
記住我
The growing need for advanced athletic performance analysis has led to increased interest in leveraging Electroencephalography (EEG) data for real-time monitoring and performance enhancement (Cao and Li, 2021). EEG data not only reflects an athlete's neural state but also enables real-time tracking of focus, fatigue, and strategy adjustments during physical activities (Friesen and Park, 2022). Performance monitoring relies not only on external movement data but also on capturing internal neural dynamics, offering athletes a more comprehensive and personalized training regimen (Zhang and Jiang, 2020). Moreover, EEG data's real-time characteristics provide the potential for immediate feedback during physical activities, helping athletes optimize their techniques while preventing injuries (Rao and Zhang, 2023). Thus, using EEG data to enhance athletic performance is not only academically significant but also holds considerable potential in practical applications such as sports training and rehabilitation (Cote and Whelan, 2021).
To overcome the limitations of traditional athletic performance analysis methods that fail to effectively process EEG signals, early research relied on symbolic AI and knowledge representation. In these approaches, EEG signals were interpreted as symbolic information processed through predefined rules or logical reasoning (Wang and Song, 2021). These methods excelled in specific scenarios by leveraging structured knowledge, offering interpretability for certain athletic states. However, symbolic AI methods are heavily dependent on predefined knowledge bases, making them inadequate for handling the complex, nonlinear fluctuations found in EEG signals (Parihar and Acharya, 2021). Additionally, they struggled with the high-dimensional nature of EEG data, especially in contexts with individual athlete differences and diverse movement patterns (Fuentes and Gomez, 2022). To address the shortcomings of symbolic AI, researchers shifted toward data-driven methods (Lee and Kang, 2020).
As large-scale EEG datasets became available, data-driven and machine learning approaches began to dominate. These methods learn patterns from the data itself, without relying on predefined rules (Zhang and Zhao, 2021). Statistical models and traditional machine learning algorithms, such as Support Vector Machines (SVM), were employed to automatically extract features and classify EEG data (Li and Zhou, 2022). Compared to symbolic AI, data-driven methods significantly improved the handling of nonlinear EEG signals and complex athletic scenarios (Duan and Xiao, 2023). However, these methods relied on manual feature extraction, which did not fully capture all the rich information in EEG data, limiting performance when dealing with high-dimensional, noisy data (Li and Sun, 2021). Furthermore, machine learning methods often struggled with overfitting when data was limited or of lower quality (Sun and Gu, 2023). In response, deep learning became a promising solution to further automate feature extraction and improve accuracy (Gao and Li, 2023).
Deep learning revolutionized EEG signal analysis by providing automated feature extraction and modeling capabilities, particularly with Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) (Roy and Das, 2021). These models could automatically learn multi-layered features from large EEG datasets, greatly improving prediction accuracy (Zhang and Chen, 2023). Additionally, deep learning's end-to-end training capability allowed for direct learning from raw EEG signals to performance prediction, eliminating the need for complex manual feature design (Li and Wu, 2023). However, deep learning came with its own set of challenges, including high computational complexity and a strong dependence on large labeled datasets for training (Xu and Zhang, 2021). With the rise of pre-trained models, researchers began to leverage pre-trained deep learning models and apply transfer learning to EEG data, reducing the reliance on vast amounts of labeled data (Ma and Tang, 2022). While these methods enhanced automation and performance, they still faced challenges when processing multimodal data (such as EEG and video fusion), and computational complexity remained a barrier to real-time applications (Shah and Kumar, 2022).
To address these limitations, we propose the Cerebral Transformer model. This model leverages adaptive attention mechanisms and cross-modal fusion techniques to effectively integrate EEG signals with video data, overcoming the shortcomings of traditional deep learning methods in handling multimodal data. The model also introduces a pre-trained Transformer architecture, significantly reducing training complexity and making it more efficient when processing large-scale, high-dimensional EEG data.
• Cerebral Transformer integrates cross-modal attention mechanisms and efficiently fuses EEG and video data, excelling in multimodal data analysis.
• The method is highly versatile and efficient, suitable for multi-scenario athletic performance monitoring and capable of real-time processing of complex EEG and video data.
• Across multiple datasets, Cerebral Transformer outperforms existing methods in accuracy and recall while significantly reducing inference time, making it ideal for real-time applications.
2 Related work 2.1 EEG signals in sports performanceElectroencephalogram (EEG) signals, as a non-invasive tool for monitoring neural activity, have gained widespread attention in recent years in the field of sports performance analysis. EEG signals can reflect athletes' neural activities, helping to understand changes in focus, fatigue, and emotional states during physical activities. Early research mostly focused on using EEG signals in areas such as emotion analysis, fatigue detection, and neuro-rehabilitation (Wang et al., 2023). In sports performance analysis, researchers have begun to integrate EEG signals with motor control theory to study the relationship between neural activity and movement patterns. For example, some studies have analyzed athletes' EEG signals during competitions to reveal neural network activity patterns in the brain during complex movements (Neuwirth and Emenike, 2024). These studies suggest that EEG signals can be used to monitor athletes' neural states in real-time, providing insights for training adjustments and performance improvement (Zong et al., 2024). However, traditional EEG analysis methods often rely on handcrafted feature extraction, which is limited by high data dimensionality and significant noise interference, leading to poor model generalization. Recently, deep learning applications in EEG signal processing have increased, with methods like convolutional neural networks (CNNs) and recurrent neural networks (RNNs) being used to extract spatiotemporal features from EEG data. However, these models still face challenges in fusing EEG data with other modalities (Pilacinski et al., 2024). Therefore, integrating EEG signals with other sports data to enhance the comprehensive understanding of sports performance has become an important research direction. Cheng C. et al. (2024) employ hierarchical spatiotemporal transformers to capture regional and global brain dynamics for emotion recognition, conceptually consistent with the adaptive attention strategy in our model; Ning et al. (2023) combine spatial, spectral, and temporal attention with meta-learning to enhance EEG emotion recognition, complementing the multi-scale fusion approach in our approach. Jia et al. (2024) introduce knowledge distillation techniques for heterogeneous multi-layer representations of sleep staging, inspiring our representation refinement approach. These studies provide a broader context for our work, highlighting the importance of powerful spatiotemporal attention and multimodal fusion strategies. By situating our model within these advances, we emphasize how our approach builds on and extends current approaches. The Introduction has been revised to reflect these discussions and to establish clearer connections to existing works, thereby enhancing the relevance and positioning of our contribution.
2.2 Video and motion sensor data in sports analysisTraditional sports analysis methods mainly rely on video data or motion sensor data, which have been widely used in sports, human posture recognition, and health monitoring. The advantage of video data is its ability to capture dynamic movements, and deep learning methods like CNNs can extract key features such as posture and movement speed from videos (Minen et al., 2023). For instance, in human posture estimation, researchers can process video with multi-scale convolutional neural networks to efficiently identify key points of an athlete's body, such as elbows and knees, and calculate movement trajectories (Yu et al., 2022). However, video processing often requires significant computational resources, and performance can degrade when dealing with low-quality videos (Neuwirth and Whigham, 2023). Motion sensor data, such as accelerometers and gyroscopes, can provide more precise information on movement trajectories and acceleration, making them important for real-time motion monitoring. Traditional methods often use machine learning models based on statistical features to analyze these data, but these models typically struggle to capture complex spatiotemporal dependencies. With the rise of deep learning, methods like spatiotemporal CNNs (ST-GCNs) and temporal neural networks (e.g., LSTM) have increasingly been applied to motion sensor data, significantly improving recognition accuracy for complex movement patterns (Cheng S. et al., 2024). However, using video or sensor data alone often leads to information loss and cannot fully capture the athlete's internal neural state. Therefore, cross-modal data fusion has become a key research trend in this field (Pan J. et al., 2024).
2.3 Cross-modal fusion in sports analysisAs multimodal data becomes more accessible, cross-modal data fusion techniques have emerged as a crucial direction in sports performance analysis. Cross-modal fusion aims to effectively combine data from multiple sources (such as EEG signals, video, and motion sensor data) to provide a more comprehensive evaluation of sports performance (Yang et al., 2024). Traditional cross-modal fusion methods often employ early fusion or late fusion strategies. Early fusion merges data from different modalities at the input stage through simple concatenation or combination, while late fusion combines the predictions from independently trained models for each modality. However, these approaches can lead to information loss or modality inconsistency. Recently, attention-based cross-modal fusion methods have gained popularity (Neuwirth et al., 2023). Self-attention mechanisms can dynamically assign weights across different modalities, enabling efficient information integration. For example, some studies have introduced multimodal attention mechanisms in sports performance analysis to fuse EEG and video features, significantly improving the accuracy of action recognition (Pilacinski et al., 2024). Additionally, the Transformer model, known for its success in natural language processing, has been gradually applied to cross-modal data tasks. By incorporating global attention mechanisms, Transformers can capture long-range dependencies between different modalities, making them particularly suitable for handling spatiotemporally heterogeneous data like EEG signals and video. As cross-modal fusion technology continues to evolve, its application in sports performance analysis will help improve model accuracy and generalization, leading to comprehensive monitoring and precise analysis of athletes' conditions (Hu et al., 2021).
3 Methodology 3.1 OverviewThe proposed model, referred to as the Cerebral Transformer for Athletic Performance, aims to enhance the recognition and analysis of complex athletic movements using EEG data and video inputs. This model builds upon advanced attention mechanisms, including multi-scale and hybrid attention, to effectively process and integrate the diverse temporal and spatial information present in athletic actions. By leveraging a transformer-based architecture, the model is capable of capturing intricate relationships within both the spatial dimensions of video inputs and the temporal sequences of EEG signals, thereby enabling a deeper understanding of athletic performance and related neural activities. The overall data flow of the model begins with preprocessing of raw EEG signals and video inputs, followed by feature extraction stages for both modalities. These extracted features are then passed through multiple attention layers designed to capture both local and global dependencies across the spatial-temporal domains. The attention mechanisms used include a hybrid of local self-attention and k-NN attention, allowing the model to focus on the most relevant segments of the input data while ignoring noisy or irrelevant information. Additionally, the model integrates a fusion mechanism to combine predictions from the separate EEG and video streams, resulting in more accurate and holistic action recognition (as shown in Figure 1).
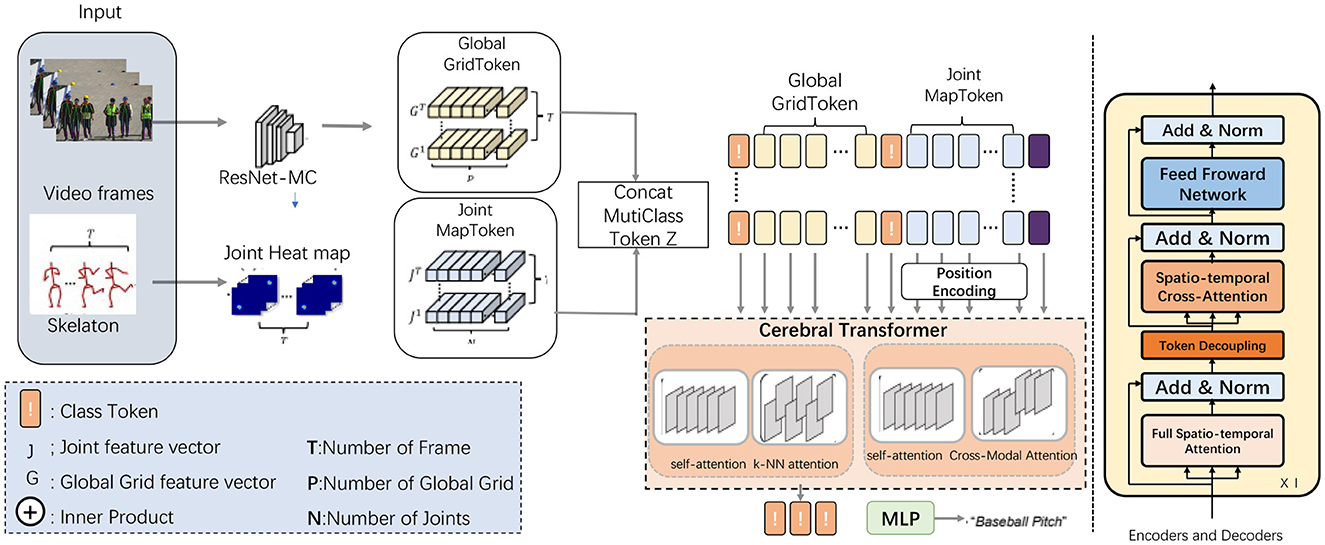
Figure 1. Cerebral transformer architecture. The data flow starts with video frames processed by ResNet-MC to generate the Global GridToken (G), while the skeleton data generates a Joint Heat Map to extract Joint MapToken (J). These tokens are concatenated with the Class Token to form the MultiClass Token Z. After positional encoding, the tokens enter the Cerebral Transformer, which processes them using mechanisms like self-attention, k-NN attention, and Cross-Modal Attention. Finally, the output is passed through an MLP to produce the final classification result.
“Cross-modal fusion” refers to the process of integrating information from multiple modalities, such as EEG and fMRI data, to leverage complementary features from each modality. This fusion typically involves aligning and combining the spatial, temporal, and spectral features extracted from each modality to enhance model performance. By effectively integrating diverse types of information, cross-modal fusion can improve the robustness and accuracy of downstream tasks, such as emotion recognition or sleep staging, by capturing patterns that may not be discernible within a single modality alone. “Adaptive attention mechanism" is a dynamic technique that allows a model to focus on the most relevant features or regions of the input data during different stages of processing. Unlike static attention methods that assign fixed weights, adaptive attention dynamically adjusts its focus based on the data and task requirements, enabling the model to better capture complex spatial-temporal dependencies or modality-specific features. In our work, this mechanism is designed to prioritize features across modalities and time steps, allowing for more effective learning and generalization in EEG-based tasks.
In this section, we provide a detailed breakdown of the model's architecture and data flow. Section 3.2 describes the fundamental data preprocessing steps for EEG and video inputs, focusing on how raw signals are transformed into actionable features. Section 3.3 explores the core transformer components of the model, including the multi-scale attention mechanism designed to handle the varying durations of athletic actions. Finally, Section 3.4 covers the fusion strategy employed to combine EEG and video-based predictions for improved performance. These components are critical to the model's ability to adaptively process diverse types of input data and recognize complex athletic actions in real-time settings.
3.2 PreliminariesIn this work, we address the problem of recognizing and analyzing complex athletic performance using EEG signals and video data. Formally, let X= represent the input sequence of EEG signals recorded over time, where xt∈ℝd denotes the EEG data at time step t and d is the dimensionality of the EEG signal. Similarly, let V= denote the corresponding video frames, where vt∈ℝh×w×c represents the frame at time step t, with h, w, and c denoting the height, width, and number of color channels of the frame, respectively. The goal is to map these sequences to a set of actions or movement labels Y=, where each yt∈C corresponds to one of the possible action classes from a predefined set C. To solve this problem, we define a model that learns a mapping f:(X,V)→Y, where the input consists of both EEG signals and video frames. The model must take into account both the spatial information present in the video frames and the temporal dependencies between consecutive frames and EEG signals. To do this, we utilize a transformer-based architecture that is well-suited for capturing both local and global dependencies across the input data. The core challenge lies in handling the high dimensionality and multimodal nature of the input. The EEG data provides temporal information about neural activity, while the video frames contain spatial and temporal information about the athlete's movement. Formally, the input can be represented as a joint distribution p(X,V), where X and V are conditionally dependent on the latent state of the athlete's actions. The objective of the model is to maximize the likelihood of the observed labels, i.e.,
argmaxθp(Y|X,V;θ), (1)where θ denotes the model parameters.
To achieve this, the model employs a sequence of operations that include both attention mechanisms and feature extraction techniques to transform the raw EEG signals and video frames into a latent representation that is suitable for classification. Let HEEG∈ℝT×dh and HVideo∈ℝT×hv represent the hidden states for the EEG and video data, respectively, where dh and hv are the dimensionalities of the hidden states. These hidden representations are obtained through a series of linear transformations and attention-based layers.
At each time step t, the attention mechanism computes a context vector ct for both EEG and video data as follows:
ctEEG=∑j=1Tαt,jEEGhjEEG, ctVideo=∑j=1Tαt,jVideohjVideo, (2)where hjEEG and hjVideo represent the hidden states at time step j, and αt,jEEG and αt,jVideo are attention weights that indicate the relevance of the hidden states at time step j with respect to the current time step t.
The attention weights are computed using a scaled dot-product attention mechanism:
αt,jEEG=exp(qtEEG · kjEEG)∑j′=1Texp(qtEEG · kj′EEG),αt,jVideo=exp(qtVideo · kjVideo)∑j′=1Texp(qtVideo · kj′Video), (3)where qtEEG, kjEEG, qtVideo, and kjVideo are query and key vectors derived from the EEG and video hidden states, respectively.
The context vectors ctEEG and ctVideo are then passed through a final classification layer that outputs the predicted action labels for each time step. The overall loss function is defined as the cross-entropy between the predicted labels and the ground truth labels:
L=−∑t=1T∑c∈Cyt,clogp(yt,c|X,V), (4)where yt, c is the ground truth label at time step t for class c, and p(yt,c|X,V) is the predicted probability of class c at time step t.
Through this approach, the model is able to learn a joint representation of EEG and video data that captures both the neural activity and physical movements of the athlete, ultimately enabling accurate action recognition and performance analysis.
3.3 Multi-stream moduleBuilding on the foundation laid in the preliminaries, the proposed model introduces a novel Adaptive Attention-based Multi-Stream Module to efficiently process the multimodal input data consisting of EEG signals and video frames. This module is designed to handle the complexity of both spatial and temporal dimensions, particularly in the context of recognizing athletic performance. The module integrates adaptive attention mechanisms and hierarchical feature extraction layers that are tailored for the unique characteristics of athletic movements and neural activity. The module is composed of two parallel streams—one for EEG signals and the other for video frames—with separate attention blocks dedicated to each modality. The adaptive attention mechanism dynamically adjusts the focus on relevant features based on the task at hand. This is achieved by employing both local and global attention layers to capture short-term and long-term dependencies within each modality, followed by a cross-modal attention block that fuses the features from both streams (as shown in Figure 2).
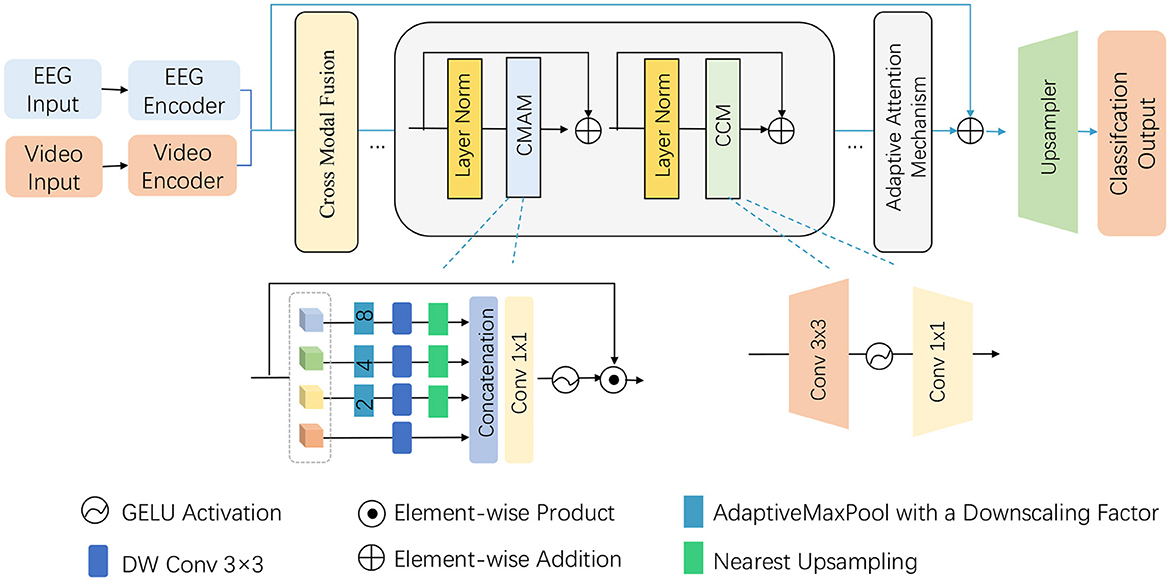
Figure 2. Illustration of the proposed Multi-Stream Module architecture and data flow. The model integrates EEG and video inputs through their respective encoders, followed by cross-modal fusion and adaptive attention mechanism. Key components such as Cross-Modal Attention Mechanism (CMAM), convolutional layers, GELU activations, and upsampling are used to process the extracted features and finally obtain the classification output. The figure gives a detailed overview of the hierarchical and modular structure of the proposed method.
3.3.1 EEG streamThe EEG stream processes raw neural signals through a series of attention layers designed to capture temporal dependencies in the data. Formally, let HEEG= represent the hidden states of the EEG signal after passing through a temporal convolutional layer, where T is the number of time steps and htEEG∈ℝdh denotes the hidden representation at time step t. We employ an adaptive attention mechanism that weighs the importance of different time steps based on the current state of the model. The attention weights are computed as:
αtEEG=exp(qtEEG · ktEEG)∑t′=1Texp(qt′EEG · kt′EEG), (5)where qtEEG and ktEEG are query and key vectors derived from the EEG hidden states. The resulting context vector is then computed as:
ctEEG=∑j=1Tαt,jEEGhjEEG. (6) 3.3.2 Video streamSimilarly, the video stream processes video frames through a spatial attention mechanism, followed by temporal attention to capture the dynamic nature of athletic performance. Let HVideo= represent the hidden states of the video frames, where each htVideo∈ℝhv is the hidden representation of the video frame at time step t. The spatial attention layer computes attention weights for each pixel within a frame, enabling the model to focus on the most relevant areas of the athlete's movement:
αtVideo=exp(qtVideo · ktVideo)∑t′=1Texp(qt′Video · kt′Video), (7)where qtVideo and ktVideo are query and key vectors derived from the video hidden states. The corresponding context vector for the video data is:
ctVideo=∑j=1Tαt,jVideohjVideo. (8) 3.3.3 Cross-modal attentionTo fully leverage the complementary nature of EEG signals and video data, we introduce a cross-modal attention block that fuses the information from both streams. This block is responsible for aligning the temporal sequences from EEG and video modalities and discovering cross-modal dependencies that are crucial for accurate performance analysis. The cross-modal attention weights are computed by combining the context vectors from both streams:
αtCross=exp(ctEEG · ctVideo)∑t′=1Texp(ct′EEG · ct′Video), (9)where ctEEG and ctVideo are the context vectors from the EEG and video streams, respectively. The final cross-modal context vector is then computed as:
ctCross=∑j=1Tαt,jCross(cjEEG+cjVideo). (10) 3.3.4 Final prediction layerThe fused cross-modal representation ctCross is passed through a fully connected layer followed by a softmax operation to predict the final action class for each time step:
p(yt|X,V)=softmax(WCrossctCross+bCross), (11)where WCross and bCross are the learned parameters of the final prediction layer.
This multi-stream architecture, powered by adaptive attention mechanisms, enables the model to dynamically adjust its focus based on the importance of various temporal segments and spatial regions, thus improving its ability to recognize complex athletic movements with high precision. By combining EEG and video inputs in this way, the model leverages the strengths of both data modalities, ultimately leading to more accurate and robust performance analysis.
3.4 Performance optimization and training strategyTo achieve optimal performance and efficiency, the model employs two critical strategies: a cyclic learning rate schedule and gradient clipping. These techniques ensure stability during training, enhance convergence speed, and prevent overfitting, allowing the model to generalize effectively across various athletic tasks.
3.4.1 Cyclic learning rate scheduleA cyclic learning rate schedule is used to accelerate convergence and avoid local minima during training. This schedule modulates the learning rate in a cyclical manner, enabling the model to explore different regions of the loss landscape early in training while settling into an optimal solution in the later stages. The learning rate ηt at time step t is given by:
ηt=ηmin+12(ηmax−ηmin)(1+cos(TcurTmaxπ
留言 (0)