Data source
The mRNA expression profiles and clinical data for EC were obtained from the TCGA database (https://portal.gdc.cancer.gov/). This dataset included RNA-Seq expression matrices for 554 EC samples and 35 normal samples, and corresponding clinical information for 544 EC samples. The survival data for these 544 EC samples was also downloaded as of April 27, 2023. Additionally, 202 GMRGs were curated from 18 gene sets, such as KEGG GLYCOLYSIS GLUCONEOGENESIS, WP GLYCOLYSIS, AND GLUCONEOGENESIS, as well as other gene sets of the MSigDB database. For single-cell analysis, the GSE173682 dataset, consisting of five disease subtypes of EC, was retrieved from the GEO database (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi).
Differential analysis
Using the TCGA-EC dataset and setting a threshold of adjusted p-value < 0.05 and |log2FC| > 1.5, differentially expressed genes (DEGs) between tumor and normal groups were identified via the ‘DESeq2’ package (version 1.36.0) [17]. Glucose metabolism-related DEGs (GMR-DEGs) were determined based on the intersection of DEGs with GMRGs.
PPI network and functional enrichment analysis
The STRING database was employed to explore the interactions among GMR-DEGs, which captures both direct physical protein interactions and indirect regulatory relationships such as co-expression and genetic interactions. These complex interactions were systematically analyzed using PPI network. Functional enrichment of Gene Ontology (GO), Kyoto Encyclopedia of Genes and Genomes (KEGG), Disease Ontology (DO), and Reactome pathways was performed using the ‘clusterProfiler’ package (version 4.6.0), with a significance threshold set at adjusted p-value < 0.05.
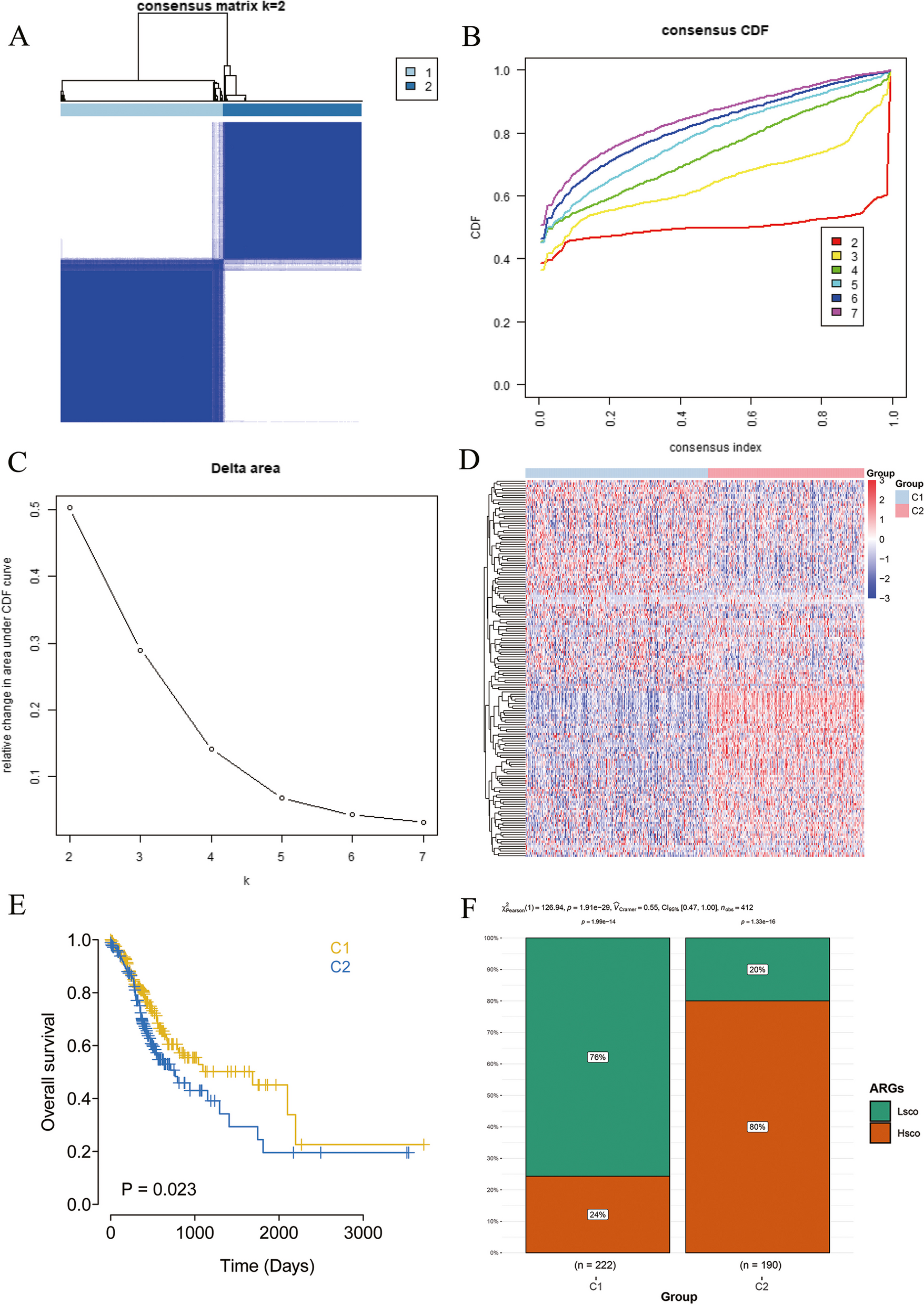
Analysis and validation of EC subgroups based on risk scores
The 544 samples from the TCGA dataset were split into training (328 cases) and testing (216 cases) cohorts in a 6:4 ratio. Univariate Cox regression and least absolute shrinkage and selection operator (LASSO) regression analyses were performed on the training cohort to identify prognostic genes based on candidate genes. To explore the precise function of prognostic genes in disease prediction, the “rms” package [18] (version 6.5-0) was employed in the training set to develop a prognostic genes-based nomogram model for forecasting disease occurrence. This nomogram comprised of “points” and a “total score”, where the former represented the scores attributed to individual prognostic genes, and the latter summed up the scores across all genes. Subsequently, we employed the “rms” package (version 6.5-0) to plot calibration curves and leveraged the pROC package [19] (version 1.18.0) to generate ROC curves, both of which were used to assess the accuracy of the model. The risk model was constructed using the following formula:\(\:\text\text\text\text\:\text\text\text\text\text=_=1}^}\text\text\text\text\left(\text\text\text}_}\right)\times\:\text\text\text\text\left(\text\text\text}_}\right)\). In this formula, coef represents the risk coefficients, denotes the expression levels of each prognostic gene, i corresponds to the number of genes, and gene represents the respective prognostic gene. The survival analysis was confined to 10 years, excluding samples with survival exceeding this threshold. EC patients with available survival data were stratified into two risk subgroups, each defined by the median risk score. To assess the prognostic reliability of the model, Kaplan-Meier (K-M) survival analysis was performed at 1-, 3-, and 5-year intervals using the R package “Survival” (version 3.5-5) [20, 21]. Additionally, receiver operating characteristic (ROC) curve analysis was conducted utilizing the R package pROC (version 1.18.0) to evaluate the model’s predictive capability further [22]. This identical approach was consistently applied to the training and validation sets for survival analysis and ROC assessments.
To explore the relationship between risk score and clinical variables such as age, overall survival (OS), stage, radiation therapy, pharmaceutical therapy, prior malignancy, and prior treatment, a heatmap was used to display the clinicopathological features across the two risk subgroups.
Both univariate and multivariate Cox proportional hazards regression analyses were conducted, incorporating age, OS, stage, radiation therapy, pharmaceutical therapy, prior malignancy, and prior treatment to identify independent prognostic factors. Based on these independent prognostic factors, a nomogram was constructed to predict the survival probabilities of patients with EC at 1, 3, and 5 years, with a calibration curve used to evaluate the model’s predictive accuracy.
Furthermore, the correlation analysis between the prognostic genes and risk scores was conducted using the psych package (version 2.2.5) [23]. The expression levels of the prognostic genes across clinical indicators were analyzed, and the visualizations were created using ggpubr package (version 0.6.0) (https://CRAN.R-project.org/package=ggpubr).
Gene Set Enrichment Analysis (GSEA)
The ‘clusterProfiler’ package [24] was utilized for GSEA to explore potential pathways in different risk subgroups. The reference gene sets were GO and KEGG, with an adjusted p-value threshold of < 0.05 set as the cutoff value.
Single-cell analysis
Before analyzing gene expression data from the GSE173682, single-cell transcriptomic dataset, which includes five EC groups, a comprehensive quality control (QC) procedure was performed using the Seurat R package (version 4.4.0). Filtering criteria included samples with at least 3 cells and 200 features (min. cells = 3 and min. features = 200). Doublets were detected using scDblFinder (version 1.16.0), and only cells with less than 10% mitochondrial content were retained. Highly variable genes were identified via the FindVariableFeatures function. Principal component analysis (PCA) was then conducted on the integrated samples using IntegrateData, and a PCA elbow plot was plotted to determine the optimal number of components capturing significant variation. Unsupervised clustering was performed using the FindNeighbors and FindClusters functions, and the clustering results were further visualized with t-Distributed Stochastic Neighbor Embedding (tSNE), offering a clearer view of cellular structure and relationships. Cell types were annotated based on known marker genes. In the GSE173682 dataset, the expression of prognostic genes was analyzed across different cell populations using ggplot2 (version 3.4.4). Cells exhibiting high expression of these prognostic genes were identified as key populations for further study.
Cellular communication and pseudo-time series analysis
A cell communication analysis was performed to quantify receptor-ligand expression and pairing between cell populations, providing insights into intercellular interactions. Using GSE173682 and annotated cell clusters, patient-specific cellular communication patterns were assessed with the CellChat package (version 1.6.1). To investigate key cell changes in cell states, a pseudo-time analysis was conducted using Monocle 2 (version 2.30.0), constructing a single-cell trajectory map that projected cells along a root-branch structure. The BEAM method in Monocle temporally ordered cells, reveals developmental trajectories and visualizes the expression patterns of prognostic genes over time.
Immune feature estimation and chemotherapy analysis
To explore the immune microenvironment in EC, the ‘estimate’ package was used to compute and compare Immune, Stromal, and ESTIMATE scores between the two risk subgroups. The ssGSEA algorithm was applied to determine the relative abundance of 29 immune-related gene sets in each subgroup [25]. Expression differences in chemokines, interferons, interleukins, other cytokines, and their receptors between the two risk groups were analyzed using the ‘ComplexHeatmap’ package (version 2.16.0) [26]. Additionally, immune status was assessed by comparing the expression of 36 immune checkpoints and 21 HLA family genes in the two groups.
EC tissues
Between April 2023 and May 2024, 24 pairs of EC tissues and adjacent non-cancerous tissues were collected from patients undergoing surgery at the Department of Obstetrics and Gynecology of Jingjiang People’s Hospital for analysis. None of the patients had received radiotherapy or chemotherapy before surgery, and informed consent was obtained from all participants. The EC tissue samples were divided into two portions: one portion was immediately frozen and stored at -80 °C for later mRNA extraction, while the other was for IHC. The study was conducted by the Declaration of Helsinki and received approval from the Ethics Committee of Jingjiang People’s Hospital (Approval No. 2023-KY-019-01).
Reverse transcription quantitative PCR (RT-qPCR)
Total RNA was extracted from the tissue samples using a tissue/cell extraction kit (TIANGEN, Beijing, China). Reverse transcription was performed with the Reverse Transcription Kit (TaKaRa, Japan), and PCR amplification was conducted using the PrimeScript RT reagent Kit with gDNA Eraser (TaKaRa, Japan). Primers were synthesized by Sangon Biotech (Shanghai, China), and their sequences are provided in Supplementary Table 1. β-actin was used as the internal reference gene for calculating relative RNA expression. Each sample was tested in four identical replicate wells, and the experiments were conducted in triplicate to ensure minimal variance.
Immunohistochemistry (IHC)
For IHC, sections of EC and normal endometrial tissues were incubated overnight at 4 °C with antibodies against SLC38A3, GAD1, ALDH1B1, and GLYATL1 (1:100 dilution; Cat Nos.14315-1-AP, 10408-1-AP, 15560-1-AP, 15717-1-AP; Proteintech, China). Following primary antibody incubation, a secondary antibody was applied at a dilution of 1:200 (G1213, Servicebio, China), and visualization was achieved through DAB staining with hematoxylin used for counterstaining. The evaluation of the staining results was carried out through a double-blind assessment by two senior pathologists. A two-tier scoring system was employed:
Percentage of positive cells (per 100 cells): 0 points for no positive cells, 1 point for < 10%, 2 points for 10–50%, 3 points for 50–75%, and 4 points for > 75%.
Staining intensity: 0 points for no staining, 1 point for yellow, 2 points for brown-yellow, and 3 points for dark brown.
The final composite score was calculated by combining these two scores.
Cell lines and cell culture
The Ishikawa, AN3CA, and HEC-1 A cell lines were generously provided by the Department of Obstetrics and Gynecology at the First Affiliated Hospital of Soochow University. KLE and EEC (normal human endometrial epithelial cells) cell lines were obtained from Keycell Biotechnology Co. Ltd (Wuhan, China). For optimal cell growth and maintenance, all cell lines were cultured in a complete medium containing 10% fetal bovine serum (FBS, Gibco, USA) and 1% streptomycin-penicillin (Beyotime, Beijing, China). The Ishikawa and KLE cell lines were maintained in Dulbecco’s Modified Eagle Medium (DMEM, Wuhan Pricella Biotechnology Co. Ltd), HEC-1 A was cultured in McCoy’s 5 A medium (Wuhan Pricella Biotechnology Co. Ltd), and both AN3CA and EEC were cultured in Minimum Essential Medium (MEM, Wuhan Pricella Biotechnology Co. Ltd). All cell cultures were incubated at 37 °C with 5% CO2.
Western blot analysis
Protein extraction was performed by lysing the cells on ice using RIPA lysis buffer supplemented with protease inhibitors. Protein concentrations were determined using the BCA Protein Assay Kit (Beyotime, Beijing, China). The proteins were then subjected to polyacrylamide gel electrophoresis and transferred to polyvinylidene fluoride (PVDF) membranes. Following a 2-hour blocking step at room temperature, the membranes were incubated overnight at 4 °C with an anti-SLC38A3 antibody using an anti-β-Actin antibody as the internal control. Finally, the chemiluminescent signal was amplified utilizing the ECL kit (New cell & Molecular Biotech Co., Ltd. Suzhou, China), and subsequent image analysis was conducted to quantify protein expression employing the ChemiDoc XRSVectorTM system (Bio-Rad, Hercules, CA).
Cell transfection
In the gene silencing experiments, Ishikawa cells were transfected with small interfering RNA (siRNA) targeting SLC38A3 and a negative control (NC) siRNA, utilizing the siRNA-Mate Plus transfection reagents. Vectors designed for the overexpression of SLC38A3 were constructed using the pCDNA3.1(+) plasmid and subsequently transfected into EEC cells. The empty vector, pcDNA, served as the control in this experiment. The siRNA and the SLC38A3 overexpression plasmid were obtained from Shanghai GenePharma Co., Ltd. The target sequences for SLC38A3 siRNA are provided in Supplementary Table 2.
Cell counting Kit-8 (CCK-8) assay
Ishikawa and EEC cells harvested 24 h post-transfection were seeded into 96-well plates containing 100 µL of cell suspension (approximately 2000 cells). Each experimental group was replicated in three wells. The plates were incubated for 72 h, and at specific time points (0 h, 24 h, 48 h, and 72 h), 10 µL of CCK-8 reagent (Beyotime, Beijing, China) was added to each well. The plates were incubated for another 2 h at 37℃ before measuring at 450 nm using a microplate reader to assess cell viability.
Transwell assay
Ishikawa and EEC cells were digested 24 h after transfection, and 200 µL of an FBS-free cell suspension (3 × 105 cells) was transferred into transwell chambers with 8 μm pores (NEST, Wuxi, China). The lower chamber was filled with 600 µL of complete DMEM medium. Each experimental group was replicated in three replicate wells. After a 24-hour incubation period, migrated cells were fixed with paraformaldehyde and stained with 1% crystal violet (Beyotime, Beijing, China). The number of migrated cells was then counted under a microscope by examining at least five fields per well.
Glucose uptake, lactate production, and ATP measurement
To evaluate cellular glucose uptake, the 2-Deoxy-2- [(7-nitro-2,1,3-benzoxadiazol-4-yl) amino]-D-glucose (2-NBDG) Glucose Uptake Cell-Based Kit (Elabscience, Hubei, China) was utilized. The fluorescent marker 2-NBDG, metabolized into 2-NBDG-6-phosphate upon cellular uptake, served as a probe to measure glucose uptake. Fluorescence intensity, observed through fluorescence microscopy and flow cytometry, indicated the level of glucose uptake. Lactate concentrations in the cell homogenate supernatants were measured using the L-Lactic Acid Colorimetric Assay kit (Elabscience, Hubei, China), following the manufacturer’s instructions. Additionally, ATP generation was determined by the ATP Chemiluminescence Assay Kit (Elabscience, Hubei, China).
Statistical analysis
R software (version 4.2.1) and GraphPad Prism 9 (GraphPad, Dotmatics, MA) were employed for statistical analysis. The Wilcoxon test, one-way ANOVA, or Student’s t-test were used to assess the statistical significance of differences between groups. A p-value less than 0.05 was considered statistically significant.


留言 (0)