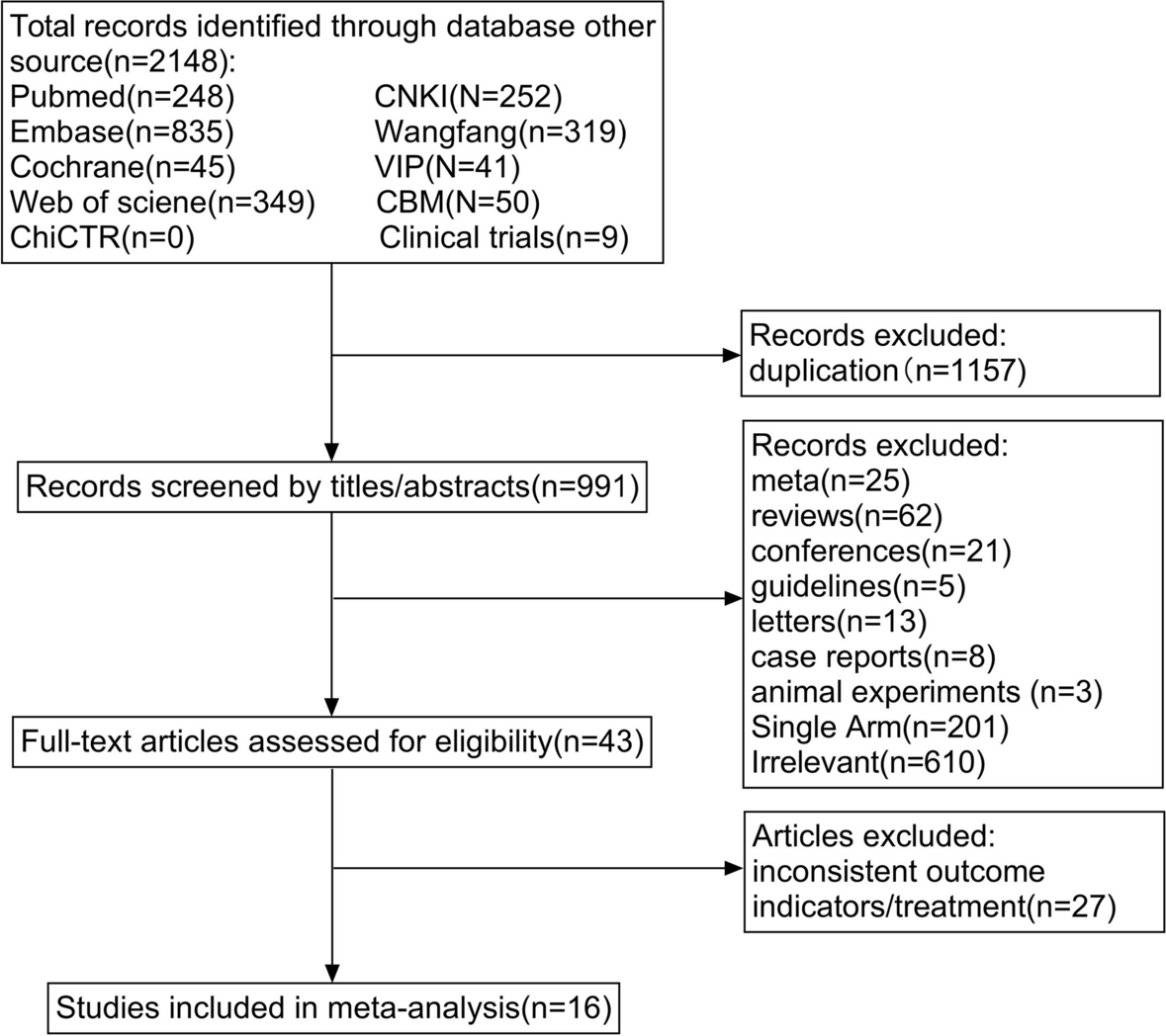
The results of the search strategy and selection process will be presented using a PRISMA flow diagram. The data on study details, facilitation and facilitator(s), and method(s) used for evaluation of training (and/or support) (see Table 3) will be presented in tables to provide contextual background for the findings on training and support of facilitators(s).
The categories created in the qualitative content analysis with frequencies will be presented in tables or figures. The tables and figures will be accompanied by text that provides details and rich descriptions of the content of the categories. We will also provide a narrative summary describing how the results relate to the review aim.






留言 (0)