
記住我



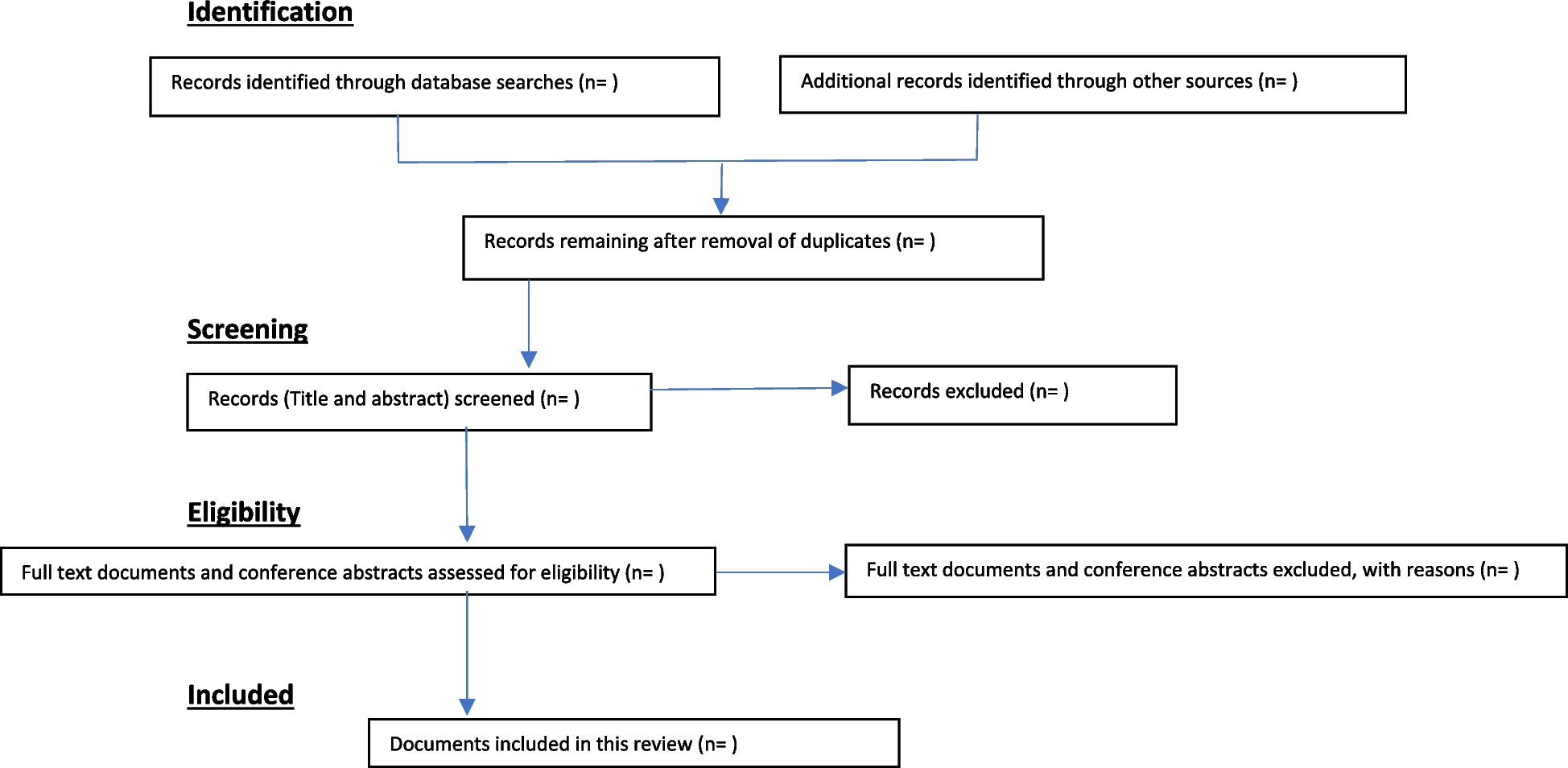


PubMed, Embase, PsycINFO, and CINAHL were searched using controlled vocabulary thesaurus (MesH in PubMed and Emtree in Embase) and free-text keywords. The search queries included “natural language processing” and “text mining.” Additional file 1 provides the full search queries. Also excluded were editorials, case reports, commentary, erratum, replies, and studies without abstracts. Before 2000, there were few NLP studies. Therefore, we included all abstracts published between January 2000 and December 2020. Multiple steps are involved in the study. First, we classified NLP abstracts based on their text source (e.g., social media versus clinical notes). After optimizing retrievable meaningful classes of abstracts, a finalized training dataset was created. Next, we calculated the classification accuracy of the computer algorithm using the entire corpus. As a final step, we applied the algorithm to obtain the classes and visualized them. The last author (S. S.) randomly selected 100 abstracts from PubMed and classified their text sources, the context of use (e.g., abstracts pertaining to clinical decision support vs. those related to NLP method development), and the type of medical conditions studied. Using these primary classes, the lead author (S. M.) and third author (N. S.) explored more classes and categories for each of these classes in further PubMed abstracts. By adding more abstracts, they continued to find more classes and subgroups until they were unable to find any more classes and subgroups. The saturation process was completed after reviewing 485 abstracts. All authors discussed and optimized the classification iteratively until they reached an agreement on the final classification. In Table 1, the finalized classes and their definitions are described.
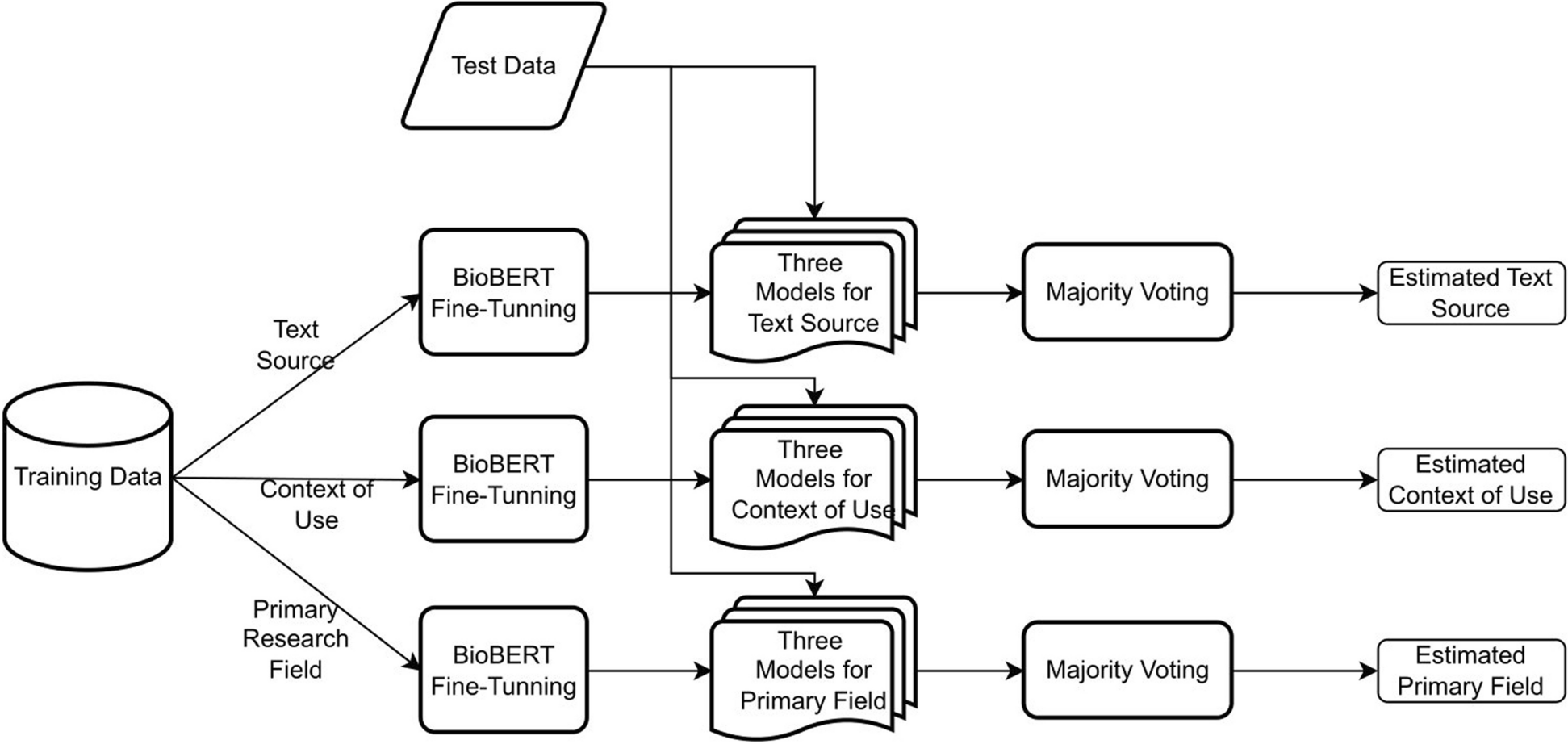
Table 1 Definitions used in classifying the NLP abstractsAnalysisAs depicted in Fig. 1, machine learning algorithms were used to classify abstracts in the final corpus into those obtained from the trained dataset. By fine-tuning the pre-trained language models ubiquitous in modern NLP, we followed the favored approach. BERT, or Bidirectional Encoder Representations from Transformers, is a language model developed by Google [8]. The models are pre-trained on large corpora and then fine-tuned using task-specific training data by reusing the parameters from the pre-trained models. We used the BioBERT model [9] from the Hugging Face Transformers library [16], which was trained on abstracts from PubMed and full articles from PubMed Central. Then we fine-tuned three different models, one for each of our targets: text source, context of use, and primary research fields. The hyper-parameters, such as the learning rate and number of epochs, were selected using cross-validation. The final model was trained on the entire training data using the optimized hyperparameters. Since we utilized a pre-trained BioBERT model, a standard GPU, such as the Nvidia Tesla K80, was sufficient for fine-tuning the model during both the training and inference phases. All the experiments were conducted in a Google Colab environment leveraging this GPU.
Fig. 1
Overview of the proposed machine learning approach
For each target variable, we fine-tuned three different classifiers as an alternative method of improving the models’ accuracy. Repeating the fine-tuning process resulted in a different classifier due to different data batches used during training. The final prediction for an input article was obtained by majority voting of the base classifiers’ predictions. Afterwards, the trained models were applied to the entire corpus. A set of 362 randomly selected abstracts was manually annotated by the lead (S. M.), third (N. S.), and last author (S. S.) to evaluate the labels provided by the trained models. Next, the human annotations were compared to those provided by the models. The evaluation showed that the trained models’ accuracy in classifying abstracts into the text source, the context of use, and the primary research field was sufficient, mainly to track the time trends of the classes. Therefore, we assumed that misclassifications would remain constant over time. Our next step was to fit models that indicated publication growth rates for different study subgroups using ordinary least-squares regression. Citations were the dependent variable, and publication year was the predictor. Per year, the coefficient of the predictor showed an average increase in citations. A squared term for the publication year was added to the primary model to determine if the growth was linear or exponential. The increase in R2 indicated logarithmic growth. The average annual growth rate (AAGR) was calculated by averaging all annual growth rates (AGR) over the study period (sum of AGRs/number of periods). We calculated AGR as the difference between the current year’s value and the past year’s value divided by the past year’s value.
We report a micro f1-score to evaluate the trained models. The f1-score is calculated as the harmonic mean of precision and recall for the positive class in a binary classification problem.
True positive (TP) and true negative (TN) are the numbers of samples correctly assigned to the positive and negative classes, respectively. On the other hand, false positive (FP) and false negative (FN) are the numbers of samples that are wrongly assigned to the positive and negative classes, respectively. Accuracy is the ratio of the samples correctly assigned to their respective classes.
Precision (P) and recall (R) are calculated as follows if TP, FP, and FN represent the number of true-positive, false-positive, and false-negative instances, respectively:
And f1-score will be as follows.
The average of the f1-scores obtained for different classes is computed for multiclass problems, such as ours. We report the weighted average considering the number of instances in each class in order to account for label imbalance.
留言 (0)