
記住我



In this retrospective study, data were sourced in January 2023 from the openly accessible PPMI database (https://www.ppmi-info.org/). PPMI is a multicenter study focused on gathering Parkinson’s progression biomarkers [16]. PPMI participants met specific criteria: PD diagnosis (marked as group ‘PD’ in the PPMI database) and availability of T1-weighted MRI data and MDS-UPDRS III scores for both medication ON and OFF states during the same visit. The exclusion criteria included the lack of a calculable levodopa equivalent daily dose (LEDD) overlapping with the visit time, multiple records for the same patient at one visit, MDS-UPDRS III OFF < 5, and LEDD > 5000. In total, 219 records, with multiple records from the same participants at different visits, were included. An additional dataset of 193 healthy controls from PPMI was included only for age correction.
A threshold of a 30% improvement rate classified the patients into “good” and “bad” responders [13]; the improvement rate was calculated as follows:
$$\,= \frac-\,\,--\,\,}-\,\,}\\ \times 100 \%$$
The whole PPMI dataset was randomly split into training and test sets with a ratio of 8:2, ensuring that records from the same participant were in the same set, resulting in 173 and 46 records for the training and test sets, respectively.
The performance of the output models on actual samples was validated using an external clinical dataset with 217 records from Ruijin Hospital, Shanghai Jiao Tong University School of Medicine, collected between 2017 and 2022. All included participants underwent standard LCT. Notably, these records were collected retrospectively from patients available for deep brain stimulation surgery, which might introduce potential bias to the dataset distribution, with longer disease duration, LEDD, and MDS-UPDRS III scores and a higher proportion of “good” responders (Table 1 and Fig. 1).
Table 1 Demographic and clinical information for datasetsFig. 1
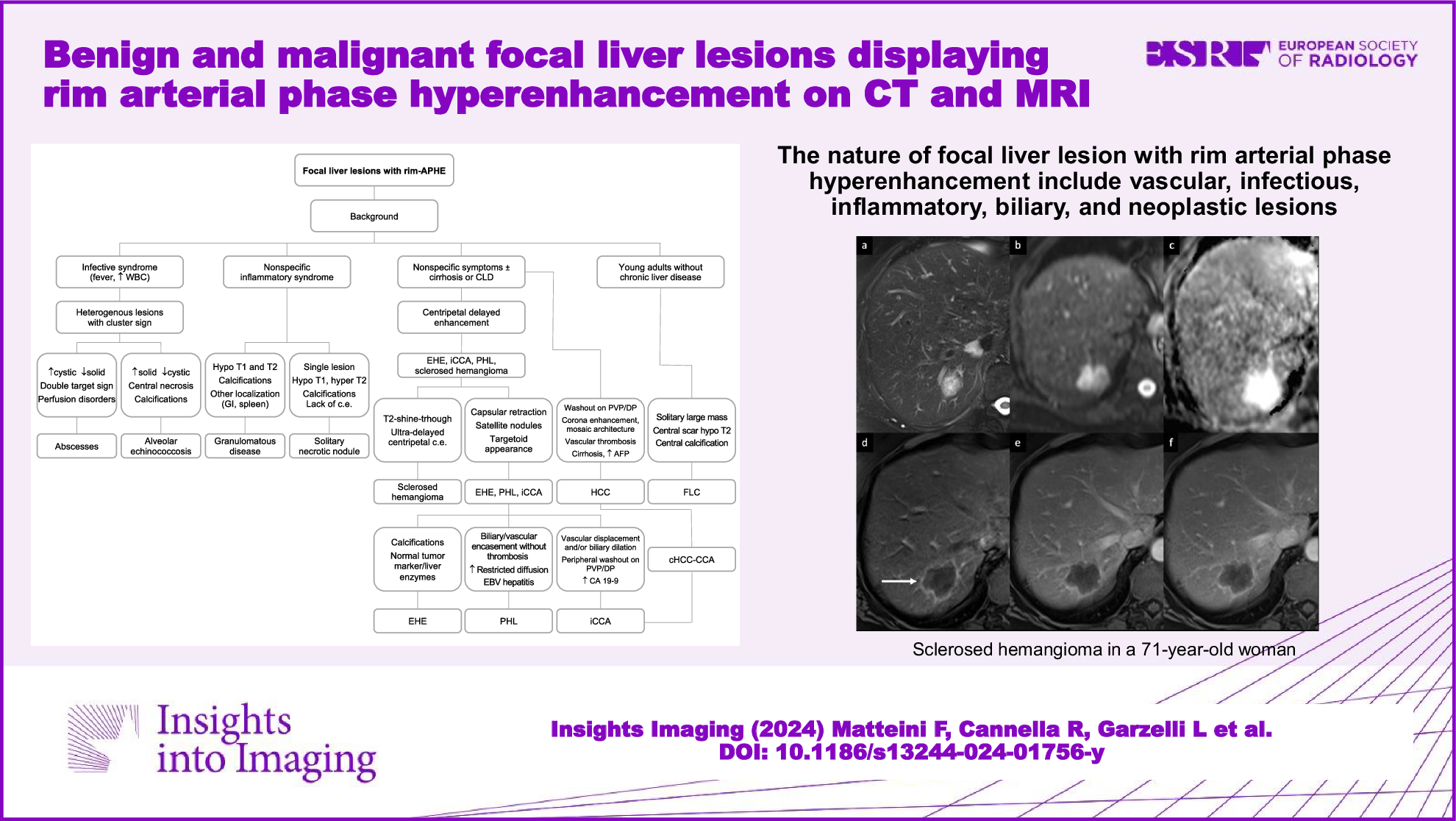
Flowchart of sample inclusion. PD, Parkinson’s disease; HC, healthy control; LEDD, Levodopa equivalent daily dose; MDS-UPDRS III, Movement Disorder Society Unified Parkinson’s Disease Rating Scale Part III
T1-weighted MRI scans from PPMI were acquired using 1.5-T (Philips) or 3-T (Siemens) scanners with an isotropic resolution of 1 mm, whereas those from Ruijin Hospital were isotropically acquired using 1.5-T or 3-T scanners (GE) with a resolution of 1 mm to 2 mm.
Data pre-processingTwo image pre-processing pipelines were constructed using Nipype (https://nipype.readthedocs.io/en/latest/) [17] for different feature extraction methods, following previous studies (see Fig. 2). The first one utilized the CAT12 toolbox (http://www.neuro.uni-jena.de/cat/) [18] from SPM12 (https://www.fil.ion.ucl.ac.uk/spm/software/spm12/); the image was segmented into gray matter, white matter, and cerebrospinal fluid, followed by registration to the default template (IXI151_MNI152) in CAT12 at 1.5 mm isotropic voxel size. Spatial smoothing was applied with an 8 mm full width at half maximum Gaussian kernel. The second one utilized ANTs (https://github.com/ANTsX/ANTs) [19, 20]; the image was registered to the PD25 atlas [21,22,23] using RegistrationSynQuick with an isotropic voxel size of 1 mm.
Fig. 2
Study design. Two preprocessing methods were performed on T1w images. Four feature extraction methods were then applied to extract features from the preprocessed images. Three feature selection methods were used sequentially to select the most significant features for classification. Three machine learning models were trained on the training set and tested on the test set to predict the category of LCT result (good/bad responder). An external clinical dataset was also included to evaluate the generalizability of the model. The important features of the MedicalNet extractor were visualized. VBM, voxel-based morphometry; CAT12, computational anatomy toolbox; ANTs, advanced normalization tools; ROI, region of interest; PCA, principal component analysis; mRMR, minimum redundancy maximum relevance; LASSO, least absolute shrinkage and selection operator; RFE, recursive feature elimination; SVM, support vector machine; XgBoost, extreme gradient boosting; MLP, multi-layer perceptron
Feature extractionFour feature extraction methods were evaluated, including three from published research and one proposed in this study. Details of the former methods are provided in the Supplementary Materials. In brief, the first one is age-corrected regional gray matter intensity extracted from CAT12 pre-processed images, following Ballarini et al [12], after which principal component analysis (PCA) was used to select the first 50 principal components as features. The second method, proposed by the PREDISTIM Study Group and Chakraborty et al [4, 5] used subcortical ROI textures as PD biomarkers, by extracting and removing highly correlated texture features of 16 subcortical ROIs from ANTs-pre-processed images, encompassing caudate, putamen, thalamus, GPi, GPe, STN, SN, and RN using PyRadiomics (https://pyradiomics.readthedocs.io/en/latest/). The morphological graph was constructed using Kullback–Leibler and Jensen–Shannon divergence following Xie et al [13]. The graph metrics of the individual networks were calculated as features.
To enhance the utility of T1-weighed MRI data, we proposed a feature extraction method based on MedicalNet, a pre-trained ResNet-based deep model tailored for medical images [24]. We replaced the layers originally used for segmentation with a max-pooling layer (kernel size = 8, stride = 8, padding = 0) and a flattening layer. The pre-trained model was fixed and treated as a pure feature extractor. ANTs-pre-processed T1-weighted images (193, 229, 193 dimensions) were input into the model to obtain the output vector as the feature for each sample.
After sequential feature selection, GradCAM [25] was employed to visualize the retained features. The selected features were mapped back to their coordinates as corresponding gradients in the flattening layer. Excluded features were assigned gradients of –0.001. A saliency map was generated and up-sampled for the last convolution layer to visualize the contributing ROIs in the image.
Feature selectionTo refine the feature sets, given their potential redundancy and noise, a feature selection step was necessary for effective classification. Minimum Redundancy - Maximum Relevance (mRMR), least absolute shrinkage and selection operator (LASSO), and recursive feature elimination (RFE) were applied sequentially to the original feature sets. mRMR, based on mutual information, selects features with high relevance to the target and low redundancy [26]. LASSO, based on L1 regularization, compresses unimportant features to zero to achieve feature selection [27]. RFE, based on backward elimination, recursively removes the least important features until the specified number of features is reached.
We sequentially applied these methods to the features extracted from the training set with four feature extraction methods respectively to eliminate irrelevant and redundant features due to the large number of features generated by MRI data, among which LASSO and RFE went through a 5-fold cross-validation to determine optimal hyperparameters. For mRMR, the top 50 features, ranked across the feature sets, were selected for the next step. For LASSO, the optimal regularization parameter α∗ was used to fit the model on the entire training set to select the features with non-zero coefficients. For RFE, a logistic regression model representing L2 regularization was used as an estimator in RFE. The entire feature selection process was repeated 10 times to generate a more robust feature set. As a result, the feature number of each extraction method resulted in feature sets being reduced separately.
Machine-learning modelsMachine learning models were trained on a training set using 5-fold cross-validation and tested on a test set to predict the category of the LCT results (good/bad responders). An ablation study was conducted to assess the contribution of T1-weighted MRI data. This involved comparing the classification performance among three feature sets under the same setting: an imaging set, containing features extracted via four methods respectively; a clinical set, encompassing demographic and clinical information including age, sex, disease duration, LEDD, and MDS-UPDRS III OFF; and union set that combined the imaging and clinical sets. All training set features were used to fit MinMaxScaler to scale the training and test set features.
Optimal hyperparameters for each model were determined through 5-fold cross-validation performed on the training set. The specific model was then trained on the entire training set with the optimal hyperparameters and used to predict LCT results for the test set. Repeated experiments were performed to eliminate random effects.
Our study employed three machine learning models—SVM, XgBoost, and MLP—resulting in nine trained and tested models.
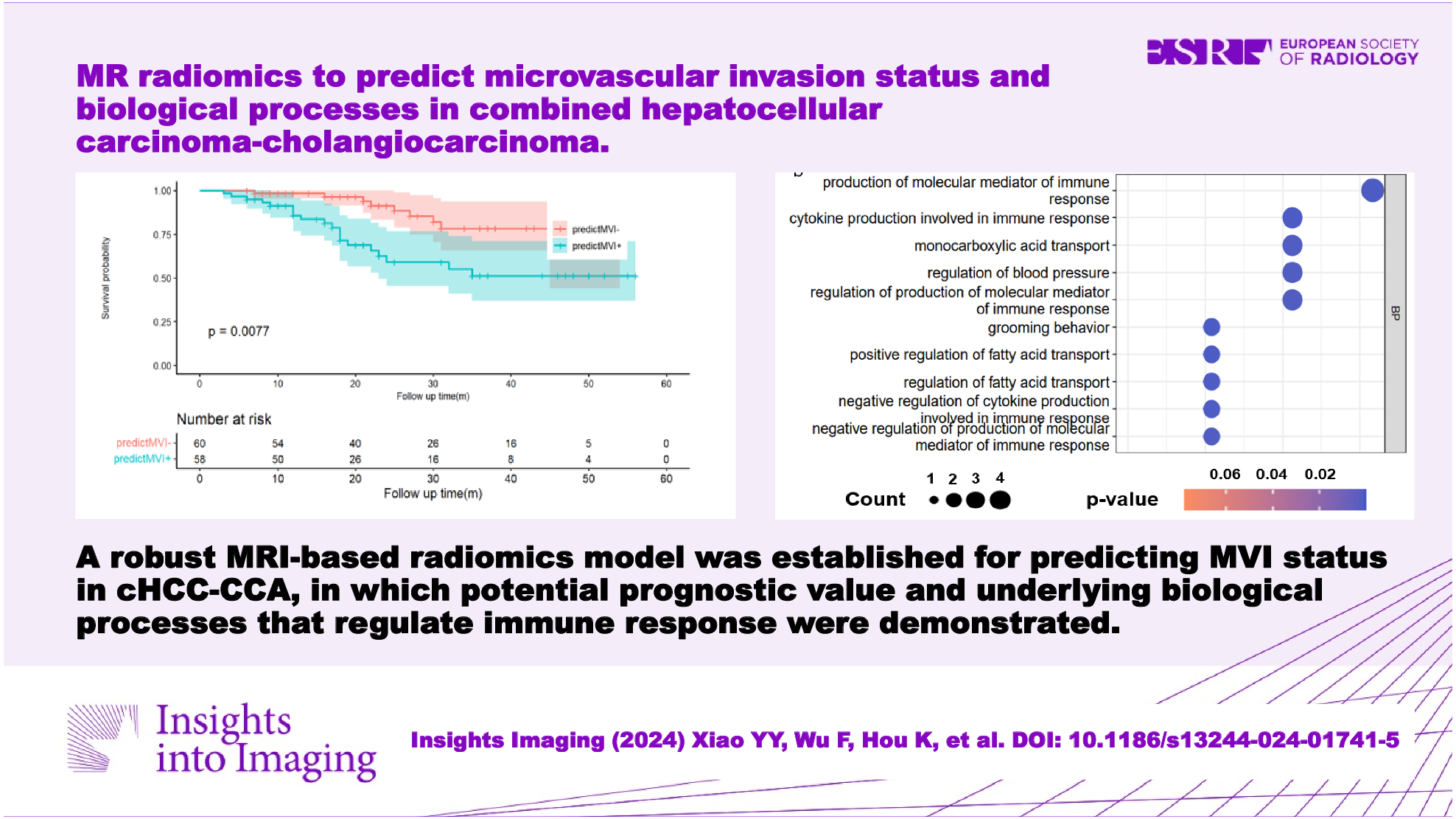
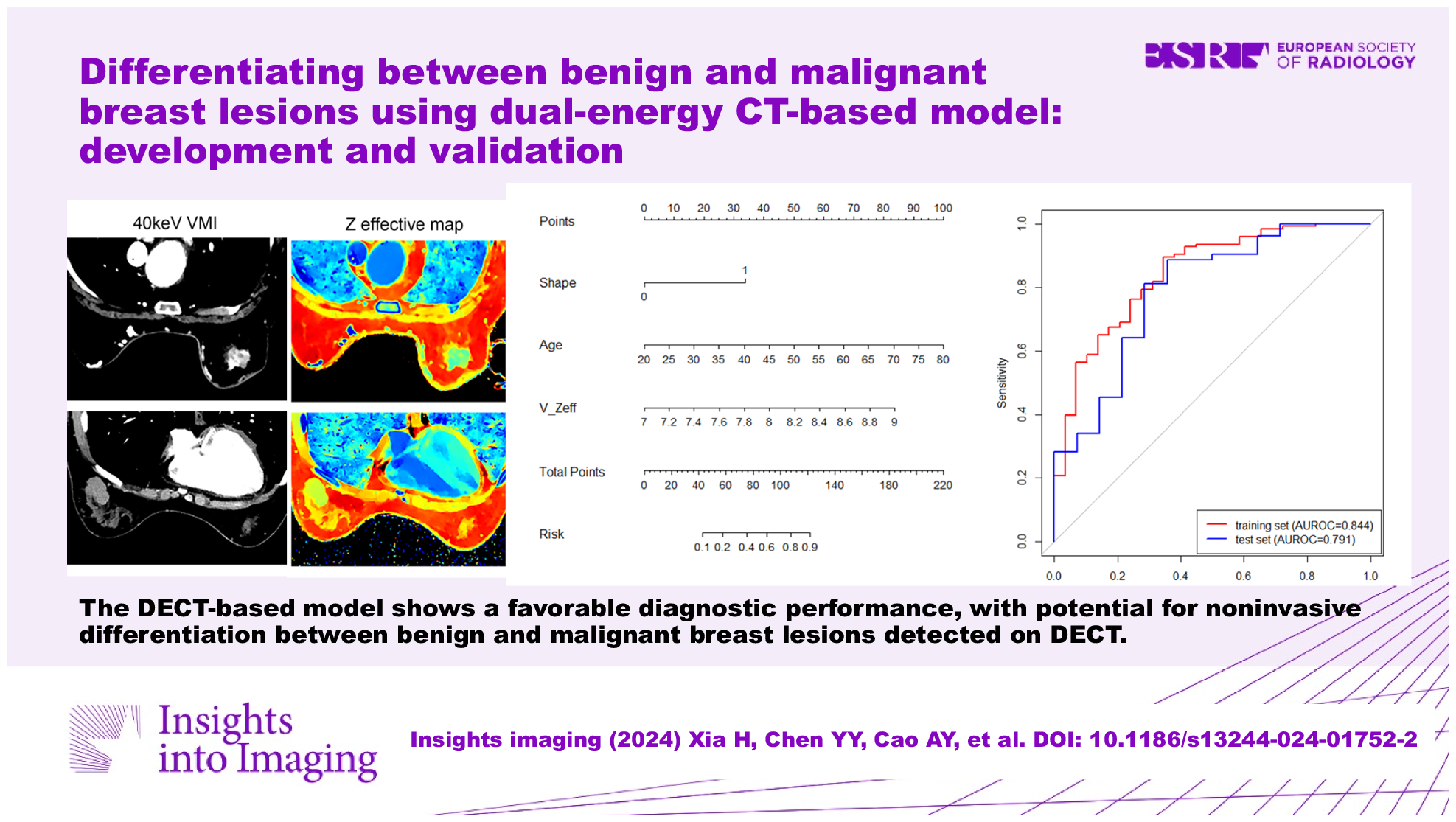
Model performance evaluationTo assess model performance, we used the micro-averaged area under the receiver operating characteristic curve (AUC) as the primary metric. For each feature extraction method and machine learning model, we calculated three AUCs for three test sets generated using three different feature sets. A paired one-tailed t-test was performed between the clinical and union sets to evaluate the statistical significance between the clinical and union models.
If any imaging feature set showed a statistically significant contribution (p < 0.001), the model was further validated on an external clinical dataset to evaluate its generalizability using the best machine-learning method. More specifically, all models trained in the training stage were fixed without further training and modification, resulting in no additional training in the validation stage. The feature labels to be tested were manually selected according to the feature-selection results of the training set, and feature sets to be validated were built by extracting features from an external set according to feature labels. The external set-generated features were normalized using the MinMaxScaler trained on the training set and inputted into the trained model to predict LCT results.
Statistical analysisTo evaluate statistical significance between the clinical and union models, a paired one-tailed t-test was performed between the two sets, with each containing 10 AUCs generated from 10 random seeds. A p-value of < 0.001 was considered statistically significant. All statistical analyses were performed using scikit-learn (https://scikit-learn.org/stable/, version 1.2.1), scipy (https://www.scipy.org/, version 1.10.0), and statannotations (https://github.com/trevismd/statannotations, version 0.5.0) [28].
留言 (0)