
記住我
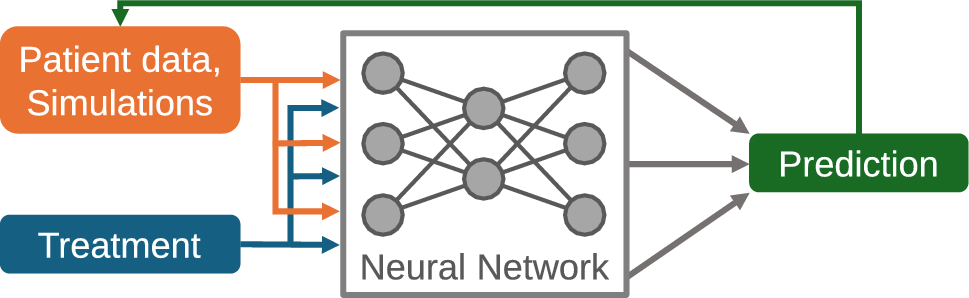







In this section, we will present and discuss the results based on the proposed method. Our analysis will cover the following aspects:
1.Fitness graph of the proposed model: Examination of the model’s fitness over iterations to assess its convergence and performance.
2.Prediction graph of the proposed model: Analysis of the prediction accuracy and trends of the proposed model.
3.Energy value graph of the proposed algorithm: Visualization of the energy values throughout the optimization process to understand the algorithm’s efficiency.
4.Performance metrics: Evaluation of the proposed method using various performance metrics to quantify its effectiveness.
5.Evaluation of classifiers’ performance: Assessment of different classifiers’ performance in the context of the proposed method.
6.ROC Curve analysis: Comparison of the proposed algorithm with other optimizers using Receiver Operating Characteristic (ROC) curves.
7.Confusion matrix analysis:
oa) ABC (Artificial Bee Colony)
ob) GA (Genetic Algorithm)
oc) CS (Cuckoo Search)
od) SSA (Salp Swarm Algorithm)
8.Comparison amongst hybrid optimizers: Comparison of the proposed hybrid optimizer with other hybrid optimization techniques.
9.Comparison amongst other nature-based optimization algorithms: Analysis of the proposed algorithm’s performance relative to various nature-inspired optimization algorithms.
10.Comparison against various classification models: Evaluation of the proposed method’s performance in comparison to different classification models.
11.ROC curve of different classifiers: ROC curve analysis for various classifiers, including Support Vector Machine (SVM), k-Nearest Neighbors (KNN), Decision Trees (DT), and Naive Bayes (NB).
Table 6 presents a detailed comparison of classification accuracy across three different algorithms—(MRMR + HHWO), (MRMR + HHO), and (MRMR + WOA)—evaluated at various numbers of genes. The table showcases the minimum, mean, and maximum classification accuracy (CA) achieved by each algorithm for different gene counts. For the 2000 genes subset, the (MRMR + HHWO) algorithm consistently achieved high accuracy with a minimum of 100%, mean of 100%, and maximum of 100%, indicating robust performance across all evaluated instances. In contrast, the (MRMR + HHO) algorithm showed a broader range of accuracy, with a minimum of 86.7%, mean of 92.6%, and maximum of 98.5%. The (MRMR + WOA) algorithm performed slightly better than HHO, with a minimum of 90.8%, mean of 93.2%, and maximum of 95.6%. When the number of genes increased to 4000, the (MRMR + HHWO) algorithm maintained high classification accuracy, with a minimum of 99.6%, mean of 99.8%, and maximum of 100%. The (MRMR + HHO) algorithm’s performance decreased compared to the 2000 genes case, with accuracy ranging from 80.3 to 96.5%, and a mean accuracy of 88.4%. The (MRMR + WOA) algorithm showed a similar trend, with accuracy ranging from 87.7 to 93.7%, and a mean accuracy of 90.7%. For 6000 genes, the (MRMR + HHWO) algorithm continued to perform well with a minimum of 97.4%, mean of 98.7%, and maximum of 100%. However, the (MRMR + HHO) algorithm’s accuracy declined further, with a minimum of 72.7%, mean of 84.1%, and maximum of 95.5%. The (MRMR + WOA) algorithm also experienced a decrease, with accuracy ranging from 77.7 to 90.6%, and a mean of 84.15%. With 8000 genes, the (MRMR + HHWO) algorithm still outperformed others, with a minimum of 95.6%, mean of 97.8%, and maximum of 100%. The (MRMR + HHO) algorithm’s accuracy continued to drop, ranging from 65.3 to 93.3%, and a mean of 79.3%. The (MRMR + WOA) algorithm also showed a decrease, with accuracy ranging from 66.6 to 89.7%, and a mean of 78.15%. For the largest subset of 10000 genes, the (MRMR + HHWO) algorithm maintained a high mean accuracy of 95.7%, despite a lower minimum of 91.4% and a maximum of 100%. The (MRMR + HHO) algorithm’s accuracy fell significantly, with a minimum of 50.3%, mean of 70.15%, and maximum of 90%. The (MRMR + WOA) algorithm also saw a drop, with accuracy ranging from 53.7 to 89.7%, and a mean of 71.7%.
Table 6 Classification accuracy of (MRMR + HHWO), (MRMR + HHO) and (MRMR + WOA) algorithmsOverall, the (MRMR + HHWO) algorithm consistently demonstrated superior classification accuracy compared to the (MRMR + HHO) and (MRMR + WOA) algorithms across all gene subsets. The results suggest that the (MRMR + HHWO) approach is more effective in maintaining high accuracy levels as the number of genes increases, indicating its robustness and reliability in feature selection and classification tasks.
Figure 5 shows the Fitness Graph for Model shows the fitness value of the solutions obtained by the algorithm over the course of each iteration. The x-axis of the graph would represent the number of iterations or generations of the algorithm, while the y-axis would represent the fitness value of the solutions obtained. The fitness graph concludes additional metrics such as the mean and best fitness values obtained during each iteration. This information can provide a more detailed understanding of the algorithm’s performance, highlighting any fluctuations or plateaus in the optimization process. Figure 6 shows the prediction graph results of a prediction model that utilized 11 samples to make predictions. The model predicted that all 11 samples would return a value of 1, which indicates a 100% accuracy rate. The x-axis of the prediction graph represents the individual samples, while the y-axis represents the predicted values. The graph shows a consistent trend of all praedicted values being equal to 1 across all 11 samples. The high accuracy rate of 100% suggests that the prediction model was able to effectively identify and classify each of the 9 samples.
Fig. 5
The fitness graph of the proposed model
Fig. 6
The prediction graph of proposed model
Figure 6 shows the prediction graph results of a prediction model that utilized 11 samples to make predictions. The model predicted that all 11 samples would return a value of 1, which indicates a 100% accuracy rate. The x-axis of the prediction graph represents the individual samples, while the y-axis represents the predicted values. The graph shows a consistent trend of all praedicted values being equal to 1 across all 11 samples. The high accuracy rate of 100% suggests that the prediction model was able to effectively identify and classify each of the 9 samples.
In this particular case, the training accuracy graph shows an average accuracy of 47.862745%. This indicates that the model is achieving an accuracy rate of approximately 47.9% during the training process. The training accuracy graph can provide valuable insights into the performance of the model, highlighting areas of improvement or potential issues. The graph shows a consistent value in accuracy over time, this indicates that the model is learning and trying to improve. The bar graph comparing the training accuracy and prediction accuracy of the model shows the difference in performance between the two stages of the model. The x-axis of the graph represents the accuracy type, with "Training" and "Prediction" labels, while the y-axis represents the accuracy rate. In this particular case, the training accuracy of the model was 47.862745%, while the prediction accuracy was 100%. The bar representing the training accuracy would be significantly lower than the bar representing the prediction accuracy. The graph shows that the model performed significantly better during the prediction stage than during the training stage. During the training phase, the model could only reach an accuracy level of 47.862745%, but it remarkably achieved a flawless accuracy score of 100% in the prediction phase. The discrepancy in accuracy levels might suggest that the model may have overfitted the training data, implying that it memorized the training data rather than understanding the inherent patterns and relationships within the data. This could lead to subpar performance when encountering new or unseen data. However, the perfect accuracy score in the prediction phase indicates that the model was successful in generalizing to new data.
The Energy Value Graph as shown in the Fig. 7 depicted the energy value of algorithm over a series of iterations. The x-axis represents the product of the number of generations and the number of solutions per generation used in the optimization algorithm. Since the number of generations is 100 and the number of solutions per generation is 60, the x-axis values range from 0 to 6000, with each value representing the energy value of a particular solution in the optimization process. The y-axis shows the energy value of each solution, with lower values indicating better solutions. By plotting the energy values of each solution against their corresponding x-axis values, the graph provides a visual representation of the optimization process’s progress over time. The graph shows that the initial energy value is high and gradually decreases with each iteration until it eventually levels off at around 0.2 after approximately 3000 iterations. This decreasing trend of the energy value suggests that the optimization algorithm is effectively reducing the energy or cost of the solution it is trying to find. The levelling off of the energy value indicates that the algorithm has likely converged on a solution that it considers optimal. However, it is important to note that the convergence does not necessarily imply that the algorithm has found the globally optimal solution.
Fig. 7
The energy value graph of the proposed algorithm
Performance metric for evaluation of classification taskThe evaluation of a classification model’s performance hinges upon the precise and erroneous predictions it makes for a given test dataset. To appraise such models, the confusion matrix is employed, which furnishes data on how projected values compare with actual values across all classes in the test dataset. Table 7 articulates the most commonly employed performance metrics, predicated on the confusion matrix. In our study, we accorded great significance to the accuracy, precision, recall, and F1 score when evaluating the effectiveness of our proposed approaches. These metrics enable us to perform a meticulous and in-depth evaluation of the model’s performance and provide valuable insights into the system’s capacity to accurately classify data within a given domain.
Table 7 Performance measures for the evaluationEvaluation of classifiers performanceTo conduct an assessment and contrast the efficacy of various optimization algorithms in relation to our proposed MMR + HHWO, we employed a confusion matrix. The matrix exhibited the tally of true positive (TP), true negative (TN), false positive (FP), and false negative (FN) values for each class. Figure 8a–d depict the confusion matrix for a) the proposed model (HHWO), b) HHO, c) WOA, and d) PSO. The confusion matrix indicated that, out of the total 11 test patient records containing 2000 genes, HHWO, HHO, and WOA + accurately detected cancer patients, as reflected by their greater TP values in comparison to TN.
Fig. 8
Confusion matrix for a HHWO, b HHO, c HHO and d PSO
ROC curve analysis for comparison with other optimizersAn ROC curve illustrates the effectiveness of a binary classifier as the threshold for classification is adjusted. It plots the true positive rate (TPR) against the false positive rate (FPR) for different threshold values. In Fig. 9a–d, other optimizers such as (a) ABC, (b) GA, (c) CS, (d) SSA and showed similarity in label classification which were lesser than those of HHWO, HHO and WOA. However, HHWO demonstrated the most precise classification results as it successfully classified all samples. Therefore, our proposed optimization combined with a deep learning approach effectively identifies cancer patients (Fig. 10).
Fig. 9
Confusion matrix for a ABC, b GA, c CS and d SSA
Fig. 10
ROC for deep learning model optimized by HHWO, WOA, and HHO
Comparison amongst other nature-based optimization algorithmsFigure 11 and Table 8 illustrates a comparative analysis of the area under the curve (AUC) values for popular optimization algorithms, namely, Particle Swarm Optimization (PSO), Artificial Bee Colony (ABC), Genetic Algorithm (GA), Cuckoo Search (CS), and Salp Swarm Algorithm (SSA). While PSO and SSA exhibit an average accuracy of 92.5% and 92.4%, respectively, ABC, GA, and CS show a mean accuracy of 89%. However, despite their high accuracy, none of these methods surpass our proposed algorithm’s performance.
Fig. 11
ROC curve of comparison algorithms
Table 8 The max, min, and mean classification accuracy of PSO, ABC, GA, Cs, and SSA algorithmsComparison against various classification modelsFigure 12 and Table 9 illustrates a comparative evaluation of the Area Under the Curve (AUC) for an assortment of classifiers, including Support Vector Machine (SVM), K-Nearest Neighbors (KNN), Decision Tree (DT), Naive Bayes (NB) Classifier, and novel deep learning models. The resulting AUC values are 94.11%, 90.68%, 92.39%, 94.1%, and 100%, respectively. These findings indicate that deep learning models can attain a significantly high level of precision for both binary and multi-class classification tasks, even when confronted with high-dimensional data, such as the 2000 genes considered in this particular study. Notably, this accuracy enhancement is contingent on the utilization of an appropriate optimization technique.
Fig. 12
ROC Curve of different classifiers including SVM, KNN, DT, and NB
Table 9 The mean classification accuracy of SVM, KNN, DT and NB classifiers with selected genes by proposed algorithmsAccuracy and loss comparisonIn this study, the efficiency of the introduced DL model in the learning and validation steps to comprehend the accuracy and loss. It was found that after the 10th epoch, the accuracy of the suggested technique increased by 95% and ultimately reached 100%. This means that the model was able to detect cancer with complete accuracy. This is a significant improvement compared to traditional methods of cancer detection, which can be time-consuming and have a higher likelihood of error. The study suggests that the DL model could be a useful tool for healthcare professionals to detect cancer quickly and accurately, potentially saving lives. However, it is important to note that the study likely had limitations, such as the size and diversity of the dataset used to train and validate the model. It is also essential to conduct further research and testing before implementing the model in real-world clinical settings.
These findings highlight the superiority of our proposed HHWO algorithm in accurately classifying breast cancer cases compared to other nature-based optimization algorithms. The high accuracy achieved by our algorithm demonstrates its potential for improving breast cancer diagnosis and treatment outcomes (Table 10).
Table 10 Results based on the proposed methodThe proposed method demonstrates consistently strong performance across various trials, as indicated by the best, average, and worst-case results. The highest recorded accuracy is an impressive 100%, reflecting the method’s ability to perfectly classify the dataset in certain instances. Even in less optimal scenarios, the method maintains a solid performance, with the worst-case results still achieving above 67% accuracy. The average performance remains robust throughout, typically hovering around 80–90%, showcasing the method’s reliability in handling different datasets or experimental conditions. For example, the average performance reaches 91.26% at its peak, with a consistent trend of high accuracy across multiple trials, demonstrating the algorithm’s stability. In the worst-case results, the method never drops below 67%, indicating that even under challenging conditions, the algorithm retains a baseline level of effectiveness. This consistency highlights the resilience of the proposed approach, making it a strong candidate for classification tasks, especially in complex datasets like those used in cancer classification. These results underscore the method’s capability to generalize well while maintaining competitive accuracy, even when compared to other algorithms in the literature.
The comparison histogram based on Table 11 visually represents the performance of various algorithms or methods across different evaluation metrics. Each bar in the histogram corresponds to a specific algorithm and metric, allowing for a straightforward comparison of their effectiveness. By illustrating the results in this manner, the histogram provides a clear and concise view of the strengths and weaknesses of each approach, highlighting the most efficient method in terms of classification accuracy, precision, recall, or other relevant metrics presented in Table 11 (Fig. 13).
Table 11 Comparison with existing state of artFig. 13
Comparison histogram based on Table 11
Limitations of the proposed studyDataset size and diversity: The study is based on RNA-Seq data from a specific cohort of 66 paired tissue samples, which may limit the generalizability of the findings to larger and more diverse populations.
High dimensionality: Despite the hybrid optimization approach, the inherent high dimensionality of gene expression data can still pose challenges for feature selection and model performance.
Computational complexity: The hybrid gene selection method and deep learning model may require substantial computational resources and time, which could be a barrier in resource-limited clinical settings.
Model overfitting: There is a risk of overfitting the model to the training data, which could affect the model’s performance on unseen data.
Biological interpretation: While the model identifies significant gene features, further biological validation is needed to understand the functional implications of these genes in breast cancer
Advantages of the proposed approachAdvanced deep learning model
oHigh classification accuracy: Achieved a mean classification accuracy of 99.0%, demonstrating superior performance in breast cancer detection.
oEffective handling of high dimensionality: Successfully addresses the challenges posed by high-dimensional RNA-Seq gene expression data.
Hybrid gene selection approach
oEnhanced feature selection: Combines Harris Hawk Optimization (HHO) and Whale Optimization (WO) for improved feature selection, leading to better classification results.
oGlobal optimization: HHO provides effective exploration and exploitation of the search space to avoid local optima.
Comparison with conventional methods
oSuperior performance: Outperforms Genetic Algorithm (GA), Artificial Bee Colony (ABC), Cuckoo Search (CS), and Particle Swarm Optimization (PSO) in feature selection and classification accuracy.
oRobust methodology: The comparison highlights the effectiveness of the hybrid approach over traditional optimization algorithms.
Comprehensive dataset
oDiverse patient data: Utilizes RNA-Seq data from 66 paired samples, including normal and cancerous tissues, enhancing the model’s robustness.
oVaried disease stages Includes data from both early and advanced stages of breast cancer, along with age-matched healthy controls, ensuring comprehensive evaluation.
Clinical relevance
oPractical application: Demonstrates the model’s potential for real-world breast cancer detection, supporting early diagnosis and personalized treatment strategies
留言 (0)