
記住我
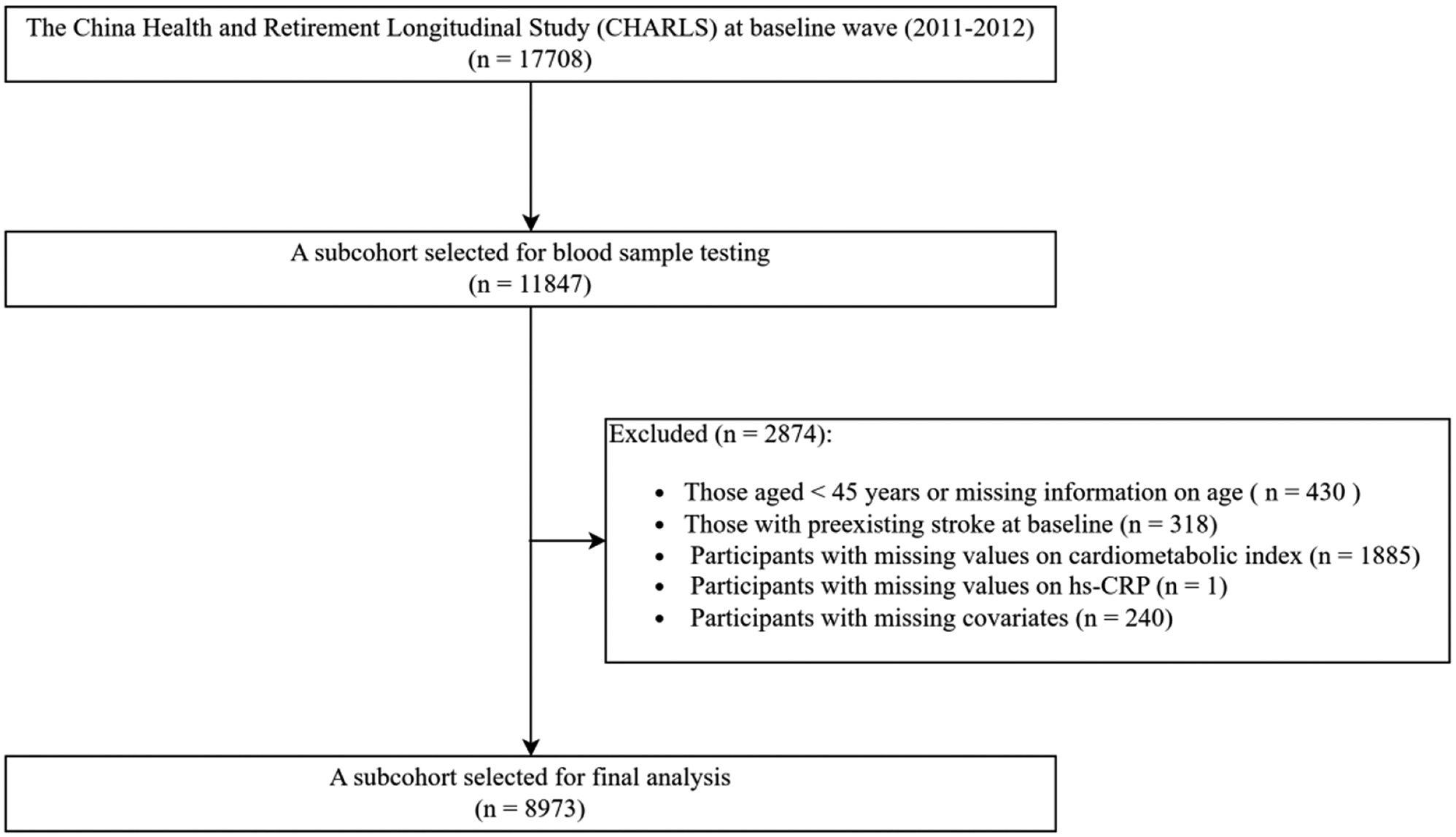
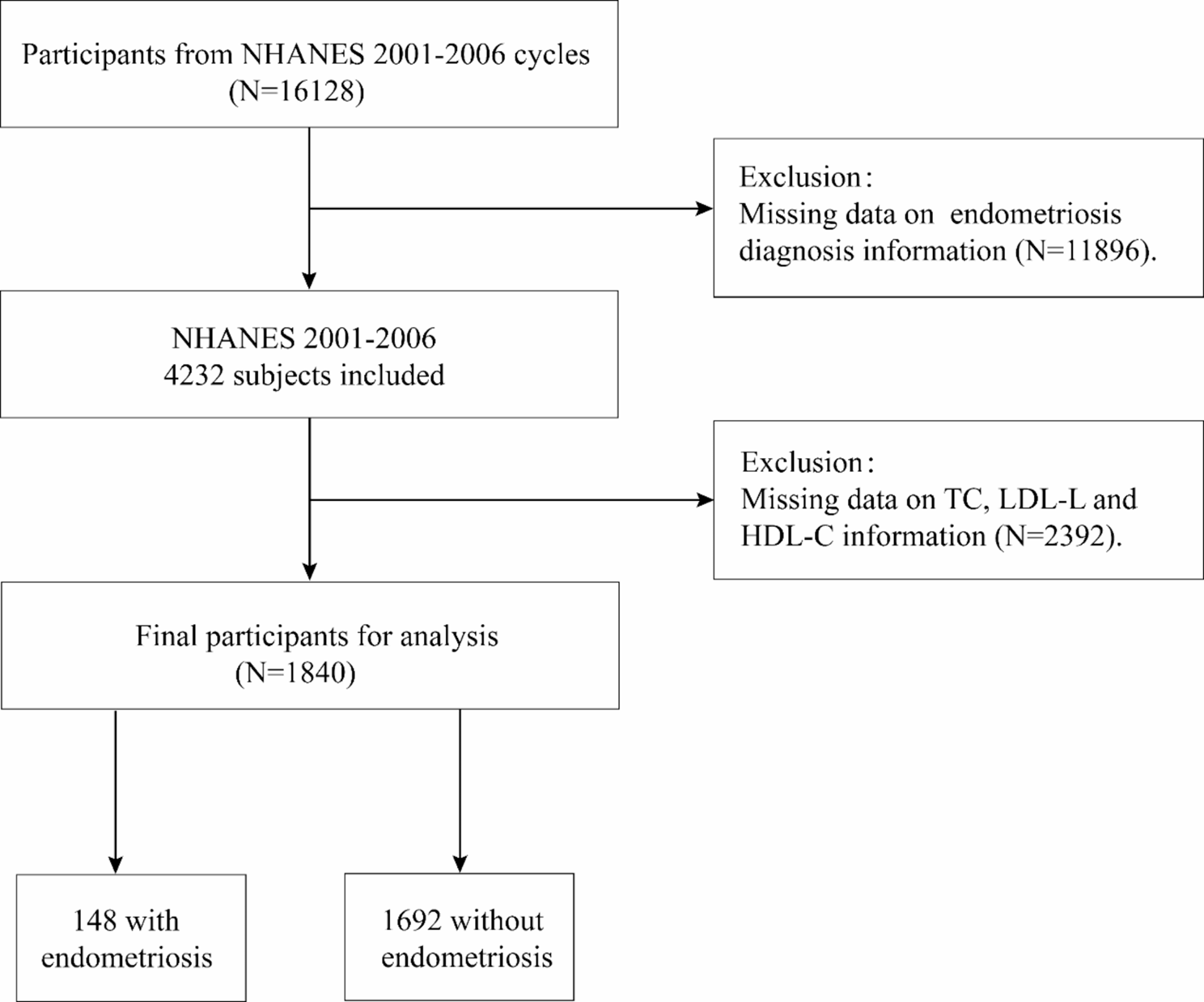
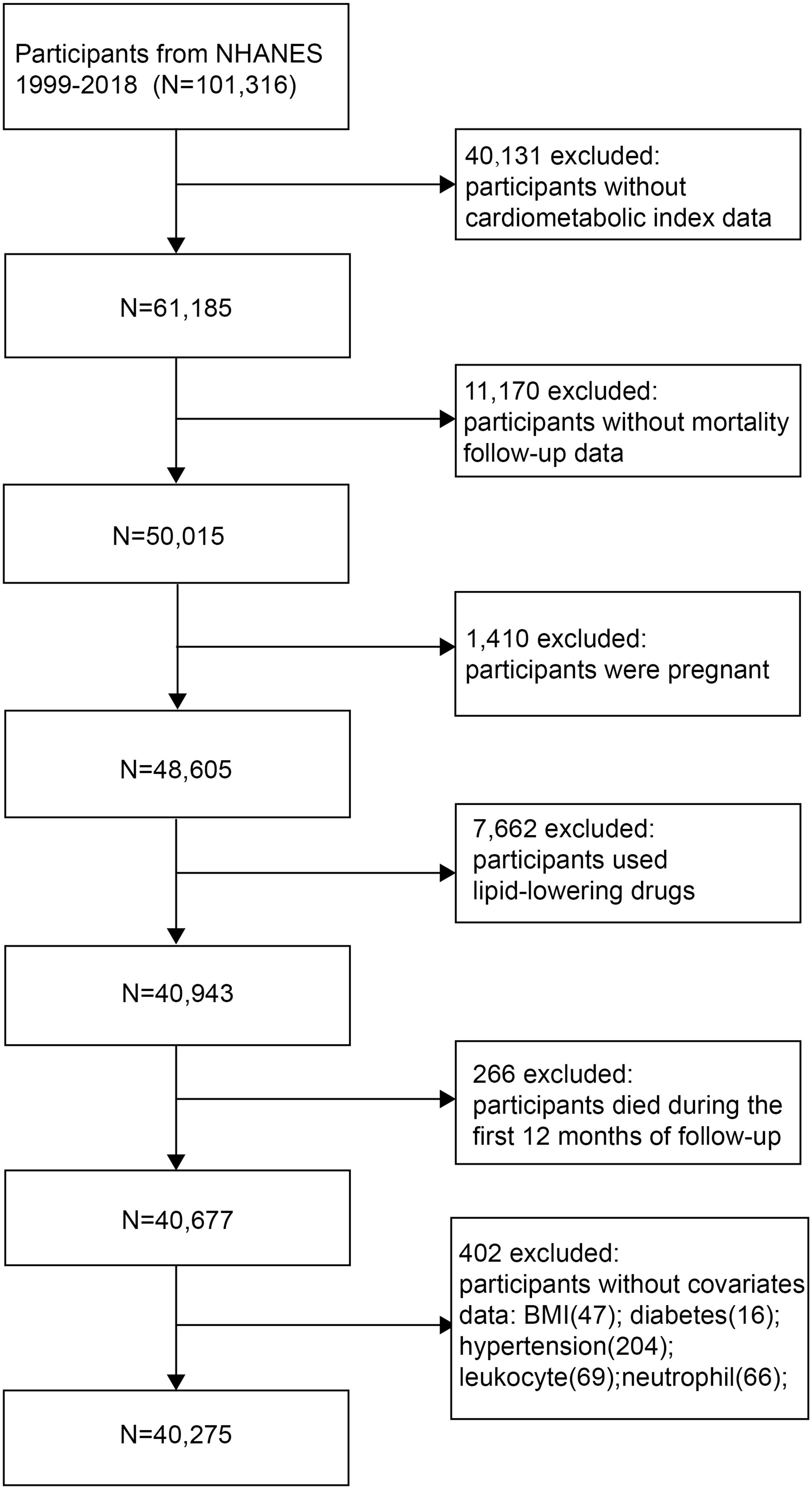
This study was a longitudinal cohort study with a database from the National Health and Nutrition Examination Survey (NHANES), a comprehensive survey designed to collect data on the health status of the U.S. population [11]. The protocols for NHANES were approved by the Research Ethics Review Board of the National Center for Health Statistics (NCHS). The datasets for this study were publicly accessible on the NHANES website (https://www.cdc.gov/nchs/nhanes/index.htm) [12, 13]. Participants aged over 18 years were recruited from nine NHANES cycles between 2001 and 2018. Individuals with incomplete sociodemographic information, missing TG and HDL-C measurements for calculating CMI, and no relevant mortality data were excluded from the analysis. In the end, a total of 5,728 participants were included, consisting of 2,296 females and 3,432 males (as shown in Fig. 1).
Fig. 1
A flowchart for participant selection
Definitions of the exposure and outcome variablesThe exposure variable was the CMI, which was calculated using the formula:
\(\begin&CMI\cr&\quad=\left[\frac&high-density\:lipoprotein\:cholesterol\cr&\:\left(HDL-C,\:mmol/L\right)\end}\right]\cr&\qquad\times\:\left[\frac\right]\end\)[14].
All variables in the equations above were measured following standard protocols established by the U.S. Centers for Disease Control and Prevention (CDC) and were expressed in international standard units [15]. CMI was considered as a continuous exposure variable. Subsequently, to investigate the specific effects of varying levels of CMI, we stratified our study participants into four groups based on CMI quartiles.
The outcomes were all-cause mortality, cancer mortality, CVD mortality, and diabetes mortality. The National Center for Health Statistics (NCHS) determined mortality status by integrating the NHANES Public Use Link Mortality File with the National Death Index (NDI) through December 31, 2019, using a probability matching algorithm (www.cdc.gov/nchs/data-linkage/mortalitypublic.htm).In a further step, to ascertain the cause of death among participants, we employed the Tenth Revision of the International Statistical Classification of Diseases (ICD-10) as a guideline [16]. According to ICD-10, cancer mortality was defined by codes C00-C97, diabetes mortality by codes E10-E14 and does not include cardiovascular complications arising from diabetes, deaths from heart disease by codes I00-I09, I11, I13, and I20-I51, and deaths from cerebrovascular disease by codes I60-I69. Cardiovascular mortality was classified as any death related to heart disease, cerebrovascular disease, and/or hypertension, which includes essential (primary) hypertension, hypertensive heart disease, hypertensive renal disease, hypertensive heart and renal disease, secondary hypertension.
Assessment of covariatesEleven covariates, including age, gender, income-to-poverty ratio (PIR), BMI, race, the disease history of hypertension, hypercholesterolemia, diabetes, and CVD, as well as history of alcohol use and smoking, were enrolled in this study. Data on age, gender, PIR, race, the disease history of hypertension, hypercholesterolemia, diabetes, and CVD, as well as history of alcohol use and smoking, were obtained through a questionnaire, while BMI (kg/m²), waist circumference (cm), and height (cm) were measured during a physical examination. BMI was the ratio of weight (kg) to height (m) squared. According to the World Health Organization’s recommended guidelines [17], a PIR below 1.3 implies poverty, a BMI of less than 25 signifies underweight, a BMI between 25 and 30 denotes overweight, and a BMI over 30 is classified as obesity. Furthermore, a waist circumference of ≥ 80 suggests obesity. The definitions of hypertension, hypercholesterolemia, and diabetes involved a positive response to the following questions:
(1)Have you ever been told by a doctor or other health professional that you had hypertension, also called high blood pressure?
(2)Have you ever been told by a doctor or other health professional that your blood cholesterol level was high?
(3)Have you ever been told by a doctor or health professional that you have diabetes or other health problems?
Statistical analysisAll statistical analyses were performed with R software (version 4.2.2) and SPSS (9.0). A p-value of < 0.05 was deemed statistically significant. Categorical variables were reported as frequencies and percentages, while continuous variables were presented as means with standard deviations. Continuous variables were analyzed using the Wilcoxon rank-sum test, whereas categorical variables were assessed with Pearson’s Chi-squared test.
The Cox frailty model was employed to generate hazard ratios (HRs) for the association between CMI and both all-cause and specific cause mortality, incorporating age at the onset of major cardiovascular disease, diabetes, and cancer as random intercepts to account for age-specific mortality. Each model adjusted for different covariates: Model 1 (unadjusted), Model 2 (adjusted for gender), and Model 3 (adjusted for gender, hypertension, diabetes, hypercholesterolemia, cardiovascular disease, alcohol use, smoke now, race, PIR, BMI). The results from the Cox frailty model were expressed as HRs and 95% confidence intervals (CIs). Kaplan-Meier curves were generated to estimate survival over time, and the log-rank test was employed to evaluate differences in survival curves across varying CMI levels. In addition, when analyzing cause-specific mortality, we also considered competing risks between causes, for which we constructed a Fine-Gray sub-distribution hazard model, plotted Nelson-Aalen cumulative risk curves [18].
Several sensitivity analyses were performed to ensure the robustness of our findings. First, to mitigate the potential influence of reverse causation, we excluded participants with self-reported CVD. Second, we reassessed the association between CMI and both all-cause and specific cause mortality by additionally adjusted for self-reported cancer status.
To explore potential dose-response patterns, restricted cubic spline (RCS) curves were employed. Threshold effects analyses were conducted if the relationship was nonlinear, which meant that we used a two-piece Cox proportional risk model on either side of the point of infection to examine the relationship between CMI and the risk of all-cause and specific mortality.
In order to compare the associations between commonly used status indicators regarding CMI (CMI, age, sex, BMI, and PIR) and all-cause and specific mortality, the average marginal effect was calculated. Briefly, the average marginal effect of a variable represents the mean predicted change in the fitted value associated with a change in the independent variable across all observations where the covariate is present [19, 20]. These average marginal effects are compared across models, with larger average marginal effects indicating stronger correlations. Average marginal effects were derived from independent logistic regression models, each incorporating the five status indicators, and included covariates such as hypertension, diabetes, hypercholesterolemia, cardiovascular disease, alcohol use, smoking status, race, PIR, and BMI.
Finally, stratified analyses were performed based on gender, hypertension, diabetes, hypercholesterolemia, cardiovascular disease, alcohol use, smoking status, race, PIR, and BMI. Interaction effects among these variables were assessed using interaction terms.
留言 (0)