
記住我








Egypt is a transcontinental nation that is part of both the Middle East and North Africa. Its official name is the Arab Republic of Egypt, with a vast territory spanning approximately 1,010,450 km2. Situated between latitude 26°50′8.76″N and longitude 30°47′44.37″E, Egypt is strategically positioned at the crossroads of Africa, Asia, and Europe (CIA World Factbook, 2021).
Geographically, Egypt is bordered by the Red Sea to the east and the Mediterranean Sea to the north, serving as vital maritime links to various international trade routes (World Bank, 2021). Libya forms its western border, while Sudan marks its southern boundary (CIA World Factbook, 2021). This geopolitical location has endowed Egypt with a significant role in regional politics and commerce, making it an important player in the Middle East and North Africa (Kausch 2015).
The climate of Egypt is predominantly arid, characterized by limited rainfall throughout the year. The majority of precipitation occurs along the coastal regions, with the Nile Delta experiencing slightly higher rainfall due to its proximity to the Mediterranean Sea (Roushdi 2022). Summers in Egypt are scorching and arid, spanning from May to September, with temperatures often surpassing 40°C in the inland areas. Winters, on the other hand, are relatively mild and chilly, particularly in the northern parts of the country (Kottek et al. 2006).
Dataset DescriptionPresence DataThe geographical distribution of A. florea was systematically documented over a span of 2 years. Close collaboration was established with local residents all over the study area, who willingly participated and provided valuable inputs. Residents promptly reported the discovery of honeybee nests on their premises via telephone, acting as citizen scientists contributing to the research effort (Bickerman-Martens et al. 2017; Hall et al. 2021).
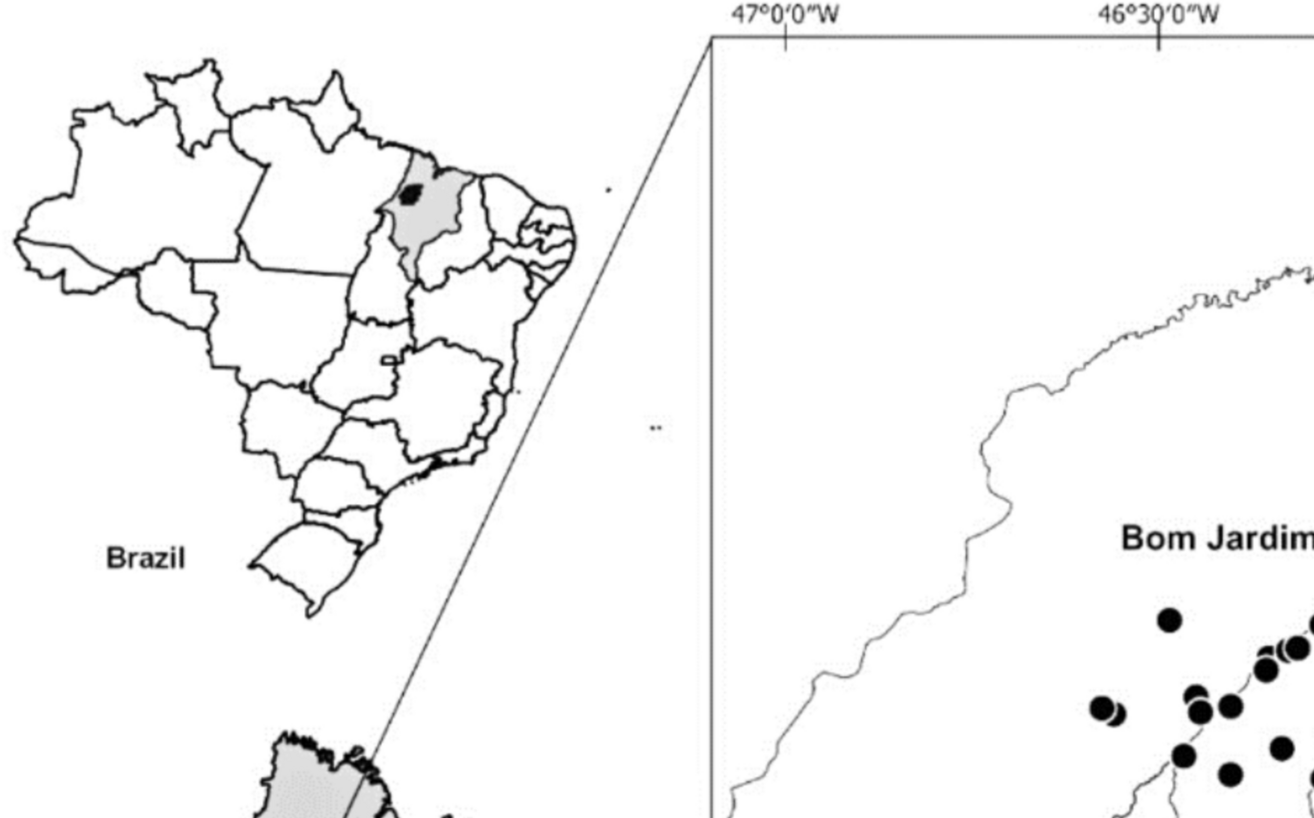
To ensure comprehensive data collection, a designated team member conducted site visits to accurately record the precise coordinates and other relevant information of each honeybee nest. These on-site visits were essential for validating the reported sightings and confirming the presence of A. florea in the specified locations. A total of 33 nests were successfully collected from diverse locations across the study area, representing a significant sample size for further analysis and study. More over 23 data points of A. florea were obtained in the study area from the GBIF platform (https://gbif.org) as illustrated in Fig. 1.
Fig. 1
Study area and reported location of Apis florea in Egypt
Bioclimatic DataThe bioclimatic data (https://www.worldclim.org/data/bioclim.html) presents and elucidates the diverse parameters that were examined and chosen for the mapping exercise. All of the listed parameters (Fig. 2) were derived from the monthly temperature and rainfall data to generate climate surfaces with a spatial resolution of 1 km. The time span covered the years 1950 to 2000 (Hijmans et al. 2005).
Fig. 2

Bioclimatic parameter description and summary information
Vegetation DataThe MODIS Terra Vegetation Continuous Fields (VCF) data product presented at https://lpdaac.usgs.gov/products/mod44bv006/ provides a summary of the vegetation variables utilized in this study. All the parameters correspond to yearly satellite data products derived from Terra MODIS (Moderate Resolution Imaging Spectroradiometer). The dataset spans from 2000 to 2021, encompassing a considerable temporal scope. Moreover, the spatial resolution employed for this analysis is set at 250 m, ensuring an appropriate level of detail for the study area (Fig. 3).
Fig. 3 Topographic Data
Topographic DataElevation data acquired from the Shuttle Radar Topography Mission (SRTM) were utilized to compute slope, aspect, and hillshade, employing a digital elevation model (DEM) with a spatial resolution of 30m (Fig. 4).
Fig. 4
Elevation, slope, aspect, and hillshade from the terrain digital elevation model
Data Processing and AnalysisData ResamplingIn order to achieve uniformity in pixel size, data resampling was conducted to account for the disparate spatial resolutions across the various datasets (Mitas and Mitasova 1999; Mookambiga and Gomathi 2016). All data were aligned with the low-resolution dataset (bioclimatic). Raster resampling encompasses the adjustment of pixel size by means of either enlargement or reduction (Sillero and Barbosa 2021; Eyelade et al. 2022). The three predominant algorithms employed in raster resampling include nearest neighbour, bilinear interpolation, and cubic convolution (Mitas and Mitasova 1999). For this particular study, bilinear interpolation was implemented to augment the pixel size from different resolutions to 1km (Lahiri and Lahiri 2003). This method entails computing the weighted average of the four pixels in the original image that are nearest to the new pixel location. Through this averaging process, the original pixel values are modified, resulting in entirely new digital values in the output image (Usery et al. 2004; Afwani and Danoedoro 2019). Bilinear interpolation is generally recommended for continuous data, albeit it may introduce some degree of data smoothing (Mitas and Mitasova 1999; Lahiri and Lahiri 2003).
Create Pseudo-Absences Spatial Data BlocksSpecies distribution models (SDMs) are essential tools in ecological research, helping us understand species’ habitat preferences and predict their spatial distribution patterns (Mitas and Mitasova 1999). To create SDMs, we need data on species’ presence and the available environmental conditions, also known as pseudo-absence data (Elith et al. 2006). In this study, we utilized a widely used k-means clustering algorithm, which groups similar data points together based on Euclidean distance (Hartigan and Wong 1979). The clustering analysis allowed us to identify areas with similar environmental conditions and presence records, offering valuable insights into species’ ecological niches (Jiménez-Valverde et al. 2008).
For generating pseudo-absences, we randomly created points within dissimilar pixels relative to the presence data. This common approach in SDMs helps simulate absence data and prevents bias in model predictions. Incorporating random pseudo-absences enables the model to capture background environmental conditions more effectively, improving its ability to distinguish suitable habitats from unsuitable ones.
The study contributes to the existing SDM literature, emphasizing the significance of robust presence data and the use of appropriate pseudo-absences to enhance model accuracy. The k-means clustering method and random pseudo-absence generation provide valuable insights into species distribution patterns and ecological niche modeling. Ongoing research to refine these techniques will contribute to a better understanding of species-environment relationships and support conservation efforts.
Feature Importance and Parameter SelectionOne of the key advantages of random forest is its ability to assess the importance of different features in making predictions. Feature importance provides insights into which features have the most influence on the model’s predictions. This can be particularly valuable for feature selection, model interpretation, and understanding the underlying data. Each decision tree in the random forest is split based on criteria that minimize impurity, such as Gini impurity or entropy. When assessing feature importance, random forest measures how much each feature decreases the impurity in the nodes where it is used. For each feature, the algorithm calculates the total reduction in impurity across all nodes where the feature is used for splitting. This reduction is then averaged across all trees in the forest.
Features that frequently result in large reductions in impurity are considered more important. Features with higher importance scores are more influential in predicting the target variable. These features contribute significantly to reducing uncertainty and improving the model’s predictive performance. Features with lower scores have a minimal impact on the model’s predictions. These features might be redundant or less relevant to the outcome. Feature importance was calculated as an average of 10 different runs of the trained models using 10 different seeds [11, 17, 22, 34, 54, 68, 96, 108, 224, 312] for model generalization.
Model Fitting, Validation, and Accuracy AssessmentRandom forest (RF) is a popular nonparametric ensemble predictor used extensively in academic research. It relies on an ensemble of decision trees trained or bootstrapped with a subset of training samples (Breiman 2001; Pal 2005; Gislason et al. 2006). RF’s appeal lies in its ability to handle large, non-parametric categorical data, effectively manage outliers, and resist overfitting issues. The algorithm combines multiple decision trees using binary decisions, growing each tree based on random sampling with replacement from the original training data (Breiman 2001).
In RF, each decision tree contributes a single vote to assign the most frequent class to the input data. The final classification output is determined by majority vote, selecting the class with the highest number of votes out of the total (N votes) (Breiman 2001; Pal 2005; Gislason et al. 2006). Users have the flexibility to define the number of variables (mtry) and trees (ntree) based on specific research requirements (Pal 2005; Gislason et al. 2006). The presence and pseudo-absence data were extracted using Google Earth Engine (GEE) and subsequently downloaded for offline analysis in R software, where the random forest hyperparameter tuning was performed. Specifically, a total of 440 pseudo-absence data points were generated, and the corresponding pixel values for all biophysical and environmental parameters were extracted. This process was similarly conducted for the presence data points.
This section outlines the methodology employed to evaluate the performance of the random forest (RF) model for binary classification, focusing on the impact of varying hyperparameters using 5-fold cross-validation. The analysis was conducted in R, with particular attention given to the handling of class imbalance during data sampling. The random forest algorithm was evaluated across a range of hyperparameter settings:
Number of trees (ntree): evaluated at 50, 100, 200, 500, 1000, and 1500 trees.
Number of features considered at each split (mtry): assessed with values of 3, 5, 7, 9, 10, 15, and 20 features.
For each combination of ntree and mtry, a random forest model was trained on the training folds and validated on the corresponding validation fold. The dataset used for this study was imbalanced for binary classification tasks. To address potential class imbalance, the following sampling strategies were applied:
Negative class: instances were randomly selected without replacement to ensure diversity and representativeness in the training data.
Positive class: instances were sampled with replacement to maintain a sufficient number of examples and counteract any imbalance issues.
A 5-fold cross-validation approach was employed to assess the performance of the random forest model. The dataset was divided into 5 equal-sized folds. Each fold was used once as the validation set, while the remaining 4 folds were utilized for training. This process was repeated five times, ensuring that every data point was used for both training and validation exactly once. This cross-validation was repeated in a for loop for 10 times to make sure all the absence data were all used against the absence data. The top preforming set of parameters (ntree and mtry) were used in GEE for the RF model implementation. The out-of-bag error and validation accuracy were used as a model performance selection.
Accurate assessment of classification results is crucial for evaluating the reliability of image classification algorithms. Metrics such as user’s accuracy, producer’s accuracy, overall accuracy, and the Kappa coefficient are commonly used to quantitatively evaluate classification accuracy in tools like GEE (Lambin and Strahlers 1994; Congalton 1991). The overall accuracy, user’s accuracy, and producer’s accuracy can be calculated using the following equation:
$$\text= \frac}}\times 100$$
While the producer’s accuracy is a measure of the accuracy of the produced map as evaluated by the mapmaker (Mawasha and Britz 2022) and can be calculated using the following equation:
$$\text= \frac}(\text.\text.,\text)} \times 100$$
The user’s accuracy refers to the perspective of the map user (Mawasha and Britz 2022) and can be calculated using the following equation:
$$\text= \frac}(\text.\text.,\text)} \times 100$$
Kappa values are classified into three possible ranges: a value greater than 80% is a strong agreement, a value between 40 and 80% is moderate agreement, and when a value less than 40% is poor agreement (Mawasha and Britz 2022). The Kappa index can be calculated using the following equation:
$$K= \frac_^Xii-_^(_* _)}^-_^(_* _)}$$
where \(r\) is the number of rows, \(_\) is the number of observations in row \(i\) and column \(i\), \(_\) and \(_\) are the marginal totals of row and column, and \(N\) is the total number of observed pixels.
留言 (0)