2.1 Overview
In our study we were using a fine-tuned T5 Base as a reference model which shows good performance in PV-related NER tasks [31, 32]. Our assumption was that all larger model sizes compared to T5 Base would typically result in better performance, but it would also require more computing resources to train and run. In our experiments we strove to find the best balance between efforts and performance depending on the results of our experiments.
LLMs are trained with large amounts of text data to determine the most likely continuation of an input text. The model proposes a list of the most probable subsequent words, and a text generation algorithm is employed to select them. Algorithms that do not consistently select the most likely word can enhance the overall probability of the complete output and generate more variable and natural text. Temperature is a common parameter, which regulates the probability of selecting the most likely next word. Its value typically starts at 0 and progress to higher values, which introduce greater randomness or creativity. In our study, the temperature parameter for all models was set to 0 to reduce the degree of randomness in response generation.
The term zero-shot refers to a prompting technique wherein the model is presented with a task without any additional examples, whereas in the case of a few-shot prompt, the prompt comprises multiple examples of the task and the anticipated outcome [33,34,35].
Experiments were executed between October 2023 and February 2024. We started with prompt engineeringFootnote 2 of GPT 3.5 Turbo [33] (gpt-3.5-turbo-1106) and GPT 4 Turbo [36] (gpt-4-1106-preview) models [37]. Although GPT 3.5 and GPT 4 experiments were originally executed using Microsoft Azure, we repeated our experiments with Open AIs public API (version 1.6.1) to allow reproducibility for the research community. Results obtained by the OpenAI API Python SDK for text generation did not principally deviate from those executed in Azure.
Both GPT models return a maximum of 4096 output tokensFootnote 3, while the context window of GPT 3.5 Turbo with 16,385 tokens is lower when compared with GPT 4 Turbo context window of 128,000 tokens. We performed qualitative prompt experiments independent of entity performance. We focused on modifying the system and user prompt to achieve adequate prompt interpretability by OpenAI models in terms of result format and complete and correct interpretation of all prompt information.
There are various sizes available for pre-trained T5 models [26] based on a Colossal Clean Crawled Corpus (C4), including small (60 million parameters), base (220 million parameters), large (770 million parameters), 3B (3 billion parameters), and 11B (11 billion parameters).
For evaluating the model performance (see section 2.5.1), we used several LLMs published on the HuggingFace hub, such as argilla/notus-7b-v1, epfl-llm/meditron-7b, HuggingFaceH4/zephyr-7b-beta, meta-llama/Llama-2-13b-hf, and togethercomputer/Llama-2-7B-32K-Instruct [38,39,40,41,42].
Table 1 summarizes methods and expected objectives of our study.
Table 1 Overview about the experiments executed and their related objective2.2 Dataset
The annotated dataset used for all experiments consists of four sources: Bayer Literature Database (PubMed), ADECorpus (PubMed) [28], Social Media Mining for Health Applications (SMM4H, Twitter) [43], and drugs.com[44] and 890 records and is publicly available as supplementary material in [32]. Each record consists of one or several sentences. The dataset was consistently annotated with controlled quality, contains diverse data sources, and the entities are relevant for PV. The dataset is small, diverse, and very clean and allows to train ML models with limited resources. The detailed entity description, data selection, and the annotation process are described in [32].
2.3 Prompting
We performed manual prompt optimization for OpenAI models to obtain the best results based on a few samples of input texts and describe our approach below. Many additional methods exist, and a growing body of literature is discussing additional methods like adding personas or chain-of-thought prompting [45]. We decided to stop spending additional effort in prompt engineering once we reached satisficing results.
We used OpenAI’s prompt engineering guide [46] to achieve better results in terms of adequate prompt interpretability of the text provided. We applied some strategies which are adequate for the given tasks:
Ask the model to adopt a persona
Use delimiters to clearly indicate distinct parts of the input
Instruct the model to answer using a reference text
In contrast to Hu et al. [29], who provided annotation guideline-based prompts and annotated samples via few-shot learning, we intentionally started with zero shot experiments and without any further explanation what is meant by a given entity description (e.g., indication or adverse event) to investigate the native LLM entity extraction capability.
We realized that the task definition in our prompt should be as exact as possible (e.g., three directly consecutive hashtags instead of three consecutive hashtags) and preferably with an example (e.g., for product event combination: “Aspirin|Rash”).
For all our experiments, the following prompt example was used with the variable part embedded by three hashtags as start and end tag (except for fine-tuned T5 which did not require any prompting). We used all entity labels which are described in [32]:
System prompt (only OpenAI models, system prompt refers to the set of instructions that guide the output): “I want you to act as an experienced and diligent annotator in a Pharmacovigilance department. Follow the user's instructions carefully. Respond using plain text.”
User prompt (with an input text example used for all reproducibility experiments, the user prompt is the specific input or question you want the AI to respond to):
“Use the following items and identify all items in the text marked by three directly consecutive hashtags (e.g., ###text to be analyzed###) put in front and at the end of the text:
01. Adverse event
02. Mode of action
03. Administration form / Primary packaging
04. Administration route
05. Comorbidity
06. Dosage
07. Drug / Device
08. Indication
09. Intended effect
10. Medical history / condition
11. Method / Procedure / Administration
12. Outcome
13. Product Dose Combination (PDC)
14. Product Event Combination (PEC)
15. Product Indication Combination (PIC)
16. Product Technical Complaint (PTC)
17. Target parameter
18. Target population
Present the results in the following form:
- Per item use a new line with the format: 'item: hit(s)'
- List multiple hits separated by semi-colon
- When you do not find an entry fill the field with 'None'
- When you find a product combination (PEC, PIC, PDC) separate Drug / Device from the other Adverse Event, Indication, or Dose term by a pipe character (e.g., 'Aspirin|Rash')
- List all items with preceding numbers
- Stop generating after the list is complete
Input text:
“###After TACE for intrahepatic metastasis, localized CCRT (45 Gy over 5 weeks with conventional fractionation and hepatic artery infusional chemotherapy using 5-fluorouracil as a radiosensitizer, administered during the first and fifth weeks of radiotherapy) was used to treat main HCC with PVT.###”
2.4 Reproducibility Experiments
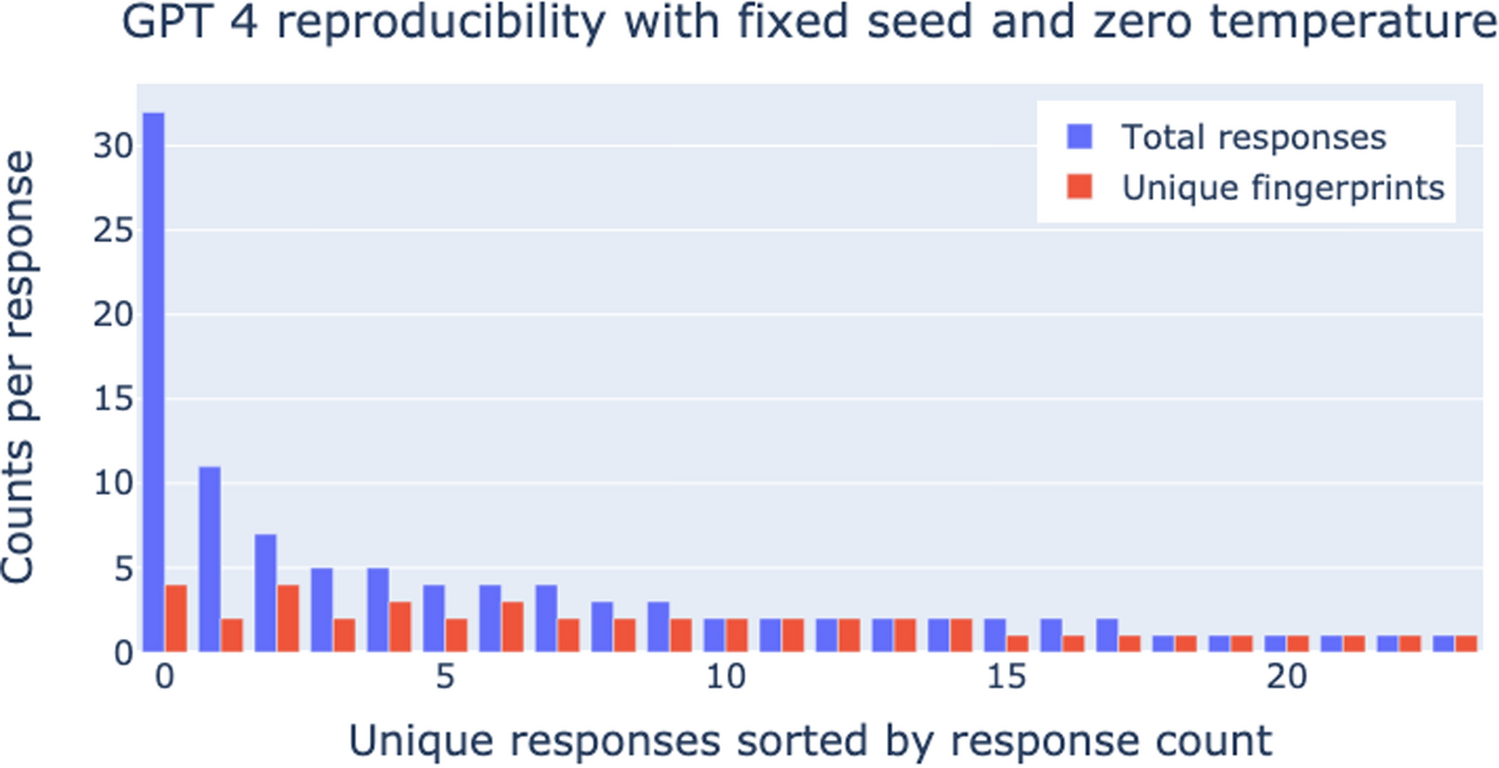
Reproducibility is of paramount importance for production use of AI models in a regulated environment. This was also acknowledged by the OpenAI developers. In November 2023, two new OpenAI model versions were released addressing this need (gpt-4-1106-preview, gpt-35-turbo-1106). Both models were used for our reproducibility experiments.
In the OpenAI Cookbook [47] the following explanation is provided:
“Reproducibility has always been a big request from user communities when using our APIs … Developers can now specify seed parameter in the Chat Completion request to receive (mostly) consistent outputs. To help you keep track of these changes, we expose the system_fingerprint field… The system fingerprint is an identifier for the current combination of model weights, infrastructure, and other configuration options used by OpenAI servers to generate the completion.”
The reproducibility of model results (used models: gpt-4-1106-preview, gpt-35-turbo-1106, HuggingFaceH4/zephyr-7b-beta) was evaluated by providing a single record multiple times as the same request (n = 100) and analyzing the number of different model responses. The prompting described in section 2.3 was used.
For reproducibility assessment, the number of different responses was counted. In all experiments and all models, the temperature was set to zero and the seed number was omitted or set to 42 to analyze result differences.
2.5 Model Performance
Our motivation for this experiment was to compare the performance of externally hosted OpenAI models versus internally hosted LLMs. In our experiments, we were focusing on partial scores on the positive class (F1 and recall) to evaluate overlapping hits between prediction and truth [32]. We started by running zero-shot performance studies with a range of transformer models to select the best model for further development steps like few-shot prompting or fine-tuning and compared the results of the selected model against two OpenAI models (gpt-4-1106-preview, gpt-35-turbo-1106) as well as a fine-tuned T5.
We assumed that GPT 4 would outperform GPT 3.5, but we also wanted to investigate if the potentially better performance justifies the higher costs and longer execution time per request.
2.5.1 Model Selection
Transformer models were selected, which could be potentially run and fine-tuned with reasonable technical efforts and costs. Therefore, we focused on recent 7B and 13B parameter models which were at the time of selecting LLMs for our study (November / December 2023) ranking high on Hugging Face leader boards [48]: argilla/notus-7b-v1, epfl-llm/meditron-7b, HuggingFaceH4/zephyr-7b-beta, meta-llama/Llama-2-13b-hf, and togethercomputer/Llama-2-7B-32K-Instruct.
Any selection of models will be an extreme reduction compared to the models published on the Hugging Face hub, which hosts, as of June 2024, over 100k models for the Text Generation task. It's common for models to be published in different versions, like meta-llama/Llama-2-13b-hf or meta-llama/Llama-2-13b-chat-hf. When multiple versions of a candidate model were available, we focused on the instruct models in favor of chat models. This was because instruct models tend to perform better in use cases that require adherence to structured output to make use of the generated text. Chat models tend to excuse themselves and are wordy in their outputs, which makes them suitable for use in chat applications but less favorable for data processing tasks.
We compared the model performance against a T5 model fine-tuned on splits of the published dataset [32]. The performance evaluation was executed to identify the candidate model for further processing (few-shot and fine-tuning experiments). We focused a) on the named entities indication, adverse event, drug/device, dose, product event combination, product indication combination, and product dose combination due to business relevance and since the dataset provides the highest number of occurrences for those entities and b) on one data source (ADE Corpus), because the majority of dataset records originated from this source (n = 500 of 890 records). All model selection experiments were performed as zero-shot and executed only once (n = 1).
2.5.2 Guided Generation
Initial experiments indicated that the prompt for GPT 3.5 and GPT 4 was not generating useful results with the selected 7B or 13B LLMs. The major issue was that open-source models did not adhere to the desired output format and output termination.
Performance of LLMs is highly sensitive to how they are prompted, and a growing body of literature is addressing various techniques to optimize results [45, 46]. One important issue of open-source models is adherence to the expected output format, which is unlikely to be fixed by prompt optimization alone.
One possible option to address the issue with the output format is to use optimized single prompts per entity, but with the disadvantage of additional work and complexity.
We used guided generation (version 0.1.10, 22 December 2023), which offers a guaranteed and stable solution for this issue without the need for additional prompting efforts to compare multiple open-source LLMs with the same user prompt developed for GPT. There are several approaches of controlling the output of LLMs, e.g., [49, 50]. In our paper we evaluated two approaches of guidance-ai for guided generation [50]:
Constrained generation to input words: Enforcing output structure, hard constraints on text generation to words occurring in the input text and in addition, generation termination after newlines. This approach is based on the idea that the output of a NER task can be limited to the input text since generated words which do not occur in the input text are by definition non-valid responses. This constraint works well for NER tasks but breaks down quickly when more free form answers are needed (as required e.g., for relation extraction).
Guided generation: Enforcing output structure and unconstrained generation within free text blocks, with termination of generation after newlines. This approach entirely focuses on adherence to a consistent output structure, which greatly simplifies downstream processing of model inference results and separates the model ability to adhere to a described output format and generating meaningful answers.
Due to the use of product combinations and the use of pipe characters in the expected results, we focused on guided generation for the following analysis. Our experiments with these two approaches showed that imposing known constraints on LLM inference greatly simplifies further usage and processing of LLM results and can bridge the gap between model performance of vastly different parameter sizes.
2.6 T5 and Zephyr Fine-Tuning
T5 was fine-tuned as described in [32] by using the published dataset, executing stratified five-fold cross validation with 80:20 splits. Stratification was performed based on data source and entity type. HuggingFaceH4/zephyr-7b-beta was selected for fine-tuning as we saw the most consistent and promising results from this model. The same dataset as for the T5 models was used for training and testing to create 5-fold cross validation Zephyr models. The quantized low rank adapter (QLoRA) method [51] was used to quantize a pre-trained model to 4-bit and adds a small set of learnable (QLoRA) weights which are tuned by back propagating gradients through the quantized weights. QLoRA reduces the average GPU memory requirements significantly by using novel high-precision techniques such as 4-bit NormalFloat, double quantization, and paged optimizers without significant performance degradation [51]. We used the X-LLM library for streamlining model training optimization and LLM finetuning [52].
For the fine-tuning of HuggingFaceH4/zephyr-7b-beta, we used an Adam optimizer (paged_adamw_8bit) and set the maximum quantization samples to 1024. The learning rate was set to 0.0002, batch size was set to 1, and the epoch was set to 1. The T5 fine-tuning parameter are described in [32].
2.6.1 Few-Shot Experiments
As a first step towards optimizing model performance, we performed few-shot experiments which were based on the same conditions as for the zero-shot experiments. In total, eight samples (about 1% of dataset) were selected (two samples per data source) which represented per data source the highest number of entities per record. We ensured that “None” was present in our few-shot experiments to teach the models that “None” is a valid option. We executed the experiments with the original HuggingFaceH4/zephyr-7b-beta model and our fine-tuned Zephyr models. For the evaluation we focused on the source ADE Corpus (which contains the most records, n = 500).

留言 (0)