
記住我

Location-based social networks (LBSNs), a new type of social media, such as Yelp and Foursquare, are typical LBSNs applications. As a result, a large amount of check-in data have been accumulated, which provides an excellent opportunity to understand users' mobile behaviors. The next POI recommendation predicts where a user will go next, providing mutual benefits for POI holders and users. Due to its highly practical value, the next POI recommendation has attracted extensive attention from academia and the industry community.
Recently, how to improve the performance of next POI recommendation has been extensively studied (Zhang and Chow, 2015; Wang et al., 2016; Zhao et al., 2019; Afzali et al., 2021). In the early stages, Markov Chain (MC) (Cheng C. et al., 2013; Cheng H. et al., 2013; Liu et al., 2013; He et al., 2016) and Matrix Factorization (MF) (Lian et al., 2014; Zhang et al., 2019; Davtalab and Alesheikh, 2021; Xu et al., 2023) were commonly employed to model sequential transitions in conventional POI recommendations, treating user behavior patterns as static. However, conventional methods tend to overlook the dynamic evolution of user preferences over time and face challenges in handling sparse sequential data. This limitation has prompted a shift toward neural network-based approaches, particularly with the emergence of deep learning (DL). In recent years, researchers have made a series of important breakthroughs based on the recurrent neural network (RNN) model. Innovative initiatives such as the spatiotemporal recurrent neural network (STRNN) have successfully integrated time and geographical context information into the model (Liu et al., 2016; Zhu et al., 2017; Fang and Meng, 2022; Wu et al., 2022). The key to these methods is to process time series data efficiently. In this research area, the subsequent studies by Liu et al. (2021) and Zhao et al. (2022) further extended the Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) model to better capture long-term and short-term dependencies (Zhao et al., 2018). This enh anced approach involves the introduction of specialized spatial and temporal gates to regulate the flow of contextual information. As self-attention networks (SAN) show great potential in process sequential tasks, SAN-based models such as SASRec (Kang and McAuley, 2018) and TiSASRec (Li et al., 2020), quickly surpassing the traditional convolutional neural network (CNN) or RNN-based methods and becoming an advanced model in the field of sequential recommendation. Recently, some SAN-based works have further improved the performance of next Point-of-Interest (POI) proposals by introducing hierarchical grids (Lian et al., 2020; Cui et al., 2021). This innovative approach aims to fully exploit geographic information while taking into account non-adjacent locations and non-contiguous visits, improving model performance by explicitly incorporating spatial and temporal proximity. Graph neural network (GNN) (Rao et al., 2022) and knowledge graph (KG) have garnered more attention on the next POI recommendation due to the ability to better express entity relationships (Rao et al., 2022; Wang et al., 2022a,b; Yang et al., 2022). This evolution in recommendation systems showcases a continuous effort to refine approaches for handling sequential data and improving the accuracy of POI recommendations.
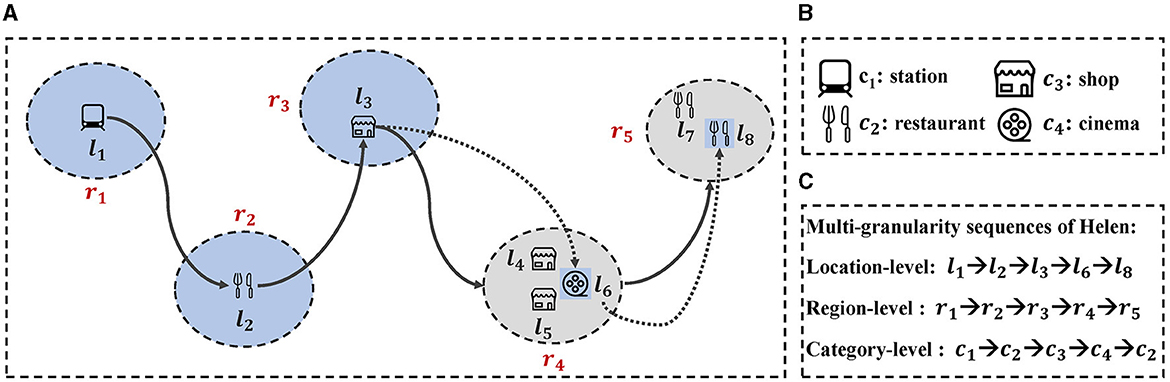
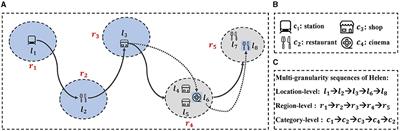
Although the above methods have achieved advanced performance, these methods still face the following issues. First, most existing studies exploit location-level POI sequences, ignoring the existence of region-level and category-level POI sequences. As illustrated in Figures 1A–C, Helen visited location-level POI at l1, l2, and l3 successively, but Helen may leave a rough footprint, e.g., region r4 instead of the precise POI l4, l5, and l6. The accessible sequence of check-ins will become: “r1→r2→r3→r4”. Thus, region-level POI are common and essential in real life. Finally modeling POI category labels are crucial for next POI recommendation as it improves accuracy and diversity. For example, if a user has visited museums and art galleries, and our model determines they are interested in art but not sure what type of place they want to visit, category label modeling becomes essential. Without it, we may recommend places they are not interested in, reducing satisfaction and usability.
Figure 1. An example of Helen's multi-granularity POI sequences. (A) An illustration of Helen's movements across different locations and regions. Each circle represents a region, with arrows indicating the sequence of her movements. (B) Icons representing different categories of POIs. (C) Multi-granularity sequences of Helen's movements.
Second, following the above innovations, most subsequent POI recommendation models adopted designs based on the supervised learning paradigm. The supervision signals of these models are mainly derived from user interaction data with POIs, but since the supervision signals are usually sparse, this may have an impact on the learning of user preferences. Existing work attempts to utilize supervised signals to enhance the quality of user preference learning. For example, CTLTR (Zhou et al., 2022) is a trip prediction model that uses self-supervised learning to capture supervised signals to enhance user preference learning. However, existing methods usually only use location-level POI check-in trajectories to mine supervised signals, while ignoring the supervised signals of region-level and category-level POI sequences.
To this end, we propose a multi-granularity contrastive learning (MGCL) model for next POI recommendation, which utilizes multi-granularity representation and contrastive learning to improve the next POI recommendation performance. Specifically, location-level POI graph, category-level, and region-level sequences are first constructed. Then, we use graph convolutional networks on POI graph to extract global cross-user sequential transition patterns. Then, self-attention networks are used to learn individual user sequential transition patterns for multi-granularity. To capture the collaborative signals among multi-granularity, we apply a contrastive learning approach, which uses pairwise contrastive learning at the location-level, region-level, and category-level representations. Finally, we joined learning the next POI recommendation task and the multi-granularity contrastive learning task. Through extensive experiments on real-world datasets, the MGCL model consistently outperforms current leading methods in all aspects. The main contributions of this study can be summarized as follows:
• To the best of our knowledge, this is the first work to apply contrastive learning for next POI recommendation, which can capture the collaborative signals among different granularities and facilitate mutual enhancement.
• We propose a framework called Multi-granularity Contrastive Learning for Next POI Recommendation (MGCL). To achieve better recommendation performance, we also adopt a multi-task learning approach.
• The effectiveness of the MGCL model was confirmed through experiments on three real-world datasets, confirming that our model has made significant progress in improving recommendation performance.
The subsequent sections of this study are structured as follows: In Section 2, we commence with a discussion of related work. Moving on to Section 3, we present our proposed model, MGCL, designed for next Point-of-Interest (POI) recommendation. Section 4 provides an overview of the experimental results. Lastly, in Section 5, we draw conclusions to summarize the study.
2 Related workIn this section, we undertake a comprehensive review of related work from two distinct perspectives: POI recommendation and contrastive learning.
2.1 POI recommendationNext POI recommendation aims to learn the user preference transition patterns, as well as the spatio-temporal information relationship between user check-ins, time of check-ins, and geographical location. Due to its great commercial value, this task has attracted much attention. Most of the next POI recommendation methods are based on Markov Chain (MC) which focus on iteratively determining the transformation matrix of the next behavior or deep learning which processes the recommendation task in a data-driven manner. Specifically, factorization machines (FMs) (Rendle, 2010) suggest dealing with the non-adjacent check-in problem in the next POI recommendation, which is not easy to model with the MC-based methods. Then, Cheng C. et al. (2013) attempt to incorporate spatio-temporal information into existing models. Zhang et al. (2020b) propose a personalized geographical influence modeling method (PGIM) that jointly learns users' geographical and diversity preferences to improve POI recommendations, addressing limitations in spatial relevance and diversity in existing methods. Liu et al. (2018) propose a privacy-preserving framework using partially homomorphic encryption to design two protocols for trust-oriented POI recommendation. It proves that these protocols are secure against semi-honest adversaries and demonstrates through experiments that they achieve privacy preservation with acceptable computation and communication costs. Compared with MC-based methods, DL-based methods can usually achieve better performance.
Next POI recommendation methods based on early deep learning are RNN-based and their variants. STRNN (Liu et al., 2016) enhances the spatio-temporal modeling capability of RNN by using spatio and temporal intervals between successive check-ins. Time LSTM (Zhu et al., 2017) adds time information to the long and short memory networks, while STGN (Zhao et al., 2022) further integrates spatial information by designing space-time gates. Recently, with the development of Transformers, the attention mechanism has been widely used in the next POI recommendation. STAN (Luo et al., 2021) uses the self-attention network (SAN) to model long-term dependencies in long-term use check-in sequences. MGSAN (Li et al., 2021b) employs a multi-granularity representation along with a self-attention mechanism to characterize Point-of-Interest (POI) sequences at both individual and collective levels. This dual-level granularity enables the model to adeptly grasp behavior transition patterns, thereby enhancing recommendation performance. MCMG (Sun et al., 2022) utilizes a multi-channel encoder to capture multi-granularity sequential transition patterns, thereby improving recommendation performance. We argue that the collaborative signals among different granularities of POI sequences can facilitate each other and benefit augment user preference learning.
2.2 Contrastive learningIn recent years, contrastive learning (CL) (Chuang et al., 2020; Ho and Vasconcelos, 2020; Liu et al., 2023) has shown potential in solving data sparsity problems in Computer Vision (CV) (Chen et al., 2020), Graph/Node Classification (G/NC) (You et al., 2020), and Natural Language Processing (NLP) (Gao et al., 2021) areas. Contrastive learning methods have been explored by certain researchers in attempts to be applied to recommendation systems (Xie et al., 2022). For example, SGL (Wu et al., 2021) employs a strategy involving the random removal of edges, vertices, and random walking to create diverse perspectives of the initial graph. The aim is to maximize the consistency of identical nodes across these varied views. NCL (Lin et al., 2022) introduces users (or items) and neighbors from structural space and semantic space, respectively, and uses them as positive (or negative) contrastive pairs. To improve the graph contrastive learning in the recommendation, SimGCL (Yu et al., 2022) introduces a straightforward contrastive learning approach. In contrast to employing a graph augmentation mechanism, the method opts for the addition of uniform noise to the embedding space for generating contrasting views. CL4SRec (Xie et al., 2022) innovatively incorporates contrastive learning into sequential recommendation. It achieves this by introducing three random data augmentation strategies, which are employed to generate contrastive sequences based on the original sequences for the first time in this context. DuoRec (Qiu et al., 2022) engages in contrastive learning at the model level as a strategy to alleviate the degradation of representation. CTLTR (Zhou et al., 2022) is a trip prediction model that uses self-supervised learning to capture supervised signals to enhance user preference learning. However, existing methods usually only use location-level POI check-in trajectories to mine supervised signals, while ignoring the supervised signals of region-level and category-level POI sequences.
3 Problem statementLet ? = , ℒ = , ℛ = , ? = represent the sets of users, locations (Points of Interest - POI), regions, and categories, respectively. A check-in track (u, l, t, g, r, c ) indicates that user u visited a POI l in region r at time t, where l is geocoded by g (longitude, latitude), and the category is c. The POI trajectory of user u is denoted as ℒu=. The corresponding region and category check-in trajectories are denoted as ℛu= and ?u=. Given ℒu, ℛu, and ?u, our objective is to predict the next location ltk+1 for user u at time tk+1.
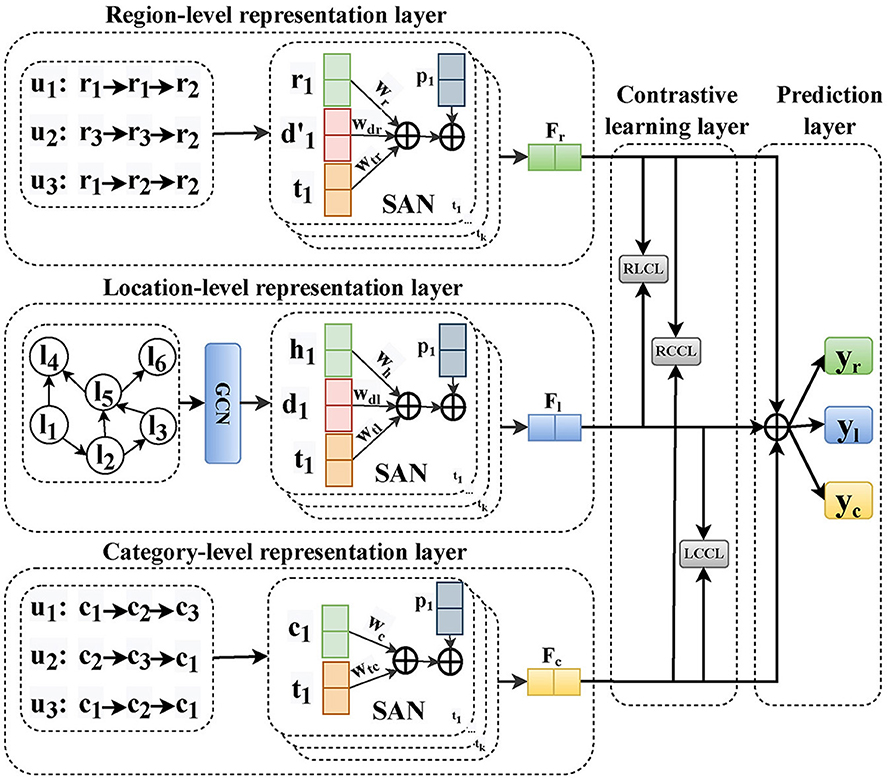
4 The proposed methodologyIn this section, we elaborate on the proposed model, multi-granularity contrastive learning (MGCL), for next POI recommendation. The overall representation of our MGCL framework is shown in Figure 2. Specifically, MGCL has the following parts: (1) Location-level representation layer aims to capture global across-user and local individual sequential transition patterns through location granularity sequences. (2) Region-level representation layer aims to learn about the sequential transition patterns based on region granularity sequences of local individual users. (3) Category-level representation layer aims to learn about the sequential transition patterns based on category granularity sequences of local individual users. (4) Contrastive learning layer aims to capture the collaborative signals between different granularities and enable POI representation to achieve high-quality representation by multi-granularity modeling. (5) The prediction layer aims to predict the next POI. We will introduce each layer in detail.
Figure 2. Illustration of the MGCL model that includes location-level, region-level, and category-level representation layers, followed by the contrastive learning and prediction layer.
4.1 Location-level representation layerThis layer aims to capture global across-user and local individual sequential transition patterns through location granularity sequences.
4.1.1 POI representation via GCNAt first, we generate a directed graph of POI according to the check-in trajectories of all users, which can model the sequential pattern of all users globally, and then capture the collaborative signal across users. After getting the constructed directed POI graph, we use GCN to obtain the POI representation,
H(z+1)=ReLU(D~-1A~H(z)W(z)), (1)Here, ReLU denotes the activation function, A~=A+I; A∈ℝ|ℒ| × |ℒ| is the in-degree adjacency matrix; I is the identity matrix representing the self-connection of each node; D~∈ℝ|ℒ|×|ℒ| is the diagonal in-degree matrix with D~ii=∑jA~ij; H(z)∈ℝ|ℒ| × d is the POI embedding matrix in the z-th layer; d is the embedding size; H(0) is the initialized POI embedding matrix; W(z)∈ℝd×d is a layer-wise trainable weight matrix.
4.1.2 Location-level POI representationThe goal of the next POI recommendation is to predict for a single user where to go in the next time. Therefore, the location-level, that is, the POI check-in sequence within a user, also plays a crucial role in user preference modeling. To this end, we model local user sequential transition patterns with the self-attention network (SAN). On the one hand, SAN can model the context information among non-continuous check-in data and adaptively aggregate it according to the corresponding weight. On the other hand, SAN can model the context information of the current POI.
After GCN, the POI in the check-in track of user u is expressed as Hu=[ht1u,ht2u,...,htku], where h∈ℝd is the output of the last layer of GCN. To distinguish different positions of POI in the check-in trajectory, we sum the embedding of position p with the above POI representation. In addition, in the next POI recommendation task, the temporal and spatial context information is very important. Therefore, we use these two factors to enhance the representation of POI embedding. The enhanced POI is represented as follows:
H~u=[ht1uWh+d1uWd,l+t1uWt,l+p1ht2uWh+d2uWd,l+t2uWt,l+p2...htkuWh+dkuWd,l+tkuWt,l+pk], (2)where W is the learnable weight matrix; dku∈ℝd is the representation of distance dku from ltk-1u to ltku; d1u=0; tku∈ℝd is the representation of temporal context; and pk∈ℝd is the position representation.
To capture the sequential dependencies at the user's local level, we input the augmented POI representation H~u into the SAN. It is calculated as follows:
Slu=softmax((H˜uWlQ)(H˜uWlK)Td)(H˜uWlV), (3)where Slu∈ℝk×d is the augmented representation of POI in ℒu through the SAN; WlQ,WlK,WlV∈ℝd×d are the query, key, and value projection matrices; and d to prevent the value of the input softmax from being too large, the partial derivative tends to approach 0.
Applying feed-forward networks (FFNs) to Slu can make the model non-linear, as follows:
Flu=ReLU(SluW1+b1)W2+b2, (4)where Flu is the augmented POI representation in ℒu through the FFN; W is the learnable weight matrix, and b is the bias vector.
4.2 Region-level representation layerThe purpose of this layer is to learn about the sequential transition patterns based on region granularity sequence of local individual users.
4.2.1 Region-level POI representationThe sequential transformation patterns at the region-level are similar to the location-level, which are also affected by two factors, temporal and spatial. Hence it is crucial to take these two factors into account, so the enhanced regional-level preference representation Ru is as follows:
Ru=[rt1uWr+d′1uWd,r+t1uWt,r+p1rt2uWr+d′2uWd,r+t2uWt,r+p2…rtkuWr+d′kuWd,r+tkuWt,r+pk], (5)where rtku∈R is the representation of Rtku in ℛu and R∈ℝ|ℛ| × d is the region representation matrix. d′ku∈ℝd is the representation of distance d′ku between rtk-1u and rtku; d′1u=0.
We then feed Ru into the SAN and FFN:
Sru=softmax((RuWr Q)(RuWr K)Td)(RuWr V), (6)where Sru,i∈ℝd×d is the refined representation of regions in ℛu through the SAN. Applying FFN to Sru can make the model non-linear. We can obtain Fru as the refined representation of regions in ℛu.
Fru=ReLU(SruW3+b3)W4+b4, (7)where Fru is the enhanced representation in ℛu through the FFN.
4.3 Category-level representation layerThe purpose of this layer aims to learn about the sequential transition patterns based on category granularity sequence of local individual users.
4.3.1 Category-level POI representationCategory information can reflect the user's intention to a certain extent, and the change in the POI category represents the dynamic shift in the user's intention. Similarly, it also has an obvious sequential transition pattern, and the sequential changes at the category-level are affected by the time factor. Hence it is crucial to consider this factor. Therefore, the augmented representation of the categories sequences Cu is as follows:
Cu=[ct1uWc+t1uWt,c+p1ct2uWc+t2uWt,c+p2...ctkuWc+tkuWt,c+pk], (8)where ctku∈C is the representation of Ctku in ?u and C∈ℝ|?| × d is the category representation matrix.
We then feed Cu into the SAN and FFN:
Scu=softmax((CuWc Q)(CuWc K)Td)(CuWc V), (9)where Scu∈ℝd×d is the refined representation of category in ?u through the SAN. Applying FFN to
留言 (0)