
記住我

The data set utilized in this study was sourced from the DATADRYAD platform, a digital repository that allows researchers to access and download a wealth of raw data freely. This study utilized the DATADRYAD platform to access the data set originally uploaded by Chen et al. [16], which contains data on 211,833 Chinese individuals. In compliance with Dryad’s terms of service, this study performed a secondary analysis on this publicly available data set.
Study populationThe initial research received approval from the Rich Healthcare Group Review Board, so no additional ethical approval was necessary for this secondary analysis. The initial investigation and this study were conducted per the principles set forth in the Declaration of Helsinki, and all protocols complied with applicable guidelines and regulations.
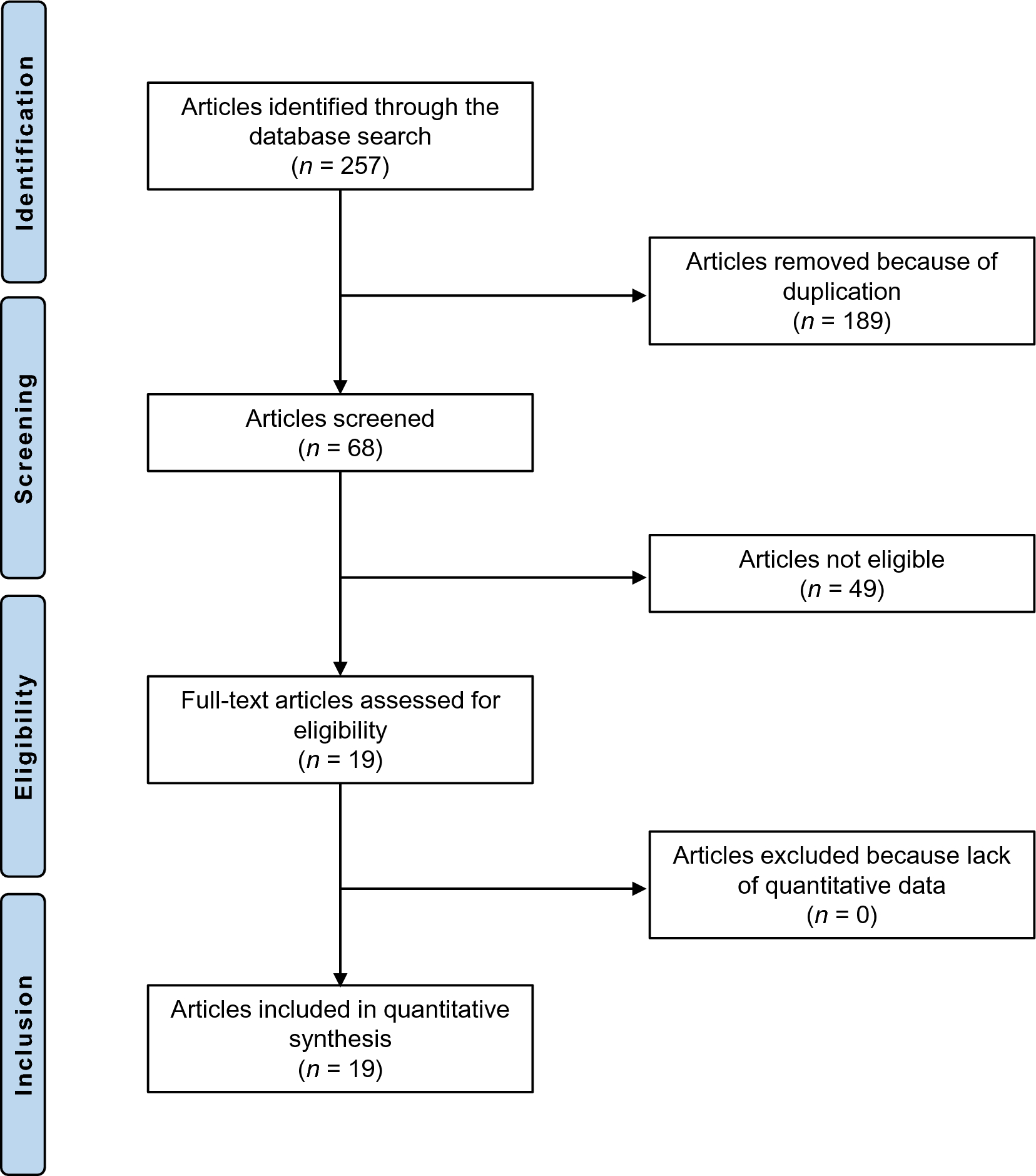
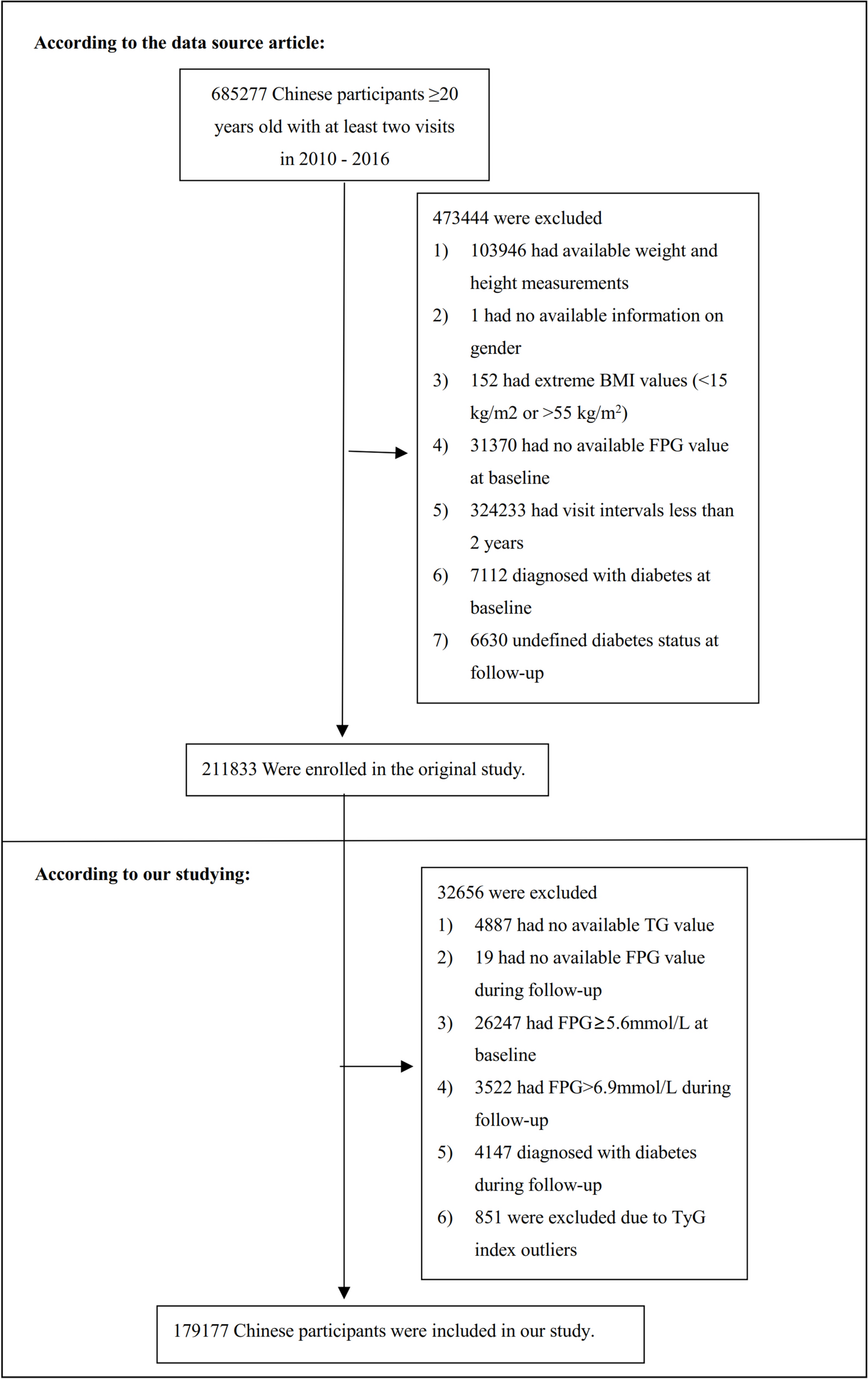
The initial investigation enrolled 685,277 Chinese individuals who were older than 20 years and had undergone at least two medical assessments. This encompassed 32 locations and 11 urban areas within China. The exclusion criteria consisted of the following: (1) having been diagnosed with diabetes at the beginning of the study and during subsequent check-ups; (2) an undefined diabetes status during follow-up; (3) extreme (BMI) values (< 15 kg/m2 or > 55 kg/m2); (4) incomplete data regarding weight, height, gender, triglyceride (TG), or fasting plasma glucose (FPG) at the start of the study, or FPG during follow-up; (5) having an FPG level surpassing 5.6 mmol/L at the beginning and exceeding 6.9 mmol/L during follow-up; and (6) having a follow-up duration of less than two years. Ultimately, the study encompassed 179,177 participants. The research’s design and procedures are delineated in Fig. 1.
Fig. 1 Data collection
Data collectionData collection was conducted in a standardized setting by well-trained staff to ensure consistency across all measurements. The team gathered demographic data, including age, systolic and diastolic blood pressure (SBP and DBP), height, and weight. Height and weight measurements were taken with participants in light clothing and without shoes, and BMI was calculated using the formula kg/m2. Blood pressure readings were obtained using a standard mercury sphygmomanometer. Furthermore, clinical parameters such as low-density lipoprotein cholesterol (LDL-C), alanine aminotransferase (ALT), FPG, TG, serum creatinine (Scr), total cholesterol (TC), aspartate aminotransferase (AST), blood urea nitrogen (BUN), and high-density lipoprotein cholesterol (HDL-C) were measured using a Beckman 5800 autoanalyzer.
TyG indexThe TyG index was determined by applying the formula: Ln[FPG (mg/dL)) × (TG (mg/dL)/2) [13].
DefinitionPre-DM was delineated as the presence of impaired FPG levels, specifically within the range of 5.6–6.9 mmol/L [17].
Statistical analysisStatistical analyses within this study were meticulously performed utilizing R software in conjunction with Empower Stats. This study stratified the TyG index into quartiles for analysis. For normally distributed continuous variables, this study reported means and standard deviations, whereas medians and interquartile ranges were presented for those with skewed distributions. Categorical variables were summarized using percentages. This study compared continuous variables with either one-way ANOVA or the Kruskal–Wallis. Categorical variables were assessed using the chi-square test. Survival and cumulative event rates were evaluated using the Kaplan–Meier method, with differences among groups tested by the log-rank test. In addition, this study calculated hazard ratios (HR) for adverse events using Kaplan–Meier estimates.
Owing to the substantial proportion of missing data for AST, smoking status, and drinking status, this study initially categorized the AST variables into tertiles. Subsequently, the missing values for smoking status, drinking status, and AST were classified into a distinct category designated as the ‘Not recorded group’. This study had some missing data, including HDL-C, SBP, TC, BUN, ALT, DBP, Scr, and LDL-C. The prevalence of missing data for each parameter is enumerated as follows: SBP and DBP both exhibited omissions in 0.009% of cases (16 and 17 individuals, respectively), TC in 0.001% (1 individual), HDL-C in 43.935% (78,704 individuals), LDL-C in 43.583% (78,113 individuals), ALT in 0.787% (1,410 individuals), BUN in 8.931% (16,005 individuals), and Scr in 4.572% (8193 individuals). This investigation employed the technique of multiple imputations to address the issue of missing data [18], thereby mitigating the potential variability introduced by absent variables. The imputation model adopted for this purpose was characterized by a linear regression framework executed over ten iterations. The variables incorporated into the model encompassed a comprehensive set of demographic and clinical parameters: sex, family history of diabetes, age, HDL-C, SBP, drinking status, TC, BUN, ALT, DBP, Scr, smoking status, AST, and LDL-C. The analytical approach to handling missing data was predicated on the Missing-at-Random (MAR) assumptions [19], a methodology that assumes the missingness of data is related to the observed data but not the missing data itself.
This study explored the relationship between the TyG index and the likelihood of developing Pre-DM by employing both univariate and multivariate Cox proportional-hazards regression analyses following a collinearity assessment. The analysis framework comprised three distinct models: Model 1, which was unadjusted; Model 2, which was controlled for family history of diabetes, BMI, age, drinking status, DBP, sex, smoking status, and SBP; and Model 3, which was controlled for HDL-C, BUN, ALT, Scr, LDL-C, and AST, alongside the variables adjusted in Model 2. Throughout the study, this study meticulously documented HR and 95% confidence intervals (CI). In addition, the collinearity assessment excluded TC from the final multivariate Cox proportional hazards regression equation due to its collinearity with other assessed factors, as detailed in Supplementary Table S1.
Notably, higher rates of Pre-DM were observed among older adults and individuals with obesity. To delve deeper into the association between the TyG index and the risk of prediabetes, this study conducted sensitivity analyses, excluding participants aged 65 years or older or those with a BMI of 25 kg/m2 or higher. A generalized additive model (GAM) was employed to validate the findings, allowing for the inclusion of continuous variables as curves within the model. Furthermore, this study computed E values to investigate the potential for unmeasured confounding factors that might influence the observed link between the TyG index and prediabetes risk [20].
To investigate the potential non-linear association between the TyG index and the risk of Pre-DM, the analysis employed Cox proportional hazards regression, incorporating cubic spline functions and smooth curve fitting. In instances where non-linearity was detected, the inflection point was determined by recursive algorithms. Subsequently, this study applied a two-piecewise Cox proportional hazards regression approach to ascertain the threshold effect of the TyG index on Pre-DM incidence, guided by the insights from the smoothed curve analysis.
To further dissect the data, this study applied the Cox proportional hazard model to various subgroups, including family history of diabetes, DBP, age, smoking status, BMI, SBP, drinking status, and sex. This study categorized these subgroups based on clinically relevant thresholds: DBP (< 90, ≥ 90 mmHg), BMI (< 25, ≥ 25 kg/m2), age (< 65, ≥ 65 years), and SBP (< 140, ≥ 140 mmHg). Each stratification underwent a comprehensive analysis with full adjustments. To assess the interactions among subgroups, this study utilized the likelihood ratio test. The documentation and presentation of all findings within this study were meticulously aligned with the guidelines delineated in the STROBE statement [21]. Values of P ≤ 0.05 were deemed to indicate statistical significance.
留言 (0)