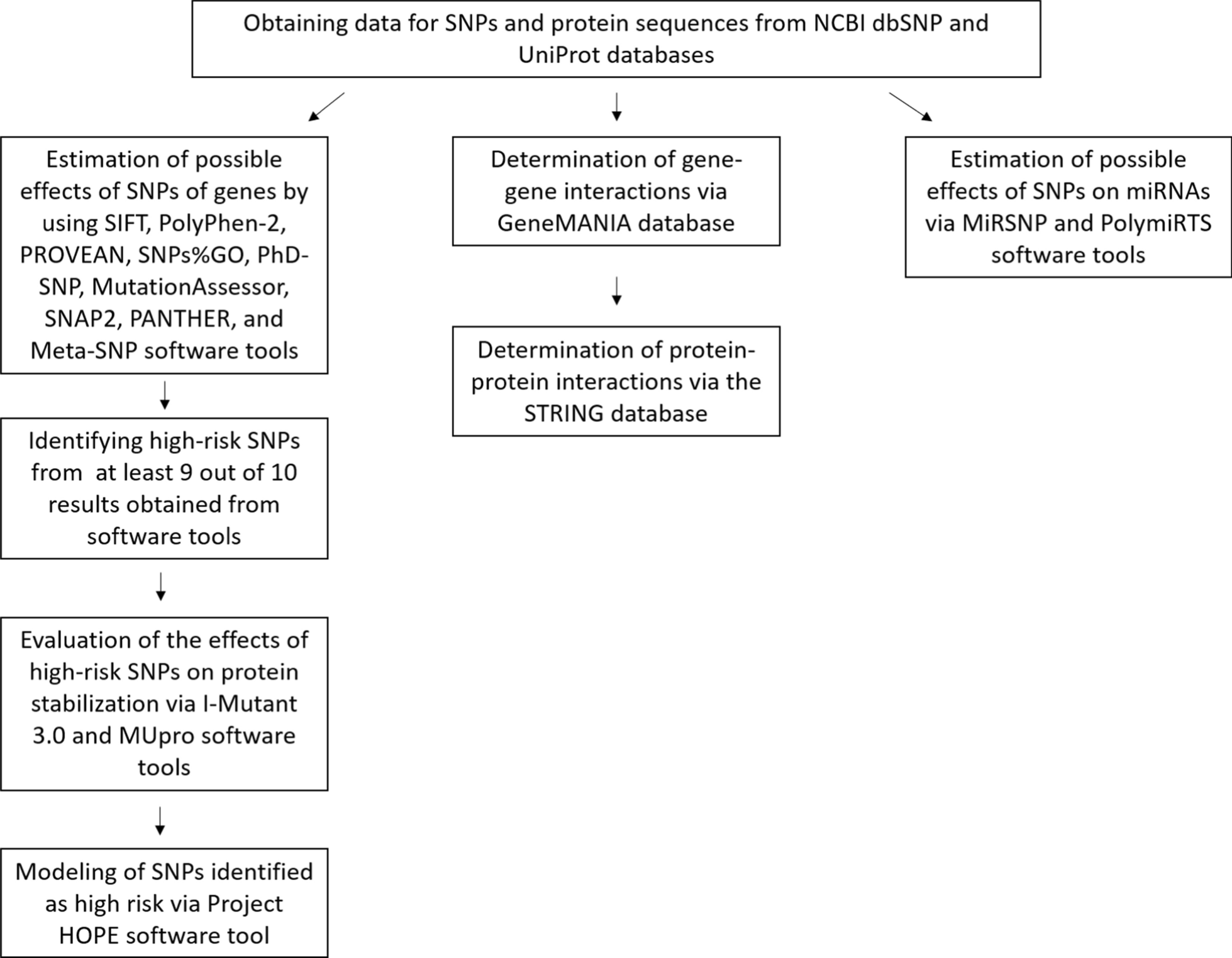
In the study, the probable impacts of SNPs in the KCTD13, CSDE1, and SLC6A1 genes associated with ASD were determined using publicly accessible tools, and the possible effects of SNPs on miRNAs were investigated. As a result, rs60476091 (V242G), rs149152730 (E116V), rs202044176 (R91C), rs372728677 (R306C), rs374722372 (L137P), rs377576 (T55M) and rs774531778 (E120K) in the KCDT13 gene, rs369551811 (F634S), rs776468790 (L49P), rs1195549290 (C42Y) in the CSDE1 gene, rs1403165900 (V323F), rs1574891085 (D52Y), rs747554856 (G442R), rs1189070900 (Y452C), rs1574892295 (L97R) and rs1574908722 (S359P) in the SLC6A1 gene were predicted to be harmful.
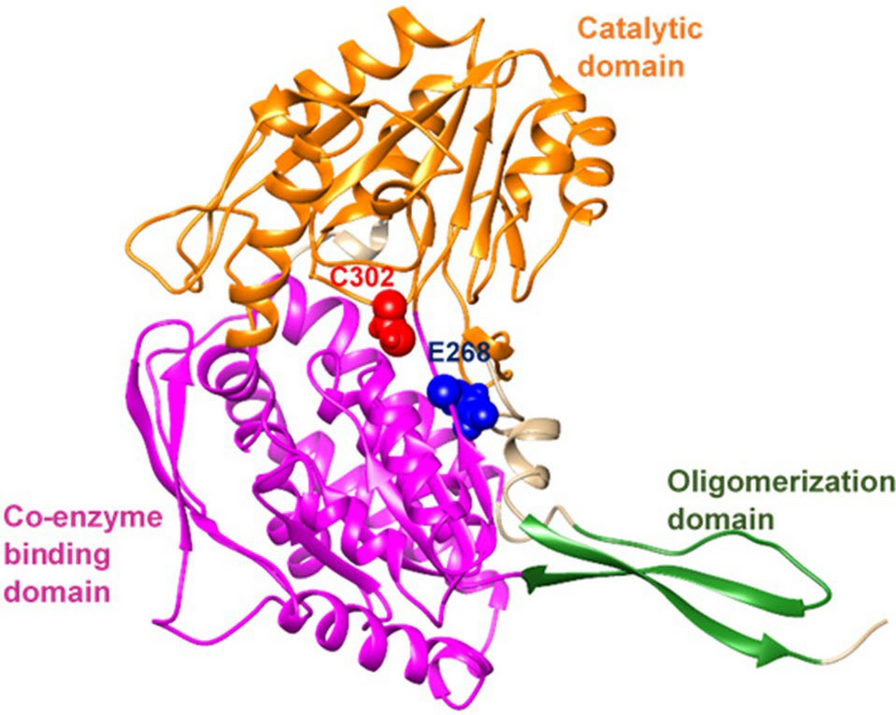
Mutations can affect protein function o via various mechanisms, including alterations in transcription, protein expression, polypeptide chain folding, and stability of the folded protein [59]. The fact that the mutant residue exhibits different properties from the wild-type residue may cause various effects (Table 5). Amino acid size has a key role in determining the compatibility of one part of the structure with other parts. Dimension and shape features can often be correlated to larger protein domains composed of many residues. The charge of a molecule depends on pH. In a study conducted in 2006, it was confirmed that charge properties have a significant role in determining the common positions of residues in protein structures [60]. Hydrophobic side chains of amino acids can interact with each other. Due to the side-chain interactions that occur with the hydrophobicity change, the amino acid order and position in the protein directs the place where the bending and twisting will occur on the protein [61]. Due to the amino acid changes, the protein folding rate can be accelerated or slowed down. This essentially depends on the location and type of mutation. The folding speed is primarily affected by hydrophobicity, and the predominance of the hydrophobic effect is emphasized during the folding process [62]. It is stated that the most common mechanism by which non-synonymous single base change causes the disease is that the protein structure becomes more unstable than the unfolded state. In a 2005 study, it was concluded that considerably majority of the monogenic disease mutations impact the destabilization of the folded protein [59].
Protein stability is required for protein function and structure–activity. The stability of a protein determines the function of the protein by governing its structure. Changes in instability can cause degradation, abnormalities, or misfolding of proteins [63]. Testing with multiple stability models sampling the randomly selected mutation shows that about half are consistent with a disease outcome. Therefore, it is thought that mutations affecting stability are related to diseases [59]. In this study, the effects of SNPs, which were estimated as harmful to protein stabilization, were analyzed in silico (Table 3).
A missense mutation in the CLIC2 gene, which is absent in healthy individuals, has been identified in X-linked intellectual disability. In an in vivo study on a family of 3 siblings, it is thought that the H101Q amino acid change may be a disease-causing mutation. A feature of this mutation detected by in silico analysis is that, unlike all other harmless mutations, it increases CLIC2 protein stability [64]. According to the stabilization results obtained from our study, it was predicted that all variants except 2 variants decreased protein stabilization. The E116V variant of the KCTD13 gene and the S359P variant of the SLC6A1 gene were estimated to increase protein stabilization according to the I-Mutant 2.0 prediction result (Table 3).
Gene–gene interactions are related to many diseases such as diabetes and hypertension and the detection of these interactions continues [65]. According to data from the GENEMANIA software tool, the genes with the maximum association of the KCTD13 gene are POLD2 (DNA Polymerase Delta 2, Accessory Subunit), HSPB8 (Heat Shock Protein Family B (Small) Member 8), SRPX (Sushi Repeat Containing Protein X-Linked), LAMB4 (Laminin Subunit Beta 4), and TNFAIP1 (TNF Alpha Induced Protein 1). The genes most associated with the CSDE1 gene are PLEKHA3 (Pleckstrin Homology Domain Containing A3), ABHD16A (Abhydrolase Domain Containing 16A, Phospholipase), MYB (MYB Proto-Oncogene, Transcription Factor), NUP188 (Nucleoporin 188), and PAIP1 (Poly(A) Binding Protein Interacting Protein 1). The genes most associated with the SLC6A1 gene are STX1A (Syntaxin 1A), SLC6A11 (Solute Carrier Family 6 Member 11), ABAT (4-Aminobutyrate Aminotransferase), PPP4R4 (Protein Phosphatase 4 Regulatory Subunit 4), and VDR (Vitamin D Receptor) [57].
Most proteins perform their functions by interacting with each other. Therefore, the detection of inter-protein interactions provides considerable information to determine the linked protein functions [66]. According to data from the STRING database, top 10 proteins associated with the KCTD13 protein are TNF (tumor necrosis factor), CUL3 (Cullin 3), ASPHD1 (aspartate beta-hydroxylase domain containing 1), KCTD10 (potassium channel tetramerization domain-containing 10), USP25 (ubiquitin-specific peptidase 25), FAM57B (family with sequence similarity 57 member B), POLD2 (DNA polymerase delta 2, accessory subunit), TNFAIP1 (TNF alpha-induced protein 1), TRIM25 (tripartite motif containing 25) and FLNC (Filamin C)). Similarly, top 10 proteins associated with the CSDE1 protein are EIF3I (eukaryotic translation initiation factor 3 subunit I), PABPC1 (Poly(A) Binding Protein Cytoplasmic 1), STRAP (serine/threonine kinase receptor-associated protein), PAIP1 (Poly(A) binding protein interacting protein 1), SYNCRIP (synaptotagmin-binding cytoplasmic RNA interacting protein), YBX1 (Y-Box binding protein 1), HNRNPU (heterogeneous nuclear ribonucleoprotein U), DHX9 (DExH-Box Helicase 9), IGF2BP1 (insulin-like growth factor 2 MRNA binding protein 1) and MSL2 (MSL complex subunit 2). Finally, STX1A (Syntaxin 1A), GAD1 (glutamate decarboxylase 1), GATS (putative protein GAT), SLC32A1 (solute carrier family 32 member 1), GABRD (gamma-aminobutyric acid Type A receptor subunit delta), PVALB (parvalbumin), GABRR3 (gamma-aminobutyric acid type A receptor subunit Rho3), GABRA5 (gamma-aminobutyric acid Type A receptor subunit Alpha5) and SLC1A2 (solute carrier family 1 member 2) are found to be most associated proteins with SLC6A1 protein [55].
The effects of gene SNPs on miRNA target binding sites were analyzed in this study (Supplementary Data Table 1 and Table 6). MiRNAs affect many cellular processes from gene expression to proliferation, from cell differentiation to apoptosis. Neuronal miRNAs have effects on protein synthesis across various regions of the brain. Therefore, miRNAs play a crucial role in neurogenesis, synaptogenesis, and neuronal migration. In these ways, miRNAs have an active role in the development and function of the central nervous system, and the dysregulation of their expression is defined in many neurodegenerative and neurodevelopmental disorders [67]. Post-transcriptional mechanisms such as miRNA, which play a role in fine-tuning the genes underlying brain development, synapse formation, synaptic plasticity, and memory formation, represent a way to alter entire gene networks by greatly influencing gene expression without changing the DNA code. Therefore, researchers turned to this mechanism to understand the dysregulation of neurodevelopmental pathways seen in ASD [67, 68]. Hicks et al. conducted a pilot study by purifying the salivary miRNAs of 24 autistic and 21 age- and sex-matched controls. In this study, the expression of 14 miRNAs expressed in the brain is presented. These miRNAs affect brain development-related mRNAs, and the results support the neurodevelopmental measures of adaptive behavior. One of these miRNAs is hsa-miR-218-5p [69]. The same miRNA is found in the miRSNP results of the CSDE1 gene examined in our study. According to the miRSNP result, rs183844328 within the CSDE1 gene was predicted to cause the formation of the hsa-miR-218-5p binding site (Supplementary Data Table 1). Mundalil Vasu et al. investigated the serum miRNAs of 55 children with autism and 55 age- and sex-matched controls, high values for sensitivity, specificity, and AUC were observed for 5 miRNAs. As a result of the study, these could be potential miRNA-based circulatory candidates for autism [70]. One of them was hsa-miR-320a, which was also detected via PolymiRTS in the CSDE1 gene in our study. According to the CLASH data result of PolymiRTS, rs144954789 polymorphism targets the binding site of miR-320a (Table 6). As a result, recent studies show that miRNAs can be used as novel biomarkers by regulating different genes involved in various pathways to reveal the process and causes of ASD [71]. Consequently, miRNAs function as epigenetic modulators that regulate the expression of numerous genes post-transcriptionally by inhibiting protein production or promoting the breakdown of mRNA [68, 72]. Mutations in miRNA genes are linked to ASD. For this reason, miRNAs hold potential as biomarkers and therapeutic targets for ASD [68]. Genetic variations, like SNPs and CNVs in miRNA genes, can disrupt their regulatory roles in brain development by affecting miRNA processing, expression, and interactions with target mRNAs, potentially contributing to ASD symptoms [73, 74].
Although dbSNP contains data from different geographical regions, some SNPs may be population-specific, and not all global populations may be represented. Additionally, dbSNP is updated by adding new data. While the Allele Frequency Aggregator (ALFA) dataset indicates that genetic variations are evenly contributed by all ancestries, the overrepresentation of European individuals (over 80% of the total sample) could distort the results and lead to a lack of representation from non-European groups [75]. Computational methods can filter SNPs to prioritize those with high potential effects, which can make experimental validation more efficient and cost-effective. However, experimental validation is necessary to determine the accuracy of in silico estimations [76]. Experimental studies can be conducted, such as investigating the contribution of SNPs to miRNA genes [77] and examining miRNA expression profiles in a study group consisting of individuals with ASD and healthy controls [78]. In addition, SNPs predicted as high-risk in silico studies can be genotyped, and the results can be compared with in vitro validation [79].






留言 (0)