
記住我



This retrospective study included 389 NPC patients who received NACT between January 2017 and January 2023. The MRI used to construct the predictive models were all obtained prior to the performance of the NACT treatment. The patients were from three institutions: the Affiliated Hospital of Southwest Medical University (n = 311), Qingyang People’s Hospital (n = 36), and Xinzhou People’s Hospital (n = 42). The inclusion criteria were as follows: ①: histopathologically confirmed NPC patients; ②: treatment-naïve patients; ③: patients who underwent MRI after two independent cycles of NACT; ④: patients with complete MRI, pathological images, clinical baseline data, and treatment response records. The exclusion criteria were: ①: patients with any missing MRI, pathological images, clinical baseline data, or treatment response records; ②: patients with poor quality images due to motion or metal artifacts.
In this study, the patients included primarily received neoadjuvant chemotherapy (NACT) using either the docetaxel, cisplatin, and 5-fluorouracil (DCF) regimens or the gemcitabine and cisplatin (GP) regimens. These chemotherapy protocols are widely used in the treatment of nasopharyngeal carcinoma (NPC) to maximize tumor shrinkage prior to definitive therapy. All NACT regimens included two cycles, each lasting 21 days. Nasopharyngeal and neck MRI scans were performed three months after the completion of NACT. The response to NACT was evaluated by three oncologists with more than 10 years of experience, according to the RECIST 1.1 criteria [13]. Complete response (CR) and partial response (PR) were classified as NACT effective, while stable disease (SD) and progressive disease (PD) were classified as NACT ineffective.
In this study, the cohort from the Affiliated Hospital of Southwest Medical University (n = 311) served as the training set for feature selection, model construction, and training. The cohorts from Qingyang People’s Hospital (n = 36) and Xinzhou People’s Hospital (n = 42) were combined into a single dataset and used as an external validation set to evaluate model performance. This study was approved by the Ethics Committee of the Affiliated Hospital of Southwest Medical University, Qingyang People’s Hospital and Xinzhou People’s Hospital (KY2023041; LC-202427; XZRY-2024030) and in accordance with the Declaration of Helsinki. Informed consent was obtained from all the patients. The study was conducted in accordance with the Declaration of Helsinki (2013 revision).
Magnetic resonance scanning parametersThe contrast-enhanced MRI scans from the Affiliated Hospital of Southwest Medical University were obtained using an Achieva 1.5T MR scanner (Philips, Netherlands). The scanning sequences and parameters were as follows: T2 weighted imaging (T2WI) sequence (TR/TE = 2975 ms/90 ms), T1WI sequence (TR/TE = 429 ms/18 ms), T1-weighted high-resolution isotropic volume examination (Thrive) sequence (TR/TE = 2500 ms/3.2 ms), with a field of view (FOV) of 240 mm × 240 mm, axial slice thickness of 1 mm, and sagittal and coronal slice thickness of 2 mm.
The contrast-enhanced MRI scans from Qingyang People’s Hospital were obtained using a GE Discovery 750 W 3.0T MRI system with a head and neck combined coil. The scanning sequences and parameters were as follows: T1WI sequence (TR/TE = 836 ms/10.4 ms), T2WI sequence (TR/TE = 6198 ms/85 ms), Thrive sequence (TR/TE = 3.9 ms/1.9 ms), with an axial slice thickness of 1 mm, sagittal and coronal slice thickness of 2 mm, and a FOV of 230 mm × 230 mm.
The contrast-enhanced MRI scans from Xinzhou People’s Hospital were obtained using a GE Discovery MR750 3.0T scanner. The scanning sequences and parameters were as follows: T1WI sequence (TR/TE = 1750 ms/24 ms), T2WI sequence (TR/TE = 8500 ms/155 ms), Thrive sequence (TR/TE = 4183 ms/102 ms), with a FOV of 240 mm × 240 mm, axial slice thickness of 1 mm, and sagittal and coronal slice thickness of 2 mm.
Data screening and feature extractionThe detailed process of this study for image data screening is shown in Fig. 2, The definition of ROI areas and the criteria for selection of pathology images are shown in Supplementary File 5.
Fig. 2
Flowchart for data screening of MRI images and pathology images
Radiomics feature extractionAll MRI images were sourced from DICOM format medical image archiving and communication systems and transferred to the 3D Slicer software (version 4.21). Two oncologists with more than 5 years of clinical experience manually segmented the regions of interest (ROIs) on each MRI sequence using the 3D Slicer software. In the case of disagreement, a third oncologist with over 10 years of experience made the final decision. Voxel size normalization was performed by resampling the voxels to 1 mm × 1 mm × 1 mm. Finally, radiomics features, including shape features, first-order statistics, and high-order texture features, were extracted from each ROI using the Pyradiomics package [14].
Pathomics feature extractionPathologists collected biopsy samples from all NPC patients before diagnosing NPC. First, the biopsy tissue was soaked in 10% formalin solution for 4 h and then embedded in immunohistochemistry paraffin blocks. The biopsy tissue was then cut at 4-micron intervals and stained with hematoxylin-eosin (H&E) for pathological assessment. A pathologist with 10 years of diagnostic experience scanned all H&E-stained pathology slides at 10x magnification using a digital slide scanner (KFBio KF-PRO-020). A pathologist with more than 5 years of experience selected sample areas containing tumor cells and obtained five non-overlapping typical area screenshots, each with a FOV of 1024 × 1024 pixels. Another pathologist with more than 5 years of experience confirmed the selection. In the case of disagreement, a third pathologist with over 10 years of experience made the final decision. All screenshots were cropped into small patches (512 × 512 pixels) for subsequent analysis through non-overlapping sampling. We used CellProfiler software (version 4.0.7) to extract quantitative pathomics features from the selected patches. The “Unmix Colors” module was used to separate and convert the H&E-stained images into grayscale images of H&E stains. The “ColorToGray” module was also used to convert H&E-stained images into grayscale images. The feature extraction process consisted of three steps. First, general primary pathomics features were extracted from the original grayscale images. Then, the primary and secondary objects were identified and extracted from the separated H&E stained images. Finally, the features extracted from the five patches of each sample’s whole slide image (WSI) were averaged for subsequent analysis [15].
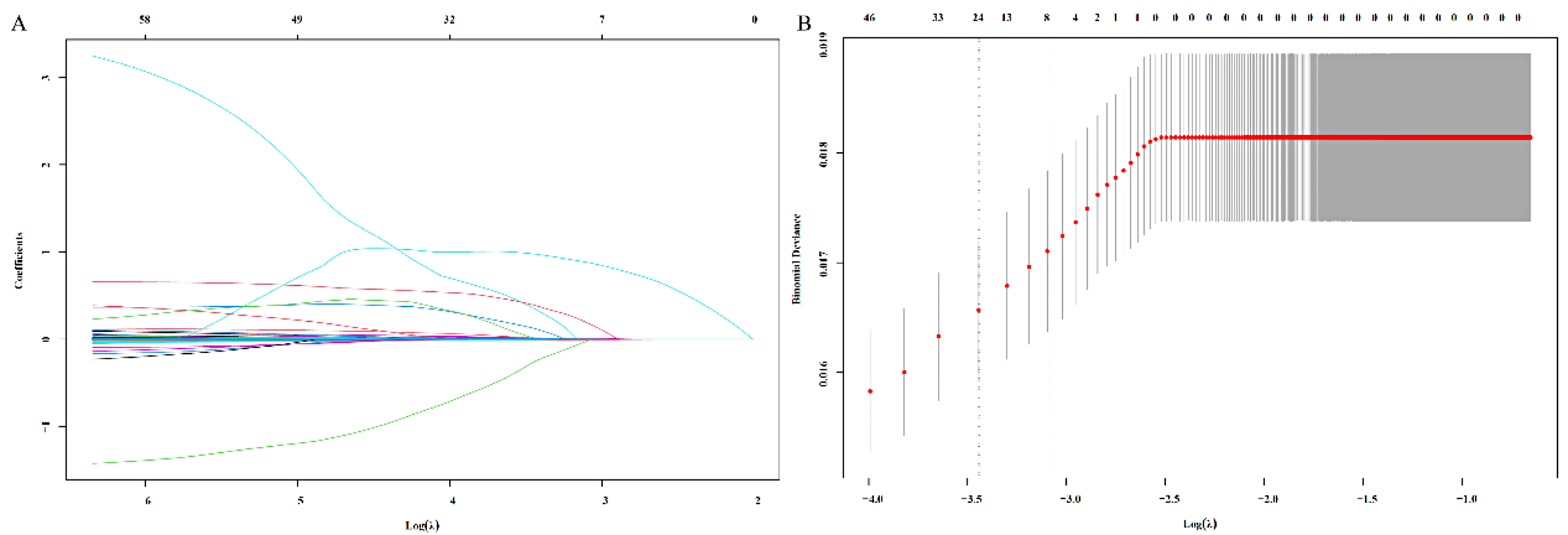
Feature screeningAfter feature extraction, all radiomics and pathomics feature values were normalized to a range between 0 and 1 using the min-max normalization method, to account for differences in scanning protocols across multiple centers. First, the reproducibility of the features was evaluated using the intra-class correlation coefficient (ICC), and only features with good reproducibility (ICCs > 0.75) were retained [16]. Next, the Mann-Whitney U test was used to identify outcome-related features for each sequence, and only factors with a significance level of P < 0.05 were included for further screening [17]. For highly reproducible features, Spearman’s rank correlation coefficient was used to calculate the correlation between features. Among any two features with a correlation coefficient greater than 0.9, one feature was retained [18]. To maximize the descriptive ability of the features, a greedy recursive elimination strategy was employed for feature filtering. Finally, a least absolute shrinkage and selection operator (LASSO) regression model was used to construct the radiomics features. The LASSO method shrinks all regression coefficients to zero and precisely sets the coefficients of many irrelevant features to zero based on the tuning weight λ [19]. To determine the optimal λ, lamda.min and 7-fold cross-validation were used, where the final value of λ produced the smallest cross-validation error. Features with non-zero coefficients retained through this process were considered important and included in the subsequent predictive model construction.
Construction of the predictive modelIn this study, a PSO-SVM was employed for predictive model construction. Radiomics and pathomics data typically have high dimensionality and complex inter-feature correlations. PSO-SVM can automatically adjust parameters, reducing manual intervention and enhancing the model’s automation. This is particularly important for handling complex, high-dimensional data, effectively reducing the complexity and error rate of manual parameter tuning [20]. First, PSO simulates the social behavior of particle swarms, utilizing information sharing among individuals to find the optimal solution [21]. During initialization, a swarm of particles is randomly generated, with each particle representing a parameter combination of SVM (penalty parameter, \(\:C\), and kernel parameter, γ). The fitness function \(\:f\left(_\right)\) is used to evaluate the performance of the particles, typically calculated using cross-validation accuracy, represented as:
$$\:f\left(_\right)=CrossValidationAccuracy(_,_)$$
Subsequently, particle velocity and position are updated based on inertia weight, acceleration constants, and random numbers:
$$\:_\left(t+1\right)=\omega\:_\left(t\right)+__\left(_-_\left(t\right)\right)+__(g-_\left(t\right))$$
$$\:_\left(t+1\right)=_\left(t\right)+_(t+1)$$
Where \(\:\omega\:\) is the inertia weight, \(\:_\) and \(\:_\) are acceleration constants, \(\:_\) and \(\:\:_\) are random numbers between [0,1], \(\:_\) is the personal best position of particle \(\:i\) and \(\:g\) is the global best position. Each particle’s current fitness is compared to its historical best fitness to update the personal best position \(\:_\). The global best position \(\:g\) is updated by comparing all particles’ fitness to the global best fitness. The algorithm terminates when the maximum number of iterations is reached or the fitness function meets a preset threshold.
For SVM, the optimal hyperplane \(f\left( x \right) = w \cdot x + b\) is defined to separate different classes of samples with maximum margin. The objective is to minimize the function:
Where \(\:}_\) is the slack variable and \(\:C\) is the penalty parameter. The constraints are:
$$\left( + b} \right) \ge \>1 - $$
and:
To handle non-linear separable data, a kernel function is used to map data from a low-dimensional space to a high-dimensional space:
$$\:K\left(_,_\right)=\text\text\text(-\gamma\:|\left|_-_\right|^)$$
In the integration of PSO and SVM, the particle swarm is first initialized, with each particle representing an SVM parameter combination. Each particle’s fitness is evaluated through cross-validation, with classification accuracy serving as the fitness value. The particle’s velocity and position are adjusted according to PSO’s update rules to find the optimal parameter combination. Finally, the optimal parameters are used to train the final SVM model on the entire training set.
In this study, PSO-SVM models and cross-validation methods were used to train radiomics models, pathomics models, and radiopathomics models separately. The models trained on the training set were applied to the external validation set to ultimately verify the performance of the PSO-SVM model proposed in this study and the performance of models based on different ‘omics’ data. The area under the curve (AUC) of the receiver operating characteristic (ROC) curve was used to evaluate the predictive performance of the models, and calibration curves were used to compare the predicted probabilities of events with the actual event frequencies, thereby assessing the model’s calibration. Additionally, decision curves were used to evaluate the clinical net benefit of all models.
Model interpretationThe radiopathomics model was interpreted using the SHAP (SHapley Additive exPlanations) algorithm to understand the prediction process and the contribution of individual features to the risk of radiation-induced dermatitis. First, the global mean absolute SHAP values were calculated to assess the overall importance of the features in the model. Subsequently, the impact of each variable’s SHAP values on the model output was evaluated. Finally, the SHAP values were used to calculate the influence of each important feature on the prediction model output for each individual sample.
留言 (0)