
記住我

The integrity and reliability of power transmission systems are paramount for maintaining a stable electricity supply, which is fundamental to modern society and economic activities. Foreign objects on transmission lines, such as tree branches, plastic bags, or other debris, pose a significant threat to this integrity. These objects can cause short circuits, power outages, and even catastrophic failures leading to substantial economic losses and potential safety hazards. The presence of foreign objects can also lead to line tripping, which disrupts the power supply and affects the quality of electricity delivery to consumers. Presently, manual inspection is the main method of inspection for most transmission lines (Koh, 2023; Luo et al., 2023). However, transmission lines often exist in complex natural environments and harsh weather conditions, such as mountains, forests, and deserts. Harsh environments and weather conditions cause manual inspection problems, which lead to false alarms, missed reports and low detection rates. These constraints hinder the prompt detection of foreign objects on power lines, challenging the timely identification and resolution of potential safety risks. Technological limitations, environmental factors, and the need for improved data processing and response systems are key areas that require attention to enhance real-time monitoring and safety on power lines. In addition, manual inspections are costly, and it is difficult to cover all transmission lines. These problems have led to new requirements for ensuring the operation and the upkeep of high-voltage electrical networks, making it difficult for conventional manual monitoring techniques to meet actual needs in complex environments and real-time monitoring of foreign objects on numerous transmission lines.
In this context, improving the efficiency and accuracy of transmission line inspections has become an urgent problem. Many researchers are committed to developing intelligent inspection systems for power line monitoring utilizing deep learning to ensure effective and precise assessments.
Wang et al. (2022) proposed a fusion detection model based on multiscale appearance and relationship features. In comparison to the initial YOLOv5, the suggested model demonstrated enhanced precision. However, this model's performance is still limited when dealing with images that have highly similar background textures, possibly due to a lack of in-depth understanding of local and global contexts. Wang et al. (2023a) proposed a fusion detection model based on the improved YOLOv8m. In a foreign transmission line object detection model, the model's architecture was optimized by substituting the original SPPF component with an advanced SPPCSPC component, thereby bolstering its capacity for extracting multi-scale features. Additionally, the implementation of the Focal-EIoU loss function addressed the issue of sample quality imbalance, ensuring a more equitable focus on both high-quality and low-quality samples during training. However, this method may over-rely on the re-weighting of samples and does not fully consider the dynamism of feature extraction. Liang et al. (2020) investigated a deep neural network approach for assessing and pinpointing flaws in power line inspections, employing learned transfer and parameter optimization techniques to build the Fast R-CNN detection model. Nevertheless, the model's performance may decline when dealing with small or partially occluded targets, indicating the need for more refined feature extraction and target localization mechanisms. Wang et al. (2017) proposed a YOLOv5 transmission line inspection image detection model implementing the K-means clustering technique to refine the dimensions of the anchor boxes, this method enhances the model's capability to accurately align with salient object characteristics. The generalizability of this method may be limited under different environmental conditions, especially in complex and variable outdoor settings. Liang et al. (2023) proposed optimizing the YOLOv5s model to solve the problems of low accuracy and poor timeliness of deep learning network models in processing background texture occlusion images. The threshold function is used to denoise the image, and the original loss function GIOU_Loss is optimized into the CIOU_Loss function, which is subsequently fine-tuned. While these improvements have increased the model's robustness to some extent, adaptability to dynamic environmental changes remains a challenge.
Although many scholars have achieved excellent results within the context of foreign object detection on power lines, the accuracy of current technology is still insufficient for increasingly complex transmission line networks. For example, in complex environments, due to background occlusion and light, foreign objects in power transmission lines cannot be completely identified in the picture, causing foreign objects to be occasionally missed. In response to the limitations of existing models, the WSA model proposed in this paper introduces a weighted spatial attention mechanism to enhance the capture of local features and the understanding of global contexts. By dynamically adjusting attention weights, the WSA model can more effectively handle background texture occlusion and improve the detection accuracy of small and occluded targets. This approach will provide a more effective means for the management and upkeep of the power system, improve work efficiency, reduce costs, and effectively avoid circuit hazards caused by foreign objects in transmission lines.
The primary contributions of this scholarly work are delineated as follows, taking into account various perspectives:
1. This paper proposes an innovative WSA network that addresses the difficult problems in foreign object detection on power lines and combines the specific advantages of BSAM, improved LSKNet, and bifpn technologies to achieve more efficient transmission line safety detection.
2. The large convolutional structure of LSKNet is introduced, and the improved large convolutional structure of LSKNet exhibits a more extensive input coverage and stronger feature extraction capability that can effectively capture the contextual information and fine-grained features of the target.
3. The BiFPN structure is used to improve the traditional PAN–FPN structure and optimize the weight distribution of the fusion results. By reasonably adjusting the weight distribution of the fusion results, the efficacy and resilience of the network for object identification assignments are additionally enhanced.
2 YOLOv8 algorithmThe YOLOv8 detection algorithm is a lightweight anchor-free model that directly predicts the center of extraneous materials within power conduits instead of the offset of the known anchor frame (Talaat and ZainEldin, 2023; Pan et al., 2024). The algorithm can quickly locate the foreign objects in transmission lines to be detected during detection. Anchorless detection reduces the number of box predictions, accelerates non-maximum suppression and replaces C3, the main building block in the network, with C2f, in which all the outputs of the bottlenecks are concatenated. In C3, only the output of the last bottleneck is utilized, and the kernel size of the first convolution is changed from 1 × 1 to 3 × 3, which makes extracting foreign body features of power transmission lines initially more efficient. More information about the characteristics of extraneous materials within power conduits can be obtained.
In the neck part, the features are directly connected without forcing the use of the same channel size, which reduces the number of parameters and the overall size of the tensor so that the volume of the final power line foreign object detection model is also reduced accordingly.
Since YOLOv8 uses a large grid to segment the image, there may be errors in the precise location of foreign objects in power lines, and it may not be suitable for precise positioning application scenarios. Second, YOLOv8 uses a constant scale during training, and the scale of the detection target may change due to factors such as distance and viewing angle. Therefore, in the application scenario, the YOLOv8 network is improved and a multiscale process is used to generate new feature maps to improve the accuracy and reliability of target recognition (Liu et al., 2024; Vahdani and Tian, 2024).
3 WSATo enhance the precision and efficiency of foreign object detection on power transmission lines, this study employs the rapid and accurate YOLOv8 algorithm as a foundation. The YOLOv8 algorithm is renowned for its exceptional speed and detection accuracy; however, it encounters difficulties in identifying targets obscured by background elements. In order to overcome this limitation, a new network structure named Weighted Spatial Attention network (WSA) is proposed based on YOLOv8. The WSA network combines a spatial attention mechanism with a weighted feature pyramid network, creating a complementary effect that significantly improves the detection performance of obscured targets. Additionally, to address the issue of partially occluded targets, this study utilizes data augmentation methods, including random occlusion techniques, to enhance the model's flexibility and robustness in handling partially obscured targets.
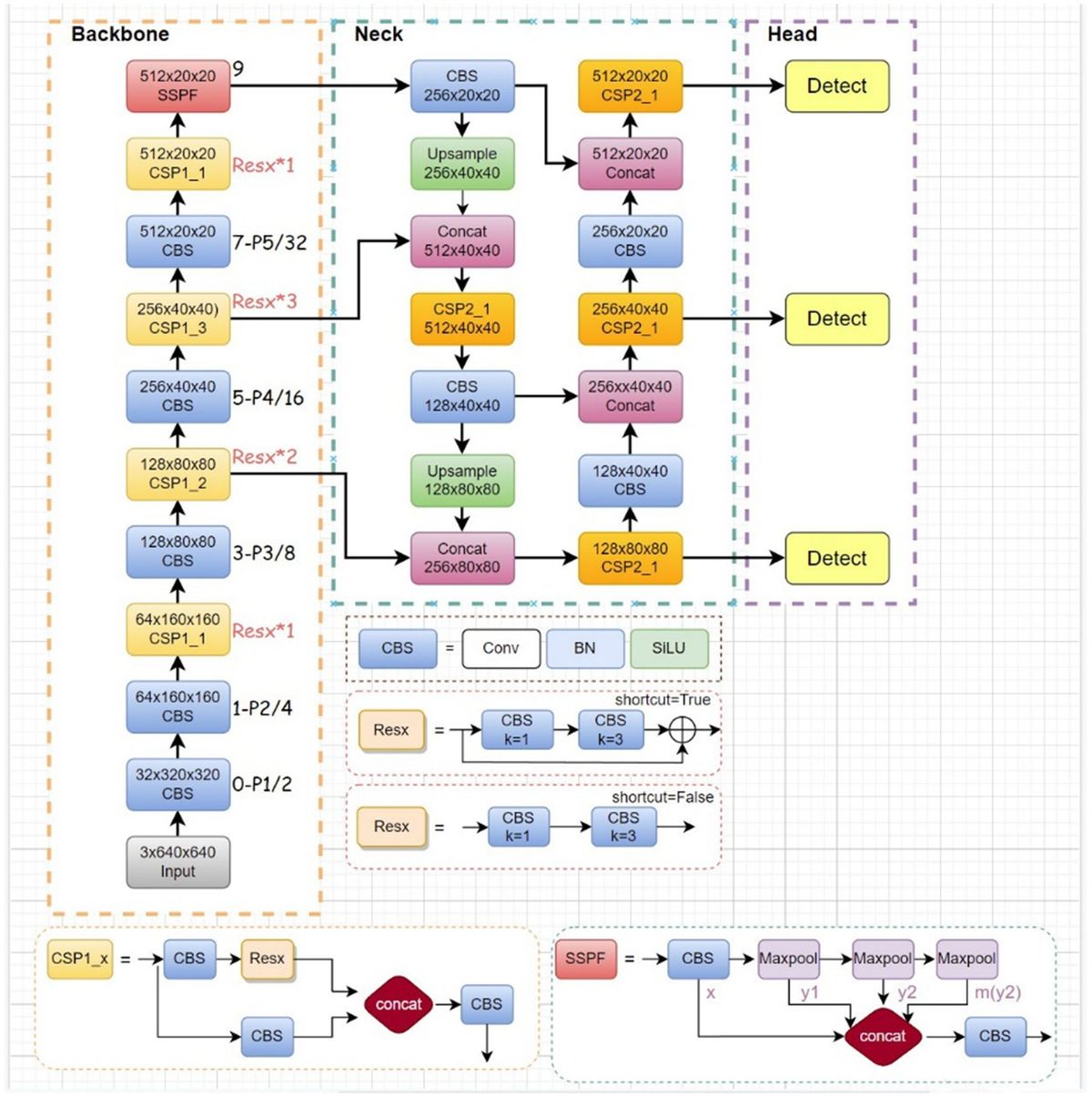
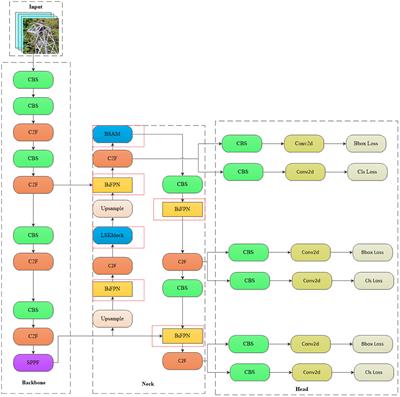
By integrating the LSKNet large convolutional framework into the BSAM foundation, the WSA network enhances its capabilities by broadening the receptive field and capturing fine-grained feature details. Furthermore, we have strengthened the traditional PAN-FPN architecture through the implementation of the BiFPN structure and an improved weight allocation method, thereby enhancing the integration of multi-scale features. With the integration of a weighted scheme, the network utilizes information from different feature layers more effectively, enhancing its focusing and discriminative abilities for transmission line detection. The WSA network retains the advantages of existing structures while enhancing the framework's effectiveness and robustness, demonstrating promising applicability and prospects for widespread adoption. The detailed structure of the WSA network architecture is depicted in Figure 1, clearly illustrating how the network achieves efficient identification of foreign objects on power transmission lines through the collaborative work of its various components.
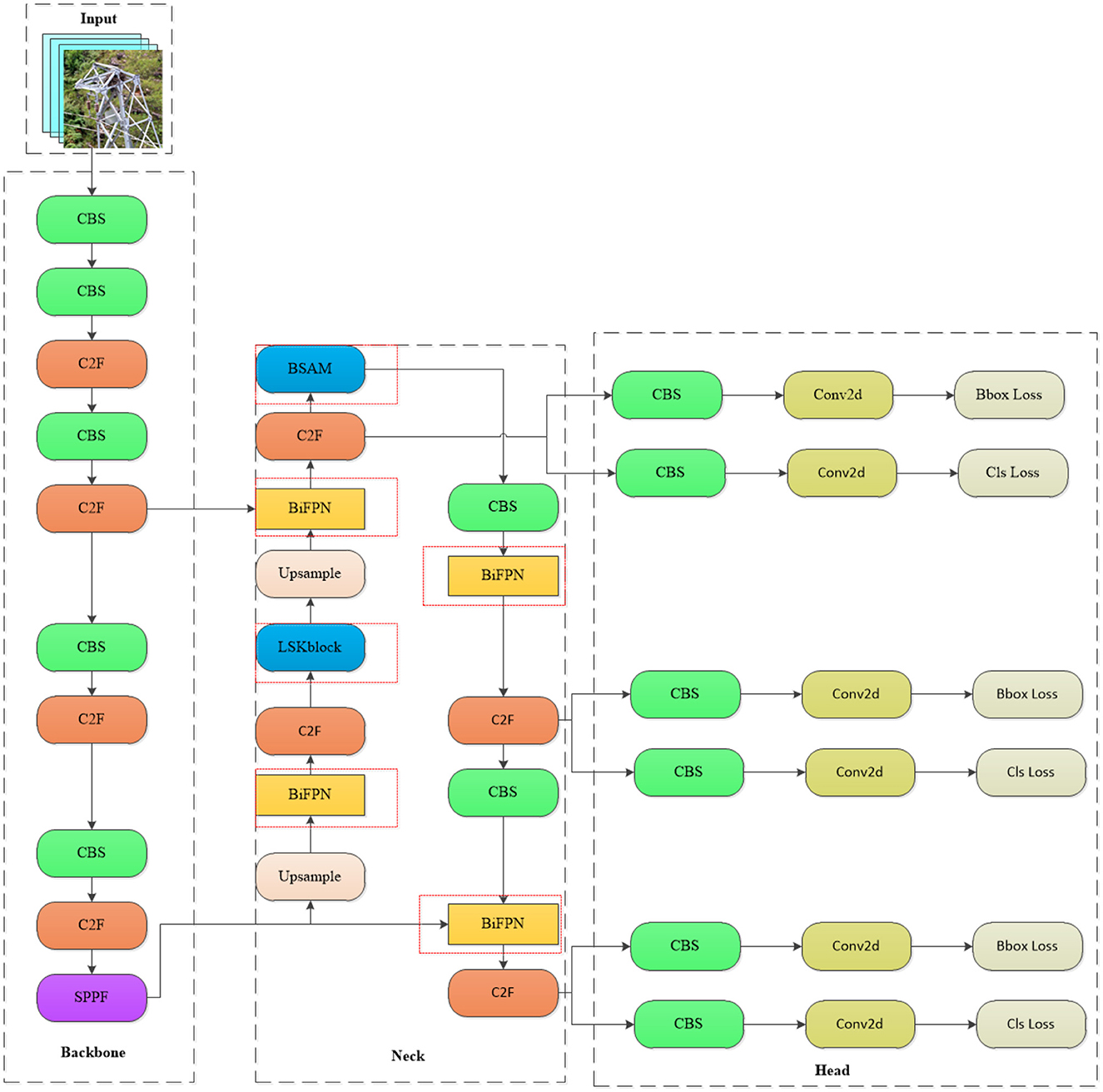
Figure 1. WSA network architecture diagram (in the neck network diagram, the network enclosed by the red dashed lines represents the addition made in this paper, where the LSK block is a modified version of the original module).
3.1 LSKNetLSKNet is a lightweight network proposed by Li that can dynamically adjust the spatial receptive field (Li F. et al., 2023; Li Y. et al., 2023). Most of the images in the transmission line foreign object dataset are obtained by drone aerial photography. The objects in many pictures are small and not easily recognized by the model. The model must rely on their background and surrounding environment to identify these objects. Addressing the issue concerning image detection in intricate surroundings, LSKNet has emerged. Using the rotation-sensitive convolution operation of LSKNet, it can effectively capture the rotation information of extraneous matter on power lines and improve the accuracy of the target detection (Guo et al., 2021; Chen et al., 2023; Hanzl et al., 2023; Ju and Wang, 2023; Kou et al., 2023; Zhang T. et al., 2023). This paper introduces a dynamic receptive field adjustment method based on large kernel selection sub-blocks and adds a deep convolution to the basic LKS election aiming to diminish the parameter count while concurrently enhancing the capacity for characteristic portrayal. In addition, feed-forward network sub-blocks are applied to channel blending and feature expression refinement, additionally, the model's precision in capturing relevant details is significantly improved. By dividing the image into multiple grids and performing feature extraction on each grid and by integrating these features, we empower the system to concentrate its attention more acutely on the area of interest. This approach improves the robustness and generalizability of the model. As shown in Figure 2, red DW-Conv is the added depth convolution.
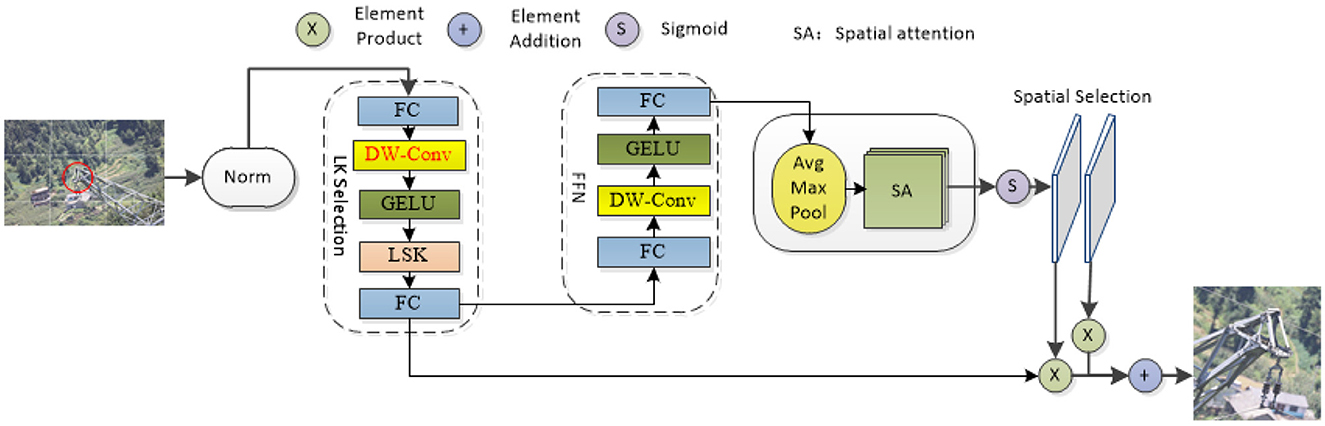
Figure 2. LSK model diagram (in the diagram, the components highlighted in red denote the added depth convolutional blocks, while “Avg Max Pool” refers to the sequential application of average and maximum pooling operations).
LSKNet plays a key feature extraction role in foreign object detection on transmission lines. First, LSKNet can dynamically adjust the feeling field of the network, through its core module, the LSK module. The network can adaptively select different sized convolution kernels according to the content of the input image and thus can capture features at different scales. This capability is particularly important for the precise identification of minor objects within satellite imagery, as small targets may require finer features to distinguish. Second, LSKNet uses a spatial selection mechanism to weight the processed feature maps of the convolution kernel at different scales. This mechanism allows the network to spatially incorporate these feature maps, thereby enhancing the contextual understanding of the target surroundings while maintaining computational efficiency. Last, the inclusion of LSKNet was driven by its ability to dynamically adjust the spatial receptive field, which is crucial for identifying small and distant objects common in transmission line imagery. The large convolutional structure of LSKNet provides extensive input coverage and robust feature extraction, enabling the model to effectively capture contextual and fine-grained features of targets.
In practical applications, LSKNet can overcome the effects of light changes, shadows, occlusions, and other factors on the detection results and can accurately identify different types of foreign objects, such as bird nests and kites. This function not only reduces the risk of missed detections and false detections but also improves the reliability of transmission line monitoring.
3.2 BSAM attentionThe BSAM is designed to integrate the dual advantages of the CBAM and BiFormer to bolsters the model's capacity to discern targets and pay attention to local details. The CBAM weights the depth and spatial aspects of the feature map through channel and spatial attention mechanisms, respectively, to extract useful feature information. BiFormer uses the internal attention mechanism of the transformer to dynamically learn the long-range dependencies between feature image pixels. By combining these two attention mechanisms, the BSAM can more effectively seize the contextual cues and intricate characteristics of the target (Guo et al., 2023; Zheng et al., 2023; Zhu et al., 2023; Hu et al., 2024a,b). The CBAM consists of two parts: channel attention and spatial attention. The BSAM also inherits this feature. The channel attention mechanism enters the input image feature map into a depth-separable convolution to reduce the amount of calculation and then normalizes it. The layer enters the dual-layer routing attention mechanism, pruning and filtering the feature information, only focusing on the routing area with the most feature information, filtering other areas, and then passing the multilayer perceptron to obtain the deep feature map (Cheng et al., 2023). These feature maps are average pooled and max pooled in units of channels, and then the results are connected, converted to dot products through convolution, and applied to the feature maps according to the spatial attention channel weights. The architecture diagram is shown in Figure 3.
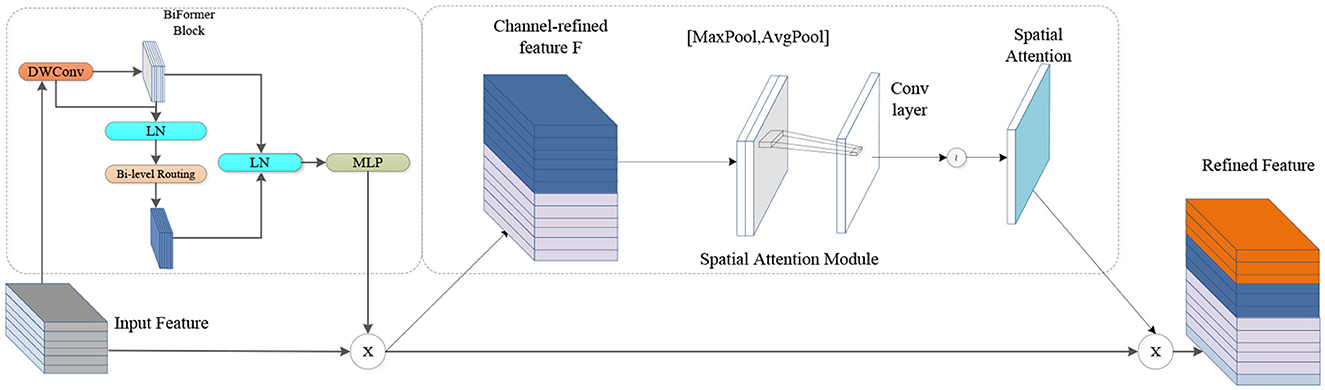
Figure 3. Diagram of the BSAM architecture.
Compared with existing attention mechanisms, the BSAM has more advantages when processing small target images. By integrating a fusion of an introspective focus system with convolution operation, the BSAM can efficiently extract feature information and adapt to different processing methods in different scenarios. The BSAM enhances the model's understanding of the image context by integrating multilevel feature information, which is crucial for the accurate identification and positioning of foreign bodies in complex backgrounds, especially in scenarios such as transmission lines, where foreign bodies may be similar to the background texture or appear at different angles and under different light conditions.
Compared with the addition of CBAM or BiFormer, the number of parameters in the BSAM has not significantly increased, but it can accurately capture the key information in the input data and filter out redundant and noisy features. This ability greatly improves the robustness of the model, allowing it to better adapt to target detection tasks under background texture occlusion and lighting conditions. Similar to the CBAM, the BSAM has the ability to adaptively weight features of different scales, thereby retaining richer semantic information and further improving the generalization ability of the model (Hanning et al., 2023; Li F. et al., 2023; Li K. et al., 2023; Liu L. et al., 2023; Liu X. et al., 2023).
First, the input image features enter a 3 × 3 depth separable convolution, and then the results enter the normalization layer and dual-layer routing attention mechanism module, which divides the feature map X∈RH×W×C into NxN non-repeating regions. X represents the feature map of the input; H, W and C represent the height, width and number of channels, respectively; each region includes H×W×N2 a feature vector, which can be converted to Equation (1); and the query, key, and value tensors Q, K, and V are derived ∈RN2×HWN2×C, which have linear projections such as Equation (2). Only the top-k connections in each region are retained to prune the association graph Ir = topkIndex (Ar), where Ar is the adjacency matrix of the interregion affinity map, and tensors of keys and values for query tokens in each region are collected. O is the tensor of the output, Attention (⊙) is an attention operation, and LCE (⊙) is a depth convolution parameterization, as shown in Equations (3, 4), where Kg, Vg is the tensor of the aggregation key and value.
Xr∈RN2×HWN2×C (1) Q=XrWq,K=XrWk,V=XrWv (2) Kg=gather(K,Ir), Vg=gather(V,Ir) (3) O=Attention(Q,Kg,Vg)+LCE(V) (4)Second, the module dedicated to spatial focus is activated, following which average and maximum pooling steps are applied, the feature maps generated by them are spliced, and the convolution operation is applied to the spliced feature maps to generate the final feature map. The whole process in Equation (5) is expressed as follows: f7 × 7 represents a 7 × 7 convolution operation, MaxPool, AvgPool represents the maximum pooling with the mean pooling, and Ms represents the spatial attention module.
Ms(O)=σ(f7×7([AvgPool(F);MaxPool(F)]) (5)The BSAM attention mechanism shows significant advantages and effects for identifying unauthorized items within the framework of power conduits. This combined attention mechanism fully utilizes the characteristics of the channel attention and spatial attention of the CBAM and weighted double-layer path attention mechanism of BiFormer. This approach elevates the model's skill in handling capture image features and focus attention.
First, by focusing on key areas in the image through ensemble channel attention and spatial attention mechanisms, important spatial locations in the image can be identified, and more attention forces can be assigned to these areas to highlight the target object in a complex background. This approach improves the detection accuracy of the model under background texture occlusion and reduces false detections and missed detections. Second, the weighted dual-layer path attention mechanism of BiFormer allows the model to focus on different parts of the image at different levels and integrate multilevel feature information. This mechanism enhances the model's understanding of the contextual information and spatial layout of the image, more accurately identifying and locating foreign objects. By integrating channel attention and spatial attention with a weighted dual-layer path attention mechanism, this mechanism can more comprehensively focus on all aspects of the image, including channel dimensions, spatial dimensions, and different levels of feature information.
3.3 BiFPNAnother innovative point of this article is to introduce a weighted feature pyramid structure called BiFPN to solve the problem of low detection accuracy caused by light intensity. The BiFPN structure is able to grasp the significance of various input characteristics, the process involves iteratively conducting a hierarchical integration of coarse-to-fine and fine-to-coarse multi-tier feature merging, thereby seamlessly blending features across disparate scales (Liu L. et al., 2023). In traditional feature pyramid networks, feature fusion is usually accomplished by simple summation or averaging operations, which may lead to the loss of information. BiFPN controls the fusion of features at different levels through learnable weights, thus achieving lossless fusion of features while retaining more useful information, enhancing the model's perception capabilities and accuracy.
In the YOLOv8 model, the PANet pyramid structure is used to enhance the receptive field of the network. Compared with the original FPN pyramid, PANet has more bottom-up path aggregation but only one input, and there is no feature fusion. Therefore, in the BiFPN module, we remove PANet but still retain its output and realize the transfer of information by connecting the previous node to the next node. In addition, BiFPN also adds skip connections based on PANet to fuse the previous features. As shown in Figure 4, each circular block is image feature information extracted by convolution. Multiple BiFPN modules are applied to the entire YOLOv8 structure to fully integrate features and better utilize different levels of semantic information (Wang et al., 2019; Chen et al., 2021; Islam et al., 2023; Wu et al., 2023).
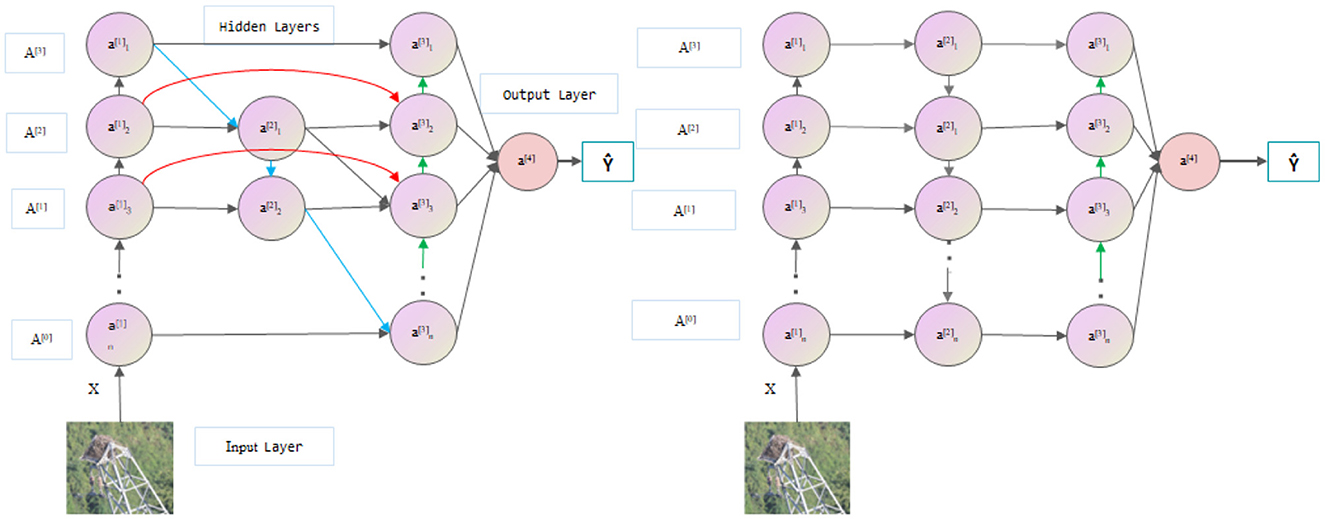
Figure 4. Comparison of BiFPN (left) with the PANet (right) network (the green arrows represent upsampling, the blue arrows represent downsampling, and the red arrows represent skip connections).
When performing feature fusion, different feature inputs have different resolutions and different output contributions to the feature network, so the network needs to learn the weights. However, general weighted fusion is not restricted, and wi makes the training process difficult to stabilize. It is not easy to converge, so BiFPN uses a fast normalized feature fusion operation, as shown in Equation (6):
O=Σiwiε+ΣjwjIi (6)First, the activation function wi≥0 ReLU is used to ensure that it is not <0. Second, a fixed value for ε, generally 0.0001, is used to ensure stable training. This approach avoids the Softmax operation and is faster than using Softmax in training. There is a significant improvement, and the final feature fusion network will also be input from bottom to top, thus constructing a weighted, two-way feature pyramid network.
Within the YOLOv8 framework, the integration of BiFPN enhances the capability of inter-scale feature interaction, which is particularly beneficial for bolstering detection capabilities in complex environments, such as power transmission lines. By establishing lateral connections that allow for direct fusion of features across various layers, BiFPN ensures a rich and detailed representation capturing both macro and micro aspects of the scene. This is crucial for the identification of foreign objects that may appear in various sizes and shapes against diverse backgrounds.
Furthermore, BiFPN's architecture is designed to iteratively refine these feature representations, enabling the model to progressively improve its understanding of the spatial hierarchy within the imagery. This refinement process is essential for the accurate localization and classification of foreign objects, especially when they are obscured or camouflaged by the natural setting of the power lines. Essentially, BiFPN contributes to the YOLOv8 model in two significant ways: it enriches the feature hierarchy through its bidirectional fusion process and enhances the model's ability to discern and locate foreign objects with high fidelity. This dual enhancement translates to a marked improvement in the detection accuracy of foreign objects on power transmission lines, thereby strengthening the model's applicability in real-world scenarios.
4 Research methodology and experimental evaluation 4.1 Dataset constructionTo address the scarcity of large-scale public datasets in the field of foreign object detection on power transmission lines, this study employed a dataset synthesized from aerial imagery captured by inspection drones and images collected from the internet, enhanced through various data augmentation techniques. Initially, web crawling technology was utilized to search for and download images related to foreign objects on power transmission lines from search engines such as Baidu and Google. Subsequently, a portion of the images was obtained through drone photography. However, due to environmental constraints, the number of images captured in this manner was limited.
To overcome this limitation and to create a more complex and diverse dataset, several data augmentation strategies were implemented. Standard enhancement methods, such as image flipping and rotation, were applied. In addition, a random occlusion technique was employed, where parts of the images were masked with black to simulate complex environmental backgrounds. Building on this, image synthesis techniques were used to place foreign objects onto power lines as a special form of dataset expansion.
The resulting dataset, comprising 2,300 images, is named the PL dataset in this paper. It mainly includes four distinct categories: bird nests, kites, balloons, and debris attached to transmission lines. Labeling was facilitated by the use of the third-party library Labeling and semi-automated annotation from Make Sense, which aids in the accurate localization and identification of foreign objects in the images.
Furthermore, the dataset was meticulously divided into training, validation, and testing sets in a ratio of 8:1:1, respectively. The training set, consisting of 1,840 images, provides a substantial amount of data for model learning. The validation and testing sets, each containing 230 images, are used to assess model performance and generalization capabilities. This partitioning strategy ensures a robust evaluation of the model's effectiveness in detecting foreign objects on power transmission lines.
4.2 Training configurationThe corresponding parameters of the model are shown in Table 1. The test hardware platform environment is Python3.8 and CUDA11.3, the GPU graphics card is an NVIDIA RTX3090, and the memory is 43 GB. The label smoothing value is set to 0.005. The learning rate was obtained using the cosine annealing algorithm. The maximum learning rate is set to 0.01, and the minimum learning rate is set to 0. The model gradually reduces the learning rate in the form of a cosine function according to the number of iterations during the training process. The training process is divided into multiple cycles. In each cycle, the learning rate starts from the initial value. As the number of iterations increases, it gradually decreases to a smaller value according to the curve of the cosine function and then starts again in the next cycle. This adjustment method not only ensures that the model can quickly converge in the early stages of training but also maintains a small learning rate in the later stages of training to prevent the model from oscillating near the optimal solution. The cosine annealing formula is shown in Equation (7), where lr represents the current learning rate, lr−max represents the maximum learning rate, e−total represents the total number of training rounds, and e_now represents the current training round.
lr=12lr-max×(1+cos(e_now×πe-total)) (7)
Table 1. Model parameter setting.
4.3 Analysis of model performance indicatorsThis paper uses the average precision mean, precision rate, recall rate, FPS and parameter quantity indicators to test the model performance (Du et al., 2023; Li F. et al., 2023; Vidit et al., 2023; Wang et al., 2023a,b; Lin et al., 2024). The mAP is the average accuracy of each category of detection results. AP refers to the area of the curve surrounded by the horizontal axis and vertical axis of the precision rate and recall rate, respectively. The calculation formulas for precision and recall are shown in Equations (8, 9), respectively.
Recall=TPTP+FN (8) Precision=TPTP+FP (9)In the formula, TP is the number of correctly identified targets. Generally, when the IoU threshold is ≥0.5, it is considered to be a correctly identified target. FP is the number of incorrectly identified targets; FN is the number of missed targets; Precision is the number of targets in the model, the proportion of correct targets among the detected targets; and Recall is the proportion of targets correctly identified by the model among the total number of all real targets (Sun et al., 2024). The number of detected categories in this article is 4; the mAP is shown in Equation (10).
mAP=14∑i=04APi (10) 4.4 Comparison experimentThis paper introduces the incorporation of depthwise convolution into the existing LSKNet network, with the improved results presented in Table 2. For ease of reference, Table 2 only displays the comparison with LSKNet-D, which is still referred to as the LSKNet network.

Table 2. Large kernel selection subblocks with added deep convolution contrast.
The data in Table 2 indicate that the Botnet model exhibits the highest precision, reaching 92.7%, but it also has the largest number of parameters, suggesting a more complex model. On the other hand, the AFPN model performs poorly in recall, with only 83.8%, yet it has the highest frames per second (FPS), reaching 262.54 FPS, indicating an advantage in speed. The C2f_repghost model has a slightly lower precision but the second-largest number of parameters, whereas the LSKNet-D model achieves the highest mean Average Precision (mAP) among all models, with 92.6%, while maintaining a relatively high FPS. The addition of depthwise convolutional layers resulted in a 0.8% decrease in mAP for the LSKNet model, which may indicate that the inclusion of depthwise convolutional layers could make it more challenging for the model to fully learn effective feature representations during training. However, with a 1.2% reduction in the number of parameters, the increase in FPS by 10.1% suggests that LSKNet can achieve rapid object detection at a lower computational cost, suitable for devices with limited resources. For instance, operating on drones significantly expands the application scope of LSKNet in the field of foreign object detection on power transmission lines.
Figure 5 shows the detection results for foreign objects such as bird nests and kites parked or attached to transmission lines. In Figure 5B, YOLOv8 recognized the spacer as a bird's nest, and the garbage recognition accuracy was only 27%. However, in Figure 5A, the WSA achieved a garbage recognition accuracy of 56%, and there were no false detections. Compared with YOLOv8, the WSA model has improved image detection accuracy and can reduce the occurrence of false detections. Thus, the WSA has higher reliability and accuracy in practical applications, which is beneficial for resource-constrained environments. Deployment and application in an environment can better meet the demand for a balance between the target detection effect and computing resource consumption.
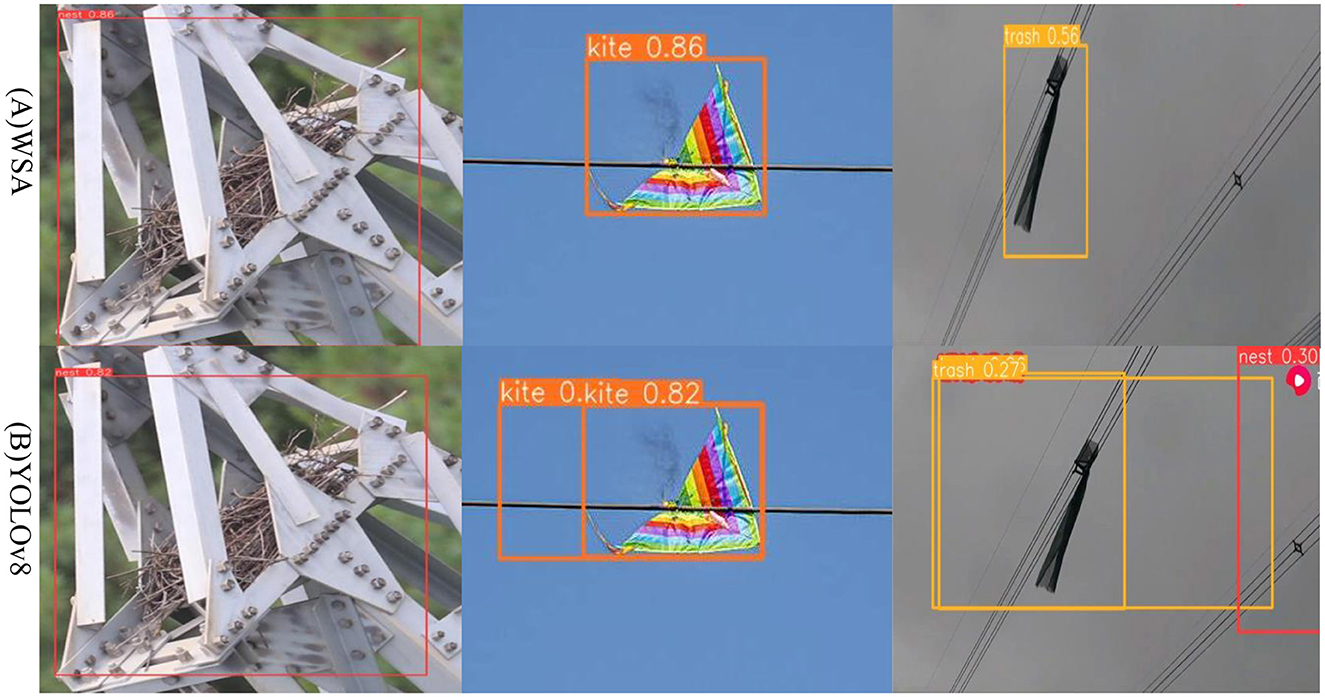
Figure 5. WSA and YOLOv8 algorithms for the identification results, (A) represents the detection effect of the WSA algorithm, (B) represents the detection effect of the YOLOv8.
However, the WSA model may also misdetect foreign objects in transmission lines during detection. First, the WSA model may not have sufficient recognition capabilities for certain types of targets, which may be attributable to the number of targets of that type in the training data caused by a low or uneven distribution. In addition, the target detection algorithm may have certain limitations on changes in the scale, posture, shape, etc., of the target, which may also cause some targets to fail to be accurately detected. Second, the WSA model may not perform well in difficult situations such as background texture occlusion, low light conditions, or occlusion. Especially when there are many distractors or when the target is highly similar to the background, the algorithm may not be able to accurately locate and identify targets. If the target is partially or completely occluded, the algorithm may not be able to obtain enough information for accurate detection. Moreover, the parameter settings and model selection in the algorithm may also affect the results of target detection. If some parameter settings are unreasonable or the model selection is not suitable for the current application scenario, target detection may fail or be missed. Therefore, when using the WSA model for target detection, it is necessary to carefully adjust the parameters and select a suitable model to improve the performance and robustness of the algorithm.
Figures 6, 7 represent the thermal maps of the improved network (left) and original network (right), respectively. A heatmap is a tool for visualizing the position and confidence of a target object. By observing the thermal maps in Figures 6, 7, we can intuitively observe the difference between the improved algorithm and the original algorithm in the target detection of layers 12 and 14 of the network. The heatmap shows that the improved network has a slightly greater effect than the original network in the same layer and more accurately identifies the target position.
留言 (0)