
記住我
The task of segmenting color patterns in ancient architectural images is crucial for the preservation, restoration, and study of historical artifacts (Minaee et al., 2021). These intricate designs not only reflect the cultural and artistic achievements of past civilizations but also carry significant historical and symbolic meanings. Accurate segmentation allows for detailed analysis and digital archiving, which helps in restoration efforts and ensures the longevity of cultural heritage (Lin et al., 2024b). Additionally, such segmentation facilitates virtual reconstruction and tourism, enabling broader accessibility to these artifacts. However, this task is challenging due to the complexity of the patterns, variations in color and texture, and potential degradation over time (Yanowitz and Bruckstein, 1989). Therefore, there is a need for advanced computational techniques to accurately segment and analyze these patterns, supporting heritage conservation and academic research.
To address the limitations of manual segmentation and traditional pattern recognition techniques, early research in this field focused on symbolic AI and knowledge-based approaches. These methods relied on predefined rules and symbolic representations to identify specific motifs and color distributions present in ancient architectural designs (Abdullah et al., 2023). The core idea was to encode expert knowledge, often derived from historians, architects, or cultural heritage experts, into a set of rules that could be programmed into the system. For instance, these rules could specify the geometric shapes, color palettes, or symmetry patterns that are commonly observed in traditional architectures, allowing the system to segment and classify these elements accordingly. This knowledge-based approach could effectively handle simple and repetitive patterns, such as borders, uniform motifs, or repetitive floral designs, making them particularly suitable for controlled environments where variations were minimal (Lin et al., 2024a). Moreover, symbolic AI systems were relatively transparent and interpretable, allowing experts to understand how decisions were being made by the algorithm. This made it easier to debug or refine the system, as the rules could be adjusted or expanded based on new insights (Bennetot et al., 2022). However, these systems were often rigid and struggled to adapt to variations in pattern design or color caused by environmental factors such as lighting, aging, and deterioration of the material. For example, an image captured under different lighting conditions might cause colors to appear different, making it difficult for rule-based systems to maintain accuracy. Additionally, aging and wear can lead to faded colors or partially obscured patterns, which would not fit neatly into the predefined rules, resulting in misclassifications or incomplete segmentations. Another major drawback of these knowledge-based systems was their scalability. Developing and refining rules required extensive domain expertise and manual effort, which limited their ability to be applied across diverse datasets. Each new dataset or variation of pattern would potentially require a re-evaluation of the rules or the addition of new ones, leading to increased costs and time (Hong et al., 2024). While these methods were foundational in introducing automated segmentation, their inability to generalize across different datasets or adapt to new scenarios effectively made them less viable for more extensive, real-world applications. This rigidity and dependence on predefined rules prompted the exploration of more flexible, data-driven approaches that could learn directly from the data itself, without the need for explicit rule-coding, paving the way for machine learning techniques.
To overcome the rigidity of rule-based systems, researchers began to explore data-driven and machine learning techniques that could learn patterns directly from the data without the need for explicit programming of rules. This shift marked a significant evolution in segmentation tasks, as it allowed for more flexible models that could adapt to variations within the data. Machine learning models, which include classical algorithms such as Support Vector Machines (SVMs) (Ai et al., 2023), k-Nearest Neighbors (k-NN) (Fuadah et al., 2020), and Random Forests (Dhivyaa et al., 2020), rely on statistical learning to identify patterns within a set of labeled data. These models operate by training on features extracted from the images, such as edges, textures, and color histograms, to distinguish between different classes or elements of the architectural patterns. The advantage of these methods over symbolic AI was their ability to adapt to new data by learning from examples, which meant they could handle more variation in the input images. For instance, an SVM could be trained to recognize different color distributions across various lighting conditions, or a Random Forest could classify textures even if the patterns were slightly worn or degraded (Wu et al., 2022). This adaptability made machine learning approaches more robust in dealing with real-world data, which is often subject to inconsistencies and noise. However, the performance of these models heavily depended on the quality of the extracted features, which still required domain knowledge and manual design (Kheradmandi and Mehranfar, 2022). Feature extraction processes such as edge detection or texture mapping needed to be carefully crafted to ensure that the most relevant information was captured, which introduced a degree of subjectivity and potential bias.
With the advent of deep learning and pre-trained models, a new era of segmentation techniques emerged, significantly improving the accuracy and robustness of pattern recognition in ancient architectural images. Deep learning models, particularly Convolutional Neural Networks (CNNs) (Sultana et al., 2020), can learn features directly from the data, eliminating the need for manual feature engineering. These models have been applied to various tasks, including semantic segmentation, where they have demonstrated superior performance due to their ability to learn hierarchical representations of data. Further advancements with architectures like Fully Convolutional Networks (FCNs) (Calisto and Lai-Yuen, 2020), U-Net (Siddique et al., 2021), and DeepLab (Azad et al., 2022) allowed for pixel-level segmentation, enabling precise delineation of patterns. More recently, transformer-based models and pre-trained architectures have been employed to handle long-range dependencies and complex spatial relationships, overcoming the limitations of earlier machine learning models. Despite their success, deep learning approaches require large datasets for training, and their performance can be hindered by variations in data quality, such as noise and degradation present in historical artifacts. Furthermore, these models are often computationally intensive, making them less feasible for real-time applications or deployment on devices with limited resources.
To address the above limitations, we propose our method ArchPaint-Swin, which combines the strengths of hierarchical vision transformers and multi-scale attention mechanisms to effectively segment complex color patterns in ancient architectural images. Unlike traditional models that either rely on rigid rules or manual feature design, ArchPaint-Swin leverages the power of deep learning while integrating multi-scale processing and adaptive feature refinement, ensuring robust performance even under challenging conditions. By incorporating diffusion-based robustness enhancement, our model can handle variations in color, texture, and quality, making it well-suited for the segmentation of intricate historical patterns. This approach not only improves accuracy and efficiency but also reduces the computational overhead, making it viable for both large-scale analysis and real-time applications in the field of cultural heritage preservation.
• Our method introduces a new hierarchical vision transformer backbone combined with multi-scale self-attention, enabling precise segmentation of intricate patterns by effectively capturing both local and global features.
• The approach is adaptable across multiple scenarios, ensuring high efficiency and generalizability, making it suitable for diverse datasets and real-time applications with reduced computational requirements.
• Experimental results demonstrate that our model consistently outperforms state-of-the-art methods, achieving higher accuracy, recall, and F1 scores while maintaining lower inference time and computational overhead.
2 Related work 2.1 Traditional convolutional neural networks for segmentationConvolutional Neural Networks (CNNs) have been the backbone of many image segmentation models due to their ability to capture spatial hierarchies in images. Early approaches like Fully Convolutional Networks (FCNs) laid the foundation for using deep learning in pixel-wise classification tasks. Subsequent improvements, such as U-Net and its variants, introduced skip connections to merge features from different layers, allowing for the capture of both high-level semantics and low-level details. Models like DeepLab series utilized dilated convolutions to expand the receptive field without increasing computational cost, significantly improving performance on complex datasets like Pascal VOC and MS COCO (Wang, 2024). Despite their success, CNN-based models have limitations, particularly when it comes to handling long-range dependencies within images. This is because convolution operations are inherently local, capturing information from a limited receptive field. To mitigate this, techniques such as atrous convolutions and multi-scale feature pyramids have been used. However, these solutions often come at the cost of increased computational overhead and fail to capture relationships effectively across distant regions (Jin et al., 2024b). This limitation has prompted the exploration of alternative architectures, such as transformers, which can handle global contexts more naturally. Our work seeks to address the limitations of traditional CNNs by leveraging hierarchical vision transformers that combine multi-scale features with efficient attention mechanisms (Li et al., 2024).
2.2 Vision transformers and their applications in segmentation 2.2.1 Transformer-based UNet variantsSwin-UNet (Cao et al., 2022) is a pioneering model that combines Swin Transformer with the UNet structure, achieving remarkable results in medical image segmentation. It employs a sliding window approach to effectively capture both local and global features. However, the basic structure of Swin-UNet has since been extended by numerous variants that further enhance its multi-scale processing and detail preservation capabilities. For instance, Rahman et al. introduced the Multi-scale Hierarchical Vision Transformer (Rahman and Marculescu, 2024), which utilizes cascaded attention decoding to achieve superior fine-grained segmentation. Similarly, Xie Y. et al. (2021) proposed CoTr, which efficiently bridges CNN and Transformer layers to improve segmentation performance in 3D medical imaging. Furthermore, AgileFormer (Qiu et al., 2024) incorporates spatially adaptive Transformer modules, enabling the model to adjust dynamically to input images of different resolutions. In comparison, our model advances multi-scale feature extraction and information flow with unique adaptive multi-scale attention and cascaded attention decoding mechanisms, achieving robustness and precision in segmenting intricate architectural and cultural heritage images.
2.2.2 Skip-connection-based modelsMany segmentation models leverage skip-connections to enhance detail preservation and cross-scale feature fusion. UC-TransUNet (Wang et al., 2022), for example, redefines the skip-connections of UNet from a channel-wise perspective by introducing Transformer modules, thereby capturing multi-scale contextual information more effectively. UNet 3+ (Huang et al., 2020) further improves feature propagation across scales through full-scale connections, enabling low- and high-resolution features to be fused more efficiently within the network. Attention U-Net (Oktay, 2018) incorporates attention mechanisms that automatically focus on more informative regions of the image, improving segmentation accuracy. While these models improve in terms of detail handling and boundary preservation, our model's cascaded attention decoding incorporates a dynamic feedback mechanism, allowing it to adaptively process details across scales. This capability is particularly advantageous for segmenting architectural images with complex details, a feature that has not been extensively explored in existing models.
2.2.3 Diffusion models for segmentationDiffusion models have recently shown promise in image generation and segmentation tasks. SegDiff (Amit et al., 2021), for instance, proposes a segmentation approach based on diffusion probabilistic models, progressively removing noise to obtain refined segmentation results. Although diffusion models demonstrate robust performance in segmentation tasks, their applications are primarily focused on generative tasks. In our work, we innovatively incorporate a diffusion model within the segmentation pipeline as a conditional adaptive diffusion module. This module dynamically adjusts the diffusion strength based on contextual information from the image, a feature that distinguishes it from conventional diffusion-based post-processing (Ruiying, 2024). This conditional adaptive diffusion process provides our model with enhanced robustness, allowing it to handle noise, degradation, and other artifacts commonly encountered in architectural and cultural heritage images. By integrating the diffusion model directly within the segmentation process, we enable more effective noise management, which is critical in preserving details and improving segmentation accuracy in challenging real-world scenarios (Jin et al., 2024a).
2.3 Robustness enhancement and multi-scale feature fusion in segmentationRobust segmentation models need to handle diverse and noisy data, especially in real-world applications where conditions can vary significantly. Traditional approaches often rely on data augmentation and ensemble methods to improve robustness. However, these methods increase the complexity of the training process and do not guarantee improved performance in unseen scenarios. Recent research has focused on incorporating robustness directly into the model architecture. For instance, the use of attention mechanisms helps models focus on relevant features, but these mechanisms are still sensitive to noise and may struggle to generalize across different datasets (Atzori et al., 2016). Multi-scale feature fusion has been a popular technique to address these issues. Methods like Feature Pyramid Networks (FPN) combine features extracted at different scales to capture both fine details and broader contextual information. However, simple feature merging is often insufficient, as it can lead to redundant information and inefficient processing. More recent works, such as HRNet, attempt to maintain high-resolution representations throughout the network, enabling better feature preservation (Jin et al., 2023). Our approach extends this idea by introducing a dynamic feature fusion strategy that selectively integrates features across scales, guided by adaptive attention mechanisms. Additionally, we enhance robustness by incorporating a diffusion-based module, which iteratively refines features to reduce noise and improve the quality of segmentation outputs. This design allows our model to achieve superior performance across diverse datasets, making it more resilient in challenging environments and more efficient in real-time applications.
3 Methodology 3.1 OverviewOur proposed model introduces a novel approach to segmentation tasks by integrating multiple advanced architectures and strategies to enhance performance in complex scenarios. The model primarily leverages the synergy between multi-scale hierarchical structures, robust fusion mechanisms, and attention-driven modules to achieve high-resolution, accurate segmentation results across diverse data types. The core structure comprises a hierarchical multi-stage processing pipeline, designed to capture fine-grained details as well as broad contextual information, ensuring that both local and global features are effectively utilized. The architecture initiates with a multi-scale transformer-based backbone that performs hierarchical processing, capturing features across various resolutions and scales. By embedding multiple attention windows, it effectively addresses the limitations of traditional single-scale attention models. This is followed by a sophisticated fusion mechanism that dynamically integrates features from different scales, ensuring consistency and reducing redundancy. Subsequently, an advanced attention-based decoder refines these multi-modal features to produce highly accurate segmentation maps, while a diffusion-based enhancement module ensures robustness against variations and improves the generalization capability.
Our model integrates several innovative components to handle the challenges inherent in ancient architectural images, particularly those affected by degradation, noise, and artifacts. Central to this is the diffusion-based robustness enhancement module, which iteratively refines feature representations to reduce noise while preserving intricate details. This module adapts its denoising strength contextually: it applies gentler processing to areas with delicate patterns, ensuring key features are maintained, and more intensive denoising in smoother regions to clear away irrelevant noise. This adaptive approach helps the model retain crucial architectural details while minimizing the impact of fading and other common forms of image degradation. The model also employs a multi-scale attention mechanism to capture both local and global features, enhancing resilience to lighting inconsistencies and quality variations. By analyzing information across multiple scales, the model isolates essential structural details from common artifacts, such as scratches and discolorations. Additionally, a dynamic feature feedback loop within the diffusion module refines feature representations iteratively, allowing the model to focus on significant architectural elements while progressively filtering out noise. Together with data augmentation techniques that simulate real-world variations, such as blur and lighting shifts, and positional encoding to maintain spatial consistency, these strategies enable the model to effectively analyze and segment ancient architectural patterns even in challenging conditions. This comprehensive approach makes the model robust and highly suited for the digital preservation of cultural heritage images.
We organize this section as follows. In Section 3.2, we describe the hierarchical vision transformer backbone that is at the core of our model, explaining how multi-scale attention is achieved. Section 3.3 discusses the fusion mechanism and the innovative cascaded attention decoding strategy that aggregates features efficiently. Finally, in Section 3.4, we introduce the diffusion-based enhancement module, which mitigates noise and improves the robustness of the segmentation output. Through this modular and highly integrated design, our model aims to set a new benchmark in segmentation tasks, effectively combining state-of-the-art techniques to address challenges in precision, robustness, and computational efficiency.
3.2 Hierarchical vision transformer backboneThe backbone of our model is constructed upon a hierarchical vision transformer framework, designed to capture multi-scale features across different levels of resolution. Unlike traditional transformer architectures that rely on a single-scale self-attention mechanism, our approach implements a multi-scale self-attention strategy, allowing the model to process visual information at various granularities. This method addresses the inherent limitations of single-scale attention by enabling the model to learn more generalizable features, thus improving performance across diverse segmentation tasks (as shown in Figure 1).
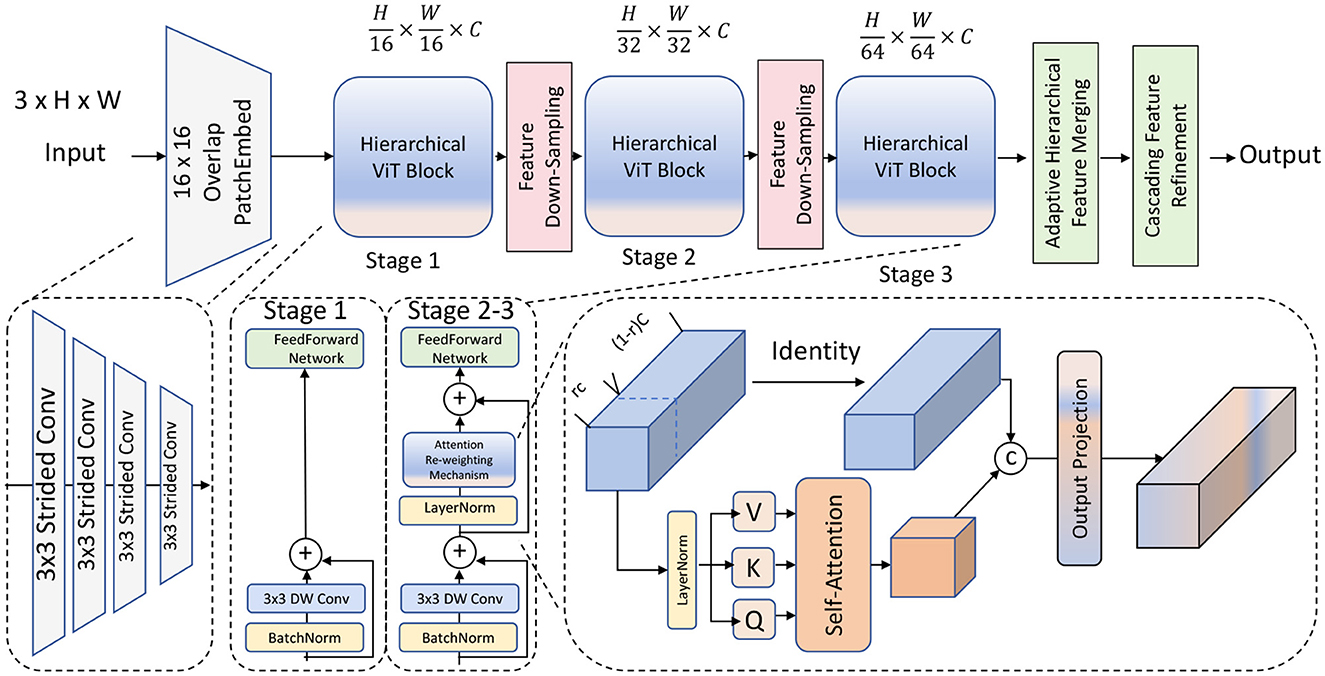
Figure 1. A hierarchical vision transformer model architecture. The model begins with an overlapping patch embedding module, followed by three main stages, each containing multi-scale self-attention blocks with feature down-sampling to capture different granularities. The architecture includes adaptive hierarchical feature merging and cascading feature refinement to integrate information across scales, enhancing fine-grained details and broader contextual understanding. The output layer consolidates these features, optimized by an attention re-weighting mechanism for improved segmentation accuracy.
3.2.1 Multi-scale self-attention moduleThe core of the hierarchical backbone in our model is the multi-scale self-attention module, denoted as Ams. This module is designed to address the limitations of conventional attention mechanisms by enabling the model to capture features across multiple scales, effectively combining fine-grained local details with broader contextual information. Let I be the input image, which is initially divided into smaller patches. Each patch is processed through a stem network, which consists of a series of convolutional layers that transform the raw pixel data into a set of feature embeddings . These embeddings represent the essential characteristics of the patches and serve as inputs to the multi-level transformer blocks.
The architecture is designed to handle multiple hierarchical levels, where each level processes the embeddings at different scales. The output of the transformer block at a specific level l is denoted by Fl, which can be mathematically expressed as:
Fl=Ams(El)=Softmax(QlKl⊤dk)Vl, (1)where El represents the input embeddings at level l, and Ql, Kl, Vl are the query, key, and value matrices, respectively, derived from El. The matrices are calculated as follows:
Ql=WQEl, Kl=WKEl, Vl=WVEl, (2)where WQ, WK, WV are learnable weight matrices. The attention mechanism computes a weighted combination of values Vl, where the weights are determined by the similarity between queries Ql and keys Kl, scaled by the dimensionality dk to stabilize gradients during training. This scaling can be particularly important when working with large-scale data, as it prevents the computed values from becoming excessively large.
The multi-scale aspect is crucial in ensuring that both fine and coarse features are captured simultaneously. To achieve this, the feature embeddings are processed at multiple resolutions within the self-attention module. Specifically, we modify the input embeddings by applying a series of down-sampling and up-sampling operations, allowing the model to adjust the scale at which the attention is computed. For example, at a higher level, the embeddings might be down-sampled, focusing on broader patterns and contextual information, whereas at a lower level, the embeddings might maintain a higher resolution, preserving fine-grained details. The multi-resolution processing can be described by:
Fl(s)=Softmax(Ql(s)Kl(s)⊤dk)Vl(s), (3)where s denotes different scales, and Ql(s),Kl(s),Vl(s) are the scaled versions of the query, key, and value matrices. The outputs from various scales are then aggregated to form a comprehensive representation:
Fl=∑s=1SαsFl(s), (4)where αs are learnable weights that determine the contribution of each scale. This multi-scale aggregation allows the model to effectively integrate information from different resolutions, enhancing its ability to discern intricate patterns that might otherwise be missed. Additionally, to further improve the robustness of feature extraction, a positional encoding is added to the input embeddings El to preserve spatial information, ensuring that the attention mechanism accounts for the relative positions of patches within the image. The enhanced design of the multi-scale self-attention module enables the model to seamlessly adapt to complex patterns, making it well-suited for tasks requiring detailed segmentation, such as those involving ancient architectural color patterns.
3.2.2 Cascading feature refinement mechanismTo enhance feature aggregation across different scales, we introduce a cascading feature refinement mechanism within the transformer blocks. This mechanism is designed to iteratively improve feature representations by aggregating information from multiple layers, effectively combining low-level details with high-level contextual features. Unlike traditional hierarchical approaches that process features in a one-way manner, the cascading feature refinement allows each block to incorporate information from preceding layers. This enables the model to refine high-level representations without losing the essential context provided by initial, low-level details, leading to more accurate segmentation outputs (Figure 2). Formally, this cascading operation can be expressed as:
Hl=Fl+∑i=1l-1αiFi, (5)where Fl denotes the feature output at the current level l, and Fi represents the feature maps from previous levels. The coefficients αi are learnable weights that adaptively adjust the contribution of each preceding feature map, ensuring that only the most relevant information is passed forward. This adaptive weighting makes the refinement process more flexible, as it allows the model to prioritize different feature aspects depending on the data characteristics. The cascading mechanism is particularly beneficial in scenarios where segmentation tasks involve intricate patterns and subtle details, such as in architectural designs. By enabling a multi-level refinement, the model ensures that details are preserved while higher-level features capture broader, more abstract concepts. This results in a more cohesive representation that enhances the overall segmentation accuracy.
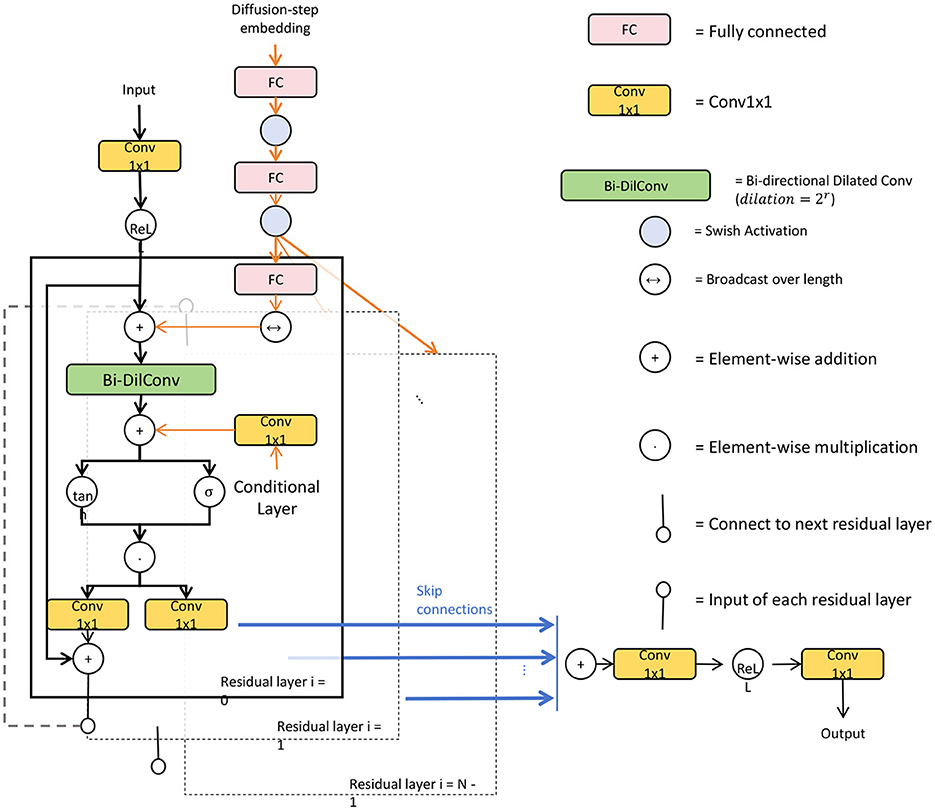
Figure 2. A detailed schematic diagram of a bidirectional dilated convolutional network with cascading feature refinement, showcasing the input pathway, diffusion-step embedding, and multiple residual layers. Key elements include Conv1x1 layers, fully connected (FC) layers, bidirectional dilated convolutions, and element-wise operations. The structure highlights skip connections and condition inputs, integrating both temporal and spatial features, while arrows indicate data flow across the network. The model employs Swish activation functions to enhance non-linearity and refine feature representations at each stage for improved accuracy in segmentation tasks.
3.2.3 Adaptive hierarchical feature merging strategyA critical component of the backbone is the adaptive hierarchical feature merging strategy, which consolidates information from different attention heads and scales. The goal of this strategy is to create a unified feature representation that seamlessly integrates multi-scale features extracted across various layers. This is achieved by using the multi-scale attention modules, Ams, at each hierarchical level, and combining their outputs. Let Fms be the final combined multi-scale feature map, then it can be defined as:
Fms=Concat(Ams1(E1),Ams2(E2),...,AmsL(EL)), (6)where Amsj represents the attention mechanism applied at the j-th level, and L denotes the total number of hierarchical levels. Each Amsj processes features at different resolutions, allowing the model to extract both coarse and fine details. The concatenation operation combines these multi-scale features, which are then passed through a set of convolutional layers to ensure smooth integration.
To further enhance the spatial consistency of the output, the concatenated feature map undergoes a series of convolutional and normalization layers that align and smooth out discrepancies between features from different scales. Let the processed output be represented as:
Ffinal=Conv(Fms)+γ·Norm(Fms), (7)where Conv(·) denotes the convolutional operations, Norm(·) represents batch normalization or layer normalization, and γ is a learnable parameter that adjusts the influence of the normalization. This final adjustment helps in maintaining consistency across spatial dimensions, ensuring that the features can be effectively used in subsequent processing steps. The adaptive hierarchical feature merging strategy is essential for tasks where understanding multi-scale features is critical. By consolidating information across multiple levels, the model ensures that both local patterns and global structures are captured, providing a robust feature set for downstream segmentation tasks. This design not only improves segmentation performance but also makes the model more resilient to variations in input data, such as changes in lighting, scale, or texture. Together, the cascading feature refinement and adaptive hierarchical merging enable the model to deliver high-precision, efficient segmentation results across diverse and challenging datasets.
Moreover, to handle variations in input data and improve generalization, our architecture includes a robust attention re-weighting mechanism, defined as:
Watt=Sigmoid(Winit+γ·ΔW), (8)where Winit is the initial attention weight, γ is a scaling factor, and ΔW represents the deviation observed during training. This adaptive re-weighting allows the model to focus more effectively on relevant regions, even when the input data varies significantly across instances.
3.3 Fusion and cascaded attention decodingIn order to effectively integrate multi-scale features and enhance segmentation accuracy, our model employs a novel Fusion and Cascaded Attention Decoding mechanism. This approach ensures that features from different stages of the backbone are aggregated and refined through a sophisticated decoding process, leading to improved performance, especially in scenarios involving complex visual patterns.
3.3.1 Dynamic multi-scale feature fusionThe first step in the decoding process is the dynamic multi-scale feature fusion, which integrates feature maps obtained from the hierarchical vision transformer backbone. The backbone produces feature maps at different scales, denoted as Fms(1),Fms(2),...,Fms(L), where L represents the total number of scales. Each feature map captures information at a specific resolution, allowing the model to understand both fine details and broader structures. The fusion mechanism adaptively combines these multi-scale features to produce a unified representation that retains essential information from each scale, leading to more accurate and robust segmentation outcomes.
The fusion process can be mathematically expressed as:
Ffused=∑j=1Lβj·Conv1×1(Fms(j)), (9)where βj are learnable weights that dynamically adjust the contribution of each scale, ensuring that the most relevant information is emphasized. The term Conv1 × 1 refers to a 1 × 1 convolution, which plays a crucial role in aligning the feature dimensions across different scales. This alignment is necessary because feature maps at various scales might have different resolutions, and the 1 × 1 convolution standardizes these dimensions, allowing them to be effectively integrated.
One of the key advantages of this dynamic fusion process is its ability to adaptively learn which scales are most important for the task at hand. For instance, in scenarios where fine-grained details are critical (e.g., segmenting intricate patterns in architectural images), the model can assign higher weights βj to lower-scale features that retain these details. Conversely, in tasks that require understanding of broader structures (e.g., identifying large regions in cityscapes), higher-scale features can be prioritized. This adaptability makes the model more versatile and capable of handling a variety of segmentation challenges. Moreover, the fusion process ensures that information from various scales is smoothly combined, reducing inconsistencies that might arise if the scales were processed independently. By summing the outputs from different scales with learnable weights, the model effectively preserves critical details across the image while also maintaining contextual information. The smooth integration is facilitated by the 1 × 1 convolutions, which not only align the dimensions but also help reduce noise and enhance the most salient features, resulting in a cleaner and more accurate segmentation map.
The effectiveness of the dynamic multi-scale feature fusion can be further enhanced by additional layers of processing after the initial fusion. For example, the fused feature map Ffused can be passed through additional convolutional and normalization layers to further refine the integrated features:
Frefined=Norm(Conv3×3(Ffused))+Ffused, (10)where Conv3 × 3 refers to a standard convolution operation that captures local relationships, and Norm indicates a normalization layer that helps stabilize the learning process. The addition of Ffused ensures that the original fused information is preserved, similar to a residual connection, which enhances the robustness and stability of the fusion. The dynamic multi-scale feature fusion mechanism ensures that the decoding process can effectively utilize information across various scales, balancing the need for both detailed and contextual understanding. This capability is crucial for tasks like segmenting architectural patterns or urban scenes, where both small details and larger structures need to be accurately identified. By learning to adaptively weigh features from different scales, the model becomes more efficient and accurate, capable of delivering high-quality segmentation results across diverse scenarios.
3.3.2 Cascaded attention decodingAfter the multi-scale features are fused, the model applies a cascaded attention decoding strategy to refine these features progressively, stage by stage. This decoding approach is designed to iteratively enhance the quality of the feature maps, ensuring that each refinement stage builds upon the output of the previous one. By incorporating contextual information at every step, the decoder effectively captures both fine details and broader spatial relationships, leading to more accurate segmentation results (as shown in Figure 3).
留言 (0)