
記住我
Salient object detection (SOD) aims to find the most noticeable area or target in an image, and has developed rapidly in recent years. In the context of the rapid development of computer technology and deep learning, SOD techniques are widely used in various fields, such as target tracking (Lee and Kim, 2018), video detection (Cong et al., 2019), image fusion (Zhang and Zhang, 2018; Cheng et al., 2018), target segmentation (Li et al., 2020, 2019), and so on.
SOD only using RGB images still suffer from performance degradation in the challenging of cluttered backgrounds, poor illumination, or transparent objects. In recent years, thermal cameras have been developed to capture infrared radiation from objects with temperatures above the zero. Thermal infrared iamges can help to detect significant objects. Even in complex conditions such as messy background of RGB image, weak light or dark, the objects in thermal infrared images will be prominent. Thus, RGB-Thermal SOD has become popular to overcome the above challenges by introducing the complementary modality information. Traditional RGB-T SOD methods mainly use low-level features and certain priors to detect targets, such as color contrast and background priors. In recent years, many excellent SOD methods have been proposed. Compared with single-channel RGB images, RGB-T images provide complementary saliency cues, which improve the performance of significance detection. For example, Niu et al. (2020) introduced a dual-stream boundary-aware network that integrates cross-modal feature sampling and multi-scale saliency aggregation, while Zhang et al. (2019) proposed an RGB-T salient object detection network based on multi-level CNN feature fusion, utilizing joint attention and information transfer units. Huang et al. (2020) designed a low-rank tensor learning model to suppress redundant information and enhance the correlation between similar image regions. Tang et al. (2019) introduced a method based on a coordinated sorting algorithm for RGB-T saliency detection, which employs a unified ranking model to describe cross-modal consistency and reliability.
Existing RGB-T salient object detection (SOD) methods face significant challenges due to the inherent differences between RGB and thermal images. While RGB images excel at capturing detailed textures under normal lighting conditions, thermal images are more effective in highlighting salient regions in low-light or cluttered environments. Despite the complementary nature of these two modalities, many existing methods fail to fully leverage this relationship. They often extract similar information from both RGB and thermal images, underutilizing the unique contributions of each modality. Furthermore, basic feature fusion strategies, such as concatenation or simple convolutional operations, fail to capture the deeper, more complex relationships between these modalities, limiting the effectiveness of the fused features and reducing the overall performance of salient object detection.
In addition to these challenges in feature fusion, many current approaches neglect the critical role of edge information in refining object boundaries. Accurate edge refinement is crucial for precise saliency map prediction, but it is often underexploited in existing methods. As a result, object boundaries tend to be poorly defined, and the suppression of background noise across the two modalities is inconsistent. This leads to irrelevant details being retained, further diminishing the accuracy of saliency detection. Without sufficient enhancement of salient regions or consistent background suppression, these methods fail to make full use of the combined strengths of RGB and thermal images.
To address these limitations, we propose an end-to-end edge-guided feature fusion network (EGFF-Net) for RGB-T salient object detection. Our approach is designed to fully exploit the complementary information between RGB and thermal images through a cross-modal feature extraction module (CMF), which aggregates both shared and distinct features from each modality. This module not only captures feature-wise information from each local region but also ensures effective fusion of modality-specific details, overcoming the shortcomings of existing simple fusion strategies. By leveraging atrous spatial pyramid pooling (ASPP) modules within the CMF, we also achieve a large receptive field and high-resolution feature maps, which further improve the fusion of complementary information.
Moreover, to enhance the precision of object boundaries, we introduce an edge-guided feature fusion module. This module incorporates multi-level features from RGB images to refine the edges of salient regions. Specifically, we extract edge features from the second layer of the RGB branch, which contains detailed texture information, and combine them in a cascade with features from deeper layers to guide the fusion process. This edge-guided refinement ensures that the boundaries of salient objects are more accurately captured, addressing the limitations of previous methods that overlook edge information. Additionally, our approach enhances the overall saliency representation, resulting in more effective suppression of irrelevant background details and more accurate detection of salient regions under various conditions.
By integrating multi-level edge features and applying a layer-by-layer decoding structure, our method ensures both effective feature fusion and precise saliency map prediction. The edge-guided fusion strategy, in combination with the CMF module, directly addresses the challenges of incomplete feature fusion and poor edge refinement, ultimately leading to improved performance in RGB-T SOD tasks. The main contributions of this work are as follows:
1. We proposed the structure of double-branch edge feature nested network for RGB-T SOD, which consists cross-modal feature extraction with the encoding format, salience map prediction and a layer-by-layer decoding format for the prediction of saliency targets.
2. We proposed the cross-modal feature extraction module (CMF) to extract and aggregate united features and intersecting information between two modalities. Two atrous spatial pyramid pooling modules (ASPPs) (Chen et al., 2017) are embedded into CMF module for obtaining large receptive field as well as high resolutions. Three branches, i.e., RGB-T branch, T-RGB branch, and mixed branch are designed when aggregating the transmembrane state features, so as to better retain the effective information of different modes and realize the mutual compensation between the two modalities.
3. We proposed an edge-guided feature fusion module that enables the refinement of salient target boundaries by edge information, as well as enhancing the overall salient target region and suppressing redundant information. The secondary feature extraction for edge features is designed on the cascaded feature map using a specific convolution block to obtain edge feature maps of the RGB images as the mult-level refinements of salient target boundaries.
2 Related works 2.1 RGB-T salient object detectionRGB-T Salient Object Detection (SOD) has attracted increasing attention due to the complementary nature of visible light and thermal infrared images. Tu et al. (2020) introduced a collaborative graph learning algorithm for RGB-T saliency detection, along with the VT1000 dataset containing 1000 RGB-T image pairs. Li et al. (2021) proposed a Hierarchical Alternate Interactions Network (HAINet) for RGB-D SOD, which could be adapted for RGB-T tasks by focusing on cross-modal interaction. Tu et al. (2021) proposed a dual-decoder framework that models interactions across multi-level features, modalities, and global contexts to exploit modality complementarity. However, its reliance on pre-defined interaction mechanisms limits its adaptability to dynamically changing conditions and subtle modality variations. Liu et al. (2022) introduced SwinNet, which employs Swin Transformers for hierarchical feature fusion and attention mechanisms to bridge the gap between modalities. To address image misalignment, Tu et al. (2022) presented DCNet, incorporating spatial and feature-wise transformations for modality alignment and a bi-directional decoder for hierarchical feature enhancement. While promising, DCNet's complex alignment strategy and decoding structure hinder its efficiency in real-time applications. Pang et al. (2023) introduced CAVER, a view-mixed transformer emphasizing global information alignment, and Zhou et al. (2023) presented WaveNet, a wavelet-based MLP employing a transformer teacher for cross-modality feature fusion. These methods demonstrated the potential of global alignment mechanisms but often struggled with fine-grained local details. More recently, He and Shi (2024) proposed a SAM-based RGB-T SOD framework incorporating modules such as High-Resolution Transformer Pixel Extraction to refine detection. However, its reliance on pre-trained models and complex feature extraction pipelines may limit adaptability in diverse scenarios.
Despite these advancements, RGB-T SOD remains challenging due to the inherent differences in RGB and thermal modalities, particularly in suppressing complex backgrounds and enhancing salient object boundaries. While Tu et al. (2021) proposed a dual-decoder framework to exploit modality complementarity, its reliance on pre-defined interaction mechanisms limits its adaptability to dynamic conditions. Liu et al. (2022) introduced SwinNet, which employs Swin Transformers for hierarchical feature fusion and attention mechanisms to bridge the gap between modalities. While its transformer-based architecture effectively captures long-range dependencies, its fusion strategy relies heavily on spatial alignment and channel re-calibration, which may fail to fully exploit complementary information from RGB and thermal modalities. Methods like CAVER (Pang et al., 2023), which emphasize global feature alignment, struggle with capturing fine-grained local details, particularly in the presence of background clutter. Similarly, WaveNet (Zhou et al., 2023) utilizes wavelet-based MLPs for cross-modality feature fusion, but its reliance on wavelet transforms for global feature aggregation may limit its ability to refine object boundaries and capture local texture details effectively. Tu et al. (2022) proposed DCNet to address image misalignment, but its complex alignment strategy and decoding structure hinder efficiency in real-time applications.
EGFF-Net overcomes these limitations through two key innovations: the Cross-Modal Feature (CMF) module and the Edge Embedding Decoder (EED) module. The CMF module improves modality fusion by dynamically aggregating complementary features from both RGB and thermal images, using multiple branches (RGB-T, T-RGB, and mixed) to ensure better retention of cross-modal information and mutual compensation between the modalities. The EED module, on the other hand, enhances boundary refinement by incorporating multi-level edge features from the RGB modality, which directly improves the accuracy of object boundaries, especially in cluttered environments or when thermal signals are weak. Together, these modules address the challenges of incomplete feature fusion and insufficient boundary refinement, ensuring robust saliency detection even in scenarios with complex backgrounds or misaligned images.
3 MethodologyThe proposed network mainly includes cross-modal feature extraction, edge-guided feature fusion, salience map prediction and hybird loss function. As shown in Figure 1, our network is a double-input end-to-end network structure, which is fed with RGB-T images. In order to better extract the features of different modes and realize the information complementarity between the feature maps of the transmembrane state, we propose the cross-modal feature extraction method, which can effectively integrate information between different modes. Considering that edge information is very helpful in refining the edge details of significant areas, edge-guided feature fusion module is explored to enhance the edge features of salient region. The cascaded decoders are used to integrate the multi-level features to generate prediction map.
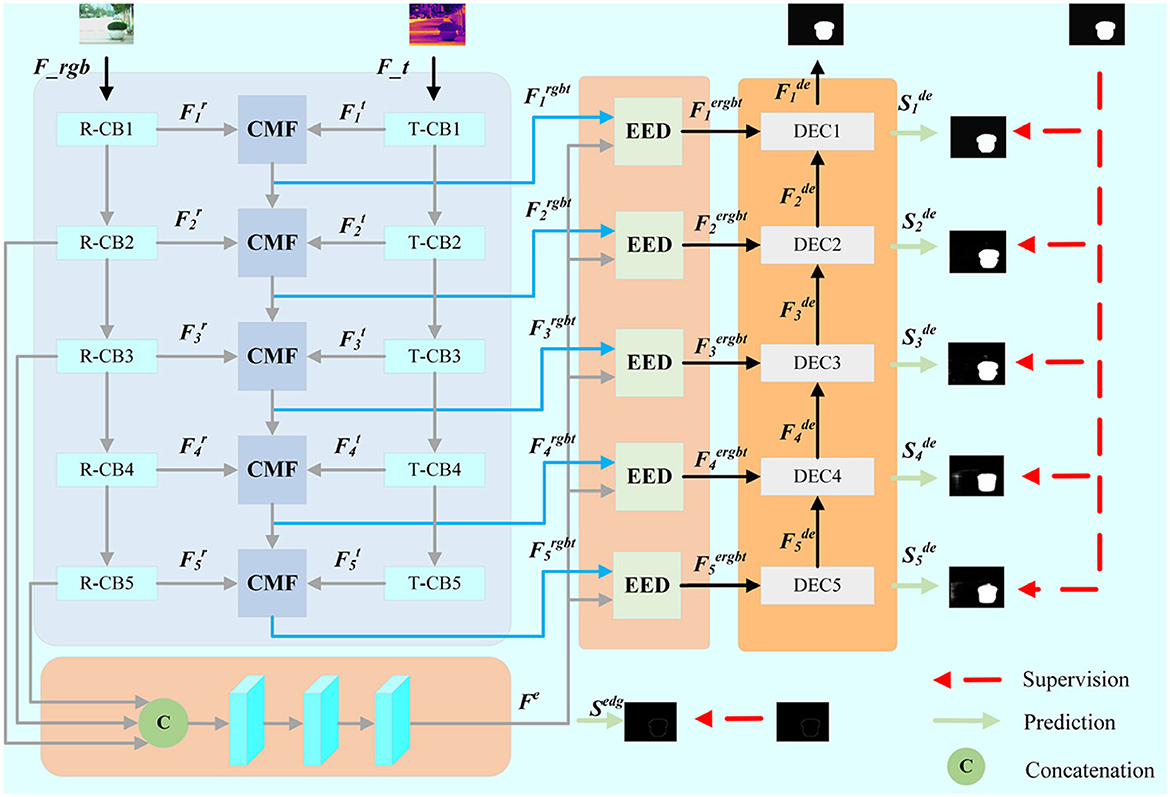
Figure 1. The framework of the proposed EGFF-Net. CMF and EED stand for Cross Model Fusion Module (CMF) and Edge Embedding Module (EED), respectively.
3.1 Cross-modal feature extractionThe proposed network is based on the encoding-decoding architecture. The double-branch VGG-16 is adopted as the backbone, which only retains the previous convolution layer, and removes the last pooling layer and all full connection layers. As shown in Figure 1, the RGB-T images are fed into two branches for feature extraction. R-CBi and T-CBi (i ∈ ) are used to extract RGB and thermal features, respectively. The dual encoder outputs the i-th layer features of the RGB and thermal encoder, which denotes as Fir and Fit (i ∈ ), respectively.
In order to better fuse the information of different modes, we propose the cross model fusion module (CMF) as shown in Figure 2. Firstly, ASPPs are embedded into CMF module for obtaining large receptive field and high resolution at the same time. frgb and ft are feature maps of ASPPs performing, respectively. Three branches, i.e., RGB-T branch, T-RGB branch, and mixed branch are designed in CMF module when aggregating the transmembrane state features, so as to better retain the effective information of different modes and realize the mutual compensation between the two modes.
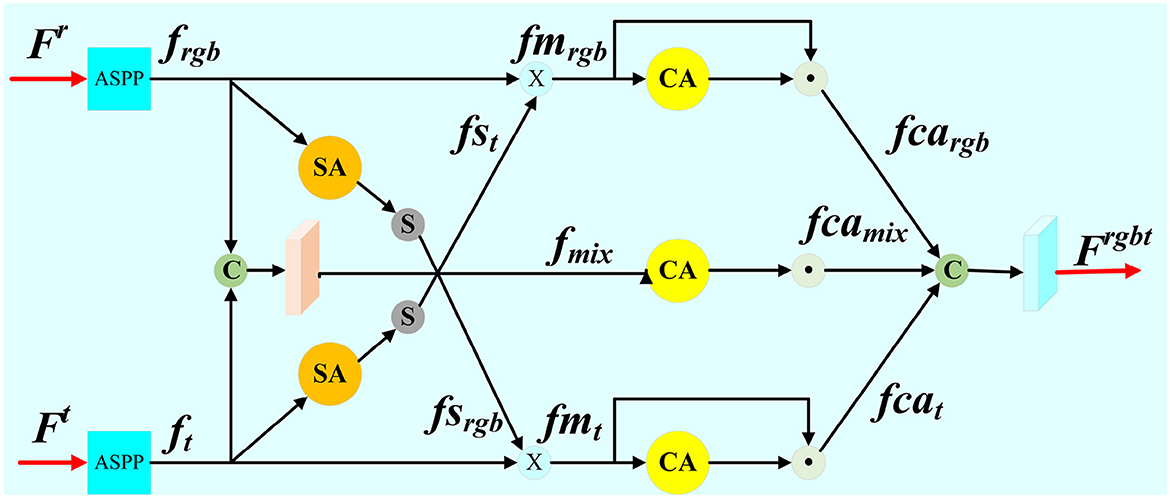
Figure 2. Detail illustration of proposed Cross Model Fusion Module (CMF).
We perform ft through a spatial attention mechanism (SA), and then through the Sigmoid function (S) in RGB-T branch. The spatial proportion of the thermal feature map fst is obtained, and the pixel values range from 0 to 1. The original feature map frgb multiplies with the attention feature maps fst to obtain the auxiliary feature map fmrgb, which enhances the salient region of the RGB feature maps. This operation can be formally represented as:
SA(f)=σ(conv(cat(GMPs(f),AVGs(f)))) (1) fst=σ(SA(ft)) (2) fmrgb=frgb⊗fst (3)where GMPs(·) represents the maximum pooling of spatial attention mechanisms, AVGs(·) represents the average pooling of spatial attention mechanisms, conv(·) for convolutional operation, σ(·) for Sigmoid function, SA(·) represents spatial attention mechanisms, ⊗ respresents matrix multiplication. T-RGB branch has the symmetrical structure with RGB-T branch. The thermal feature maps ft is multiplied by the RGB feature maps fsrgb, which has been performed through the attention mechanism and Sigmoid function. The auxiliary feature map fmt is obtained as follows:
fsrgb=σ(SA(frgb)) (4) fmt=ft⊗fsrgb (5)In the mix branch, RGB feature maps frgb and thermal infrared feature maps ft are concatenated to extract the mixed feature fmix of transmembrane states as follows:
fmix=conv(cat(frgb,ft)) (6)In the RGB-T branch, thermal features (ft) are processed through a spatial attention (SA) mechanism, which emphasizes salient regions by generating spatial attention weights (fst) that highlight significant areas in the thermal feature map. These attention weights are then applied to the RGB feature map (frgb) to produce an enhanced RGB feature map (fmrgb) where regions aligned with thermal saliency are emphasized. This selective enhancement effectively suppresses irrelevant details in RGB features that are not supported by thermal information. The RGB-T branch thus leverages thermal cues to refine RGB feature maps, enhancing their focus on salient regions.
The T-RGB branch complements the RGB-T branch by following a symmetric design. Here, RGB features (frgb) are processed through the same spatial attention mechanism, producing spatial attention weights (fsrgb) that highlight significant areas. These weights are then applied to the thermal feature map (ft), producing an enhanced thermal feature map (fmt). This operation ensures that salient regions in thermal images are reinforced using RGB information, particularly in scenarios where thermal signals are weak or ambiguous. The T-RGB branch thus strengthens thermal features by leveraging complementary cues from RGB images.
While the RGB-T and T-RGB branches focus on modality-specific refinement, the mixed branch addresses cross-modal feature integration at a more global level. In this branch, RGB (frgb) and thermal (ft) features are concatenated to form a unified feature representation (fmix). This concatenated feature map is processed through convolutional layers to learn mixed modality representations that capture high-level interactions between RGB and thermal modalities. The mixed branch ensures that the complementary information across both modalities is preserved and exploited to its full potential.
The channel attention mechanism is applied to obtain the weights of each channel from feature maps, and then these weights are multiplied with the corresponding feature maps. Finally, the feature maps of the three branches are concatenated, and the aggregated feature Firgbt (i ∈ ) is extracted as follows:
CA(f)=σ(FCβ(FCα(GMPc(f)))⊕FCβ(FCα(AVGc(f)))) (7) fcargb=CA(fmrgb)⊙fmrgb (8) fcat=CA(fmt)⊙fmt (9) fcamix=CA(fmix)⊙fmix (10) Frgbt=conv(cat(fcargb,fcat,fcamix)) (11)where GMPc(·) represents maximum pooling of channel attention mechanisms, AVGc(·) represents the average pooling of channel attention mechanisms, FCα(·) represents the fully connected layer of the Relu activation function, FCβ(·) represents the fully connected layer of the Sigmoid activation function, CA(·) represents channel attention mechanisms, fcargb, fcat, fcamix represent the performing of fmrgb, fmt, fmix after the channel attention, respectively, ⊙ represents elemental multiplication, ⊕ represents elemental summation.
3.2 Edge-guided feature fusionConsidering that edge information is very helpful in refining the edge details of significant areas, edge-guided feature fusion module is explored to enhance the edge features of salient region. For the reasons that RGB images contain more detailed textures, we choose the second layer feature maps of RGB combined with the fourth and fifth layer feature maps in a cascade way to extract edge information as a guide for feature fusion. The secondary feature extraction as shown in Figure 1 is performed on the cascaded feature map using a specific convolution block to obtain edge feature maps Fe of the RGB images. The representation can be expressed as:
Fe=convedg(cat(F2r,up(F3r),up(F5r))) (12)where Fir represents the feature maps of the i-th layer, up(·) represents upsampling, and convedg(·) represents edge feature extraction convolution.
Edge embedding module (EED) is designed to embed the edge feature Fe with the aggregated feature Frgbt, as shown in Figure 3. The aggregated feature Frgbt and edge feature Fe are each subjected to one feature extraction via a convolution layer. Then, we cascade the salient region feature maps frgbt with the edge feature maps fe. In order to better capture the contextual information and obtain a larger perceptual field, ASPP module is employed to extract features from the cascaded feature maps. The feature map fe−rgbt is obtained as the edge-to-significance region guide. These operations are expressed as the following:
frgbt=conv(Frgbt),fe=conv(Fe) (13) fe-rgbt=ASPP(cat(frgbt,fe)) (14)Theoretically, the feature maps of salient region focus on the salient target, while the feature maps of edges pay more attentions on the texture of edges. In order to enhance the features of salient targets, both of the salient region feature map frgbt and the edge feature map fe are performed through a channel spatial attention mechanism and Sigmoid function, respectively.
fsrgbt=σ(SA(frgbt)),fsrgbt∈ [0,1] (15) fse=σ(SA(fe)),fse∈ [0,1] (16)Then, we perform an addition operation on fsrgbt and fse, and multiply the result with the map of salient region features to strengthen the saliency region as well as reduce the background interference. The feature map of the enhanced salient region fargbt is obtained as follows:
fargbt=frbgt⊙((fsrgbt+fse)/2) (17)Finally, the two branch feature maps fargbt and fe−rgbt are concatenated, and be further put through a convolution block, respectively. The final edge-guided feature map Fergbt is formulated as follows:
Fergbt=conv(cat(conv(fargbt),conv(fe-rgbt))) (18)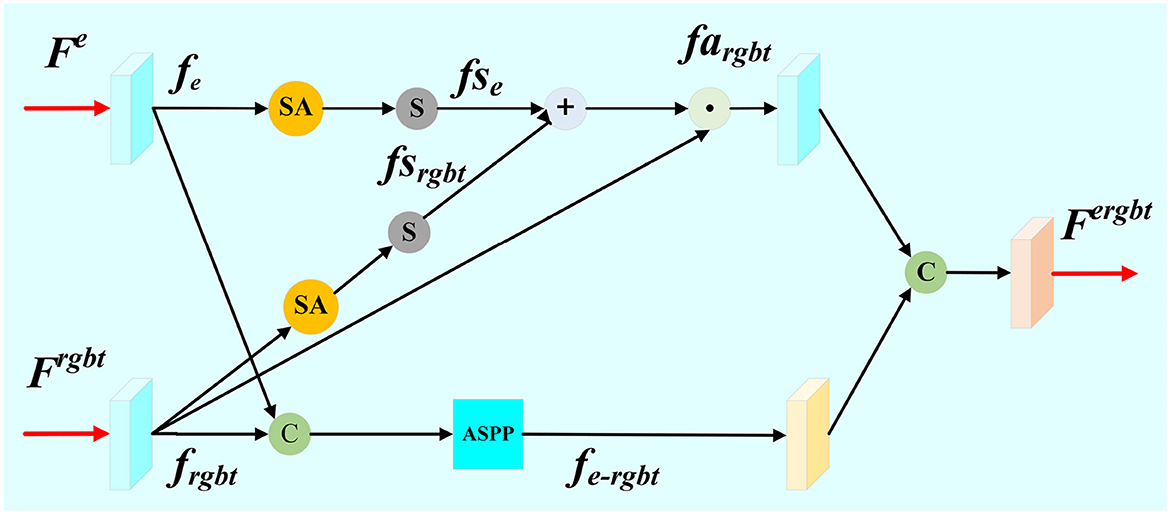
Figure 3. Detail illustration of proposed Edge Embedding module (EED).
3.3 Salience map prediction and hybird loss functionAs shown in Figure 1, the layer-by-layer decoding structure is designed for the prediction of salient maps. We cascade the output Fide (i ∈ ) of each decoding block with the output Fiergbt (i ∈ ) of the edge-guided feature fusion module of the upper layer, and then fed them into the upper decoding block as follows:
F5de=convde(F5ergbt) (19)
留言 (0)